[Перевод] RabbitMQ tutorial 6 — Удаленный вызов процедур
В продолжение пятого урока по изучению азов RabbitMQ, публикую перевод шестого урока с официального сайта. Все примеры написаны на python (используется pika версии 0.9.8), но по-прежнему их можно реализовать на большинстве популярных ЯП.Во втором уроке мы рассмотрели использование очередей задач для распределения ресурсоёмких задач между несколькими подписчиками.Но что если мы захотим запустить функцию на удаленной машине и дождаться результата? Ну, это совсем другая история. Этот шаблон широко известен как Удаленный Вызов Процедур (Remote Procedure Call или RPC, далее в тексте RPC).В этом руководстве мы построим, используя RabbitMQ, RPC систему, которая будет включать клиент и масштабируемый RPC сервер. Так как у нас нет реальной трудоемкой задачи требующей распределения, мы создадим простой RPC сервер, возвращающий числа Фибоначчи.
Интерфейс клиентаДля иллюстрации использования RPC службы, создадим простой клиентский класс. Этот класс будет содержать метод call, который будет отправлять RPC запросы и блокироваться до получения ответа: fibonacci_rpc = FibonacciRpcClient () result = fibonacci_rpc.call (4) print «fib (4) is %r» % (result,) Замечание о RPC Несмотря на то, что RPC довольно распространенный шаблон, его часто критикуют. Проблемы обычно возникают, когда разработчик не знает точно, какую функцию он использует: локальную или медленную, выполняющуюся посредством RPC. Неразбериха, вроде этой, может вылиться в непредсказуемость поведения системы, а также вносит излишнюю сложность в процесс отладки. Таким образом, вместо упрощения программного обеспечения неверное использование RPC может привести к не обслуживаемому и не читаемому коду.С учетом вышеизложенного можно дать следующие рекомендации:
Убедитесь, что это очевидно, какая функция вызывается в каждом конкретном случае: локальная или удаленная; Документируйте вашу систему. Делайте зависимости между компонентами явными; Обрабатывайте ошибки. Как должен реагировать клиент, если RPC сервер не отвечает в течение длительного промежутка времени? Если сомневаетесь — не используйте RPC. Если это возможно, используйте асинхронный конвейер вместо блокирующего RPC, когда результаты асинхронно передаются на следующий уровень обработки. Очередь результатов Вообще, совершать RPC через RabbitMQ легко. Клиент отправляет запрос и сервер отвечает на запрос. Чтобы получить ответ, клиент должен передать очередь для размещения результатов вместе с запросом. Давайте посмотрим как это выглядит в коде: result = channel.queue_declare (exclusive=True) callback_queue = result.method.queue
channel.basic_publish (exchange='', routing_key='rpc_queue', properties=pika.BasicProperties ( reply_to = callback_queue, ), body=request)
# …какой-то код для чтения ответного сообщения из callback_queue … Свойства сообщений В протоколе AMQP имеется 14 предопределенных свойств сообщений. Большинство из них используются крайне редко, за исключением следующих: delivery_mode: отмечает сообщение как «стойкое» (со значением 2) или «временное» (любое другое значение). Вы должны помнить это свойство по второму уроку. content_type: используется для описания формата представления данных (mime). К примеру, для часто используемого JSON формата хорошим тоном считается устанавливать это свойство в application/json. reply_to: обычно используется для указания очереди результатов correlation_id: свойство используется для сопоставления RPC ответов с запросами. Correlation id В методе, представленном выше, мы предлагали создавать очередь ответов для каждого RPC запроса. Это несколько избыточно, но, к счастью, есть способ лучше — давайте создадим общую очередь результатов для каждого клиента.Это поднимает новый вопрос, получив ответ из этой очереди не совсем ясно, какому запросу соответствует этот ответ. И тут нам пригодится свойство correlation_id. Мы будем присваивать этому свойству уникальное значение при каждом запросе. Позднее, когда мы извлечем полученный ответ из очереди ответов, основываясь на значении этого свойства мы сможем однозначно сопоставить запрос с ответом. Если встретим неизвестное значение в свойстве correlation_id, мы можем спокойно игнорировать это сообщение, так как оно не соответствует ни одному из наших запросов.
