[Перевод] Семантический поиск: от простого сходства Жаккара к сложному SBERT

В материале, переводом которого мы решили поделиться к старту курса о машинном и глубоком обучении, простым языком рассказывается о семантическом поиске, статья охватывает шесть его методов; начиная с простых сходства по Жаккару, алгоритма шинглов и расстояния Левенштейна, автор переходит к поиску с разреженными векторами — TF-IDF и BM25 и заканчивает современными представлениями плотных векторов и Sentence-BERT. Простые примеры сопровождаются кодом и иллюстрациями, а в конце вы найдёте ссылки на соответствующие блокноты Jupyter.
Поиск сходства — одна из самых быстрорастущих областей в ИИ и машинном обучении. По своей сути, это процесс сопоставления релевантных частей информации друг с другом. Велика вероятность, что вы нашли эту статью через поисковую систему — скорее всего, Google. Возможно, вы искали что-то вроде «what is semantic similarity search?» или «traditional vs vector similarity search». Google обработал ваш запрос и использовал многие основные принципы поиска по сходству, о которых рассказывается в этой статье.
Если поиск сходства лежит в основе успеха компании стоимостью $ 1,65 Т — пятой по стоимости в мире[1], есть большой шанс, что о нём стоит узнать больше. Поиск сходства — сложная тема, есть бесчисленное множество методик построения эффективных поисковых систем. В этой статье мы рассмотрим несколько наиболее интересных и мощных из этих методов, уделяя особое внимание семантическому поиску. Посмотрим, как они работают, чем они хороши и как мы можем применять их самостоятельно. Можно посмотреть это видео или прочитать статью.
Два видео о двух классах подходовТрадиционный поиск
Мы начинаем с лагеря традиций и там находим нескольких ключевых игроков:
Сходство Жаккара.
Алгоритм шинглов.
Расстояние Левенштейна.
Все это показатели отлично работают при поиске сходства, из них мы рассмотрим три самых популярных: сходство по Жаккару, алгоритм шинглов и расстояние Левенштейна.
Сходство Жаккара
