[Перевод] Руководство по аппаратному обеспечению для глубокого обучения
Примечание переводчика: На Хабре и в нашем блоге о корпоративном IaaS мы много пишем об облачных технологиях, и рассматриваем интересные инфраструктурные проекты различных компаний и исследователей. Мы уже рассказывали о масштабировании Apache Storm в Spotify и создании технологий для стриминга видео, а сегодня представляем вашему вниманию рассказ немецкого математика Тима Деттмерса о том, какое «железо» стоит выбрать для осуществления проектов по глубокому обучению.
Глубокое обучение — это процесс, требующий больших вычислительных мощностей, поэтому вам потребуется быстрый процессор с большим количеством ядер. Или покупать процессор совершенно необязательно? Нет ничего хорошего в том, чтобы тратить деньги на покупку ненужного аппаратного обеспечения при сборке системы глубокого обучения. Сейчас я шаг за шагом хочу провести вас по основным компонентам, которые потребуются для создания дешевой и высокопроизводительной системы.
Работая над распараллеливанием процессов глубокого обучения, я собрал себе кластер из видеокарт, для которого я тщательно выбирал оборудование. Несмотря на проводимое мною исследование и следующие из него умозаключения, я допустил множество ошибок в выборе аппаратных компонентов, которые обнаруживались только после проверки работы кластера на практике. Сейчас я хочу помочь вам избежать ловушек, в которые я попался, и поделиться своим опытом.
Графический процессор (ГП)
Этот пост предполагает, что для глубокого обучения вы будете использовать графический процессор. Создавая подобную систему, очень неблагоразумно обходить его стороной. Графический процессор — это сердце приложений глубокого обучения. Повышение производительности, которое он дает, слишком велико, чтобы его игнорировать.
Я подробно рассказывал о выборе графического процессора в своем предыдущем посте, и, считаю, что вероятно, это самое важное решение, которое вы принимаете при сборе системы глубокого обучения. Обычно, если у вас мало денег, я рекомендую брать GTX 680 на eBay. Если деньги есть, то лучшими графическими процессорами на данный момент будут GTX Titan X (для свертки) или GTX 980 (лучшее решение за свои деньги; имеет ограничения для очень больших сверточных нейронных сетей). GTX Titan с eBay отлично подойдет, если вам нужна дешевая память. Ранее я поддерживал GTX 580, но обновление библиотеки cuDNN значительно увеличило скорость свертки, поэтому все графические процессоры, которые её не поддерживают, потеряли свою актуальность. GTX 580 не поддерживает cuDNN, однако если вы не занимаетесь сверточными сетями, то это по-прежнему достойный выбор.

Подозреваемые
Можете определить «железо», виновное в плохой производительности? Это одна из этих графических карточек? Или во всем виноват центральный процессор?
Центральный процессор (ЦП)
Чтобы выбрать правильный центральный процессор, нам нужно понять, что это такое, и какое он имеет отношение к глубокому обучению. Что делает процессор во время глубокого обучения? Во время работы глубокой нейросети центральный процессор выполняет очень мало вычислений, но по-прежнему производит нижеследующее:
- Запись и чтение переменных в коде;
- Выполнение инструкций, например, вызов функций;
- Инициализацию функциональных вызовов к графическому процессору;
- Формирование mini-batch выборки;
- Передачу параметров графическому процессору.
Необходимое число ядер процессора
Когда я провожу обучение глубоких нейронных сетей, используя три разные библиотеки, то всегда замечаю, что один поток процессора постоянно загружен на 100% (периодически другие потоки также загружаются на 100%). Это говорит нам о том, что большинство библиотек глубокого обучения (как и большинство приложений) используют всего один поток. Это означает, что многоядерные процессоры бесполезны. Однако они могут вам пригодиться для запуска нескольких программ одновременно, если вы работаете с фреймворками, использующими параллельные вычисления, как, например, MPI. Вам должно хватить одного потока на графический процессор, но два потока на графический процессор повысят производительность при использовании большинства библиотек глубокого обучения; каждая библиотека работает с одним ядром, но, иногда, осуществляет асинхронный вызов функций, для чего задействуется второй поток. Помните, что многие процессоры могут обрабатывать несколько потоков на одном ядре (в особенности процессоры Intel), поэтому одного ядра на графический процессор часто бывает достаточно.