Вы могли бы поинтересоваться, почему мы планируем просто игнорировать неизвестные сообщения из очереди ответов, вместо того, чтобы прервать выполнение сценария? Это связано с вероятностью возникновения race condition на стороне сервера. Хотя это и маловероятно, но вполне возможен сценарий, при котором RPC сервер отправит нам ответ, но не успеет отправить подтверждение обработки запроса. Если это произойдет, перезапущенный RPC сервер снова будет обрабатывать данный запрос. Вот почему на клиенте мы должны корректно обрабатывать повторные ответы. Кроме того, RPC, в идеале, должен быть идемпотентен.
Итоги
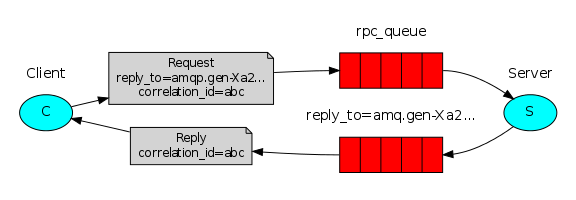 Наш RPC будет работать следующим образом: — Когда Клиент стартует, он создает анонимную уникальную очередь результатов.— Для совершения RPC запроса, Клиент отправляет сообщение с двумя свойствами: reply_to, где в качестве значения указывается очередь результатов и correlation_id, устанавливаемый в уникальное значение для каждого запроса.— Запрос отправляется в очередь rpc_queue.— Сервер ожидает запросы из этой очереди. Когда запрос получен, Сервер выполняет свою задачу и отправляет сообщение с результатом обратно Клиенту, используя очередь из свойства reply_to.— Клиент ожидает результат из очереди результатов. Когда сообщение получено, Клиент проверяет свойство correlation_id. Если оно соответствует значение из запроса, то результат отправляется приложению.
Наш RPC будет работать следующим образом: — Когда Клиент стартует, он создает анонимную уникальную очередь результатов.— Для совершения RPC запроса, Клиент отправляет сообщение с двумя свойствами: reply_to, где в качестве значения указывается очередь результатов и correlation_id, устанавливаемый в уникальное значение для каждого запроса.— Запрос отправляется в очередь rpc_queue.— Сервер ожидает запросы из этой очереди. Когда запрос получен, Сервер выполняет свою задачу и отправляет сообщение с результатом обратно Клиенту, используя очередь из свойства reply_to.— Клиент ожидает результат из очереди результатов. Когда сообщение получено, Клиент проверяет свойство correlation_id. Если оно соответствует значение из запроса, то результат отправляется приложению.
