[Перевод] Рушим капчу SilkRoad
 Silk Road, знаменитый черный рынок, был закрыт около года назад. До недавнего времени я думал, что он мертв. Это бы облегчило написание статьи, но не все так хорошо. Я только что прочитал о его возвращении в сеть.
Silk Road, знаменитый черный рынок, был закрыт около года назад. До недавнего времени я думал, что он мертв. Это бы облегчило написание статьи, но не все так хорошо. Я только что прочитал о его возвращении в сеть.
Сейчас я хочу углубиться в код, который был написан мною несколько лет назад, чтобы разобрать механизм чтения капчи «старой» версии сайта.
МотивацияВпервые я услышал о The Silk Road в статьях gwern’a. После подключения Tor я получил возможность увидеть этот сайт.Моя первая мысль такова: здесь много интересных рыночных данных в реальном времени, к которым сложно получить доступ программно.
Неужели это Drug Wars с реальным обновлением цен?
Индексы, которые показывают MJ ▲0.21, COKE ▼3.53?
Через некоторое время я бы мог собрать историю изменения цен на все эти товары.
Я уже начал представлять себе графы, схемы и случаи Sr: Listing. Для начала нам нужно автоматизировать процес авторизации.
Весь код в этой статье будет представлен на языке Ruby, но API публиковать я не буду по двум причинам:
Скорее всего, оно просто уже не работает; Оно никогда не было опрятно оформлено. Tor Silk Road был переделан в скрытый сервис TOR. Значит, наше API должно обращаться к Tor.Vidalia открывает локально SOCKS5 прокси при запуске. Необходимо настроить клиент для верных HTTP запросов. К счастью, socksify gem позволяет нам это сделать. Этот трюк позволит нам преобразовывать запросы SOCKS в нашем приложении auto_configure.
require 'socksify' require 'socksify/http'
module Sr
class TorError < RuntimeError; end
class Tor # Loads the torproject test page and tests for the success message. # Just to be sure. def self.test_tor? uri = 'https://check.torproject.org/? lang=en-US' begin page = Net: HTTP.get (URI.parse (uri)) return true if page.match (/browser is configured to use Tor/i) rescue ; end
false end
# Our use case has the Tor SOCKS5 proxy running locally. On unix, we use # `lsof` to see the ports `tor` is listening on. def self.find_tor_ports p = `lsof -i tcp | grep »^tor» | grep »\(LISTEN\)»` p.each_line.map do |l| m = l.match (/localhost:([0–9]+) /) m[1].to_i end end
# Configures future connections to use the Tor proxy, or raises TorError def self.auto_configure! return true if @configured
TCPSocket: socks_server = 'localhost'
ports = find_tor_ports
ports.each do |p| TCPSocket: socks_port = p if test_tor? @configured = true return true end end
TCPSocket: socks_server = nil TCPSocket: socks_port = nil fail TorError, «SOCKS5 connection failed; ports: #{ports}» end end end Все готово. Мы создали довольно простой процесс.Капча Теперь мы переходим к теме статьи: обход капчи SilkRoad.Я никогда раньше этого не делал, поэтому должно быть интересно. Весь приведенный код — это результат шестичасовой работы.
Я решил назвать проект успешным, если приложение будет распознавать текст с точностью до одной трети всех кодов.
В итоге получилось сделать нечто большее, чем планировалось.
Из-за того, что авторы Silk Road должны были развить в себе паранойю, они не могли использовать сервисы типа reCAPTCHA. Я не уверен, что их решение в итоге оказалось самописным, но давайте посмотрим на несколько примеров:





Есть несколько очевидных особенностей этого капчи:
Стандартный формат: словарное слово, обрезанное до пяти символов, вместе с числом от 0 до 999; Шрифт никогда не меняется; Любой сивол может быть на любой позиции по оси Х; Любой сивол может быть повернут, но лишь на несколько градусов; На заднем плане наблюдается что-то типа спирали, не больно контрастирующее с текстом; Они все ужасные и розовые, что дает нам один канал цветовой информации. Я написал Mechanize, который скачал 2,000 примеров капч с сайта с интервалом в две секунды. После я решил их вручную, называя в формате (текст).jpg. Это было очень даже грустно, поверьте.Зато есть и плюсы: я получил много образцов для тестов в моем новом приложении.
