[Перевод] Разработка Adblock Radio

tl; dr: Adblock Radio распознаёт аудиорекламу с помощью машинного обучения и Shazam-подобных техник. Основной движок с открытым исходным кодом: используйте его в своих продуктах! Можно объединить усилия для поддержки большего количества радиостанций и подкастов.
Мало кому нравится слушать рекламу на радио. Я запустил проект AdblockRadio.com, чтобы слушатели могли пропускать рекламу на своём любимом интернет-радио. Алгоритм опубликован с открытым исходным кодом, а в этой статье описывается, как он работает.
Adblock Radio уже протестировали на реальных данных более 60 радиостанций в семи странах. Он также совместим с подкастами и работает довольно хорошо!
По сравнению с предыдущими реализациями наш алгоритм предлагает универсальный подход, обрабатывая потоки из различных источников. Из предыдущих реализаций одна полагается на метаданные интернет-радио, но только небольшая часть радио совместима с этим методом. Другая реализация распознаёт известные джинглы, но во многих случаях начало и конец рекламных пауз не отмечены джинглом.
Помимо обнаружения рекламных роликов, предложенный алгоритм умеет отличать разговор от музыки. Поэтому он также позволяет избежать болтовни и слушать только музыку.
Это отчёт о моей личной работе почти за три года. Я запустил Adblock Radio в конце 2015 года, через несколько месяцев после окончания аспирантуры по физике термоядерной плазмы. Когда Adblock Radio приобрёл некоторую известность в 2016 году, я получил угрозы от юристов из французских радиостанций (подробнее ниже). Мне пришлось частично закрыть сайт, изменить архитектуру системы, лучше изучить правовые последствия и т. д. Сегодня я считаю, что AdBlock Radio будет гораздо лучше развиваться в парадигме открытых инноваций.
Эта статья состоит из трёх частей. Они предназначены для разных аудиторий. Можете прокрутить вниз или щёлкнуть по названию, чтобы сразу перейти к нужному разделу.
- Обнаружение рекламы: опробованные стратегии. Для технически подкованных людей, учёных, специалистов по анализу данных… Здесь представлены разные технические способы, которые я опробовал для обнаружения рекламы, в том числе распознавание речи, звуковые отпечатки и машинное обучение. Мысли о вариантах дальнейшей работы.
- Не рекомендуется запускать Adblock Radio в облаке. Для разработчиков программного обеспечения и людей, заинтересованных в авторском праве. Обсудим, как трудно найти удовлетворительный компромисс между техническими и юридическими ограничениями при запуске Adblock Radio в облачных сервисах. По этим причинам лучше запускать Adblock Radio только на устройствах конечных пользователей.
- Можете интегрировать Adblock Radio в свой плеер. Для производителей, владельцев продуктов, UX-дизайнеров, технарей… Я рассматриваю идеи по интеграции алгоритма с открытым исходным кодом в конечные продукты, в том числе автомобильные плееры, и подчеркиваю необходимость получения обратной связи от пользователей о случаях неправильного срабатывания. Это необходимо для поддержания системы. Наконец, здесь подсказки, как создавать правильные пользовательские интерфейсы. Ожидаю много отзывов на эту тему.

Adblock Radio возвращает удовольствие от прослушивания радио
Чтобы заблокировать рекламу, сначала нужно её обнаружить. Цель состоит в том, чтобы обнаружить рекламу в аудиопотоке без какой-либо помощи радиостанции. Это непростая задача. Я опробовал несколько подходов, прежде чем получить хороший результат.
1. Простые способы (не работают)
Громкость
Первая идея в том, чтобы проверять громкость звука, потому что реклама такая громкая! Для рекламы часто используется акустическое сжатие. Это интересный критерий, но его недостаточно, чтобы отличить рекламу. Например, такая стратегия довольно хорошо работает для классических музыкальных станций, где реклама обычно громче музыки. Но поп-музыка такая же громкая, как реклама. Более того, какую-то рекламу нарочно могут сделать тихой, чтобы избежать обнаружения.
