[Перевод] Почему так сложно извлекать текст из PDF?
Перевод статьи с сайта компании FilingDB, составляющей базу данных из документации европейских компаний
Согласно распространённым представлениям, извлечение текста из PDF не должно быть такой уж сложной задачей. Ведь вот он, текст, прямо у нас перед глазами, и люди постоянно и с большим успехом воспринимают содержимое PDF. Откуда взяться трудностям в автоматическом извлечении текста?
Оказывается, точно так же, как работа с именами людей сложна для алгоритмов из-за множества пограничных случаев и неправильных предположений, так и работа с PDF сложна из-за чрезвычайной гибкости PDF-формата.
Основная проблема в том, что PDF не предполагался как формат для ввода данных — его разрабатывали, как канал вывода, дающий возможность тонкой подстройки вида итогового документа.
По сути, формат PDF состоит из потока инструкций, описывающих, как создаётся изображение на странице. В частности, текстовые данные хранятся не в виде параграфов — или даже слов –, а в виде символов, нарисованных на определённых местах в странице. В итоге при преобразовании текста или документа Word в PDF большая часть семантики контента теряется. Вся внутренняя структура текста превращается в аморфный суп из плавающих на странице символов.
Наполняя FilingDB, мы извлекли текстовые данные из десятков тысяч PDF-документов. В процессе мы наблюдали за тем, как оказались неверными абсолютно все наши предположения о структуре PDF-файлов. Наша миссия оказалась особенно трудной потому, что нам приходилось обрабатывать PDF-документы, приходящие от разных источников, с совершенно разными стилями, шрифтами и внешним видом.
Ниже описывается, какие особенности PDF-файлов делают сложной или даже невозможной задачу извлечения из них текста.
Защита от чтения PDF
Вы могли встречать PDF-файлы, запрещающие копировать из них текстовое содержимое. К примеру, вот, что выдаёт программа SumatraPDF при попытке скопировать текст из защищённого от копирования документа:

Интересно, что текст виден, но при этом программа для просмотра отказывается передавать выделенный текст в буфер обмена.
Это реализовано при помощи нескольких флагов с «разрешениями доступа», один из которых управляет разрешением на копирование. Важно понимать, что сам PDF-файл это делать не заставляет — его содержимое от этого не меняется, и задача по его реализации лежит полностью на программе для просмотра.
Естественно, это на самом деле не защищает от извлечения текста из PDF, поскольку любая достаточно продвинутая библиотека для работы с PDF позволит пользователю либо поменять эти флаги, либо проигнорировать их.
Символы за пределами страниц
Частенько в PDF можно встретить больше текстовых данных, чем те, что показаны на странице. Возьмём эту страницу из ежегодного отчёта Nestle за 2010-й.
К этой странице прикреплено больше текста, чем видно. В частности, в содержимом, связанном с нею, можно найти следующее:
KitKat отметила свой 75-й день рождения в 2010-м, но остаётся молодой и успевает за тенденциями, имея более 2,5 млн фанатов на Facebook. Её продукция продаётся в более чем 70 странах, а продажи хорошо растут в развитых странах и на развивающихся рынках, например, на Среднем Востоке, в Индии и России. Япония — второй по величине рынок компании.
Этот текст расположен вне границ страницы, поэтому большинство просмотрщиков PDF его не показывают. Однако данные там есть, и их можно извлечь программно.
Такое иногда бывает из-за принимаемых в последнюю минуту решений о замене или удалении текста в процессе утверждения.
Мелкие или невидимые символы
Иногда на странице PDF можно встретить очень маленькие или вообще невидимые символы. Вот, к примеру, страница из отчёта Nestle за 2012 год.

На странице имеется мелкий белый текст на белом фоне, где написано следующее:
Wyeth Nutrition logo Identity Guidance to marketsVevey Octobre 2012 RCC/CI&D
Иногда это делается для повышения доступности, с теми же целями, которым служит тег alt в HTML.
Слишком много пробелов
Иногда в PDF между буквами слов вставлены дополнительные пробелы. Это наверняка сделано в целях кернинга (изменения интервала между символами).
К примеру, в отчёте Hikma Pharma от 2013 года есть такой текст:

Если его скопировать, получим:
ch a i r m a n ' s s tat em en t
В общем случае сложно решить задачу реконструкции исходного текста. Наиболее успешно у нас работает подход с применением оптического распознавания символов, OCR.
Недостаточно пробелов
Иногда в PDF не хватает пробелов, или они заменены другим символом.
Пример 1: следующая выдержка сделана из ежегодного отчёта SEB за 2017.