Собирая всё вместе Код сервера rpc_server.py: #!/usr/bin/env python import pika
connection = pika.BlockingConnection (pika.ConnectionParameters ( host='localhost'))
channel = connection.channel ()
channel.queue_declare (queue='rpc_queue')
def fib (n): if n == 0: return 0 elif n == 1: return 1 else: return fib (n-1) + fib (n-2)
def on_request (ch, method, props, body): n = int (body)
print » [.] fib (%s)» % (n,) response = fib (n)
ch.basic_publish (exchange='', routing_key=props.reply_to, properties=pika.BasicProperties (correlation_id = \ props.correlation_id), body=str (response)) ch.basic_ack (delivery_tag = method.delivery_tag)
channel.basic_qos (prefetch_count=1) channel.basic_consume (on_request, queue='rpc_queue')
print » [x] Awaiting RPC requests» channel.start_consuming () Серверный код довольно прост:
(4) Как обычно, мы устанавливаем соединение и объявляем очередь. (11) Объявляем нашу функцию, возвращающую числа Фибоначчи, которая принимает в качестве аргумента только целые положительные числа (эта функция вряд ли будет работать с большими числами, вероятнее всего это самая медленная из возможных реализаций). (19) Мы объявляем функцию обратного вызова on_request для basic_consume, которая и является ядром RPC сервера. Она исполняется когда запрос получен. Выполнив работу, функция отправляет результат обратно. (32) Вероятно, мы захотим когда-нибудь запустить более одного сервера. Для равномерного распределения нагрузки между несколькими серверами мы устанавливаем prefetch_count. Код клиента rpc_client.py:
#!/usr/bin/env python import pika import uuid
class FibonacciRpcClient (object): def __init__(self): self.connection = pika.BlockingConnection (pika.ConnectionParameters ( host='localhost'))
self.channel = self.connection.channel ()
result = self.channel.queue_declare (exclusive=True) self.callback_queue = result.method.queue
self.channel.basic_consume (self.on_response, no_ack=True, queue=self.callback_queue)
def on_response (self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body
def call (self, n): self.response = None self.corr_id = str (uuid.uuid4()) self.channel.basic_publish (exchange='', routing_key='rpc_queue', properties=pika.BasicProperties ( reply_to = self.callback_queue, correlation_id = self.corr_id, ), body=str (n)) while self.response is None: self.connection.process_data_events () return int (self.response)
fibonacci_rpc = FibonacciRpcClient ()
print » [x] Requesting fib (30)» response = fibonacci_rpc.call (30) print » [.] Got %r» % (response,) Код Клиента несколько сложнее:
(7) Мы устанавливаем соединение, канал и объявляем уникальную очередь результатов для полученных ответов. (16) Мы подписываемся на очередь результатов для получения ответов от RPC. (18) Функция обратного вызова 'on_response', исполнямая при получении каждого ответа, выполняет довольно тривиальную задачу — для каждого поступившего ответа она проверяет соответствует ли correlation_id тому что мы ожидаем. Если это так, она сохраняет ответ в self.response и прерывает цикл. (23) Далее, мы определяем наш метод call, который, собственно, и выполняет RPC запрос. (24) В этом методе мы сначала генерируем уникальный correlation_id и сохраняем его — функция обратного вызова 'on_response' будет использовать это значение для отслеживания нужного ответа (25) Далее мы помещаем запрос со свойствами reply_to и correlation_id в очередь. (32) Далее начинается процесс ожидания ответа. (33) И, в конце, мы возвращаем результат обратно пользователю. Наш RPC сервис готов. Мы можем запустить сервер:
$ python rpc_server.py [x] Awaiting RPC requests Для получения чисел Фибоначчи запускаем Клиент:
$ python rpc_client.py [x] Requesting fib (30) Представленный вариант реализации RPC не является единственным возможным, но он имеет следующие преимущества:
Если RPC сервер слишком медленный, вы можете легко добавить еще один. Попробуйте запустить второй rpc_server.py в новой консоли. На стороне Клиента, RPC требует отправки и получения только одного сообщения. Не требуется синхронный вызов queue_declare. Как результат, RPC клиент обходится одним циклом запрос-ответ для одного RPC запроса. Наш код, тем не менее, является упрощенным и даже не пытается решать более сложные (но, безусловно, важные) проблемы вроде таких:
Как должен реагировать Клиент, если сервер не запущен? Должен ли Клиент иметь таймоут для RPC? Если Сервер в какой-то момент «сломается» и выбросит исключение, должно ли оно передаваться Клиенту? Защита от недопустимых входящих сообщений (например, проверка допустимых границ) перед обработкой. Все статьи руководства RabbitMQ tutorial 1 — Hello World (python)RabbitMQ tutorial 2 — Очередь задач (python)RabbitMQ tutorial 3 — Публикация/Подписка (php)RabbitMQ tutorial 4 — Роутинг (php)RabbitMQ tutorial 5 — Тематики (php)RabbitMQ tutorial 6 — Удаленный вызов процедур (эта статья, python)