Блокировка по часам
Ещё одна идея заключается в том, что реклама транслируется по расписанию в конкретное время. В какой-то степени это верно, но здесь нет точности. Например, я наблюдал, как утреннее шоу на французской станции не начиналось точно в одно и то же время, с вариациями до двух минут. Радиостанции могут легко обойти такую блокировку, случайным образом сдвигая свои программы на несколько десятков секунд.
Метаданные
Очевидное решение — полагаться на метаданные ICY/Shoutcast, по которым плееры вроде VLC отображают информацию о потоке. К сожалению, эти данные в большинстве случаев сломаны. Можно было бы взять информацию из прямого эфира на веб-сайтах радиостанций (я разработал инструмент для этого), но чаще всего реклама не идентифицируется как есть. Обычно во время рекламы на сайте отображается название предыдущей песни или программы. Одним примечательным исключением является Jazz Radio, которое во время рекламы пишет «la musique revient vite…» (музыка скоро вернётся). В заключение следует отметить, что это ненадёжная стратегия, поскольку радиостанции могут очень легко изменить метаданные.
Маркировка вручную
В конце концов, обнаружение рекламы возможно вообще без какого-то алгоритма! Можно просто попросить некоторых слушателей нажать кнопку, когда начинается и заканчивается реклама. Другие слушатели выиграют от этого. Такова стратегия телеприставки TiVo Bolt. Она позволяет удалять рекламу на установленных каналах в установленное время. Это даёт прекрасные результаты, но не очень масштабируется на тысячи радиостанций.
Недостаток в том, что трудно запустить систему с нуля. На новой станции может не хватать аудитории для правильной работы. Первые слушатели расстроятся и уйдут, так что станция никогда и не соберёт достаточно большой аудитории.
Ещё одна трудность в том, что радиостанциям захочется отправлять поддельные сигналы, чтобы саботировать систему. Тут требуется механизм модерации, система консенсуса или порог голосования.
Краудсорсинг — хорошая идея. Думаю, что она выглядит ещё лучше, если алгоритм выполнит бóльшую часть работы, оставляя минимум для людей. Это то, что я сделал.
2. Распознавание речи и анализ лексического поля (неудача)
Реклама — это всегда одна и та же тематика и лексическое поле: покупка автомобиля, получение купонов супермаркета, подписка на страховку и т. д. Если распознать речь, то можно применить стандартные инструменты для борьбы со спамом. Это был мой первый путь исследования в конце 2015 года, но я не смог реализовать распознавание речи.
Будучи новичком в обработке речи, я начал с чтения «Обработки устной речи» Хуанга, отличной книги, хотя немного устаревшей. Я наложил свои грязные ручонки на CMU Sphinx, лучший на то время свободный движок для распознавания речи.
Первая попытка дала очень плохие результаты и требовала интенсивных вычислений на CPU. Я использовал параметры по умолчанию: стандартный французский словарь (список возможных слов и соответствующих фонем), языковая модель (вероятности последовательностей слов) и акустическая модель (связь фонем с формой звуковых волн).
Попытки улучшить систему оказались тщетными: распознавание всё равно работало плохо. Я настроил словарь и языковую модель на небольшом наборе данных, разделяя звук инструментом диаризации. Также адаптировал акустическую модель MLLR к радиостанции Europe 1 (French), на которой обучал систему.
В общем, от идеи распознавания речи пришлось отказаться. Наверное, это для экспертов. Впрочем, в будущем к ней можно вернуться. С 2015 года достигнут значительный прогресс в распознавании речи. Опубликованы новые инструменты с открытым исходным кодом, такие как Mozilla Deep Speech.
3. Краудсорсинг рекламной базы, обнаружение по звуковым отпечаткам (обнадёживающе)
Первая версия Adblock Radio в 2016 году работала с базой рекламных роликов. Система непрерывно прослушивала звуковой поток в поисках рекламы. Результаты были действительно многообещающими, но сложным оказалось поддержание такой базы в актуальном состоянии.
Техника поиска по звуковым отпечаткам похожа на то, что делает Shazam на своих серверах для распознавания песен. Такой тип алгоритмов широко известен как landmark. Я адаптировал его для работы на потоковом вещании и открыл исходный код.