Извлечённый текст:
Tenyearsafterthefinancialcrisisstarted
Пример 2: отчёт Eurobank от 2013 содержит следующее:

Извлечённый текст:
On_April_7,_2013,_the_competent_authorities
И снова лучше всего оказалось использовать для таких страниц OCR.
Встроенные шрифты
PDF работает со шрифтами, мягко говоря, сложным образом. Чтобы понять, как хранятся в PDF текстовые данные, сначала нам нужно разобраться в глифах, названиях глифов и шрифтах.
- Глиф — это набор инструкций, описывающих, как изображать символ или букву.
- Название глифа — это название, связанное с этим глифом. К примеру, «торговая марка» для или «а» для глифа «а».
- Шрифт — это список глифов и связанных с ними названий. К примеру, в большинстве шрифтов есть глиф, который большинство людей распознает, как букву «а», при этом в разных шрифтах содержатся различные способы изображения этой буквы.
В PDF символы хранятся в виде чисел, кодов символов [codepoints]. Чтобы понять, что нужно выводить на экран, рендерер должен пройти цепочку от кода символа к названию глифа, а потом к самому глифу.
К примеру, PDF может содержать код символа 116, который он сопоставляет с названием глифа «t», который, в свою очередь, сопоставлен глифу, описывающему, как выводить на экран символ «t».
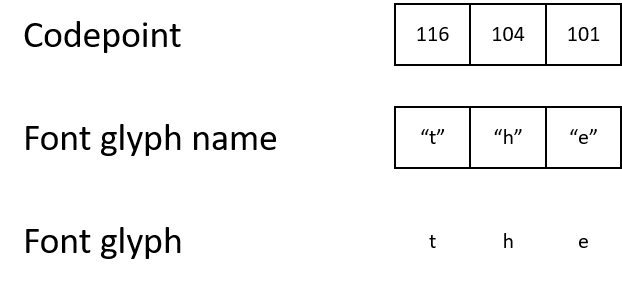
Большинство PDF используют стандартную кодировку символов. Кодировка символов — это набор правил, присваивающих смысл самим кодам символов. К примеру:
- В ASCII и Unicode для обозначения буквы «t«используется код символа 116.
- Unicode сопоставляет код символа 9786 глифу «белый смайлик», который выводится, как, а в ASCII такой код не определён.
Однако в PDF-документе иногда используется собственная кодировка символов и специальные шрифты. Это может показаться странным, но документ может обозначать букву «t» кодом символа 1. Он сопоставит код символа 1 названию глифа «c1», которое будет сопоставлено глифу, описывающему, как выводить букву «t».
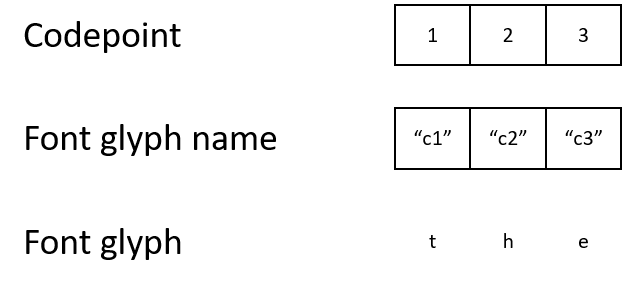
Хотя для человека итоговый результат ничем не отличается, машина запутается из-за таких кодов символов. Если коды символов не соответствуют стандартной кодировке, программным способом почти невозможно понять, что обозначают коды 1, 2 или 3.
Зачем же в PDF нужно включать нестандартные шрифты и кодировку?
- Одна причина — усложнить извлечение текста.
- Вторая — использование субшрифтов. В большинстве шрифтов есть глифы для очень большого числа кодовых символов, при этом в PDF может использоваться небольшое их подмножество. Для экономии места создатель PDF может обрезать все ненужные глифы и создать компактный субшрифт, который скорее всего будет использовать нестандартную кодировку.
Один из способов обойти это — извлечь глифы шрифтов из документа, прогнать их через OCR, построить соответствие между шрифтом и Unicode. Это позволит вама переводить кодировку, связанную со шрифтом, в Unicode, к примеру: код символа 1 соответствует названию «c1», которое, судя по глифу, должно обозначать «t», которому соответствует код Unicode 116.
Карта кодирования, которую вы только что сделали — та, что сопоставляет цифры 1 и 116 — называется в PDF-стандарте картой ToUnicode. В PDF-документах могут содержаться собственные карты ToUnicode, однако это не обязательно.
Распознавание слов и параграфов
Воссоздание параграфов и даже слов из аморфного символьного супа PDF-файлов — задача сложная.
PDF-документ содержит список символов на странице, а распознавать слова и параграфы должен потребитель. Люди от природы эффективно справляются с этим, поскольку чтение — навык распространённый.
Чаще всего используется алгоритм группировки, сравнивающий размеры, расположение и выравнивание символов, с целью определить, что является словом или параграфом.
У простейших реализаций таких алгоритмов сложность легко может достичь O (n²), из-за чего обработка плотно забитых страниц может проходить долго.
Порядок текста и параграфов
Распознавание текста и порядка параграфов — задача сложная по двум причинам.
Во-первых, иногда правильного ответа просто нет. Если у документов с обычным типографским набором с одной колонкой последовательность чтения выходит естественной, то у документов с более смелым расположением элементов определить её сложнее. К примеру, не совсем ясно, должна ли следующая вставка идти до, после или в середине статьи, рядом с которой она расположена:

