[Перевод] Разработка веб-приложения для транскрибирования аудиозаписей с использованием Python, Streamlit и AssemblyAI
Приложение, о котором тут пойдёт речь, можно испытать здесь.
Веб-приложение в действии
Транскрибирование — это процесс преобразования аудиозаписи в текст. Хотя можно создать собственную систему, основанную на технологиях машинного обучения, предназначенную для извлечения текста из звука, это — весьма трудоёмкая задача:
- Для извлечения признаков из аудиосигнала требуются глубокие знания в сфере обработки звуковых сигналов.
- Нужно будет как-то достать (например — пользуясь методами добычи информации или веб-скрапинга) из разных источников большие объёмы данных.
- Для построения модели нужно уметь обращаться с соответствующими библиотеками для машинного обучения, с такими, как PyTorch или TensorFlow.
К счастью, существует проект AssemblyAI, возможности которого, доступные даже в рамках бесплатного тарифного плана, позволяют транскрибировать аудиозаписи, выполнив буквально несколько запросов к соответствующему API.
В этом материале я расскажу о том, как создать веб-приложение, которое позволяет транскрибировать аудиозаписи с использованием AssemblyAI. Графическая часть приложения создана с помощью Streamlit — Python-фреймворка, предназначенного для создания интерфейсов приложений из сферы машинного обучения.
Полный исходный код проекта можно найти в этом репозитории.
Предварительные требования
Для того чтобы создать этот проект нам понадобится следующее:
- Учётная запись AssemblyAI (тут можно зарегистрироваться в системе, это бесплатно).
- Ключ к API AssemblyAI (найти его можно здесь).
- Знание основ Python 3.5+ (обратите внимание на то, что тут я буду пользоваться Python 3.9).
- Умение работать с библиотекой requests (это не обязательно, но желательно).
Обзор используемых инструментов
▍AssemblyAI
Проект AssemblyAI используется для преобразования аудиозаписей в текст. Он предоставляет REST API, им можно пользоваться из программ, написанных на любом языке программирования, который позволяет выполнять запросы к подобным API. Это, например, JavaScript, PHP, Python и так далее. Мы будем выполнять запросы к API из программы, написанной на Python.
▍Streamlit
Streamlit — то опенсорсный фреймворк для разработки пользовательских интерфейсов приложений, в которых применяются технологии машинного обучения. Для эффективного применения этого фреймворка не нужно знать HTML, CSS или JavaScript. В нём имеется обширная библиотека готовых компонентов, которые можно применять для быстрой разработки простых интерфейсов.
▍Requests
Requests — это Python-библиотека, которую мы будем использовать для выполнения запросов к REST API AssemblyAI.
▍Python-dotenv
Python-dotenv — это библиотека, с помощью которой мы будем считывать значения переменных из файлов
.env.Настройка директории проекта
Создадим новую директорию, воспользовавшись инструментами командной строки:
mkdir ASSEMBLYAI
Для организации надёжного хранения секретных данных рекомендуется записывать их в файлы
.env. Для того чтобы читать такие данные из подобных файлов — можно воспользоваться библиотекой python-dotenv. Ещё одним допустимым способом хранения секретных данных является их запись в переменные окружения.В нашей новой директории ASSEMBLYAI создадим два Python-файла и один файл .env:
В Windows это делается так:
New-Item main.py, transcribe.py, .env
В macOS или в Linux можно воспользоваться такой командой:
touch main.py && touch transcribe.py && touch .env
Файл
main.py будет содержать весь код, имеющий отношение к интерфейсу приложения, созданному с помощью Streamlit. В файле transcribe.py будет находиться код вспомогательных функций и код, реализующий взаимодействие с API AssemblyAI.Отсюда можно загрузить MP3-файл для экспериментов. Назовём его testData.mp3 и сохраним в папке ASSEMBLYAI.