Сходство Жаккара — это простая, но иногда мощная метрика сходства. Даны две последовательности A и B: находим число общих элементов в них и делим найденное число на количество элементов обеих последовательностей.
 Сходство Жаккара измеряет пересечение между двумя последовательностями по сравнению с объединением двух последовательностей
Сходство Жаккара измеряет пересечение между двумя последовательностями по сравнению с объединением двух последовательностейПример: даны две последовательности целых чисел, запишем:
Здесь мы определили два общих неодинаковых целых числа, 3 и 4 — между двумя последовательностями с общим количеством десяти целых чисел в обеих, где восемь чисел являются уникальными значениями — 2/8 даёт нам оценку сходства по Жаккарду 0,25. Ту же операцию можно выполнить и для текстовых данных: всё, что мы делаем, — заменяем целые числа на токены.
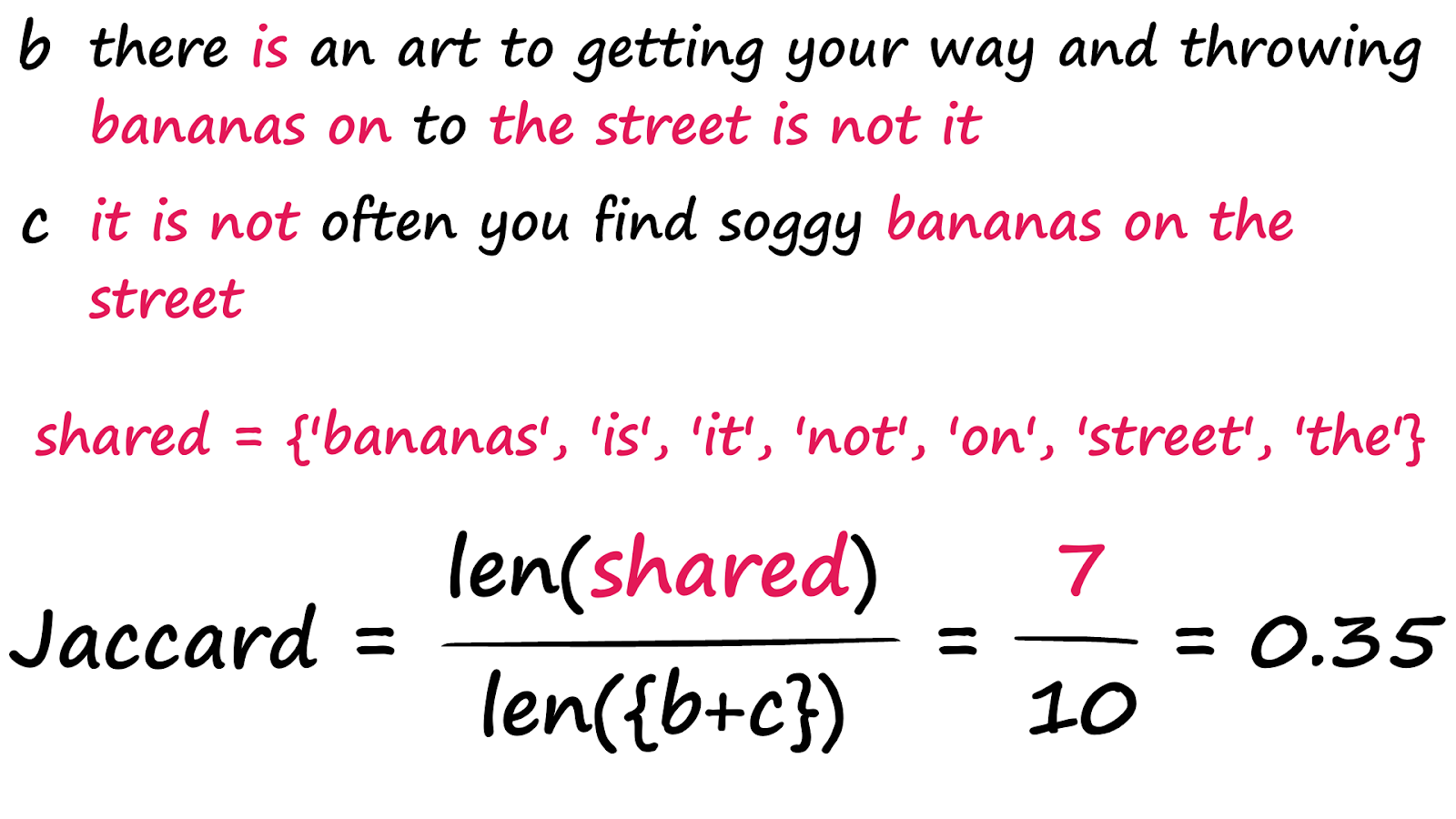 Сходство по Жаккару, рассчитанное между двумя предложениями a и b
Сходство по Жаккару, рассчитанное между двумя предложениями a и bМы обнаружили, что, как и ожидалось, предложения b и c набрали гораздо больше баллов. Конечно, это не лучшее решение — два предложения, в которых нет ничего общего, кроме слов 'the', 'a', 'is' и т. д., могут получить высокие оценки Жаккара, несмотря на то, что они неодинаковы по смыслу. Эти недостатки могут быть частично устранены с помощью методов предварительной обработки, таких как удаление стоп-слов, стемминг/лемматизация и т. д. Однако, как мы скоро увидим, некоторые методы позволяют полностью избежать этих проблем.
Алгоритм шинглов
Другая похожая техника — алгоритм использует точно такую же логику пересечения/объединения —, но с «шинглом». 2-шингловое предложение a будет выглядеть так:
a = {'his thought', 'thought process', 'process is', ...}После можно применить тот же расчёт пересечения/объединения между разбитыми на шинглы предложениями:
При помощи двух шинглов находим три совпадающих шингла между предложениями b и c, в результате сходство составляет 0,125.