Фингерпринтинг подходит для обнаружения рекламных роликв, потому что они многократно транслируются в одинаковом виде. По той же причине он распознаёт и музыку. Но эта техника не будет работать на речи, потому что люди никогда не произносят слова одинаково. Это возможно только при повторной трансляции передач ночью, что нас не интересует. Таким образом, в базу отпечатков нужно вносить и рекламу, и музыку (как «не реклама»), но обрабатывать речь бессмысленно.
По сути, звуковые отпечатки — это преобразование некоторых звуковых характеристик в ряд чисел, называемых отпечатком. Если в прямом эфире много отпечатков совпадают с базой, можно сделать вывод, что передаётся реклама. Для оптимального разрешения, временного и частотного диапазона нужна некоторая настройка. Различные образцы должны хорошо различаться. Однако система должна работать даже при незначительном изменении алгоритмов сжатия звука или если радиостанция изменила настройки эквалайзера. Наконец, следует ограничить количество отпечатков, чтобы не загружать вычислительные ресурсы.
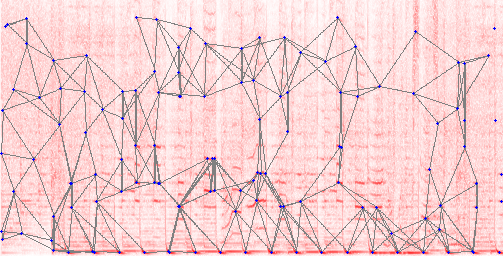
Пример расчёта звуковых отпечатков. Красный фон — спектрограмма. Она отражает изменение интенсивности звука по частоте (низкие частоты внизу). На этой карте спектральные пики идентифицируются (синие точки) и соединяются (серые линии). Положение, длина и ориентация каждой серой линии преобразуется в уникальное число, отпечаток
Двоичная классификация выдаёт результат: является образец рекламой или нет. Если анализировать случаи ошибок, то система почти всегда выдавала ложноотрицательный результат, то есть пропускала рекламу, и очень редко отмечала хороший контент как рекламу. Пользователи могут сообщать о незамеченных объявлениях одним щелчком мыши, что обеспечивает отличный пользовательский интерфейс. Соответствующий звук автоматически добавляется в БД. Я модерировал эти действия апостериори.
Было трудно поддерживать базу в актуальном состоянии, поскольку рекламные ролики часто меняются, а объявления транслируются с небольшими вариациями. Они также часто обновляются, в некоторых случаях каждые несколько дней. Некоторые потоки с недостаточным количеством слушателей очень плохо распознавались.
Я исследовал интересные стратегии для частичной автоматизации работы слушателей. Объявления одинаково транслируются много раз каждый день. Это можно использовать для их идентификации. В записях осуществлялся поиск максимально повторяющихся последовательностей (MRS). Другой контент тоже повторяется, например, песни и джинглы (заставки). Я отсортировал все последовательности по длине и взял образцы с длиной около 30 секунд, типичной для рекламных роликов. Таким образом очень часто удавалось выловить рекламу. Но иногда попадались припевы песен или даже записанные прогнозы погоды.
Я нашёл способ отфильтровать большинство музыкальных повторов: проанализировал плейлисты станций, скачал песни и интегрировал их в базу с меткой «не реклама». Поэтому всё больше кандидатов в MRS оказывались реальными рекламными роликами. Но всё же не все, поэтому помощь пользователей оставалась необходимой.
Требовалось меньше ручной работы, но нагрузка на серверы уже стала проблемой. Оглядываясь назад, далеко не лучшим оказался выбор SQLite для этих ресурсоёмких, критичных по времени операций с БД.
К счастью, у алгоритма было несколько секунд, чтобы определить, является звук рекламой или нет. Это происходит потому, что интернет-радио используют аудиобуфер, обычно 4−30 секунд, который не сразу воспроизводится на устройстве конечного пользователя. Это помогает предотвратить обрывы трансляций в случае временной потери сети.
Я использовал эту задержку буфера для постпроцессинга, чтобы сделать прогнозы алгоритма более стабильными и контекстно-зависимыми. Непосредственно перед воспроизведением звука на устройстве конечного пользователя алгоритм просматривает результаты прогнозов, которые всё ещё находятся в буфере, а также более старые, которые уже воспроизведены. Он обрезает сомнительные точки данных с несколькими совпадениями отпечатков, демонстрируя гистерезис. Он также учитывает средневзвешенное время, чтобы сгладить возможные сбои.