Настройка окружения проекта
Сейчас мы должны находиться в директории
ASSEMBLYAI. Если это не так, и мы, например, находимся в её родительской директории, перейти в неё можно с помощью следующей команды: cd ASSEMBLYAI
Если вы раньше не работали с виртуальными окружениями — это значит, что вам, для продолжения работы, потребуется установить virtualenv.
В Windows это делается так:
python -m pip install -user virtualenv
В macOS и в Linux — так:
python3 -m pip install -user virtualenv
Сначала надо создать виртуальное окружение.
Вот вариант соответствующей команды для Windows:
python -m venv venv
Вот — команда для macOS или Linux:
python3 -m venv venv
Затем нужно будет активировать локальное виртуальное окружение.
В Windows это делается так:
venv/Scripts/activate
В macOS или Linux — так:
source venv/bin/activate
Подробности о настройке виртуальных окружений ищите здесь.
Для установки библиотек requests, steamlit и python-dotenv можно воспользоваться следующей командой:
pip install streamlit, requests, python-dotenv
После этого будут установлены свежие версии соответствующих библиотек.
Теперь содержимое папки ASSEMBLYAI должно выглядеть так, как показано на следующем рисунке.
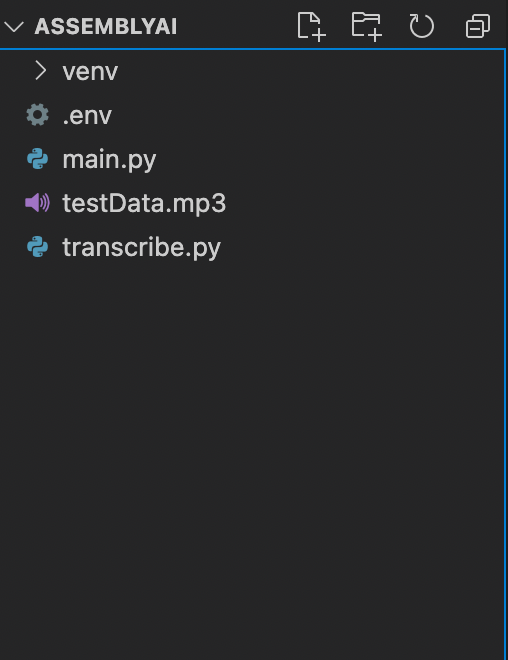
Содержимое папки ASSEMBLYAI
Добавление ключа API в файл .env
- Откроем файл
.env, который мы создали ранее. - Добавим в него следующее:
API_TOKEN = "Your API Key" - Строку
Your API Keyнужно заменить на ключ API, полученный на сайте AssemblyAI.
Клонирование репозитория и запуск проекта
Возможно вы, перед работой над собственным вариантом проекта, решите испытать готовое приложение на своём компьютере. Сделать это можно так:
- Перейдём в соответствующий GitHub-репозиторий и загрузим его материалы.
- Откроем командную строку и перейдём в папку с загруженными материалами.
- Настроим виртуальное окружение так, как описано выше.
- Активируем виртуальное окружение.
- Создадим в папке с загруженными материалами файл
.envи добавим в него ключ API (этот процесс описан в предыдущем разделе). - Необходимые библиотеки можно либо установить вручную, либо — воспользовавшись файлом
requirements.txt, который имеется в папке проекта.
В Windows библиотеки можно установить так:
pip install streamlit, requests, python-dotenv
В macOS и Linux — так:
pip install streamlit requests python-dotenv
Или — так:
pip install -r requirements.txt
После того, как установлены все необходимые зависимости, выполним следующую команду:
streamlit run main.py
Должно запуститься веб-приложение, которое можно испытать, передав ему звуковой файл.
Транскрибирование MP3-файлов
Прежде чем приступать к разработке интерфейса, нам понадобится несколько вспомогательных функций. Их мы будем использовать для выгрузки звуковых файлов на сервер AssemblyAI, который обработает файлы и возвратит нам их текстовое представление.
Код вспомогательных функций размещается в файле transcribe.py.