Центральный процессор и PCI-Express
Это ловушка. Некоторые из новых процессоров Haswell, в отличие от старых, не поддерживают 40 полос PCIe — избегайте этих процессоров, если хотите собрать систему с несколькими графическими процессорами. Если материнская плата имеет поддержку PCIe 3.0, то убедитесь, что процессор также его поддерживает.
Размер кэша центрального процессора
Как мы увидим позднее, размер кэша процессора не играет большой роли при обмене данными между ЦП и ГП, но я включил короткий обзор, дабы убедится, что рассмотрены все возможные проблемные места, и понятен весь процесс.
Люди, покупая процессор, часто не обращают внимания на кэш, но это достаточно важный аспект, сильно влияющий на производительность. Кэш — это небольшой блок памяти, расположенной на кристалле, которая физически располагается очень близко к процессору и используется для быстрого выполнения вычислений и других операций. Процессор часто имеет целую иерархию кэшей: маленькие, но быстрые кэши (L1, L2), и большие, но медленные (L3, L4). Как программист, вы можете представить себе кэш в виде хэш-таблицы, где каждая строка — это пара ключ-значение, и где можно проводить быстрый поиск по ключу. Если ключ найден, то можно прочитать или записать переменную; если ключ не обнаружен (это называется промахом), то ЦП нужно обратиться к оперативной памяти и прочитать значение оттуда — этот процесс происходит гораздо медленнее. Повторяющиеся промахи кэша ведут к серьезному снижению производительности. Эффективные архитектуры и процедуры кэширования часто оказывают серьезное влияние на производительность процессора.
Как процессор выполняет кэширование? Сложный вопрос, но вы должны знать, что в кэше хранятся переменные, инструкции и адреса оперативной памяти, которые используются чаще других.
В глубоком обучении для обработки каждой mini-batch выборки перед её отправкой в графический процессор (память просто перезаписывается) читается один и тот же участок памяти, и ответ на вопрос, сможет ли эта память поместиться в кэш, зависит только от размера mini-batch. При размере выборки, равном 128, мы получаем 0,4 Мб и 1,5 Мб для MNIST и CIFAR соответственно, что поместится в большинство кэшей процессоров. Для ImageNet mini-batch займет более 85 Мб (4×128 X 2442×3 X 1024–2), что значительно превышает даже самый большой кэш (кэш третьего уровня ограничен несколькими мегабайтами).
Так как наборы данных, обычно, слишком большие, чтобы уместиться в кэше, для каждой новой mini-batch данные приходится читать из памяти — поэтому в любом случае понадобится постоянный доступ к оперативной памяти.
Адреса оперативной памяти хранятся в кэше (процессор может быстро просматривать кэш и находить адреса, точно указывающие на месторасположение данных в оперативной памяти), но только в том случае, если весь набор данных помещается в оперативную память, иначе адреса будут меняться, и никакого ускорения от кэширования мы не получим (можно предотвратить это с помощью заблокированных страниц, но, как мы увидим позднее, нет смысла это делать).
Другие части кода глубокого обучения — обращение к переменным и вызовы функций — будут выполняться быстрее, но обычно это маленькие числа, которые легко помещаются в маленький и быстрый кэш первого уровня практически любого процессора.
Из этого следует, что размер кэша процессора не особо важен, и дальнейший анализ в следующих главах только подтверждает это заключение.
Необходимая частота процессора
Когда люди говорят о быстром процессоре, то первое, о чем они думают — это тактовая частота. 4 ГГц лучше, чем 3,5 ГГц, так ли это? Это верно только в том случае, если сравнивать процессоры с одинаковой архитектурой, например, Ivy Bridge. Тактовая частота не всегда является оптимальной мерой производительности.
В процессе глубокого обучения ЦП практически не производит вычислений: увеличивает пару переменных тут, вычисляет булево выражение там, совершает несколько функциональных вызовов в графический процессор или внутри программы — скорость выполнения этих операций зависит от частоты процессора.
