[Перевод] Простой способ построения изотропных псевдослучайных рядов точек синего шума
В данной статье я описываю простой способ создания ряда точек, основанных на псевдослучайном ряде с низким расхождением, демонстрирующем улучшенные изотропные свойства синего шума. Он обеспечивает высокую скорость схождения с минимальными артефактами алиасинга.

Рисунок 1. Первые 100, 200, 500, 1000, 2000 и 5000 точек выборки из предлагаемого прогрессивного нестохастического ряда точек (уравнение 11), демонстрирующие почти изотропные характеристики синего шума с быстрой сходимостью QMC и сниженным количеством артефактов. Ряд основан на новой простой псевдослучайной последовательности с низким расхождением  .
.
Псевдослучайные ряды с низким расхождением применяются для создания распределений, являющихся менее регулярными, чем решётки, но более регулярными, чем простые случайные распределения (см. рисунок 2). Они играют важную роль во множестве областей численных вычислений, в том числе в физике, финансах, а в последнее время — и в компьютерной графике.

Рисунок 2. Сравнение регулярной решётки (слева) с тремя разными псевдослучайными функциями (посередине) и простым случайным распределением (справа). Заметьте, что псевдослучайные распределения выглядят менее регулярными, чем решётка, но имеют не так много скоплений и разрежений точек, как случайное распределение.
Классической статьёй о том, как использование псевдослучайного сэмплирования вместо равномерного сэмплирования может улучшить 2D-изображения, является Stochastic Sampling in Computer Graphics [Cook, 1986]. За последние десятилетия псевдослучайное сэмплирование стало важным инструментом 3D-рендеринга. Рендеринг (и сэмплеры) могут использовать для вычисления или ЦП, или GPU. Превосходным примером их использования в 3D-рендеринге является Anti-aliased Low Discrepancy Samplers for Monte Carlo Estimators in Physically Based Rendering [Perrier, 2108]. В этой статье автор рассказывает о задаче 3D-рендеринга (см. рисунок 3) следующим образом:
«При отображении 3D-объекта на компьютерном экране эта 3D-сцена превращается в 2D-изображение, являющееся множеством упорядоченных разноцветных пикселей. Мы называем рендерингом процесс, нацеленный на поиск нужных цветов этих пикселей. Это реализуется симуляцией и интегрированием всего освещения. Мы численно аппроксимируем уравнение, беря случайные сэмплы в области интегрирования и аппроксимируя значение интегрируемой функции при помощи методов Монте-Карло. Стохастический сэмплер должен минимизировать дисперсию интегрирования для схождения к правильной аппроксимации посредством как можно меньшего количества сэмплов. Существует множество различных сэмплеров, которые можно приблизительно разбить на два семейства:
— Сэмплеры синего ушма, имеющие низкую дисперсию интегрирования, но генерирующие неструктурированные множества точек. Проблема этих сэмплеров заключается в том, что часто они медленно генерируют множества точек.
— Сэмплеры с низким расхождением (Low Discrepancy), минимизирующие дисперсию интегрирования и способные очень быстро генерировать и заполнять множество точек. Однако при использовании в рендеринге они создают множество структурных артефактов».
В последнее время предпринимались попытки объединить преимущества сглаживания флуктуационного сэмплирования с высокой скоростью схождения (низкой дисперсией), характерной для псевдослучайных последовательностей с низким расхождением [Christensen, 2018]. С той же самой целью я представил новый способ построения бесконечного ряда точек, являющийся чрезвычайно простым, быстрым в вычислении, прогрессивным, полностью детерминированным, который демонстрирует быструю сходимость (низкую дисперсию) с нужным изотропным спектром синего шума, а следовательно, приводит к минимальным артефактам.
Итак, приступаем…
- простые флуктуационные (конечные) множества точек
- флуктуационные псевдослучайные множества точек
- флуктуации (бесконечных) псевдослучайных рядов
- сравнения сходимости QMC
- вывод
- пример кода
Наиболее простыми флуктуационными (возмущёнными) множествами точек являются флуктуационные сетки. В нашем случае пространство сэмплирования подразделено на сетку из  квадратных областей. Вместо простого выбора точки в центре каждой ячейки выбирается любая (псевдо-)случайная точка внутри каждой ячейки. Преимущества флуктуационного сэмплирования сетки заключаются в простоте понимания и реализации, а также в чрезвычайной скорости вычисления. Однако оно имеет очевидное ограничение —
квадратных областей. Вместо простого выбора точки в центре каждой ячейки выбирается любая (псевдо-)случайная точка внутри каждой ячейки. Преимущества флуктуационного сэмплирования сетки заключаются в простоте понимания и реализации, а также в чрезвычайной скорости вычисления. Однако оно имеет очевидное ограничение —  должен быть идеальным квадратом.
должен быть идеальным квадратом.
Хотя прямоугольное типологическое сэмплирование может снизить строгость этого ограничения так, чтобы был произведением двух соответствующих целых чисел, я опишу другой подход, который информативен, очень изящен и намного менее известен. Представим без потери обобщённости, что пространство сэмплирования является единичным квадратом  .
.
Мы определим решётку Фибоначчи как решётку из точек, где:

где  — золотое сечение, а
— золотое сечение, а  обозначает дробную часть
обозначает дробную часть  . Учтите, что при вычислениях этот оператор дробности обычно записывается и реализуется как
. Учтите, что при вычислениях этот оператор дробности обычно записывается и реализуется как  (произносится как «mod 1»), и поскольку этот пост в основном направлен на вычислительные области применения, в дальнейшем мы будем использовать эту запись.
(произносится как «mod 1»), и поскольку этот пост в основном направлен на вычислительные области применения, в дальнейшем мы будем использовать эту запись.
Стоит заметить, что решётка Фибоначчи — это очень изящный способ размещения любого количества точек в единичном квадрате чрезвычайно регулярным образом. Например, на рисунке 2a показана стандартная решётка Фибоначчи для N=41 точек. При флуктуационном сэмплировании вместо выбора в качестве сэмплируемых точек центров каждого диска мы можем просто выбрать точку  внутри каждого из дисков (см. рисунок 4b). Учитывая, что типичное расстояние между точками равно
внутри каждого из дисков (см. рисунок 4b). Учитывая, что типичное расстояние между точками равно  ,
,

где  означает, что для
означает, что для  -того члена случайный сэмпл берётся из центрированной в нуле окружности с радиусом
-того члена случайный сэмпл берётся из центрированной в нуле окружности с радиусом  .
.
Следует заметить, что простой прямой способ равномерного взятия сэмпла из окружности радиусом заключается в том, чтобы сначала взять два равномерных сэмпла  и
и  , каждый из которых находится в интервале
, каждый из которых находится в интервале  , а затем применить следующее преобразование:
, а затем применить следующее преобразование:

Разумеется, можно снизить степень флуктуаций, просто выбрав меньшее значение  .
.

Рисунок 4–1. (a) Каноническая решётка Фибоначчи; (b) флуктуационная решётка Фибоначчи.
Распределения точек, приблизительные радиальные спектральные функции и спектры Фурье этих множеств точек показаны ниже.

Рисунок 4–2. (a) Каноническая решётка Фибоначчи; (b) флуктуационная решётка Фибоначчи; и © случайные сэмплы.
Если известно заранее, то это простой, но эффективный способ создания изотропного множества точек.
Интересно то, что несмотря на интуитивное ощущение наличия между соседними точками постоянного расстояния, спектр Фурье для флуктуационного множества точек Фибоначчи не демонстрирует спектра классического синего шума. Тем не менее, эта флуктуационная версия очень хорошо подходит во многих областях применения и контекстах!
Однако известно, что существует множество превосходных способов создания изотропных множеств точек при известном заранее . В этом посте мы исследуем менее изученную область прямых построений для открытых/бесконечных изотропных рядов точек синего шума, в которых заранее неизвестно.
Более того, несмотря на чрезвычайно высокую скорость вычисления флуктуационной сетки и флуктуационной решётки Фибоначчи, они обе страдают от упорядочивания точек «строка за строкой». Часто более предпочтительны способы сэмпирования, при которых последовательные точки не находятся поблизости, а скорее «равномерно распределены» по всему пространству сэмплирования. Это свойство часто называют «прогрессивным сэмплированием».
Таким образом, мы исследуем практичность построения прогрессивных изотропных множеств и рядов точек синего шума.
Псевдослучайный ряд с низкой расходимостью — это (бесконечный) ряд точек, распределённых более равномерно, чем простое случайное распределение, но менее регулярно, чем решётки. Такие ряды полезны во многих областях применения, например, при интегрировании методом Монте-Карло. Существует множество типов псевдослучайных рядов, в том числе Вейла/Кронекера, ван дер Корпута/Холтона, Нидеррайтера и Соболя. Я подробно рассказывал о них, в том числе и о новом, в своём предыдущем посте: The unreasonable effectiveness of quasirandom sequences. В этом посте мы рассмотрим только один из описанных рядов — ряд . Для сравнения мы также рассмотрим ряд Холтона и ряд Соболя, поскольку сегодня их чаще всего используют в QMC.
Я приведу краткое изложение псевдослучайных рядов с низким расхождением, описанных в этом посте.
 : ряд — это рекурсивный ряд Кронекера/Вейла/Рихтмайера, представленный в моём предыдущем посте. Он основан на обобщении золотого сечения, а потому может рассматриваться как естественный способ построения обобщённой решётки Фибоначчи, соединяющейся слева направо и сверху вниз. Он задаётся следующим образом:
: ряд — это рекурсивный ряд Кронекера/Вейла/Рихтмайера, представленный в моём предыдущем посте. Он основан на обобщении золотого сечения, а потому может рассматриваться как естественный способ построения обобщённой решётки Фибоначчи, соединяющейся слева направо и сверху вниз. Он задаётся следующим образом:


Стоит заметить, что  , часто называемая пластической константой, имеет множество красивых свойств (также см. здесь).
, часто называемая пластической константой, имеет множество красивых свойств (также см. здесь).
Ряд Холтона:  -мерный ряд Холтона является независимыми от рядами обратного основания ван дер Корпута с покомпонентным сочленением. В этом посте мы будем придерживаться традиционной схемы с выбором в качестве оснований первых простых чисел. Следовательно, в этом посте я всегда буду использовать {2,3}-ряд Холтона.
-мерный ряд Холтона является независимыми от рядами обратного основания ван дер Корпута с покомпонентным сочленением. В этом посте мы будем придерживаться традиционной схемы с выбором в качестве оснований первых простых чисел. Следовательно, в этом посте я всегда буду использовать {2,3}-ряд Холтона.
Ряд Соболя: ряд Соболя имеет множество превосходных свойств низкого расхождения, в том числе высокие скорости схождения. В этом посте построение ряда Соболя (и выбор параметров) будет выполняться при помощи Mathematica версии 10. В документации Mathematica говорится, что реализация Соболя является «закрытыми, проприетарными и полностью оптимизированными генераторами из библиотеки MKL Intel».
В отличие от конечных множеств точек, ряды точек являются бесконечными. Ключевым преимуществом бесконечных рядов является то, что если погрешность спустя по-прежнему слишком велика, то можно просто сэмплировать дополнительные точки без необходимости повторного вычисления всех предыдущих точек. А преимущество сэмплирования на основе псевдослучайных рядов заключается в их прогрессивности. То есть каждая последующая точка проксимально далека от предыдущей, и при увеличении количества сэмплируемых точек они заполняют пространство сэмплирования равномерно.
На рисунке 5 показаны эти три ряда с низким расхождением вместе с их Фурье-преобразованиями и радиальными спектральными функциями. Мы можем это увидеть:
- Точки очень равномерно распределены. Для многих областей применения такое распределение идеально, но для других областей оно «слишком равномерно».
- во всех рядах с низким расхождением заметны чёткие паттерны, которые часто приводят к нежелательным артефактам, возникающим на отрендеренных при помощи QMC изображениях.
- спектры Фурье для всех рядов с низким расхождением состоят из множества пространственно регулярных пиков
- ни один из псевдослучайных множеств точек не является изотропным
- радиальная спектральная функция ряда состоит только из дискретного количества пиков.
- радиальные спектральные функции рядов Холтона и Соболя непрерывны, но не гладки.
То есть, артефакты рендеринга являются непосредственным результатом (i) дискретных ярких пиков в спектрах Фурье и/или (ii) дискретных пиков в радиальных спектральных функциях.
Краткое примечание о том, почему здесь может быть полезен термин «синий шум».
В общем смысле распределение можно назвать синим шумом, потому что его низкие (синие) частоты очевидно подавлены. Однако он состоит только из дискретных пиков, поэтому, возможно, лучше называть его «дискретным синим шумом» (или не называть его синим шумом вообще). В более общем контексте для «синего шума» требуются (i) изотропные спектры Фурье и (ii) радиальная спектральная функция, плоская как у белого шума, но с полностью подавленными низкими частотами. Превосходный обзор различных спектров синего шума см. в [Heck, 2012]
Кроме того, некоторые авторы [Perrier, 2018] замечают, что в большинстве способов сэмплирования диском Пуассона, например, в best candidate Митчелла, используется не строго синий шум, потому что их спектральные функции малы, но не равны нулю при наименьших частотах. В этом смысле лучше называть его «аппроксимированным синим шумом». Также замечают, что разница между почти нулём и полным нулём может сильно отрицательно влиять на скорость схождения.