Убираем фон Самый, на мой взгляд, верный шаг для старта. На данном этапе я хотел получить изображения в оттенках серого, содержащих лишь только символы (желательно), а также отсеивание всех «шумов» изображения.Используя Gimp, я поиграл с несколькими эффектами и несколькими их последовательностями. У меня были ошибки, но, в конечном счете, я получил вот это:
Оригинал:
Откорректированная:

Оттенки серого, 0.09: 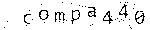
Результат был получен следующим кодом для RMagick:
# Basic image processing gets us to a black and white image # with most background removed def remove_background (im) im = im.equalize im = im.threshold (Magick: MaxRGB * 0.09)
# the above processing leaves a black border. Remove it. im = im.trim '#000' im end Это освободило наше изображение от ненужных деталей, но все же остался «мусор» — маленькие черные точки между буквами. Давайте избавимся от них:
# Consider a pixel «black enough»? In a grayscale sense. def black?(p) return p.intensity == 0 || (Magick: MaxRGB.to_f / p.intensity) < 0.5 end
# True iff [x, y] is a valid pixel coordinate in the image def in_bounds?(im, x, y) return x >= 0 && y >= 0 && x < im.columns && y < im.rows end
# Returns new image with single-pixel «islands» removed, # see: Conway’s game of life. def despeckle (im) xydeltas = [[-1, -1], [0, -1], [+1, -1], [-1, 0], [+1, 0], [-1, +1], [0, +1], [+1, +1]]
j = im.dup j.each_pixel do |p, x, y| if black?(p) island = true
xydeltas.each do |dx2, dy2| if in_bounds?(j, x + dx2, y + dy2) && black?(j.pixel_color (x + dx2, y + dy2)) island = false break end end
im = im.color_point (x, y, '#fff') if island
end end
im
end
Итак, мы получили нечто подобное: 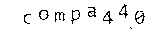
Замечательно.
Сегментация Теперь я хочу разрезать нашу капчу на растровые изображения, чтобы каждое содержало по одному символу. Мы перемещаемся по картинке слева направо, выискивая белые отступы. # returns true if column «x» is blank (non-black) def blank_column?(im, x) (0 … im.rows).each do |y| return false if black?(im.pixel_color (x, y)) end
true end
# finds columns of white, and splits the image into characters, yielding each def each_segmented_character (im) return enum_for (__method__, im) unless block_given?
st = 0 x = 0 while x < im.columns # Zoom over to the first non-blank column x += 1 while x < im.columns && blank_column?(im, x)
# That’s now our starting point. st = x
# Zoom over to the next blank column, or end of the image. x += 1 while x < im.columns && (!blank_column?(im, x) || (x - st < 2))
# slivers smaller than this can’t possibly work: it’s noise.
if x — st >= 4
# The crop/trim here also removes vertical whitespace, which puts the
# resulting bitmap into its minimal bounding box.
yield im.crop (st, 0, x — st, im.rows).trim ('#fff')
end
end
end
Это обрезает нашу капчу на таки вот куски: 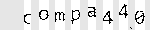
Далее каждый кусок превращается в отдельный квадратик с буквой, тем самым отделяясь от других.
Я выполнял данный код для множества заготовленных ранее капч, и вот что получилось в некоторых случаях:

Подумайте об этом как о гистограмме. Темные участки — это места, где алгоритм резал изображение. Вы можете наблюдать смещения…
Мы также видим то, как вращение символов влият на четкость полученного результата. Если бы символы вращались под большим углом, то наша задача существенно бы усложнилась.
Итак, каждый символ вполне возможно прочитать. Так как буквы взяты из английского словаря, то более часто используемые символы видны четче. Мы рассмотрим этот вопрос позднее.
Но не знал, что J используется настолько редко!
Нейронные сети для распознавания символов Существует классный gem для Ruby под названием AI4R. Так как Ai4r: Positronic не всегда был доступен, я решил использовать нейронную сеть.Вы начинаете с пустого массива битов. Вы обучаете его рисунками из известных решений:
«Такая модель представляет собой А.», «А эта модель тоже есть в А.» «Эта модель встречается в В.» После проверки по множеству примеров, появляются несколько подходящих символов-кандидатов, и сеть вам скажет верный вариант, используя свою базу.Но есть и сложности. Чем больше у Вас символов и чем больше параметров для распознавания Вы указываете, тем дольше нужно тренировать алгоритм.
Я взял каждый символ в квадраты, сделал его размером 20×20 и применил монохромный эффект, и начал тренировки.
require 'ai4r' require 'RMagick'
module Sr class Brain def initialize @keys = *(('a'…'z').to_a + ('0'…'9').to_a) @ai = Ai4r: NeuralNetwork: Backpropagation.new ([GRID_SIZE * GRID_SIZE, @keys.size]) end
# Returns a flat array of 0 or 1 from the image data, suitable for # feeding into the neural network def to_data (image) # New image of our actual grid size, then paste it over padded = Magick: Image.new (GRID_SIZE, GRID_SIZE) padded = padded.composite (image, Magick: NorthWestGravity, Magick: MultiplyCompositeOp)
padded.get_pixels (0, 0, padded.columns, padded.rows).map do |p| ImageProcessor.black?(p) ? 1: 0 end end
# Feed this a positive example, e.g., train ('a', image) def train (char, image) outputs = [0] * @keys.length outputs[ @keys.index (char) ] = 1.0 @ai.train (to_data (image), outputs) end
# Return all guesses, e.g., {'a' => 0.01, 'b' => '0.2', …} def classify_all (image) results = @ai.eval (to_data (image)) r = {} @keys.each.with_index do |v, i| r[v] = results[i] end r end
# Returns best guess def classify (image) res = @ai.eval (to_data (image)) @keys[res.index (res.max)] end end end Я изменил мой инструмент Mechanize для загрузки новых капч. На этот раз капчи решал алгоритм, после чего выполнял авторизацию в системе.
