[Перевод] Понимаем JIT в PHP 8
Перевод статьи подготовлен в преддверии старта курса «Backend-разработчик на PHP»
TL; DR
Компилятор Just In Time в PHP 8 реализован как часть расширения Opcache и призван компилировать операционный код в инструкции процессора в рантайме.
Это означает, что с JIT некоторые операционные коды не должны интерпретироваться Zend VM, такие инструкции будут выполняться непосредственно как инструкции уровня процессора.
JIT в PHP 8
Одной из наиболее комментируемых фич PHP 8 является компилятор Just In Time (JIT). Он на слуху во множестве блогов и сообществ — вокруг него много шума, но пока я нашел не очень много подробностей о работе JIT в деталях.
После многократных попыток и разочарований найти полезную информацию, я решил изучить исходный код PHP. Совмещая свои небольшие познания языка С и всю разбросанную информацию, которую я смог собрать до сих пор, я сумел подготовить эту статью и надеюсь, что она поможет вам лучше понять JIT PHP.
Упрощая вещи: когда JIT работает должным образом, ваш код не будет выполняться через Zend VM, вместо этого он будет выполняться непосредственно как набор инструкций уровня процессора.
В этом вся идея.
Но чтобы лучше это понять, нам нужно подумать о том, как php работает внутри. Это не очень сложно, но требует некоторого введения.
Я уже писал статью с кратким обзором того, как работает php. Если вам покажется, что эта статья становится чересчур сложной, просто прочитайте ее предшественницу и возвращайтесь. Это должно немного облегчить ситуацию.
Как выполняется PHP-код?
Мы все знаем, что php — интерпретируемый язык. Но что это на самом деле означает?
Всякий раз, когда вы хотите выполнить код PHP, будь то фрагмент или целое веб-приложение, вам придется пройти через интерпретатор php. Наиболее часто используемые из них — PHP FPM и интерпретатор CLI. Их работа очень проста: получить код php, интерпретировать его и выдать обратно результат.
Это обычная картина для каждого интерпретируемого языка. Некоторые шаги могут варьироваться, но общая идея та же самая. В PHP это происходит так:
- Код PHP читается и преобразуется в набор ключевых слов, известных как токены (Tokens). Этот процесс позволяет интерпретатору понять, в какой части программы написан каждый фрагмент кода. Этот первый шаг называется лексирование (Lexing) или токенизация (Tokenizing).
- Имея на руках токены, интерпретатор PHP проанализирует эту коллекцию токенов и постарается найти в них смысл. В результате абстрактное синтаксическое дерево (Abstract Syntax Tree — AST) генерируется с помощью процесса, называемого синтаксическим анализом (parsing). AST представляет собой набор узлов, указывающих, какие операции должны быть выполнены. Например, «echo 1 + 1» должно фактически означать «вывести результат 1 + 1» или, более реалистично, «вывести операцию, операция — 1 + 1».
- Имея AST, например, гораздо проще понять операции и их приоритет. Преобразование этого дерева во что-то, что может быть выполнено, требует промежуточного представления (Intermediate Representation IR), которое в PHP мы называем операционный код (Opcode). Процесс преобразования AST в операционный код называется компиляцией.
- Теперь, когда у нас есть опкоды, происходит самое интересное: выполнение кода! PHP имеет движок под названием Zend VM, который способен получать список опкодов и выполнять их. После выполнения всех опкодов программа завершается.
Чтобы сделать это немного нагляднее, я составил диаграмму:
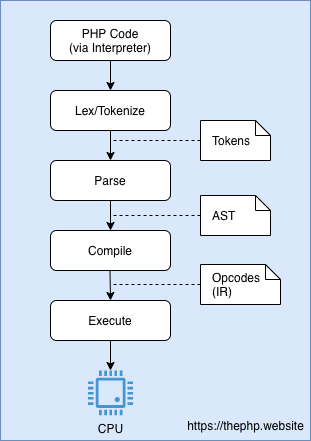
Упрощенная схема процесса интерпретации PHP.
Достаточно прямолинейно, как вы можете заметить. Но здесь есть и узкое место: какой смысл лексировать и парсить код каждый раз, когда вы его выполняете, если ваш php-код может даже не меняется так часто?
В конце концов, нас интересуют только опкоды, верно? Правильно! Вот зачем существует расширение Opcache.