Рисунок 5. Множества точек (n=2000), основанные на разных псевдослучайных рядах: (i) , (ii) Холтона; и (iii) Соболя, со (iv) случайным рядом для сравнения. Спектральные функции ни одного из псевдослучайных рядов не походят ни на случайный белый шум, ни на классический синий шум. Все они имеют заметные и регулярные дискретные пики, и ни один из них не является изотропным — два классических показателя того, что они будут создавать визуальные артефакты.
Мы бы хотели объединить преимущества сглаживания флуктуационного сэмплирования с быстрой сходимостью псевдослучайных рядов с низкой расходимостью, а потому:
главная цель этой статьи проста: определение минимального уровня флуктуаций, применяемого к псевдослучайным точкам таким образом, чтобы все пики Фурье оказались подавленными, преобразование стало изотропным, а радиальная спектральная функция для высоких частот стала плоской и равномерной — в идеале при этом нам нужно сохранить подавление низких частот.
Интуитивно понятно, что этот критический уровень флуктуаций будет тесно связан с типичным расстоянием (поделённым на  ) между соседними точками. На рисунке 6a показано минимальное расстояние между соседними точками для рядов , Холтона и Соболя. Стоит заметить, что ряд является единственным рядом с низким расхождением, при котором минимальное расстояние между соседними точками снижается со скоростью всего . Для рядов Холтона и Соболя расстояне падает с гораздо большими скоростями, близкими к
) между соседними точками. На рисунке 6a показано минимальное расстояние между соседними точками для рядов , Холтона и Соболя. Стоит заметить, что ряд является единственным рядом с низким расхождением, при котором минимальное расстояние между соседними точками снижается со скоростью всего . Для рядов Холтона и Соболя расстояне падает с гораздо большими скоростями, близкими к  . Аналогично, на рисунке 6b показано, что среднее расстояние между соседними точками не менее
. Аналогично, на рисунке 6b показано, что среднее расстояние между соседними точками не менее  для
для  при всех значений . Эти показатели дают понять, что идеальной будет флуктуация в пределах радиуса в половину этого значения. Эмпирические проверки подтверждают это.
при всех значений . Эти показатели дают понять, что идеальной будет флуктуация в пределах радиуса в половину этого значения. Эмпирические проверки подтверждают это.
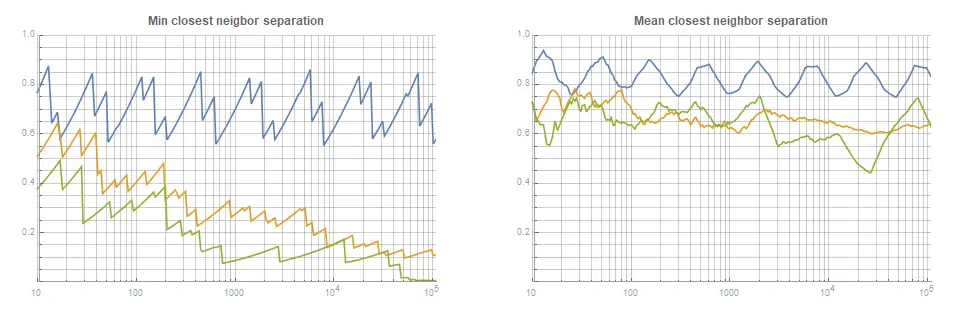
Рисунки 6a, 6b. Метрика ближайшего соседа для ряда (синий); Холтона (оранжевый); и Соболя (зелёный). Все показанные расстояния являются абсолютными расстояниями между ближайшими соседями, умноженными на  . Заметьте, что ряд является единственным, у которого минимальное расстояние падает со скоростью всего , у остальных оно падает со скоростью примерно . Также он имеет наибольшее среднее расстояние для всех значений
. Заметьте, что ряд является единственным, у которого минимальное расстояние падает со скоростью всего , у остальных оно падает со скоростью примерно . Также он имеет наибольшее среднее расстояние для всех значений  .
.
При помощи этого подхода был эмпирически определён критический радиус флуктуации для , Холтона и Соболя, показанные в таблице ниже. Соответствующие им распределения точек показаны на рисунке 5. Заметьте, что флуктуация для ряда Соболя должна снижаться гораздо медленнее чем  , чтобы маскировать его очень отчётливые артефакты, поэтому я не рекомендую его для любой области применения, но я всё равно представил его для полноты изучения.
, чтобы маскировать его очень отчётливые артефакты, поэтому я не рекомендую его для любой области применения, но я всё равно представил его для полноты изучения.