Adblock Radio на определённом этапе в 2016 году. Подсвечивание красным радиостанций, где в данный момент звучит реклама, выглядело действительно здорово! Пользователи могли отмечать пропущенную рекламу синей кнопкой. Кнопка music-in-a-cloud в верхней части позволяет экспортировать пользовательский MP3-поток с удалённой из него рекламой и, если настроена такая функция, плавными переходами между радиостанциями. Ниже представлены дополнительные кнопки и функции
4. Классификация рекламы, разговоров и музыки на машинном обучении (почти готова!)
Следующая версия алгоритма анализирует акустику: от низких до высоких звуков и их изменение во времени. Новые неизвестные рекламные ролики детектируются почти так же хорошо, как и старые, на которых происходило обучение, только по признакам шумности и назойливости. Это более сложный метод анализа громкости звука (см. предыдущее обсуждение).
Для этого я использовал инструменты машинного обучения, а именно библиотеку Keras, подключенную к Tensorflow. Это дало очень хорошие результаты с малым использовании CPU. Эта версия работала в продакшне более года, с начала 2017 года до середины 2018 года. Теперь реально отличать разговоры и музыку, поэтому классификация стала более точной: вместо «реклама/не реклама» — «реклама/разговор/музыка».
Изучим детали. Звук преобразуется в 2D-карту, где интенсивность звука представлена как функция от частоты и времени (в масштабе около четырёх секунд). Эта карта концептуально похожа на красную карту в главе об отпечатках. Основное отличие в том, что вместо классического спектра Фурье я использовал Мел-кепстральные коэффициенты, актуальные в контексте распознавания речи.
Последовательные карты с разными метками времени затем анализировались как картинки в рекуррентной нейронной сети типа LSTM (long short-term memory). Каждая карта анализировалась независимо от другой (RNN без сохранения состояния), но карты перекрывали друг друга. Карты были длиной 4 секунды, и каждую секунду появлялась новая. Конечным результатом для каждой карты становился вектор softmax, например, ad: 72%, talk: 11%, music 17%. Эти прогнозы затем обрабатывались тем же методом, который описан в разделе об отпечатках.
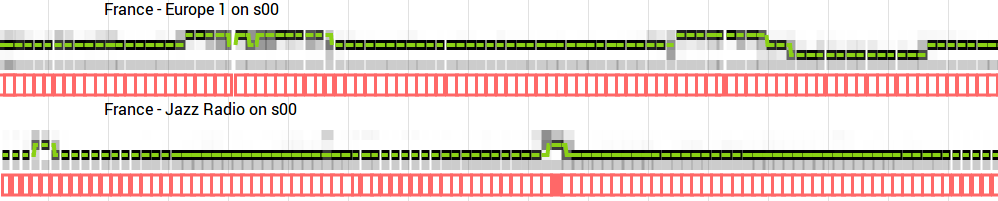
Предварительный просмотр типичных результатов машинного обучения для двух радиостанций. Горизонтальная ось представляет около 17 минут времени. Зелёная линия перемещается между тремя позициями: реклама вверху, разговор посередине и музыка внизу (самая ближняя к однородному серому фону). Красные области — интервалы прослушивания звука пользователем. Если алгоритм даёт неверный прогноз, пользователь может его исправить
Изначально я обучал нейросеть на очень маленьком наборе данных. Я разработал UI (см. рисунок выше) для визуализации прогнозов и мог бы добавить больше данных для обучения моделей с лучшей производительностью. На момент написания этой статьи обучающий набор данных содержит около десяти дней аудио: 66 часов рекламы, 96 ч разговоров и 73 ч музыки.
Несмотря на хорошую работу, точность классификации всё-таки оказалась чуть ниже ожиданий пользователей (см. ниже раздел о будущих улучшениях). При обучении точность прогноза категории составила 95%, но оставшиеся неверные классификации оставляли пользователей недовольными.