Расстояние Левенштейна
Другая популярная метрика сравнения двух строк — расстояние Левенштейна — это количество операций, необходимых для преобразования одной строки в другую, вот его формула:
 Формула расстояния Левенштейна
Формула расстояния ЛевенштейнаНа вид она довольно сложна; если вы её поняли, это прекрасно! Если нет, не волнуйтесь — мы разберём её. Переменные a и b представляют две наши строки, i и j — позиции символов в a и b соответственно. Итак, даны строки:
 «Levenshtein» и неправильно написанное «Livinshten»
«Levenshtein» и неправильно написанное «Livinshten»Мы найдём, что:
 Индексируем само слово, начиная с 1 до его длины, нулевой индекс означает «ничего» (подробнее об этом — далее).
Индексируем само слово, начиная с 1 до его длины, нулевой индекс означает «ничего» (подробнее об этом — далее).Это легко! Прекрасный способ понять логику этой формулы — визуализировать алгоритм Вагнера — Фишера, рассчитывающий расстояние Левенштейна при помощи простой матрицы. Мы берём два слова a и b и размещаем их по обеим осям нашей матрицы, включая символ ничего как пустое пространство:
 Пустая матрица Вагнера-Фишера — мы будем работать с ней для вычисления расстояния Левенштейна между 'Levenshtein' и 'Livinshten'.
Пустая матрица Вагнера-Фишера — мы будем работать с ней для вычисления расстояния Левенштейна между 'Levenshtein' и 'Livinshten'.Код инициализации пустой матрицы Вагнера — Фишера:
Переберём все позиции в матрице и применим ту сложную формулу, которую видели ранее. Первый шаг в нашей формуле if min (i, j) = 0 — здесь мы уточняем, не равны ли i и j нулю? Если да, переходим к функции max (i, j), которая присваивает текущей позиции в нашей матрице больше из двух значений — i и j:
 Начнём справа, вдоль рёбер, где i и/или j равно 0, значение в матрице будет заполнено max (i, j)
Начнём справа, вдоль рёбер, где i и/или j равно 0, значение в матрице будет заполнено max (i, j)Код операций min (i, j) == 0, за которой следует визуализированная выше max (i, j).
С внешними краями нашей матрицы мы разобрались, но нам всё ещё нужно вычислить внутренние значения — именно там будет проходить оптимальный путь. Вернёмся к if min (i, j) = 0 — что, если ни одно из них не равно 0? Затем переходим к сложной части уравнения в разделе min {. Нам нужно вычислить значение для каждой строки, а после взять минимальное значение. Сейчас эти значения известны — они находятся в нашей матрице:
 Для каждой новой позиции берём минимальное значение из трёх соседних позиций (обведено кружком вверху слева)
Для каждой новой позиции берём минимальное значение из трёх соседних позиций (обведено кружком вверху слева)lev (i-1, j), а все остальные операции — это операции индексации, когда мы извлекаем значение в данной позиции. Затем берём минимальное значение из трёх. Остаётся только одна операция. +1 слева должно применяться только в том случае, если a[i] != b[i] — это штраф за несовпадение символов.
![Если a[i] != b[j], прибавляем 1 к нашему минимальному значению — это штраф за несовпадение символов](https://habrastorage.org/getpro/habr/upload_files/12c/fbc/914/12cfbc914c84442521dd0be415c77d46.png) Если a[i] != b[j], прибавляем 1 к нашему минимальному значению — это штраф за несовпадение символов
Если a[i] != b[j], прибавляем 1 к нашему минимальному значению — это штраф за несовпадение символовЭта операция в цикле по всей матрице выглядит так:
Полная реализация расчёта расстояния Левенштейна при помощи матрицы Вагнера — Фишера.
Итак, мы вычислили каждое значение в матрице — эти значения представляют собой количество операций, необходимых для преобразования из строки a до позиции i в строку b до позиции j. Мы ищем количество операций для преобразования a в b, поэтому мы берём правое нижнее значение нашего массива lev[-1, -1].
![Оптимальный путь по матрице — в позиции [-1, -1] внизу — справа мы имеем расстояние Левенштейна между двумя строками](https://habrastorage.org/getpro/habr/upload_files/c9d/56c/572/c9d56c5721de0206c637ddecac7be442.png) Оптимальный путь по матрице — в позиции [-1, -1] внизу — справа мы имеем расстояние Левенштейна между двумя строками
Оптимальный путь по матрице — в позиции [-1, -1] внизу — справа мы имеем расстояние Левенштейна между двумя строкамиВекторное сходство
Для поиска на основе вектора мы обычно используем один из нескольких методов построения векторов:
TF-IDF.
