[Перевод] Распределенное обучение с Apache MXNet и Horovod
Перевод статьи подготовлен в преддверии старта курса «Промышленный ML на больших данных»
Распределенное обучение на нескольких высокопроизводительных вычислительных экземплярах может сократить время обучения современных глубоких нейронных сетей на большом объеме данных с нескольких недель до часов или даже минут, что делает эту технику обучения превалирующей в вопросах практического использования глубокого обучения. Пользователи должны понимать, как делиться и синхронизировать данные на нескольких экземплярах, что в свою очередь оказывает большое влияние на эффективность масштабирования. Помимо этого, пользователи также должны знать, как развернуть на нескольких экземплярах обучающий скрипт, который работает на одном экземпляре.
В этой статье мы поговорим про быстрый и простой способ распределенного обучения с использованием открытой библиотеки для глубокого обучения Apache MXNet и фреймворка распределенного обучения Horovod. Мы наглядно покажем преимущества фреймфорка Horovod в вопросах производительности и продемонстрируем, как написать обучающий скрипт MXNet так, чтобы он работал распределенно с Horovod.
Что такое Apache MXNet
Apache MXNet — открытый фреймворк для глубокого обучения, который используется для создания, обучения и развертывания глубоких нейронных сетей. MXNet абстрагирует сложности, связанные с реализацией нейронных сетей, обладает высокой производительностью и масштабируемостью, а также предлагает API для популярных языков программирования, таких как Python, C++, Clojure, Java, Julia, R, Scala и других.
Распределенное обучение в MXNet с сервером параметров
Стандартный модуль распределенного обучения в MXNet использует подход сервера параметров (parameter server). Он использует набор серверов параметров для сбора градиентов с каждого воркера, выполнения агрегации и отправки обновленных градиентов обратно ворекрам для следующей итерации оптимизации. Определение правильного соотношения серверов к воркерам — залог эффективного масштабирования. Если сервер параметров всего один, он может оказаться бутылочным горлышком в проведении вычислений. И наоборот, если используется слишком много серверов, то связь «многие-ко-многим» может забить все сетевые соединения.
Что такое Horovod
Horovod — открытый фреймворк распределенного глубокого обучения, разработанный в Uber. Он использует эффективные технологии взаимодействия между несколькими GPU и узлами, такие как NVIDIA Collective Communications Library (NCCL) и Message Passing Interface (MPI) для распределения и агрегирования параметров модели между ворекрами. Он оптимизирует использование пропускной способности сети и хорошо масштабируется при работе с моделями глубоких нейронных сетей. В настоящее время он поддерживает несколько популярных фреймворков машинного обучения, а именно MXNet, Tensorflow, Keras, и PyTorch.
Интеграция MXNet и Horovod
MXNet интегрируется с Horovod через API распределённого обучения, определенные в Horovod. В Horovod коммуникационные API horovod.broadcast (), horovod.allgather () и horovod.allreduce () реализованы с помощью асинхронных коллбэков движка MXNet, как часть его графа задач. Таким образом, зависимости данных между коммуникацией и вычислениями с легкостью обрабатываются движком MXNet, чтобы избежать потерь производительности из-за синхронизации. Объект distributed optimizer, определенный в Horovod horovod.DistributedOptimizer расширяет Optimizer в MXNet таким образом, чтобы он вызывал соответствующие API Horovod для распределенного обновления параметров. Все эти детали реализации прозрачны для конечных пользователей.
Быстрый старт
Вы можете быстро начать обучать небольшую сверточную нейронную сеть на наборе данных MNIST с помощью MXNet и Horovod на вашем MacBook.
Для начала установите mxnet и horovod из PyPI:
pip install mxnet
pip install horovodПримечание: Если у вас возникает ошибка во время pip install horovod, возможно, вам нужно добавить переменную MACOSX_DEPLOYMENT_TARGET=10.vv, где vv — это версия вашей версии MacOS, например, для MacOSX Sierra нужно будет написать MACOSX_DEPLOYMENT_TARGET=10.12 pip install horovod
Затем установите OpenMPI отсюда.