Примечание для специалистов по обработке данных: принято приводить формальные результаты, разбивая набор данных на подмножества обучения и тестирования. Думаю, что здесь это не имеет смысла, потому что набор данных постепенно выстраивается на данных, где ошибались предыдущие модели. Это означает, что набор данных содержит больше патологий, чем средняя радиопередача, и точность будет недооценена. Потребуется отдельная работа по измерению реальных показателей. Оператор может помечать непрерывные сегменты обычных аудиозаписей как тестовые данные, затем вычислить на них точность и recall. Такая регулярная проверка позволит контролировать работоспособность фильтров.
Разделение по категориям реклама/разговоры/музыка добавила слушателям удобства. Однако такая классификация усложнила пользовательский интерфейс, а с пользовательскими отчётами стало сложнее работать. Если флаг указывает, что какой-то контент не является музыкой, это реклама или разговор? Тут нужна немедленная модерация, а не постфактум.
Чтобы ещё улучшить качество, я разработал последнюю версию Adblock Radio, которая немного улучшает данную стратегию.
5. Сочетание звуковой классификации и сопоставления отпечатков (успех!)
Мой самый лучший алгоритм опубликован на Github. Для повышения надёжности он сочетает концепции из двух предыдущих попыток: акустическая классификация и база отпечатков.
Правильно обученный предиктор машинного обучения обеспечивает корректную классификацию большинства исходных материалов, но в некоторых ситуациях не работает (см. ниже в разделе о будущих улучшениях). Роль модуля сопоставления отпечатков заключается в снижении ошибок модуля машинного обучения.
В базу отпечатков заносятся не все известные обучающие данные, а только небольшое подмножество, где машинное обучение демонстрирует ошибки. Я называю её «базой хотлиста» (hotlist database). Небольшой размер помогает уменьшить общую частоту повторения ошибок, сохраняя низкой нагрузку на CPU.
На обычном ноутбуке алгоритм потребляет всего 5–10% CPU на файлах и 10–20% на прямом эфире.
Будущие улучшения
Некоторые виды контента по-прежнему проблематичны
Детектор неидеально работает на некоторых конкретных видах аудиоконтента:
- хип-хоп музыка часто распознаётся как реклама. Обойти проблему можно путём добавления треков в хотлист, но это слишком много музыки. Можно разработать более общую нейросеть, возможно, в ущерб производительности.
- реклама музыкальных альбомов часто распознаётся как музыка. Но блокировка через отпечатки приведёт к ложноположительным срабатываниям, когда будет транслироваться настоящая песня. Проблему можно решить путём более глубокого анализа контекста, но это трудно в прямом эфире, где контекст известен только на несколько секунд вперёд.
- реклама ток-шоу часто распознаётся как разговор. Здесь размытые границы, потому что это одновременно и разговор, и реклама. Мы видим предел возможностей классификатора реклама/разговор/музыка. Для классификации по отпечаткам я некоторое время использовал класс ad_self, содержащий рекламу ток-шоу на конкретных станциях, но с внедрением алгоритма машинного обучения перестал это делать. Возможно, разумно воссоздать этот класс. Другой вариант — более качественный анализ контекста.
- нативная реклама, где ведущий зачитывает спонсорский текст. На радио такое встречается редко, а чаще в подкастах. Логичный следующий шаг для блокировки такой рекламы — внедрение ПО для распознавания речи.
Марковские цепи для более стабильной постобработки
Стабильность постобработки можно улучшить. В настоящее время используются только доверительные пороги. При достижении порогового значения берётся последний уверенный прогноз. Таким образом, система иногда сохраняет ошибку.
Циклы рекламы, разговоров и музыки довольно цикличны в каждом эфире. Например, реклама обычно длится несколько минут. Для каждого периода времени в рекламной паузе можно рассчитать вероятность перехода в другое состояние (разговор или музыка). Эта вероятность поможет лучше интерпретировать шумные предсказания алгоритма: это просто короткий сегмент музыки в объявлении или рекламный перерыв завершён? Здесь хорошим направлением исследований будут скрытые марковские модели.
Аналоговое радио пока не поддерживается
Аналоговые сигналы (FM) не тестировались и в настоящее время не поддерживаются. Аналоговый шум аннулирует используемые здесь методы. Могут потребоваться фильтры и/или шумоустойчивые алгоритмы распознавания отпечатков. Если такое произойдёт, то программа способна найти более широкое применение у пользователей. Однако радио всё больше переходит на цифровые технологии без шума, такие как DAB и интернет-радио.