Все выглядит вполне разумно, однако во время запуска программ глубокого обучения центральный процессор загружается на 100%, так в чем здесь проблема? Чтобы понять причину, я провел несколько экспериментов, уменьшив частоту процессора (андерклокинг):
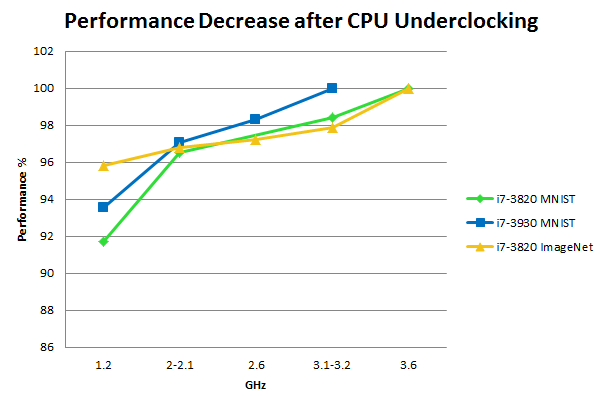
Андерклокинг на базах MNIST и ImageNet: Производительность измерялась за время формирования 200 эпох MNIST или 25 эпох на ImageNet с ядрами различной частоты, где максимальная тактовая частота бралась как основная для каждого ЦП. Для сравнения: апгрейд с GTX 680 до GTX Titan дает прирост производительности около 15%; с GTX Titan до GTX 980 еще 20%; оверклокинг прибавляет еще около 5% производительности любому процессору.
Так почему ЦП используется на 100%, если его тактовая частота практически не оказывает влияния на производительность? Ответом могут послужить промахи кэша: ЦП постоянно занят обращениями к памяти (которая имеет меньшую частоту) и вынужден дожидаться, пока она обработает запрос — это ведет к парадоксально огромным задержкам. Если все так, то андерклокинг частоты процессора не должен сильно повлиять на производительность — что подтверждают результаты, которые вы могли видеть выше.
Центральный процессор также управляет и другими операциями, например, копированием данных в mini-batch и подготовкой данных к передаче в графический процессор, но все это зависит от частоты оперативной памяти, а не от частоты самого процессора. Поэтому давайте перейдем к памяти.
Необходимая частота оперативной памяти
Все взаимодействия, в частности, взаимодействие процессора, с оперативной памятью довольно сложны. Сейчас я попробую упростить. Давайте рассмотрим поподробнее процесс работы с памятью графического и центрального процессоров, чтобы лучше разобраться в ситуации.
Частоты работы ЦП и оперативной памяти связаны. Частота работы процессора определяет максимальную частоту работы оперативной памяти, и обе эти частоты определяют результирующую пропускную способность памяти процессора. Чаще всего пропускную способность определяет только оперативная память, так как она работает медленнее памяти процессора. Вы можете определить пропускную способность следующим образом:
Частота RAM в гигагерцах x каналы памяти CPU x 64×8–1
Где 64 означает 64-битную архитектуру. Для моих процессоров и планок оперативной памяти пропускная способность составила 51,2 Гб/сек.
Однако пропускная способность имеет значение только тогда, когда вы копируете большие объемы данных. Тайминги (например, 8–8–8) оперативной памяти обычно оказываются более важными при обработке небольших кусков данных. Они определяют, как долго процессор должен ожидать ответа от памяти. Но, как я уже отмечал выше, практически все данные вашей программы глубокого обучения или будут легко помещаться в кэш процессора, или будут слишком большими и поэтому не получат никакой выгоды от кеширования. В связи с этим, можно сказать, что пропускная способность важнее таймингов.
Какое отношение имеет все это к программам глубокого обучения? Я просто упомянул, что пропускная способность может быть важна, но далее мы увидим, что это не так. Давайте пойдем дальше. Пропускная способность оперативной памяти определяет, насколько быстро может быть переписана и размещена mini-batch, чтобы можно было начать инициализацию передачи данных графическому процессору. Здесь мы снова упираемся в ограничение, так как память ЦП и ГП взаимодействует в режиме прямого доступа к памяти (ПДП). Как было отмечено выше, пропускная способность моих модулей оперативной памяти составляет 51,2 Гб/сек, а скорость обмена в режиме ПДП — всего лишь 12 Гб/сек.