BM25.
word2vec/doc2vec.
BERT.
USE.
В тандеме с некоторыми реализациями приблизительных ближайших соседей (ANN) эти векторные методы в мире поиска сходства, если говорить терминами программирования, — минимально жизнеспособные продукты. Рассмотрим подходы на основе TF-IDF, BM25 и BERT, поскольку они являются наиболее распространёнными и охватывают как разреженные, так и плотные векторные представления.
1. TF-IDF
Почтенный дедушка векторного поиска сходства, родившийся ещё в 1970-х годах. Он состоит из двух частей: Term Frequency (TF) и Inverse Document Frequency (IDF). Компонент TF подсчитывает, сколько раз термин встречается в документе, и делит его на общее количество терминов этого же документа.
 Компонент частоты термина (TF) TF-IDF подсчитывает частоту нашего запроса («bananas») и делит её на частоту всех лексем
Компонент частоты термина (TF) TF-IDF подсчитывает частоту нашего запроса («bananas») и делит её на частоту всех лексемЭто первая половина нашего расчёта, мы имеем частоту запроса в рамках текущего документа f (q, D) в числителе и частоту всех терминов в рамках текущего документа f (t, D) в знаменатели дроби. TF — хороший показатель, но не позволяет нам провести различие между распространёнными и необычными словами. Если бы мы искали слово «the», используя только TF, мы бы присвоили этому предложению ту же релевантность, что и при поиске «bananas». Это хорошо, пока мы не начнём сравнивать документы или искать что-то с помощью длинных запросов. Мы не хотим, чтобы такие слова, как 'the', 'is' или 'it', были оценены так же высоко, как 'bananas' или 'street'.
В идеале хочется, чтобы совпадения между более редкими словами оценивались выше. Для этого мы можем умножить TF на второй член — IDF. Обратная частота документа измеряет, насколько часто встречается слово во всех наших документах.
 Компонент обратной частоты документов (IDF) TF-IDF подсчитывает количество документов, содержащих наш запрос.
Компонент обратной частоты документов (IDF) TF-IDF подсчитывает количество документов, содержащих наш запрос.Здесь три предложения. Вычислив IDF для нашего распространённого слова 'is', получаем гораздо меньшее число, чем в случае более редкого слова 'forest'. Если бы после мы искали оба слова 'is' и 'forest', то объединили бы TF и IDF следующим образом:

Мы вычисляем оценки TF ('is', D) и TF ('forest', D) для документов a, b и c. Значение IDF относится ко всем документам, поэтому IDF ('is') и IDF ('forest') вычисляются только один раз. Затем мы получаем значения TF-IDF для обоих слов в каждом документе путём умножения компонентов TF и IDF. Предложение a набирает наибольшее количество баллов для 'forest', а 'is' всегда набирает 0, поскольку IDF ('is') равно 0.
Это замечательно, но где здесь применяется векторное сходства? Итак, мы берём наш словарный запас (большой список всех слов в нашем наборе данных) и вычисляем TF-IDF для каждого слова.
 Мы вычисляем значение TF-IDF каждого слова словаря, чтобы создать вектор TF-IDF. Этот процесс повторяется в каждом документе
Мы вычисляем значение TF-IDF каждого слова словаря, чтобы создать вектор TF-IDF. Этот процесс повторяется в каждом документеЧтобы сформировать векторы TF-IDF, мы можем собрать это воедино:
Отсюда мы получаем вектор TF-IDF. Стоит отметить, что словарь легко может иметь более 20 000 слов, поэтому созданные этим методом векторы невероятно разрежены, а это означает, что закодировать какой-либо семантический смысл мы не можем.