Импорт модулей, необходимых для работы вспомогательных функций
Следующий фрагмент кода надо разместить в начале файла
transcribe.py: import os
from dotenv import load_dotenv
import requests
Вспомогательная функция №1: выгрузка локального аудиофайла на сервер AssemblyAI
Первая функция, которую нам надо написать, отвечает за выгрузку на сервер AssemblyAI файла, хранящегося на нашем компьютере. Эта функция должна располагаться в файле
transcribe.py.Модель AssemblyAI ожидает, что к файлу можно будет обратиться по URL. Поэтому аудиофайл надо загрузить в blob-хранилище, что и позволит передать AssemblyAI необходимый URL. К нашему счастью, платформа AssemblyAI даёт нам механизм для быстрого и простого решения этой задачи.
А именно, нам нужно выполнить POST-запрос к следующей конечной точке API AssemblyAI:
https://api.assemblyai.com/v2/upload
В ответе на этот запрос будет содержаться временный URL для нашего файла. Этот URL можно передать другой конечной точке API AssemblyAI, которая носит имя
transcript. Это — приватный URL, поэтому обращаться к нему могут только серверы AssemblyAI.Все загруженные файлы после завершения транскрибирования немедленно удаляются. Сервис ничего не хранит.
Для выполнения POST-запроса мы воспользуемся ранее установленной библиотекой requests:
def get_url(token,data):
'''
Parameter:
token: The API key
data : The File Object to upload
Return Value:
url : Url to uploaded file
'''
headers = {'authorization': token}
response = requests.post('https://api.assemblyai.com/v2/upload',
headers=headers,
data=data)
url = response.json()["upload_url"]
print("Uploaded File and got temporary URL to file")
return url
- Функция принимает пару параметров — токен API и объект, представляющий выгружаемый файл.
- Мы выполняем POST-запрос к вышеупомянутому API AssemblyAI. В тело запроса мы включаем токен API и объект файла.
- Объект ответа содержит URL выгруженного файла. Именно его и возвращает эта функция.
Вспомогательная функция №2: передача файла на транскрибирование
Теперь у нас имеется функция, которая позволяет получить URL, ведущий к выгруженному на сервер AssemblyAI аудиофайлу. Мы воспользуемся этим URL для выполнения запроса к конечной точке, позволяющей выполнить расшифровку файла. Код функции, ответственной за это, будет находиться в файле
transcribe.py.Изначально запрос на транскрибирование аудиофайла приводит к созданию задания, пребывающего в состоянии queued, то есть — задания, поставленного в очередь. О том, как узнать о завершении этого задания, то есть — о его переходе в состояние completed, мы поговорим, описывая нашу последнюю вспомогательную функцию. Пока же мы поработаем над функцией, которая позволит выполнить запрос к конечной точке transcript, передав ей URL нашего файла. А именно, запрос нужно отправить по следующему адресу:
https://api.assemblyai.com/v2/transcript
Эта функция очень похожа на предыдущую:
def get_transcribe_id(token,url):
'''
Parameter:
token: The API key
url : Url to uploaded file
Return Value:
id : The transcribe id of the file
'''
endpoint = "https://api.assemblyai.com/v2/transcript"
json = {
"audio_url": url
}
headers = {
"authorization": token,
"content-type": "application/json"
}
response = requests.post(endpoint, json=json, headers=headers)
id = response.json()['id']
print("Made request and file is currently queued")
return id
- Функция принимает два параметра: токен API и URL аудиофайла, полученный от предыдущей функции.
- Мы выполняем POST-запрос к конечной точке API AssemblyAI, которая называется
transcript. Если система в этот момент не занимается обработкой некоего файла — немедленно начинается обработка файла, URL которого ей передан. Если же в момент выполнения запроса выполняется разбор другого файла, задание на обработку нового файла ставится в очередь и пребывает в ней до завершения предыдущего задания. Это — особенность бесплатного тарифного плана. Если вас интересует одновременная обработка нескольких файлов — вам понадобится платный тарифный план. - Объект ответа содержит
ID— идентификатор задания на транскрибирование аудиозаписи. ЭтотIDбудет использоваться при обращении к другой конечной точке для получения сведений о состоянии соответствующего задания. - Функция возвращает этот
ID.