Пропускная способность ПДП связана с обычной пропускной способностью, но сейчас детали не важны, поэтому я просто дам вам ссылку на страницу Википедии, где вы сможете посмотреть пропускную способность модулей оперативной памяти в режиме ПДП (пиковая скорость передачи). Но давайте посмотрим, как он работает.
Прямой доступ к памяти (ПДП)
ЦП может общаться с графическим процессором только с помощью ПДП. На первом этапе в памяти ЦП и ГП резервируется специальный буфер передачи. На втором этапе ЦП записывает запрашиваемые данные в свой ПДП буфер. На третьем этапе этот буфер передается в память ГП — в этот процесс ЦП не вмешивается. Пропускная способность вашей шины PCIe (PCIe 2.0) равна 8 Гб/сек или 15,75 Гб/сек (PCIe 3.0), поэтому из того, что сказано выше, следует, что вы должны выбирать оперативную память с высокой пиковой скоростью передачи данных, так?
Необязательно. Здесь большую роль играет программное обеспечение. Если будете правильно осуществлять передачу, то сможете обойтись более дешевой и медленной памятью. Вот что нужно сделать.
Асинхронное распределение mini-batch
Когда ГП завершил работу с текущей mini-batch, он хочет незамедлительно начать работу над следующим набором данных. Разумеется, сейчас вы можете инициировать ПДП передачу, а затем ждать её завершения, чтобы ГП мог продолжить обрабатывать цифры. Но существует гораздо более эффективный способ: подготовьте следующую mini-batch выборку заранее, чтобы вашему графическому процессору не пришлось ждать. Это можно легко сделать асинхронно и без потерь в производительности.

Код CUDA для асинхронного распределения mini-batch: Первые два вызова выполняются, когда ГП начинает работать с mini-batch; последние два вызова выполняются, когда ГП закончил обработку mini-batch. Передача данных будет завершена задолго до завершения всех операций потока, поэтому задержки перед началом обработки следующей mini-batch не возникнет.
Сверточной сети Алекса Крижевского (Alex Krishevsky) требуется 0,35 секунд, чтобы выполнить полный проход по методу обратного распространения ошибки с mini-batch ImageNet 2012 размером 128. Сможем ли мы предоставить следующую mini-batch выборку за это время?
Если мы примем размер mini-batch равным 128, а размеры данных 244×244x3, то в сумме получим около 0,085 Гб (4×128 x 2442×3 x 1024–3). С супермедленной памятью мы получим скорость 6,4 Гб/сек или 75 mini-batch в секунду. Так что, если использовать асинхронный метод распределения mini-batch, то даже самая медленная оперативная память подойдет для глубокого обучения. Если вы используете этот способ, то покупка более быстрых модулей оперативной памяти не приведет к увеличению производительности.
Это косвенно указывает на то, что кэш процессора не играет особой роли. Неважно, насколько быстро ваш ЦП может перезаписать данные (в быстром кэше) и подготовить (записать из кэша в память) mini-batch для ПДП передачи, потому что передача закончится задолго до того, как графический процессор затребует новые данные — большой кэш не так важен.
Подведем итоги: частота оперативной памяти не имеет значения. Покупайте то, что дешевле. Но сколько всего вы должны купить?
Размеры оперативной памяти
Вы должны иметь объем оперативной памяти, который был бы не меньше объема памяти графического процессора. Можно работать и с меньшим её количеством, но вам может потребоваться осуществить пошаговую передачу данных. Однако из собственного опыта скажу, что гораздо удобнее работать с большими объемами памяти.
Психология говорит нам, что концентрация — это такая вещь, которая со временем снижается. Оперативная память — это один из нескольких аппаратных модулей, который позволяет вам сохранить вашу концентрацию для более сложных проблем программирования. Вместо того, чтобы тратить кучу времени на борьбу с нехваткой оперативной памяти, вы можете направить эти усилия на другие цели, просто увеличив её количество. Если памяти много, можно избежать массы проблем, сохранить время и увеличить продуктивность, занявшись решением более сложных вопросов. Работая в Kaggle, я понял, что дополнительная оперативная память очень помогает в подготовке наборов оптимальных параметров (feature engineering). Так что если вы часто выполняете первичную обработку, и у вас есть деньги, то дополнительная память — это отличное приобретение.