2. BM25
Преемник TF-IDF, Okapi BM25, является результатом оптимизации TF-IDF в первую очередь для нормализации результатов на основе длины документа. TF-IDF — отличный инструмент, но он может давать сомнительные результаты, когда мы начинаем сравнивать несколько упоминаний. Если мы возьмём две статьи по 500 слов и обнаружим, что «Черчилль» в статье А упоминается 6 раз, а в статье Б — 12 раз, должны ли мы считать статью А в два раза менее релевантной? Скорее всего, нет. BM25 решает эту проблему путём модификации TF-IDF:
 Формула BM25
Формула BM25Уравнение выглядит довольно неприятно, но это не что иное, как наша формула TF-IDF с несколькими новыми параметрами! Давайте сравним два компонента TF:
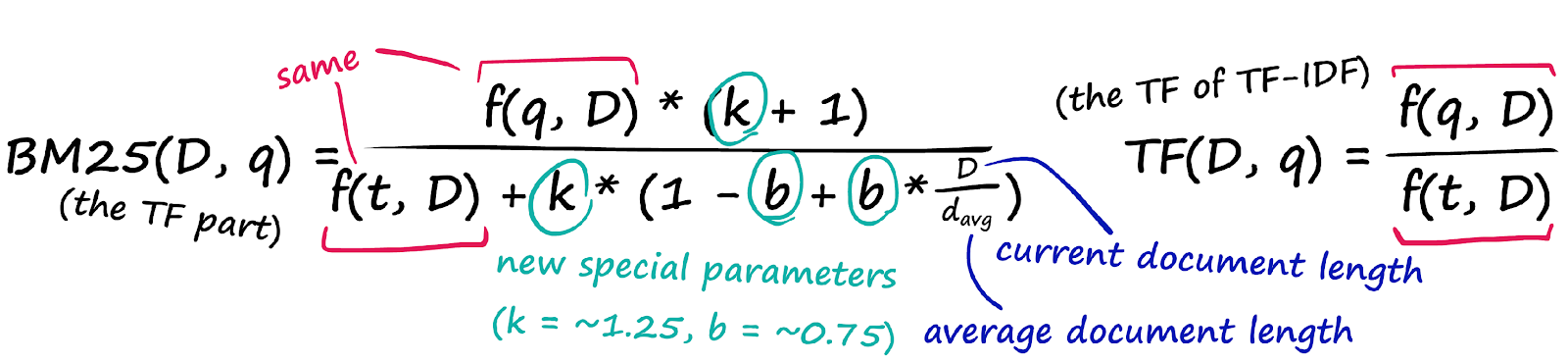 TF-часть BM25 (слева) по сравнению с TF-частью TF-IDF (справа)
TF-часть BM25 (слева) по сравнению с TF-частью TF-IDF (справа)И затем часть IDF, которая даже не вводит никаких новых параметров — она просто переставляет IDF из TF-IDF.
 IDF часть BM25 (слева) в сравнении с IDF TF-IDF (справа)
IDF часть BM25 (слева) в сравнении с IDF TF-IDF (справа)Итак, каков результат этой модификации? Если взять последовательность из 12 лексем и постепенно подавать в неё всё больше и больше «подходящих» лексем, то получим следующие результаты:

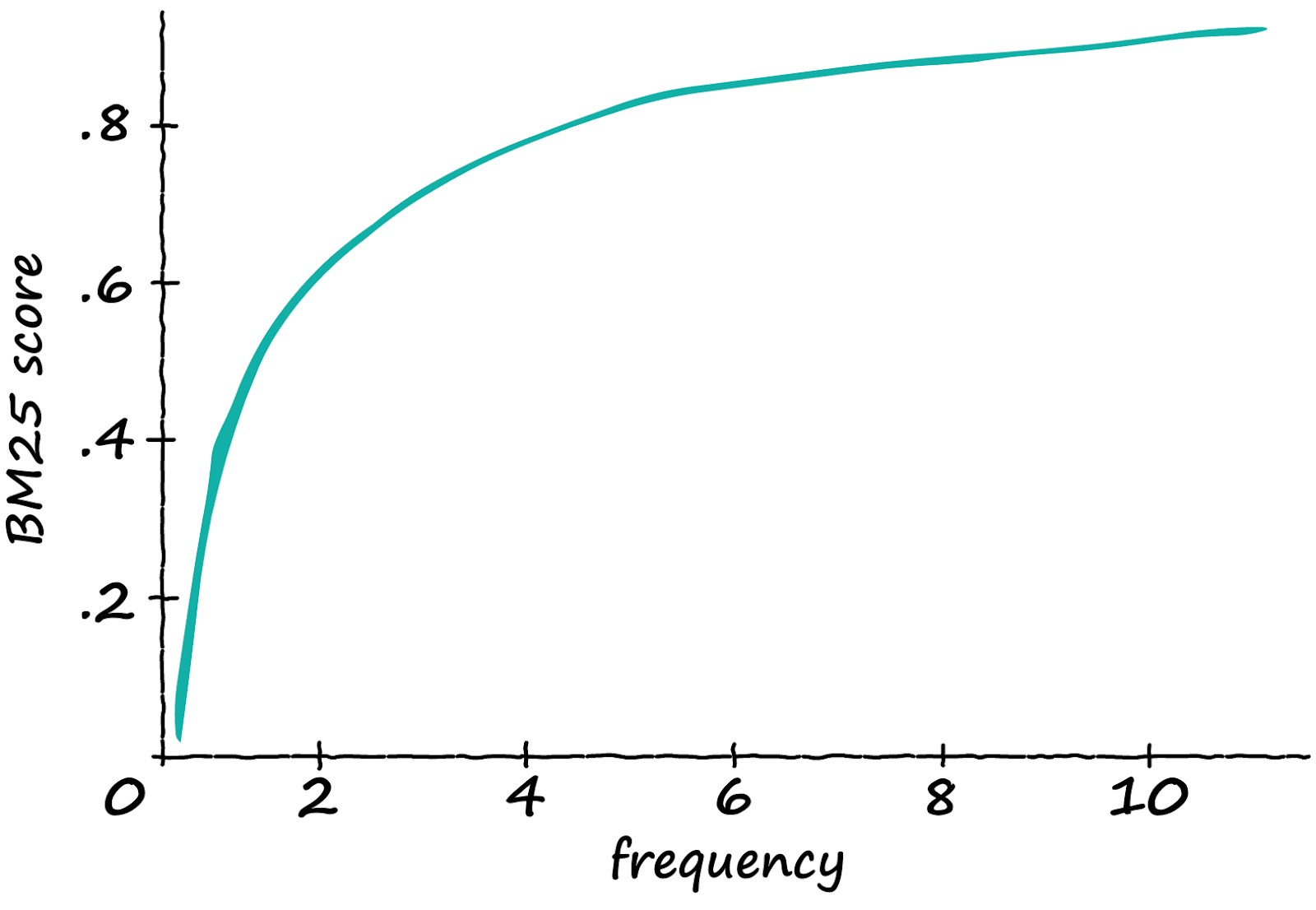 Сравнение алгоритмов TF-IDF (вверху) и BM25 (внизу) с использованием предложения из 12 лексем и возрастающего числа релевантных лексем (ось x)
Сравнение алгоритмов TF-IDF (вверху) и BM25 (внизу) с использованием предложения из 12 лексем и возрастающего числа релевантных лексем (ось x)Показатель TF-IDF линейно увеличивается с ростом числа релевантных лексем. Таким образом, если частота удваивается — увеличивается и показатель TF-IDF. Звучит круто! Но как реализовать это на Python? Опять же напишем простую и понятную реализацию, как с TF-IDF.
Мы использовали параметры по умолчанию для k и b, и наши результаты выглядят многообещающе. Запрос 'purple' соответствует только предложению a, а 'bananas' набирает приемлемые баллы и для b, и для c, но для c — немного выше благодаря меньшему количеству слов. Чтобы построить векторы на основе этих данных, сделаем то же самое, что и с TF-IDF.
Опять же, как и в случае с векторами TF-IDF, эти векторы разрежены. Мы не сможем кодировать семантическое [смысловое] значение, вместо этого сосредоточимся на синтаксисе.
Теперь давайте посмотрим, как можно начать рассматривать семантику.
3. BERT
BERT (Bidirectional Encoder Representations from Transformers) — это чрезвычайно популярная модель трансформатора, в NLP она используется почти для всего. Посредством 12 (или около того) уровней кодера BERT кодирует огромное количество информации в набор плотных векторов.