Вспомогательная функция №3: загрузка результатов транскрибирования аудиозаписи
После того, как у нас имеется
ID задания на транскрибирование аудиофайла, мы можем выполнить GET-запрос к соответствующей конечной точке API AssemblyAI для того чтобы узнать о состоянии задания: https://api.assemblyai.com/v2/transcript/{transcribe_id}
Если не возникает ошибок, то состояние задания меняется с
queued на processed, что указывает на то, что над ним ведётся работа. А потом, после завершения транскрибирования, задание переходит в состояние completed.Нужно опрашивать эту конечную точку до тех пор, пока в нашем распоряжении не окажется объект ответа, содержимое которого указывает на то, что задание с соответствующим ID перешло в состояние completed.
В этой ситуации для периодического выполнения запросов можно воспользоваться циклом while. В каждой итерации цикла мы будем проверять состояние задания. Цикл будет выполняться до тех пор, пока задание не перейдёт в состояние completed. Процесс опроса некоей системы в ожидании завершения какой-то операции называют «поллингом» (от английского «polling»). Мы создадим этот механизм в ходе работы над пользовательским интерфейсом приложения.
Функция, код которой приведён ниже, просто отправляет серверу запрос о текущем состоянии задачи по транскрибированию аудиофайла. Она, как и вышеописанные функции, должна находиться в файле transcribe.py:
def get_text(token,transcribe_id):
'''
Parameter:
token: The API key
transcribe_id: The ID of the file which is being
Return Value:
result : The response object
'''
endpoint = f"https://api.assemblyai.com/v2/transcript/{transcribe_id}"
headers = {
"authorization": token
}
result = requests.get(endpoint, headers=headers).json()
return result
Вспомогательная функция №4: запрос результатов транскрибирования из пользовательского интерфейса
Эта функция пользуется возможностями уже описанных вспомогательных функций
get_url() и get_transcribe_id(). Она, кроме того, будет подключена к кнопке Upload, присутствующей в интерфейсе приложения. Она принимает лишь один параметр — объект файла. Вот как она работает: - Загружает токен API из файла
.env. - Использует токен при вызове функций
get_url()иget_transcribe_id(). - Возвращает
IDзадания на транскрибирование аудиозаписи.
Ниже показан код функции. Она, как и другие вспомогательные функции, должна находиться в файле
transcribe.py.def upload_file(fileObj):
'''
Parameter:
fileObj: The File Object to transcribe
Return Value:
token : The API key
transcribe_id: The ID of the file which is being transcribed
'''
load_dotenv()
token = os.getenv("API_TOKEN")
file_url = get_url(token,fileObj)
transcribe_id = get_transcribe_id(token,file_url)
return token,transcribe_id
- Мы пользуемся функцией
load_dotenv()для загрузки данных из файла.env. Затем, пользуясь методомgetenv()из модуляos, мы читаем значение переменнойAPI_TOKEN, которая хранится в файле.env. - Вызывается функция
get_url(), которой, в качестве параметров, передаётся объект файла и токен API. - Вызывается функция
get_transcribe_id(), которой передаётся токен API и переменнаяfile_url, содержащая то, что возвратила функцияget_url(). - Выполняется возврат токена API и
IDзадания на транскрибирование аудиозаписи.
Разработка пользовательского интерфейса приложения с помощью Streamlit
Теперь, когда в нашем распоряжении имеются все необходимые вспомогательные функции, мы можем приступить к работе над интерфейсом приложения с применением Streamlit.