В конце загрузите тестовый скрипт mxnet_mnist.py отсюда и выполните следующие команды в терминале MacBook в рабочей директории:
mpirun -np 2 -H localhost:2 -bind-to none -map-by slot python mxnet_mnist.pyТак вы запустите обучение на двух ядрах вашего процессора. На выходе будет следующее:
INFO:root:Epoch[0] Batch [0-50] Speed: 2248.71 samples/sec accuracy=0.583640
INFO:root:Epoch[0] Batch [50-100] Speed: 2273.89 samples/sec accuracy=0.882812
INFO:root:Epoch[0] Batch [50-100] Speed: 2273.39 samples/sec accuracy=0.870000Демонстрация производительности
При обучении модели ResNet50-v1 на наборе данных ImageNet на 64 GPU с восемью экземплярами p3.16xlarge EC2, каждый из которых содержит 8 GPU NVIDIA Tesla V100 на AWS cloud, мы достигли пропускной способности обучения 45000 изображений/сек (т.е. количество обученных сэмплов в секунду). Обучение завершалось за 44 минуты после 90 эпох с лучшей точностью в 75.7%.
Мы сравнили это с распределенным обучением MXNet с подходом использования серверов параметров на 8, 16, 32 и 64 GPU с сервером с одним параметром и отношением серверов к воркерам 1 к 1 и 2 к 1 соответственно. Результат вы можете увидеть на Рисунке 1 ниже. По оси y слева столбцы отражают количество изображений для обучения в секунду, линии отражают эффективность масштабирования (то есть отношение фактической пропускной способности к идеальной) на оси y справа. Как видите выбор количества серверов оказывает влияние на эффективность масштабирования. Если сервер параметров один, эффективность масштабирования падает до 38% на 64 GPU. Для достижения такой же эффективности масштабирования как с Horovod нужно увеличить количество серверов в два раза по отношению к количеству воркеров.
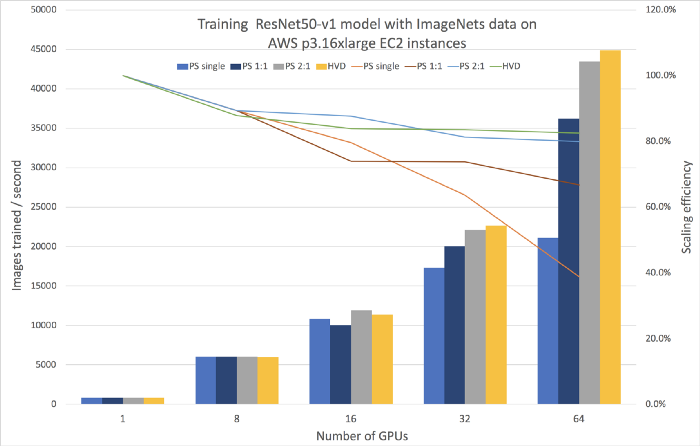
Рисунок 1. Сравнение распределённого обучения с использованием MXNet с Horovod и с сервером параметров
В Таблице 1 ниже мы сравнили итоговую стоимость экземпляра при выполнении экспериментов на 64 GPU. Использование MXNet вместе с Horovod обеспечивает наилучшую пропускную способность при наименьших затратах.

Таблица 1. Сравнение затрат между Horovod и сервером параметров с соотношением серверов к воркерам 2 к 1.
Шаги для воспроизведения
В следующих шагах мы расскажем, как воспроизвести результат распределенного обучения с помощью MXNet и Horovod. Чтобы узнать больше о распределенном обучении с MXNet прочитайте этот пост.
Шаг 1
Создайте кластер однородных экземпляров с MXNet версии 1.4.0 или выше и Horovod версии 0.16.0 или выше, чтобы использовать распределенное обучение. Вам также нужно будет установить библиотеки для обучения на GPU. Для наших экземпляров мы выбрали Ubuntu 16.04 Linux, с GPU Driver 396.44, CUDA 9.2, библиотеку cuDNN 7.2.1, коммуникатор NCCL 2.2.13 и OpenMPI 3.1.1. Также вы можете использовать Amazon Deep Learning AMI, где эти библиотеки уже предустановлены.