На рисунке 7 видно, что флуктуационный R2, флуктуационный Холтон и даже флуктуационный Соболь создают распределения точек изотропного синего шума.
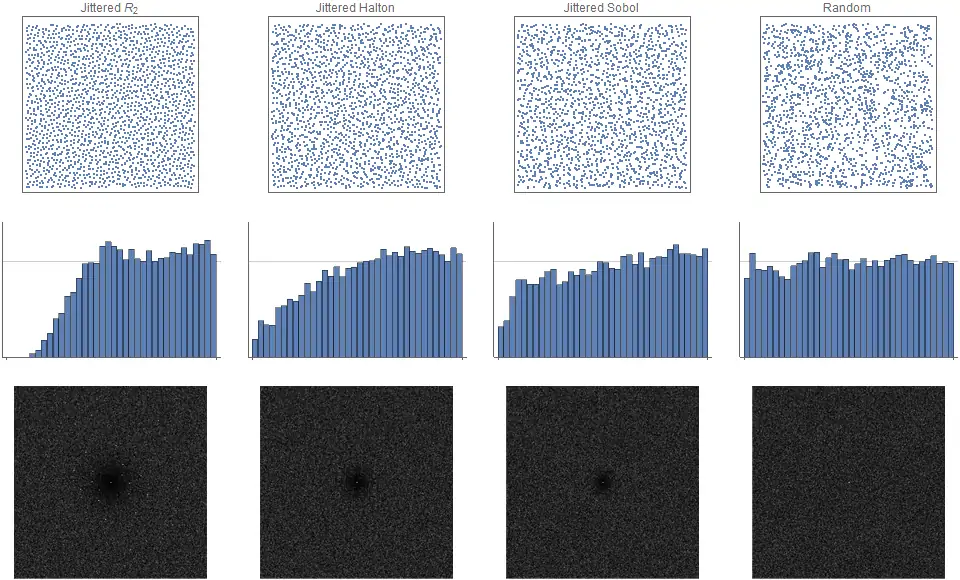
Рисунок 7. Флуктуационные множества точек (n=2000), основанные на различных псевдослучайных рядах: (i) , (ii) Холтона; и (iii) Соболя, со (iv) случайным для сравнения. Заметьте, что преобразование Фурье для всех псевдослучайных версий теперь изотропно, с небольшими, но наблюдаемыми признаками синего шума. Также заметьте, что флуктуация для ряда Соболя должна быть гораздо больше, чтобы замаскировать очень крупные артефакты. Стоит заметить, что радиальная спектральная функция флуктуационного R2 и флуктуационного Холтона кажется похожей на рандомизированные и флуктуационные сетки Оуэна (не показаны), но их спектры Фурье очень отличаются.
Стоит заметить, что для мы можем определить критический уровень флуктуации иным образом — как максимально возможный уровень флуктуаций, который обеспечивает нулевое значение радиальной спектральной функции для самых низких частот. Эмпирически это определение даёт нам для похожее значение  , но соответствующие уровни для Холтона и Соболя будут гораздо ниже указанных в таблице, и должны падать со скоростью
, но соответствующие уровни для Холтона и Соболя будут гораздо ниже указанных в таблице, и должны падать со скоростью  , а не
, а не  , как в случае .
, как в случае .
В связи с желательными спектрами Фурье часто требуется построение множеств точек с хорошим разделением между соседними точками. Ниже показаны минимальное и среднее расстояние для n=500 точек при различных методах. Помеченные звёздочкой данные взяты из статьи «Progressive Multi-jittered Sample Sequences» [Christensen, 2018], а жирным шрифтом указаны новые результаты. (Стандартные данные для Холтона и Соболя, а также общие данные для случайного рядаThe). Данные представлены в порядке убывания среднего расстояния.