В идеале Adblock Radio следует запускать только на оконечных устройствах. Но сейчас в моде облачные сервисы. Более того, это отличная бизнес-идея! Adblock Radio тестировал два варианта архитектуры с такой парадигмой. Однако опыт показывает, что это не лучший вариант по техническим и юридическим причинам.
Вариант 1. Ретрансляция с сервера
Сервер может ретранслировать слушателям аудиоконтент с тегами ad/talk/music. Мы это тестировали в 2016 году. Тут возникают юридические проблемы, поскольку ретрансляция потока может рассматриваться как подделка и/или нарушение копирайта (хотя я не юрист). Также это плохо масштабируется, потому что теперь вы CDN и должны нести расходы.
Ради анекдота, в воскресенье, когда я отсутствовал по семейным обстоятельствам, Adblock Radio получил бешеную популярность, от которой и упал. Забавный факт: через несколько дней France Inter, крупная французская общественная радиостанция, прорекламировала Adblock Radio в прайм-тайм (впрочем, не называя его). Это неожиданное решение редакции в контексте того факта, что регуляторы решили в 2016 году ослабить ограничения на рекламу на государственных радиостанциях, что усугубило раздор между сотрудниками Radio France и руководством.
Спустя несколько недель я получил угрозы от адвоката французской частной радиосети Les Indés Radio, якобы на основании нарушения авторских прав и товарных знаков. Не имея финансовых ресурсов для серьёзной защиты, мне пришлось удалить с сайта некоторые потоки, частично закрыть сайт и изменить архитектуру системы. В то же время эта радиосеть отказалась сотрудничать в поисках компромисса. С тех я вижу в логах, что они продолжали следить за моим сайтом (иногда с псевдонимными учётными записями), ещё они консультировались со своими адвокатами. Какая честь для меня! Оглядываясь назад, они успешно выиграли время, но не более того. Привет, ребята из Indés! Надеюсь, вам понравится читать это! xoxoxo.

Признание в любви от Les Indés, сети из 131 французской радиостанции
Вариант 2. Сервер ретранслирует звук, но приватно
Здесь предполагается анализ на сервере и ретрансляция очищенного звука для конкретного пользователя. Такая система может подпадать под исключение из закона о копирайте как собственная частная копия средств массовой информации. Если сервер управляется конечным пользователем, а исходный источник легален и официально доступен в вашем регионе, вероятно, всё юридически чисто. Для дополнительной информации см. обсуждения Station Ripper [FR] и VCast [FR]. Но пользователи редко настолько технически подкованы, чтобы самостоятельно арендовать и установить сервер.
Очень заманчиво поставить сервер под управлением третьей стороны, но это приводит к юридическим проблемам, поскольку тогда оператор, делающий копию, и конечный пользователь не являются одним и тем же лицом. В этом случае накладываются юридические ограничения, по крайней мере, во Франции. Французский интернет-сервис Wizzgo [FR] столкнулся с этим правилом в 2008 году. Совсем недавно в США телевизионный сервис Aereo был закрыт, хотя принял меры предосторожности, раздав каждому клиенту отдельный тюнер (!).
В данный момент сервис Molotov.TV [FR] сражается с правообладателями, которые хотят ограничить его функции [FR], несмотря на значительное влияние его соучредителей. Необходимо оплатить в официальную организацию налог на частную копию [FR]. Сумма определяется довольно непрозрачными расчётами [FR] и увеличивается [FR] с каждым годом, достигая нескольких десятков евроцентов на пользователя в месяц. Эта плата стала настолько высокой, что Molotov.TV недавно удалил функции своего сервиса для бесплатных пользователей [FR]. (Примечание: сердечно благодарю журналистов французского сайта NextINpact за очень хорошее освещение этой темы).
Платить недостаточно: закон требует от субъектов вроде Molotov.TV подписать соглашения [FR] с компаниями, обладающими авторскими правами, о функциональности своего сервиса. Попробуйте достичь соглашения с радиокомпаниями, если вы начнёте резать их рекламу.