Шаг 2
Добавьте в свой обучающий скрипт MXNet возможность работы с API Horovod. Приведенный ниже скрипт на основе MXNet Gluon API можно использовать как простой шаблон. Строки, выделенные жирным, нужны в том случае, если у вас уже есть соответствующий обучающий скрипт. Вот несколько критических изменений, которые необходимо внести для обучения с Horovod:
- Установите контекст в соответствии с локальным рангом Horovod (строка 8), чтобы понимать, что обучение выполняется на правильном графическом ядре.
- Передайте начальные параметры от одного воркера ко всем (строка 18), чтобы убедиться, что все воркеры начинают работу с одинаковыми начальными параметрами.
- Создайте Horovod DistributedOptimizer (строка 25), чтобы обновлять параметры распределенно.
Чтобы получить полный скрипт, обратитесь к примерами Horovod-MXNet MNIST и ImageNet.
1 import mxnet as mx
2 import horovod.mxnet as hvd
3
4 # Horovod: initialize Horovod
5 hvd.init()
6
7 # Horovod: pin a GPU to be used to local rank
8 context = mx.gpu(hvd.local_rank())
9
10 # Build model
11 model = ...
12
13 # Initialize parameters
14 model.initialize(initializer, ctx=context)
15 params = model.collect_params()
16
17 # Horovod: broadcast parameters
18 hvd.broadcast_parameters(params, root_rank=0)
19
20 # Create optimizer
21 optimizer_params = ...
22 opt = mx.optimizer.create('sgd', **optimizer_params)
23
24 # Horovod: wrap optimizer with DistributedOptimizer
25 opt = hvd.DistributedOptimizer(opt)
26
27 # Create trainer and loss function
28 trainer = mx.gluon.Trainer(params, opt, kvstore=None)
29 loss_fn = ...
30
31 # Train model
32 for epoch in range(num_epoch):
33 ...Шаг 3
Войдите в один из воркеров для запуска распределённого обучения с помощью директивы MPI. В данном примере, распределенное обучение запускается на четырех экземплярах с 4 GPU в каждом, и с 16 GPU в кластере по итогу. Будет использоваться оптимизатор стохастического градиентного спуска (SGD) со следующими гиперпараметрами:
- mini-batch size: 256
- learning rate: 0.1
- momentum: 0.9
- weight decay: 0.0001
По мере масштабирования от одного GPU к 64 GPU мы линейно масштабировали скорость обучения в соответствии с количеством GPU (от 0,1 для 1 GPU до 6,4 для 64 GPU), сохраняя при этом количество изображений, приходящихся на один GPU, равным 256 (от пакета в 256 изображений для 1 GPU до 16 384 для 64 GPU). Параметры weight decay и momentum изменялись по мере увеличения числа GPU. Мы использовали смешанную точность обучения с типом данных float16 при прямом проходе и float32 для градиентов, чтобы ускорить вычисления float16, поддерживаемые GPU NVIDIA Tesla.
$ mpirun -np 16 \
-H server1:4,server2:4,server3:4,server4:4 \
-bind-to none -map-by slot \
-mca pml ob1 -mca btl ^openib \
python mxnet_imagenet_resnet50.pyЗаключение
В этой статье мы рассмотрели масштабируемый подход к распределенному обучению модели с использованием Apache MXNet и Horovod. Мы показали эффективность масштабирования и экономическую эффективность по сравнению с подходом с использованием сервера параметров на наборе данных ImageNet, на котором обучалась модель ResNet50-v1. Также мы отразили шаги, с помощью которых вы можете изменить уже существующий скрипт, чтобы запустить обучение на нескольких экземплярах с помощью Horovod.
Если вы только начинаете работать с MXNet и глубоким обучением, перейдите на страницу установки MXNe, чтобы сначала собрать MXNet. Также настоятельно рекомендуем почитать статью MXNet in 60 minutes, чтобы начать работу.
Если вы уже работали с MXNet и хотите попробовать распределенное обучение с Horovod, то загляните на страницу установки Horovod, соберите его с MXNet и следуйте примеру MNIST или ImageNet.
*стоимость рассчитывается на основании почасовой ставки AWS для экземпляров EC2
Узнать подробнее о курсе «Промышленный ML на больших данных»