Жесткий диск/SSD
В некоторых случаях жесткий диск может серьезно снижать производительность. Если у вас большой набор данных, то, скорее всего, вы будете хранить одну его часть на жёстком диске или SSD, другую часть в оперативной памяти и третью часть (две небольшие выборки) в памяти графического процессора. Чтобы ГП постоянно получал данные, нам нужно обеспечить поступление новых mini-batch с такой же частотой, с какой ГП сможет их обрабатывать.
Для этого воспользуемся той же идеей с асинхронным размещением mini-batch. Нам нужно асинхронно читать файлы с группами mini-batch — это очень важно! Если не делать это асинхронно, то производительность упадет на 5–10% и сведет на нет все преимущества, за которые вы так боролись — хорошо настроенное глубокое обучение будет работать быстрее на GTX 680, чем плохо настроенное — на GTX 980.
В случае со сверточной сетью ImageNet Алекса выходит, что нам нужно читать 0,085 Гб (4×128 x 2442×3 x 1024–3) каждые 0,3 секунды, что равно 290 МБ/сек, если мы сохраняем данные как 32-битные числа с плавающей точкой. Если мы сохранили данные в формате jpeg, то можем сжать их 5–15-кратной сверткой, получив требуемую пропускную способность около 30 МБ/сек. Стандартная скорость жестких дисков составляет 100–150 Мб/сек — этого будет достаточно для данных, сжатых в формате jpeg. Для звуковых файлов можно использовать mp3 или другие методы сжатия, но для наборов данных, представленных в виде 32-битных чисел с плавающей точкой, подобное сжатие невозможно: мы можем уменьшить их объем только на 10–15%. Так что если вы работаете с большим набором 32-битных данных, то вам определенно понадобится SSD, так как жесткие диски со скоростью 100–150 Мб/сек слишком медленные и не будут поспевать за ГП. Если у вас такие наборы данных, то берите SSD, в противном случае можете смело работать с жесткими дисками.
Многие люди покупают SSD просто для удобства: запуск и отклик программ, а также предобработка больших файлов выполняется быстрее, но для глубокого обучения он необходим только в том случае, если размерность входных данных велика, и вы не можете их эффективно сжать.
Если вы покупаете SSD, выбирайте его так, чтобы он вместил наборы данных, с которыми вы работаете, с дополнительными несколькими десятками гигабайт буферного пространства. Хорошей идеей будет подключить жесткий диск, на котором будут храниться неиспользуемые наборы данных.
Блок питания (БП)
Вам нужен БП, способный обеспечить работу всех ваших будущих графических процессоров. Со временем ГП становятся все более энергоэффективными, БП, в отличие от остальных компонентов, не будет меняться довольно долго, поэтому имеет смысл в него вложиться.
Вы можете просчитать необходимое число ватт, сложив мощность ЦП и всех ГП с дополнительными 100–300 ваттами, которые понадобятся для других компонентов и выступят в качестве резерва при скачках напряжения.
Важно проверить, чтобы разъемы питания PCIe вашего БП имели 8-контактный и 6-контактный коннектор на одном кабеле. Как-то я купил БП, который мог запитать 6 PCIe-портов, но мог подавать напряжение или только на 8-контактный, или только на 6-контактный коннекторы. С тем блоком питания я не мог подключить 4 графических процессора.
Также очень важно приобретать БП с высоким КПД, особенно если у вас подключено множество графических процессоров, работающих длительное время.
Система с 4 графическими процессорами, работающими на полной мощности (1000–1500 ватт) и тренирующими сверточную сеть на протяжении двух недель, накрутит 300–500 кВт/ч, что в Германии, стране с достаточно высокой стоимостью электроэнергии (20 евроцентов за кВт/ч), будет стоить вам €60–100 ($66–111). Если такая стоимость получается при 100% КПД, то тренировка подобной сети при КПД равном 80% увеличит стоимость на €18–26 — ой-ёй! При работе с одним графическим процессором увеличение стоимости менее заметно, но тенденция ясна — поэтому стоит потратить чуть больше денег на эффективный БП.
Охлаждение
Охлаждение очень важно и может влиять на производительность в большей степени, чем это делает плохое аппаратное обеспечение. Центральный процессор должен работать нормально со стандартным радиатором, но графическому процессору следует уделить отдельное внимание.