Вариант 3. Сервер отправляет только метаданные
Ещё один вариант состоит в том, чтобы и пользователь, и сервер одновременно прослушивали одно и то же интернет-радио. При этом сервер анализирует звук и отправляет пользователю классификационные метаданные (ad/talk/music), но не аудиоконтент. На такой архитектуре с 2017 года работает adblockradio.com. Она опирается на CDN, так что не несёт никаких затрат в отношении трансляции аудио.
Эта архитектура снимает проблему с нарушением копирайта (дисклеймер: я не юрист). Тем не менее, всё ещё может существовать некоторая неопределённость в отношении законов о товарных знаках. Недавно (октябрь 2018 года) владельцы радио Skyrock потребовали удалить контента на таком основании.

Романтическое послание от юридического отдела Skyrock
Помимо юридических соображений, есть техническая проблема правильной синхронизации между звуком и метаданными. В большинстве случаев всё работает нормально с интервалом синхронизации менее двух секунд. Но у некоторых радиостанций странные/вредоносные CDN или они динамически вводят рекламу в поток. Это означает, что потоки между сервером и разными клиентами могут значительно отличаться. Например, на Radio FG наблюдались лаги до 20 секунд, а на Jazz Radio — до 45 секунд. Это разочаровывает слушателей.
Синхронизацию можно жёстко внедрить сравнением блоков данных между сервером и пользователем. К сожалению, это не работает в веб-браузерах, потому что большинство CDN у интернет-радиостанций не используют заголовки CORS. Поэтому JavaScript в браузере не сможет прочитать аудиоконтент для сравнения. Для работы понадобятся отдельные автономные модули (например, Electron), модули Flash (ага) или веб-расширения, что кажется немного излишним.
Это проект не для конечных пользователей, а для компаний, которые выпускают массовый продукт. Вы можете сделать такой!
У разработчиков есть два варианта интеграции Adblock Radio. Во-первых, SDK просто берёт метаданные с сервера adblockradio.com. Это не идеальное решение по причинам, описанным выше (юридические и проблемы синхронизации). Лучше запустить у себя полный алгоритм анализа.
Программное обеспечение
- мобильные приложения для интернет-радио и подкастов. Модели Keras нужно конвертировать в нативные Tensorflow, а библиотеку Keras + Tensorflow можно заменить на Tensorflow Lite для Android и iOS. Рутины Node.JS внедряются с помощью плагина React Native или на крайний случай с Termux.
- расширения браузера работают с Tensorflow JS и SQL.js. Расширение может управлять ползунком громкости в популярных каталогах интернет-радио, таких как TuneIn или Radio.de. Я уже работал над таким расширением. Было забавно ковыряться в JavaScript-плеерах, чтобы получить этот контроль. В зависимости от реализации помните о проблемах синхронизации, которые мы обсуждали выше.
Аппаратное обеспечение
- цифровые будильники и любительские проекты, при условии наличия достаточной вычислительной мощности и доступа в Сеть. Платформы вроде Raspberry Pi Zero/A/B должно быть достаточно для анализа одного потока, хотя для параллельного управления несколькими потоками рекомендуется RPi 3B/3B+. Tensorflow есть на Raspbian.
- подключённые динамики, такие как Sonos. Сам алгоритм не будет работать на таком оборудовании, поэтому нужно обрабатывать данные или в облаке, или на отдельном устройстве в той же локальной сети (например, на Raspberry). Отличная идея для краудфандинговой кампании.
Adblock Radio в автомобиле
Автомобиль — одно из самых популярных мест для прослушивания радио. Там людям реально нужен блокировщик рекламы. Но это и контекст, где реализовать Adblock Radio непросто. Ведь система должна получать обратную связь, чтобы эффективно фильтровать новую рекламу, поэтому программа нуждается в сетевом подключении. Я вижу три возможных концепции автомобильных продуктов с Adblock Radio.