Расширение Opcache
Расширение Opcache поставляется с PHP, и, как правило, нет особых причин его деактивировать. Если вы используете PHP, вам, вероятно, следует включить Opcache.
Что он делает, так это добавляет слой оперативного общего кэша для опкодов. Его задача состоит в том, чтобы извлекать опкоды, недавно сгенерированные из нашего AST, и кэшировать их, чтобы при дальнейших выполнениях можно было легко пропустить фазы лексирования и синтаксического анализа.
Вот схема того же процесса с учетом расширения Opcache:
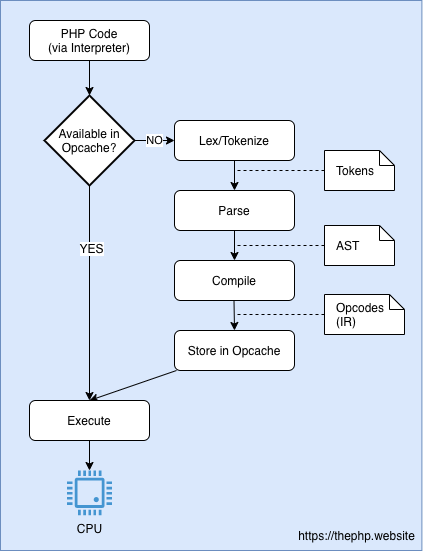
Поток интерпретации PHP с Opcache. Если файл уже был проанализирован, php извлекает для него кэшированный операционный код, а не анализирует его заново.
Это просто завораживает, как красиво пропускаются шаги лексирования, синтаксического анализа и компиляции.
Примечание: именно здесь лучше всего себя проявляет функция предварительной загрузки PHP 7.4! Это позволяет вам сказать PHP FPM анализировать вашу кодовую базу, преобразовывать ее в опкоды и кэшировать их даже до того, как вы что-либо выполните.
Вы можете начать задумываться, а куда сюда можно прилепить JIT, верно?! По крайней мере я на это надеюсь, именно поэтому я и пишу эту статью…
Что делает компилятор Just In Time?
Прослушав объяснение Зива в эпизоде подкастов PHP и JIT от PHP Internals News, мне удалось получить некоторое представление о том, что на самом деле должен делать JIT…
Если Opcache позволяет быстрее получать операционный код, чтобы он мог переходить непосредственно к Zend VM, JIT предназначить заставить его работать вообще без Zend VM.
Zend VM — это программа, написанная на C, которая действует как слой между операционным кодом и самим процессором. JIT генерирует скомпилированный код во время выполнения, поэтому php может пропустить Zend VM и перейти непосредственно к процессору. Теоретически мы должны выиграть в производительности от этого.
Поначалу это звучало странно, потому что для компиляции машинного кода вам нужно написать очень специфическую реализацию для каждого типа архитектуры. Но на самом деле это вполне реально.
Реализация JIT в PHP использует библиотеку DynASM (Dynamic Assembler), которая отображает набор команд ЦП в конкретном формате в код сборки для многих различных типов ЦП. Таким образом, компилятор Just In Time преобразует операционный код в машинный код для конкретной архитектуры, используя DynASM.
Хотя одна мысль все-таки не давала мне покоя…
Если предварительная загрузка способна парсить php-код в операционный перед выполнением, а DynASM может компилировать операционный код в машинный (компиляция Just In Time), почему мы, черт возьми, не компилируем PHP сразу же на месте, используя Ahead of Time компиляцию?!
Одна из мыслей, на которые меня натолкнул эпизода подкаста, заключалась в том, что PHP слабо типизирован, то есть часто PHP не знает, какой тип имеет переменная, пока Zend VM не попытается выполнить определенный опкод.
Это можно понять, посмотрев на тип объединения zend_value, который имеет много указателей на различные представления типов для переменной. Всякий раз, когда виртуальная машина Zend пытается извлечь значение из zend_value, она использует макросы, подобные ZSTR_VAL, которые пытаются получить доступ к указателю строки из объединения значений.
Например, этот обработчик Zend VM должен обрабатывать выражение «меньше или равно» (<=). Посмотрите, как он разветвляется на множество различных путей кода, чтобы угадать типы операндов.
Дублирование такой логики вывода типов с помощью машинного кода неосуществимо и потенциально может сделать работу еще медленнее.