Каждый плотный вектор обычно содержит 768 значений, и мы обычно имеем 512 таких векторов для каждого закодированного BERT предложения. Эти векторы содержат то, что мы можем рассматривать как числовые представления языка. Эти векторы также возможно извлечь (если этого захочется) из разных слоёв, но обычно из последнего слоя. Теперь, имея два правильно закодированных плотных вектора, мы можем использовать метрику сходства, такую как косинусное сходство, чтобы рассчитать теперь уже семантическое сходство. Более выровненные векторы семантически схожи, и наоборот.
 Меньший угол между векторами (рассчитанный с помощью косинусного сходства) означает, что они более выровнены. Для плотных векторов это коррелирует с большим семантическим сходством
Меньший угол между векторами (рассчитанный с помощью косинусного сходства) означает, что они более выровнены. Для плотных векторов это коррелирует с большим семантическим сходствомНо есть одна проблема: каждая последовательность представлена 512 векторами — не одним вектором. Вот здесь-то и появляется ещё одна — блестящая — адаптация BERT. Sentence-BERT позволяет нам создать один вектор, который представляет нашу полную последовательность, иначе известную как вектор предложений[2]. У нас есть два способа реализации SBERT: простой способ с использованием библиотеки sentence-transformers или уже не столько простой способ с использованием transformers и PyTorch.
Рассмотрим оба варианта, начиная с подхода через transformers и PyTorch, чтобы получить интуитивное представление о построении векторов. Если вы уже использовали библиотеку трансформаторов HF, первые несколько шагов покажутся вам очень знакомыми: инициализируем SBERT и токенизатор, токенизируем наш текст и обработаем токены моделью.
Мы добавили сюда новое предложение, предложение g несёт тот же семантический смысл, что и b, — без тех же ключевых слов. Из-за отсутствия общих слов все наши предыдущие методы не смогли бы найти сходство между этими двумя последовательностями — запомните это на будущее.
У нас есть векторы длины 768, но это не векторы предложений, так как мы имеем векторное представление каждой лексемы в последовательности (поскольку мы работаем SBERT, их здесь 128, а в случае BERT их 512). Для создания вектора предложений нам необходимо выполнить вычислить среднее значение.
Первое, что мы делаем, — умножаем каждое значение в тензоре embeddings на соответствующее значение attention_mask. Маска attention_mask содержит единицы там, где у нас есть «настоящие токены» (например, не токен заполнения), и нули в других местах — эта операция позволяет нам игнорировать ненастоящие токены.
И вот наши векторы предложений, при помощи которых мы можем измерить сходство, вычислив косинусное сходство между всеми векторами.
Визуализировав массив, можно легко определить предложения с более высоким уровнем сходства:
 Тепловая карта, показывающая косинусное сходство между нашими векторами предложений SBERT: обведена оценка между предложениями b и g
Тепловая карта, показывающая косинусное сходство между нашими векторами предложений SBERT: обведена оценка между предложениями b и gТеперь вспомните замечание о том, что предложения b и g имеют по сути одинаковый смысл, но не имеют ни одного одинакового ключевого слова. Мы надеемся, что SBERT с его превосходными семантическими представлениями языка определит эти два предложения как похожие — и вот, пожалуйста, сходство между ними составляет 0,66 балла (обведено выше). Итак, альтернативный (простой) подход заключается в применении SBERT. Чтобы получить точно такой же результат, как выше, напишем:
Что, конечно, гораздо проще. На этом завершаем прогулку по истории с Жаккаром, Левенштейном и Bert!
Ссылки[1] Market Capitalization of Alphabet (GOOG), Companies Market Cap.
[2] N. Reimers, I. Gurevych, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019), Proceedings of the 2019 Conference on Empirical Methods in 2019.
Репозиторий блокнотов
Эта статья — живая иллюстрация развития технологий анализа текста и искусственного интеллекта. Если вы не хотите оставаться в стороне от области ИИ, то вы можете обратить внимание на наш курс «Machine Learning и Deep Learning». Или же прокатайтесь в работе с данными на нашем курсе о Data Science.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Другие профессии и курсыПРОФЕССИИ
КУРСЫ