Правильно угаданные коды автоматически разбивались посимвольно на квадраты и добавлялись в базу примеров для улучшения знаний приложения.
Когда попытка авторизации проваливалась, капча отправлялась отдельную папку, чтобы я решал ее самостоятельно. Как только я менял название капчи на ее ответ, алгоритм забирал изображение, делил его на квадраты и пополнял свою базу. Время от времени мне приходилось решать пару десятков примеров.
После нескольких часов тренировок процент успешно решенных задач составлял 90%.
К сожалению, длина капчи обычно равнялась восьми символам, поэтому, вероятность удачного решения была 0.90 ** 8, или 43%. Моя изначальная цель была достигнута, но хотелось большего.
Использование словаря и частоты использования букв Временами наша сеть выдавала странных кандидатов решения, не соответствующих действительности. Что-то странное, что не соответствовало формату. Она распознавала символы независим и объединяла результат без дальнейшего контекста.Но «словесная» часть капчи была не рандомными буквами, а именно частями реальных слов. Обрезанных слов из специального списка. Если бы у меня был лист, то можно бы было построить логическую цепочку рассуждений для улучшения результата распознавания символов. Вот так я генерировал свой список слов:
cat /usr/share/dict/words *.txt | tr A-Z a-z | grep -v '[^a-z]' \ | cut -c1–5 | grep '…' | sort | uniq > dict5.txt После я мог предположить, что dict5.txt содержал все возможные варианты, которые могла содержать капча.
# Returns the «word» and «number» part of a captcha separately. # «word» takes the longest possible match def split_word (s) s.match (/(.+?)?(\d+)?\z/.to_a.last (2) rescue [nil, nil] end
def weird_word?(s) w, d = split_word (s)
# nothing matched? return true if w.nil? || d.nil?
# Digit in word part?, Too long? return true if w.match /\d/ || w.size > 5
# Too many digits? return true if d.size > 3
# Yay return false end
def in_dict?(w) return dict.bsearch { |p| p >= w } == w end Но как же исправить странные слова, которые отсутствуют в словаре?
Первой моей мыслью было заглянуть в список кандидатов системы, но дело было в другом. Скрипт выполнял некачественную сегментацию, увы
Давайте взглянем на эту интересную таблицу:
# a-z English text letter frequency, according to Wikipedia LETTER_FREQ = { a: 0.08167, b: 0.01492, c: 0.02782, d: 0.04253, e: 0.12702, f: 0.02228, g: 0.02015, h: 0.06094, i: 0.06966, j: 0.00153, k: 0.00772, l: 0.04025, m: 0.02406, n: 0.06749, o: 0.07507, p: 0.01929, q: 0.00095, r: 0.05987, s: 0.06327, t: 0.09056, u: 0.02758, v: 0.00978, w: 0.02360, x: 0.00150, y: 0.01974, z: 0.00074 } Заметили наше бедное и редко используемое J снова?
Peter Norvig написал интересную статью Как написать корректор произношения. У нас есть словарь и, предположительно, слово с опечаткой. Давайте это исправим:
# This finds every dictionary entry that is a single replacement away from # word. It returns in a clever priority: it tries to replace digits first, # then the alphabet, in z…e (frequency) order. As we’re just focusing on the # «word» part,»9» is most definitely a mistake, and «z» is more likely a # mistake than «e».
def edit1(word) # Inverse frequency, «zq…e» letter_freq = LETTER_FREQ.sort_by { |k, v| v }.map (&: first).join
# Total replacement priority: 0…9zq…e replacement_priority = ('0'…'9').to_a.join + letter_freq
# Generate splits, tagged with the priority, then sort them so # the splits on least-frequent english characters get processed first splits = word.each_char.with_index.map do |c, i| # Replace what we’re looking for with a space w = word.dup; w[i] = ' ' [replacement_priority.index©, w] end splits.sort_by!{|k, v| k}.map!(&: last)
# Keep up with results so we don’t end up with duplicates yielded = [] splits.each do |w| letter_freq.each_char do |c| candidate = w.sub (' ', c) next if yielded.include?(candidate)
if in_dict?(candidate) yielded.push (candidate) yield candidate end end end end Большая хитрость заключается в замене. Используя таблицу частоты использования символов и список возможных слов, которые отличаются лишь одним символом от предложенных сетью вариантов, мы просто заменяем символ на нужный, чтобы исправить «опечатку».
Этот шаг увеличил процент успешных решений с 43% до 56%. Это заставило меня понять, что цель реально достигнуто.
Скоро будет опубликована статья о взломе новой (второй) капчи SilkRoad. Не пропустите!
За идею статьи спасибо ilusha_sergeevich