Стоит также помнить, что расхождение формально является зависимой от площади метрикой. Она измеряет разницу между плотностью количества точек произвольной (прямоугольной) области распределения точек и плотностью точек, распределённых в равномерной решётке. В общем случае ряды с низким расхождением обычно ассоциируются с хорошими скоростями схождения.
В противовес расхождению, метрики разделения точек основаны на длине. Интуитивно понятно, что распределения с хорошим разделением точек обычно обладают низким расхождением, и наоборот. Поэтому на практике эти понятия очень близки и часто (произвольно и некорректно) используются как взаимозаменяемые. Однако иногда могут возникать тончайшие различия между этими отличающимися понятиями. Оптимальный ряд точек с низким расхождением может иметь хорошее, но неоптимальное разделение точек. И наоборот, ряды с идеальным разделением точек могут иметь хорошее, но неидеальное расхождение. Иными словами, «дисковые сэмплы best candidate имеют хорошее распределение пространства между точками, но неравномерное распределение в целом» [Christensen, 2018]. Это может помочь нам в более глубоком интуитивном понимании того, почему ряд Соболя имеет превосходные скорости схождения, но только неплохое разделение точек; и почему аппроксимированное дисковое сэмплирование может иметь почти оптимальные характеристики синего шума, но только неплохие скорости схождения.
Также стоит заметить, что если судить только по метрике минимального/среднего разделения точек, то покажется, что флуктуационные ряды Холтона на практике бесполезны и не отличимы от случайного шума. Однако из рисунка 4 чётко видно, что флуктуационный ряд Холтона демонстрирует меньше скоплений и пробелов, чем случайный шум. Следовательно, каждый ряд имеет свои достоинства и недостатки, а отдельные метрики только дают понимание об узком аспекте общих характеристик. (Ещё одна ключевая метрика, не указанная в этой таблице — время, необходимое для вычисления этих множеств точек. Большинство классических распределений синего шума основаны на методе принятия/отбрасывания или методик наподобие имитации отжига, а поэтому довольно медленны по сравнению с методами, вычисляющими точки напрямую.)
Следовательно, как мы все видели, теоретические метрики часто способствуют пониманию определённых аспектов, но не должны руководить окончательным выбором — такой выбор должен определяться теми измерениями и ограничениями реального мира, которые применимы в нашем конкретном контексте.
Коэффициент в уравнении (3) означает, что это выражение можно использовать только для конечных множеств точек.
Во многих случаях заранее неизвестно.
В ситуациях, когда известен аппроксимированный интервал (например,  ), на удивление хорошие результаты можно получить, присвоив размеру флуктуации фиксированное значение
), на удивление хорошие результаты можно получить, присвоив размеру флуктуации фиксированное значение  в пределах этого интервала. В нашем примере хорошо подойдёт значение
в пределах этого интервала. В нашем примере хорошо подойдёт значение  .
.
Однако такой аппроксимированный метод не полностью устраивает присутствующих среди нас пуристов! Если мы хотим подвергнуть флуктуации бесконечный ряд, то нам нужно полностью избавиться от этой зависимости от . К счастью, оказывается, что существует простая подстановка, позволяющая нам выполнять флуктуацию бесконечного ряда с неизменно хорошими результатами. Требуемая подстановка выглядит так:

То есть размер флуктуации для -той точки теперь является строго убывающей функцией от .
Следовательно, уравнение для флуктуации бесконечного ряда можно упростить:

Радиус флуктуации для каждого из бесконечных псевдослучайных рядов:

Распределение точек этого флуктуационного бесконечного ряда показан на рисунке 1 в самом начале статьи. Более того, как следует из рисунка 8, эта адаптация из флуктуации множества точек в флуктуацию бесконечного ряда практически никак визуально не влияет на качество!