Финальная компиляция после того, как типы были оценены, также не является хорошим вариантом, потому что компиляция в машинный код является трудоемкой задачей ЦП. Так что компиляция ВСЕГО во время выполнения — плохая идея.
Как ведет себя компилятор Just In Time?
Теперь мы знаем, что не можем вывести типы, чтобы генерировать достаточно хорошую опережающую компиляцию. Мы также знаем, что компиляция во время выполнения стоит дорого. Чем же может быть полезен JIT для PHP?
Чтобы сбалансировать это уравнение, JIT PHP пытается скомпилировать только несколько опкодов, которые, по его мнению, того стоят. Для этого он профилирует коды операций, выполняемые виртуальной машиной Zend, и проверяет, какие из них имеет смысл компилировать. (в зависимости от вашей конфигурации).
Когда определенный опкод компилируется, он затем делегирует выполнение этому скомпилированному коду вместо делегирования на Zend VM. Это выглядит как на диаграмме ниже:
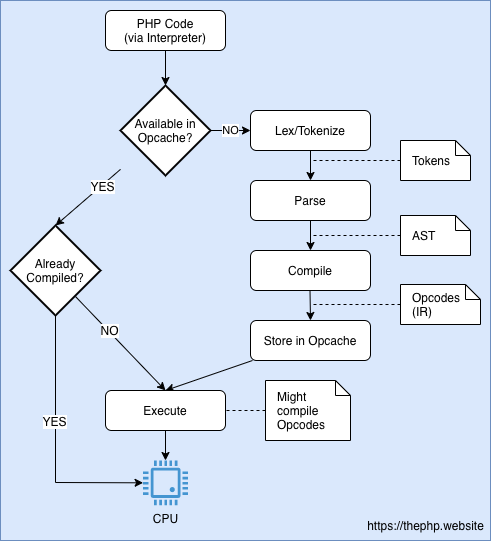
Поток интерпретации PHP с JIT. Если они уже скомпилированы, опкоды не выполняются через Zend VM.
Таким образом, в расширении Opcache есть пара инструкций, определяющих, должен ли определенный операционный код быть скомпилирован или нет. Если да, то компилятор преобразует его в машинный код с помощью DynASM и выполняет этот новый сгенерированный машинный код.
Интересно, что, поскольку в текущей реализации есть ограничение в мегабайтах для скомпилированного кода (также настраиваемое), выполнение кода должно иметь возможность беспрепятственного переключения между JIT и интерпретируемым кодом.
Кстати, эта беседа Бенуа Жакемона о JIT от php ОЧЕНЬ помогла мне разобраться во всем этом.
Я до сих пор не уверен в том, в каких конкретных случаях происходит компиляция, но я думаю, что пока не очень хочу это знать.
Так что, вероятно, ваш прирост производительности не будет колоссальным
Я надеюсь, что сейчас гораздо понятнее, ПОЧЕМУ все говорят, что большинство приложений php не получат больших преимуществ в производительности от использования компилятора Just In Time. И почему рекомендация Зива для профилирования и эксперимента с различными конфигурациями JIT для вашего приложения — лучший путь.
Скомпилированные опкоды обычно будут распределены между несколькими запросами, если вы используете PHP FPM, но это все равно не изменит правила игры.
Это потому, что JIT оптимизирует операции с процессором, а в настоящее время большинство php-приложений в большей степени завязаны на вводе/выводе, нежели на чем-либо еще. Не имеет значения, скомпилированы ли операции обработки, если вам все равно придется обращаться к диску или сети. Тайминги будут очень похожи.
Если только…
Вы делаете что-то не завязанное на ввод/вывод, например, обработку изображений или машинное обучение. Все, что не касается ввода/вывода, получит пользу от компилятора Just In Time. Это также причина, по которой люди сейчас говорят, что они склоняются больше к написанию нативных функций PHP, написанных на PHP, а не на C. Накладные расходы не будут разительно отличаться, если такие функции будут скомпилированы в любом случае.
Интересное время быть программистом PHP…
Я надеюсь, что эта статья была полезна для вас, и вам удалось лучше разобраться, что такое JIT в PHP 8. Не стесняйтесь связываться со мной в твиттере, если вы хотите добавить что-то, что я мог забыть здесь, и не забудьте поделиться этим со своими коллегами-разработчиками, это, несомненно, добавит немного пользы вашим беседам! -- @nawarian
PHP: статические анализаторы кода