Но, прежде чем мы перейдём к рассмотрению кода, описывающего интерфейс, давайте взглянем на команды Streamlit, которыми мы будем пользоваться при создании компонентов интерфейса:
header(string),subheader(string),text(string)— эти команды выводят в интерфейсе текст, используя различные способы его форматирования, в частности — меняя размеры шрифта. Методheader()можно рассматривать как аналог тега,subheader()— как аналог, аtext()— как аналог.file_uploader(label)— эта команда позволяет создать элемент для выгрузки файла, содержащий кнопку и поле, в которое можно перетащить файл. Параметрlabel— это строка, которая будет выведена над полем. Метод возвращает файловый объект. Мы будем пользоваться этим механизмом для приёма файлов от пользователя.progress(integer)— создаёт индикатор прогресса. Параметрintegerдолжен представлять собой число в диапазоне от 0 до 100. Он указывает на процент завершения некоей задачи. Если написать циклfor, в каждой итерации которого есть командаsleep(), приостанавливающая выполнение программы на 0,1 секунды, на основе этого цикла можно создать приятную анимацию индикатора прогресса.spinner(label)— то, что передано этому методу вlabel, выводится до тех пор, пока мы находимся в соответствующем блоке кода.balloons()— эта команда позволяет вывести симпатичную анимацию из воздушных шариков.
Создание компонентов пользовательского интерфейса
Следующий код должен находиться в файле
main.py. Этот файл будет точкой входа в веб-приложение.Для начала надо импортировать в этот файл все необходимые модули и библиотеки:
import streamlit as st
from transcribe import *
import time
transcribe — это имя файла, в котором хранится код вспомогательных библиотек.Для того чтобы проверить правильность импорта библиотек — можно попробовать выполнить следующую команду в командной строке. Прежде чем выполнять эту команду — надо проверить, чтобы было активировано виртуальное окружение, и чтобы текущей папкой являлась бы корневая папка проекта (ASSEMBLYAI):
streamlit run main.py
Если до этого момента всё было сделано правильно — после выполнения этой команды должна открыться пустая страница веб-приложения. Для того чтобы перезапустить приложение — можно либо воспользоваться командой меню
Rerun, либо открыть веб-приложение и воспользоваться сочетанием клавиш Ctrl + R (или Cmd + R).Начнём с описания заголовка страницы и поля для выгрузки файлов.
Внесём в файл main.py следующий код:
st.header("Trascribe Audio")
fileObject = st.file_uploader(label = "Please upload your file" )
Если теперь снова запустить приложение, выглядеть оно должно так, как показано ниже.
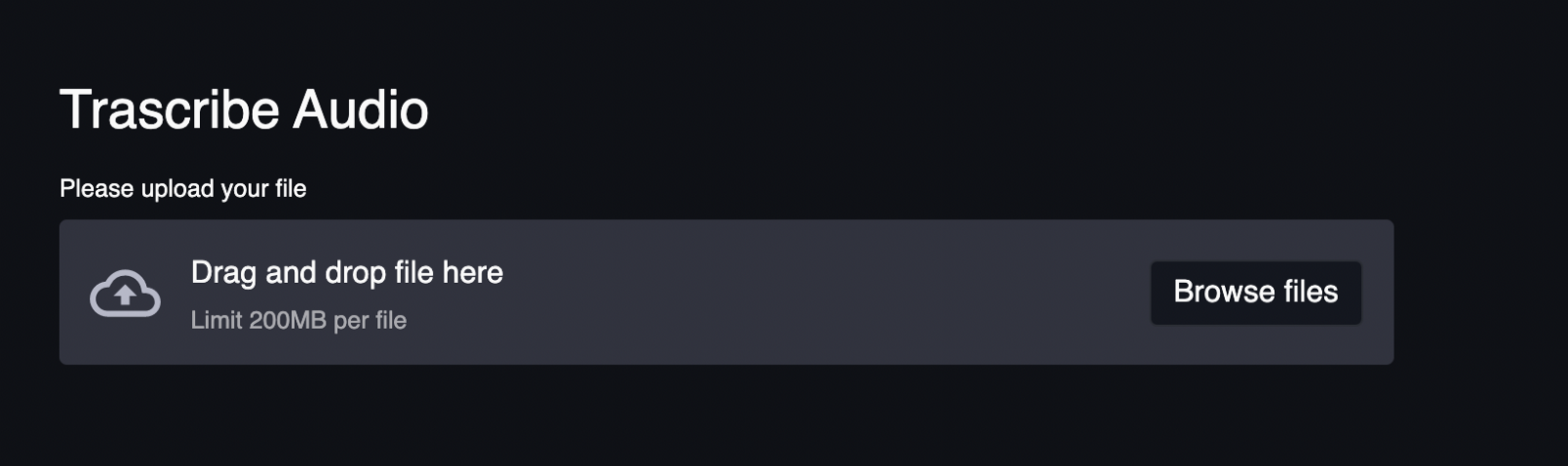
Приложение после добавления на его страницу заголовка и поля для загрузки файлов
Изначально переменная fileObject имеет значение None, а после выбора файла в ней будет объект файла.