Во время работы алгоритма современные ГП повышают свою частоту и энергопотребление до максимума, но как только температура процессора достигает 80 °C, скорость сбрасывается, чтобы избежать превышения температурного порога. Это гарантирует наилучшую производительность и не дает графическому процессору перегреться.
Однако стандартный план скоростей вращения вентиляторов плохо подходит для программ глубокого обучения, поэтому температурный порог достигается за несколько секунд после старта алгоритма. Это ведет к уменьшению производительности (на несколько процентов), что выливается в потерю 10–25%, если вы используете несколько ГП, поскольку они расположены близко друг от друга и сильно нагреваются.
Так как графические процессоры NVIDIA лучше всех подходят для компьютерных игр, то они оптимизированы под Windows. Вы можете изменить настройки вентилирования всего несколькими кликами, но вот в Linux так не получится, а так как большинство обучающих библиотек написаны для Linux — возникает проблема.
Самый простой и дешевый способ обойти ограничения — это установить прошивку BIOS, имеющую новые, более адекватные настройки вентиляторов, которые сохранят температуру и шумы на приемлемом уровне (Если у вас сервер, то вы можете подкрутить скорость вентиляторов на максимум, но шум будет непереносимый). Вы можете немного «разогнать» частоту ГП на 30–50 МГц — это не повредит системе. Программа для прошивки BIOS написана для Windows, но вы можете использовать wine, чтобы запустить её на операционных системах Linux/Unix.
Другой вариант — это установить в конфигурационном файле сервера Xorg (Ubuntu) опцию «coolbits». Такое решение отлично подойдет для одного ГП, но если у вас их несколько, и не ко всем их них подключен монитор, вам придется его эмулировать, что довольно сложно. Я как-то пытался сделать это, но потом провел долгие утомительные часы с загрузочным диском, восстанавливая графические настройки. Мне так и не удалось корректно настроить карты без мониторов.
Есть другой способ, он более затратный и трудный. Можно использовать водяное охлаждение. Водяное охлаждение практически вдове снизит температуру одного графического процессора даже при максимальной нагрузке, и температурный порог никогда не будет достигнут. Останутся холодными даже несколько ГП, чего не может добиться воздушное охлаждение. Еще одним преимуществом водяного охлаждения является бесшумность, что большой плюс, если несколько ГП работают в помещении с другими людьми. Водяное охлаждение обойдется вам в $100 за каждый графический процессор, плюс, нужно будет добавить сверху около $50. Водяное охлаждение немного сложно в установке, но существует большое количество подробных инструкций и руководств, так что весь процесс займет всего несколько часов. Обслуживание не требует особых усилий и не должно стать проблемой.
По своему опыту скажу, что это — один из самых важных моментов. Я купил большие тауэры для моего кластера глубокого изучения, потому что у них есть дополнительные кулеры в зоне с графическими процессорами, но я понял, что это совершенно излишне: температура упала всего на 2–5 °C, которые не стоят денег, вложенных в огромные корпусы. Очень важно решить вопрос с охлаждением ГП — обновите BIOS, используйте водяное охлаждение или живите с пониженной производительностью — в разных ситуациях, все три решения вполне приемлемы. Просто выберите то, которое подходит именно вам.
Материнская плата и корпус
Материнская плата должна иметь достаточное количество PCIe портов, чтобы на ней можно было закрепить все ГП (обычно ограничиваются 4 ГП, даже если у вас есть больше слотов). Помните, что многие ГП занимают два слота сразу, так что для подключения 4 ГП вам может потребоваться 7 слотов PCIe. PCIe 2.0 подойдет для одного ГП, но PCIe 3.0 обладает лучшими показателями цена/производительность. Для нескольких ГП всегда берите платы с поддержкой PCIe 3.0 — это сыграет вам на руку, когда вы будете проводить мультипроцессорные вычисления, так как PCIe-соединение в этом случае оказывается «узким местом».
Выбор материнской платы — простая задача: выбирайте ту, которая поддерживает нужное вам аппаратное обеспечение.