Рисунок 8. Сравнение использования флуктуации замкнутого конечного множества точек (сверху) с флуктуацией открытого бесконечного ряда точек (внизу). Верхние ячейки — это три разных множества точек с N=100, N=300 и N=1000. Для сравнения: в ячейках внизу представлены первые 100, 300 и 1000 сэмплируемых точек одного бесконечного ряда точек. Заметьте, что качество соответствующих распределений визуально почти неразличимо.
Форма флуктуации
Выше мы обсуждали только радиальную флуктуацию. Эмпирические тесты показывают, что визуальная разница в качестве почти неразличима, если флуктуация просто основана на квадрате с длиной стороны  , а не на окружности радиуса . Хотя это имеет незначительное отрицательное влияние на спектры Фурье и некоторые метрики разделения точек, я не обнаружил измеримой разницы в скоростях схождения. Поэтому ради простоты и/или ускорения вычислений флуктуации можно упростить до
, а не на окружности радиуса . Хотя это имеет незначительное отрицательное влияние на спектры Фурье и некоторые метрики разделения точек, я не обнаружил измеримой разницы в скоростях схождения. Поэтому ради простоты и/или ускорения вычислений флуктуации можно упростить до

Размер флуктуаций
В отличие от рандомизации и перемешивания, которые по сути являются процессами вида «всё или ничего», мы можем управлять величиной применяемой флуктуации. Следовательно, мы можем ввести настраиваемый параметр  , определяющий степень флуктуации. То есть подвергнутые флуктуации точки можно вычислить так:
, определяющий степень флуктуации. То есть подвергнутые флуктуации точки можно вычислить так:
 для N= 600, подвергнутый флуктуации на разных уровнях. Заметьте, что
для N= 600, подвергнутый флуктуации на разных уровнях. Заметьте, что  соответствует исходному множеству точек без флуктуаций; при
соответствует исходному множеству точек без флуктуаций; при  мы получаем критический уровень флуктуаций;, а при
мы получаем критический уровень флуктуаций;, а при  .
.

Рисунок 9. Изменение относительного размера флуктуаций, от 0% до 100%. Где 100% представляет собой критический порог между исходным дискретным спектром Фурье и белым шумом. В общем случае наиболее визуально приятными оказываются значения в окрестности  . Меньшие значения означают пониженное расхождение, улучшенное разделение точек и ускорение схождения, но при этом увеличивается количество артефактов алиасинга.
. Меньшие значения означают пониженное расхождение, улучшенное разделение точек и ускорение схождения, но при этом увеличивается количество артефактов алиасинга.
Это последний фрагмент картины. Вас не должно удивлять, что случайные функции, используемые для применения флуктуаций, не обязаны обладать криптографическим качеством. Флуктуационное сэмплирование должно отвечать только довольно слабым критериям, поскольку оно играет вторичную роль в структуре распределения точек. Следовательно, там, где требуется простота и/или высокая скорость вычислений, можно (и нужно?) просто заменить всю рандомизацию самыми любимыми высокоскоростными функциями хеширования, выдающих значения в интервале .
Однако те пуристы среди читателей, которые обычно занимаются математикой или естественными науками, могут не посчитать такой подход полностью удовлетворительным, и без сомнений задаются вопросом: можно ли заменить всю рандомизацию полностью детерминированной функцией?
К счастью, на вопрос можно уверенно ответить положительно!
Насколько я знаю, пока нет опубликованных способов явного и детерминированного создания изотропных рядов точек синего шума. Все известные мне способы (для конечных множеств точек или открытых рядов) требуют перемешивания, перестановки, методов принятия/отбрасывания и/или итеративной релаксации.
Следовательно, одним из основных теоретических достижений этого поста является описание непосредственного создания детерминированного ряда точек при помощи изотропного синего шума.
Мы не только можем заменить случайные флуктуации полностью детерминированной функцией, но и структура предлагаемой формулы невероятно близка к структуре самого ряда . (Пока вы не спросили — как бы ни хотел я использовать для флуктуаций ряд с низким расхождением, все эмпирические тесты пока демонстрируют, что флуктуации должны быть намного «менее регулярными», так как каждая точка флуктуации должна быть более независимой от предыдущей точки, чем это оказывается в псевдослучайных рядах.)
Общеизвестно, что Вейл продемонстрировал следующее: для любого иррационального числа  дробная часть кратных величин имеет равномерное распределение. Очевидно, что это образует базис ряда . Менее известно то, что он также показал, что для почти любого числа
дробная часть кратных величин имеет равномерное распределение. Очевидно, что это образует базис ряда . Менее известно то, что он также показал, что для почти любого числа  распределена равномерно (см. fractional part of powers).
распределена равномерно (см. fractional part of powers).
То есть вместо выбора случайного числа из интервала мы можем выбрать константу -тый член этого ряда. В частности, для нашего случая, вместо и , являющихся случайными переменными из интервала , мы зададим  следующим образом:
следующим образом:

Если вы не работаете с ПО, автоматически обрабатывающим произв