fileObject = st.file_uploader(label = "Please upload your file" )
if fileObject:
token, t_id = upload_file(fileObject)
result = {}
#polling
sleep_duration = 1
percent_complete = 0
progress_bar = st.progress(percent_complete)
st.text("Currently in queue")
while result.get("status") != "processing":
percent_complete += sleep_duration
time.sleep(sleep_duration)
progress_bar.progress(percent_complete/10)
result = get_text(token,t_id)
sleep_duration = 0.01
for percent in range(percent_complete,101):
time.sleep(sleep_duration)
progress_bar.progress(percent)
Разберём основные детали этого кода:
- Если значением
fileObjectне являетсяNone— мы вызываем функциюupload_file(). - Мы пользуемся циклом
whileдля поллинга конечной точки. - На каждой итерации цикла
whileсоздаётся индикатор прогресса, программа «засыпает» на 0,1 секунды и инкрементирует значение, передаваемое индикатору, на 1. - После того, как задание на транскрибирование перейдёт в состояние
processing, время задержки уменьшается до 0,01 секунды. Это приводит к выводу довольно-таки интересной анимации, когда изначально полоса индикатора прогресса движется медленно, а после начала обработки файла ускоряется.
Индикатор прогресса - После того, как индикатор прогресса укажет на то, что операция полностью завершена, мы снова начинаем обращаться к конечной точке. В этот раз мы проверяем задачу на предмет её завершения, на переход её в состояние
completed. Во время поллинга конечной точки мы пользуемся функциейspinner()для показа соответствующего текста на странице.with st.spinner("Processing....."): while result.get("status") != 'completed': result = get_text(token,t_id) - После того, как состояние задачи изменится на
completed— мы выходим из циклаwhileи, пользуясь функциейballoons(), выводим анимацию с воздушными шариками.st.balloons() st.header("Transcribed Text") st.subheader(result['text']) - И мы, наконец, выводим на экран результаты транскрибирования аудиозаписи.
В начале этого материала мы уже приводили анимированное изображение, демонстрирующее веб-приложение в действии. Приведём его снова. Полагаем, теперь вы видите его немного иначе, чем прежде.
Веб-приложение в действии
Итоги
Примите поздравления! Только что вы создали веб-приложение, которое умеет транскрибировать аудиозаписи. Вы, если хотите, вполне можете расширить его возможности. Например — рассмотрев следующие варианты его развития:
- AssemblyAI позволяет пользователям сервиса указывать акустические модели и (или) языковые модели, используемые при транскрибировании аудиозаписей. В интерфейсе приложения выбор чего-то подобного можно представить в виде выпадающего списка, реализованного средствами Streamlit.
- Пользователям приложения можно дать возможность записи и транскрибирования голоса. Для того чтобы решить эту задачу, понадобится приложить определённые усилия, так как в Streamlit нет встроенных компонентов, ориентированных на запись голоса. Но подобный компонент можно создать самостоятельно, воспользовавшись HTML и JavaScript. Если вас эта идея заинтересовала — загляните сюда.
Пользуетесь ли вы Streamlit?