При выборе корпуса убедитесь, что в него влезут полноразмерные ГП, установленные на материнскую плату. Большинство корпусов позволяют это сделать, но стоит проверить, если вы покупаете небольшой экземпляр. Изучите его размеры и параметры, вы даже можете попробовать найти в Google его изображение с видеокартами внутри.
Мониторы
Сначала я думал, что будет глупо писать про мониторы, но они оказались так важны, что я должен это сделать. Между одним и тремя мониторами — огромная разница.
Три 27-дюймовых монитора — вероятно, лучшее, на что я когда-либо тратил деньги — они многократно увеличивают продуктивность. Я чувствую себя неполноценным, если работаю всего за одним монитором. Не ограничивайте себя в этом. Что хорошего в быстрой системе глубокого обучения, если вы неспособны эффективно ей управлять?
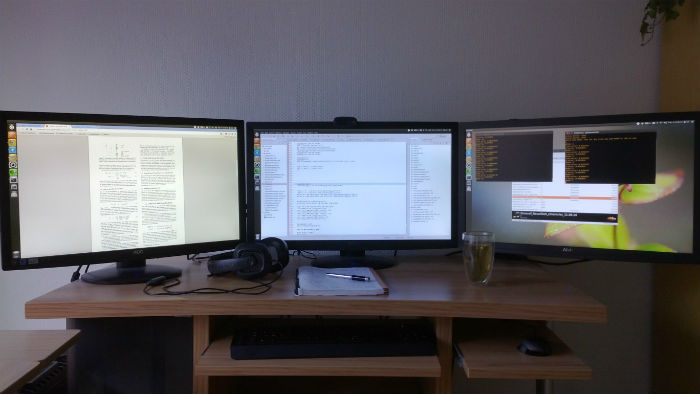
Классическая расстановка мониторов, когда я занимаюсь глубоким обучением: слева — книги, Google, почта, stackoverflow; посередине — код; справа — окна вывода, R, папки, системные мониторы и мониторы графических процессоров, список дел и другие небольшие приложения.
Еще пара слов о сборе ПК
Многих пугает сама мысль о сборке компьютера. Аппаратные компоненты дорогие, и вы боитесь сделать что-то неправильно. Но это просто, так как компоненты, не подходящие друг к другу, нельзя соединить вместе. В руководстве к материнской плате подробно показано, как все подключить, а огромное количество обучающих видео и других источников помогут вам, если у вас нет опыта.
Чтобы разобраться в том, как собирать компьютер, вам достаточно сделать это всего один раз, и это замечательно, так как сборка компьютера станет полезным навыком, который вы сможете применять снова и снова. Нет причин медлить!
Заключение / TL; DR
ГП: GTX 680 или GTX 960 (если нет денег); GTX 980 (лучшая производительность); GTX Titan (если нужна память); GTX 970 (не для сверточных сетей)
ЦП: Два потока на ЦП; поддержка всех 40 полос PCIe и его правильной версии (такой же как для материнской платы); тактовая частота >2ГГц; кэш не имеет значения.
Оперативная память: Используйте асинхронное распределение mini-batch; тактовая частота и тайминги не имеют значения; количество памяти равно количеству графической памяти или больше.
Жесткий диск/SSD: Асинхронно читайте файлы mini-batch выборками и сжимайте звук или изображение; жесткий диск подойдет, только если вы не работаете с большими объемами 32-битных данных с плавающей точкой.
БП: Для подсчета мощности сложите ватты ЦП + ГП + (100–300); для работы с большими сверточными сетями берите БП с высоким КПД; убедитесь, что он имеет достаточное количество PCIe коннекторов (6-контактный + 8-контактный) и достаточную мощность для будущих ГП.
Охлаждение: установите флажок «coolbits» в конфигурационном файле, если используете один ГП; иначе прошейте BIOS для увеличения скорости кулеров — это самое простое и дешевое решение; используйте водяное охлаждение для нескольких ГП и/или когда вам нужно снизить шум (если вы работаете в помещении с другими людьми).
Материнская плата: берите PCIe 3.0 и такое количество слотов, чтобы они уместили все будущие ГП (некоторые ГП занимают два слота, максимум 4 ГП на систему).
Мониторы: если вы хотите улучшить систему и повысить продуктивность, то имеет смысл вместо апгрейда ГП купить дополнительный монитор.