- Приложение, совместимое с информационно-развлекательными системами современных автомобилей. Вероятно, данные проще всего передавать через смартфон пользователя. Смартфон можно использовать и отдельно — с мобильным приложением, потоковыми интернет-радио, через аудиовыход, подключение к AUX или Bluetooth автомобиля. Его также можно интегрировать с информационно-развлекательной системой автомобиля, в духе Apple Car Play, Android Auto и MirrorLink. Было бы фантастикой слушать наземное радио (FM, DAB). Но необходима работа, чтобы определить, в каких именно конфигурациях Adblock Radio может получить доступ к аудиовыходу радиотюнера и, в то же время, управлять им (громкость, канал).
- Универсальный аппаратный адаптер, выделенный пользовательский интерфейс. Также возможна разработка нестандартного оборудования, аналогичного существующим DAB-адаптерам для автомобилей. Эти устройства настраиваются на радиостанции и передают звуковые данные в автомобильную систему через разъём AUX или через неиспользуемый FM-канал, как старые адаптеры iPod FM. Доступ к сети может идти через смартфон по Bluetooth-соединению. Можно было бы рассмотреть альтернативные решения, такие как Sigfox и LoRa, если подходят битрейт и цена. Следует разработать специальный пользовательский интерфейс, отдельно от основного автомобильного устройства. В итоге это может оказаться слишком дорогим решением.
- Минималистичное устройство, которое взламывает FM-приёмник. Такое небольшое устройство может при необходимости управлять тюнером. Нужен стандартный, но легко подключаемый интерфейс. Хороший кандидат — переключатели на рулевом колесе, но конечные пользователи не смогут легко их модифицировать для этой цели. Так что нужно взломать систему.
У этого headless-устройства будет FM-тюнер и микрофон для анализа, какую станцию слушает пользователь (перекрёстная корреляция). Когда обнаружена реклама, устройство излучает поддельные данные RDS (например, дорожные объявления), чтобы обмануть тюнер автомобиля и изменить станцию на время рекламы. Он также может транслировать тишину на текущей FM-частоте.
Интерфейс такого устройства очень прост, всего с несколькими кнопками. Так дешевле, чем полнофункциональный автомобильный адаптер. Однако неясно, будет ли это надёжно работать, поскольку без лицензии использование радиопередатчиков строго ограничено законом. Наконец, неизвестно, можно ли адаптировать такую стратегию для работы с цифровыми потоками DAB.
Если удастся разработать дешёвое устройство, то такой продукт должен иметь коммерческий успех. Кроме того, он подходит для краудфандинга.
Проекту нужны сигналы о некорректных срабатываниях и помощь в их обработке
При интеграции Adblock Radio в продукт, пожалуйста, оставьте возможность для фидбека. О неправильных срабатываниях следует незамедлительно сообщать мне, чтобы я мог обновлять модели машинного обучения и базу хотлиста.
Отчёты просматриваются вручную: достаточно указать название радиостанции (радиостанций) и время, когда возникла проблема. В библиотеку заложен механизм отправки отчётов.
Обработка отчётов отнимает время. Кроме расходов на сервер, это ещё одна причина, почему я не добавил больше радиостанций на adblockradio.com. Нужна помощь, чтобы прослушивать аудиодорожки и классифицировать контент в админском веб-интерфейсе. Благодаря этому мы сможем увеличить количество радиостанций и обеспечить поддержку подкастов. Если вы готовы помочь, пожалуйста, зарегистрируйтесь здесь и следите за репозиторием, где будет проходить обсуждение поддерживаемых потоков.
Чем заменить рекламу: вопрос UX
Пропуск рекламы в подкасте тривиален: с точки зрения слушателя это как пропуск части песни. К сожалению, для радио так не работает. В прямом эфире мы не можем сделать перемотку вперёд!
Сейчас adblockradio.com предлагает три варианта фильтрации:
- уменьшение громкости
- переключение на другую станцию и возврат назад по окончании рекламы. Это актуально, если пользователь слушает разговорную передачу. Во время рекламы он временно переключается на музыкальную станцию.
- постоянное переключение на другую станцию. Полезно при прослушивании музыкальных станций.
Я изо всех старался сделать максимально удобно, но система по-прежнему сложная. Не такая простая, как обычное радио или блокировщик рекламы на компьютере, который можно установить и забыть. Очень рассчитываю на помощь коллективного разума.

Текущий веб-интерфейс Adblock Radio

Прежний прототип, который так и не вышел. Здесь