Во-вторых, даже когда человеку ответ ясен, компьютеры определить точный порядок параграфов бывает очень сложно — даже с использованием ИИ. Возможно, это утверждение покажется вам чересчур смелым, но в некоторых случаях правильную последовательность параграфов можно определить, только понимая содержимое текста.
Рассмотрим данное расположение компонентов в два столбца, где описано приготовление овощного салата.

В западном мире разумно предположить, что чтение идёт слева направо и сверху вниз. Поэтому мы, не изучая содержимого текста, можем свести все варианты к двум: A B C D и A C B D.
Изучив содержание, поняв, о чём там говорится, и зная, что овощи моют перед нарезкой, мы можем понять, что правильным порядком будет A C B D. Алгоритмически это определить крайне сложно.
При этом «в большинстве случаев» работает подход, полагающийся на порядок хранения текста внутри PDF-документа. Обычно он соответствует порядку вставки текста во время создания. Когда большие отрезки текста содержат по многу параграфов, они обычно соответствуют тому порядку, который подразумевал их автор.
Встроенные изображения
Нередко часть содержимого документа (или весь документ) оказывается отсканированным изображением. В таких случаях в нём нет текстовых данных, и приходится прибегать к OCR.
К примеру, ежегодный отчёт Yell от 2011 года доступен только в виде скана:

Почему бы просто всё не распознать?
Хотя OCR может помочь с некоторыми описанными проблемами, у него тоже есть свои недочёты.
- Длительное время обработки. Запуск OCR на скане из PDF обычно отнимает на порядок больше времени (а то и ещё дольше), чем прямое извлечение текста из PDF.
- Сложности с нестандартными символами и глифами. Алгоритмам OCR сложно работать с новыми символами — смайликами, звёздочками, кружочками, квадратиками (в списках), надстрочными индексами, сложными математическими символами, и т.п.
- Нет подсказок о последовательности текста. Упорядочивать текст, извлекаемый из PDF-документа, легче, поскольку большую часть времени этот порядок соответствует порядку вставки текста в файл. При извлечении текста с изображений таких подсказок не будет.
Тестирование
Пока что мы ещё не упоминали о том, насколько сложно подтвердить, что текста был извлечён правильно или ожидаемо. Мы обнаружили, что лучше всего проводить обширный набор тестов, изучающих как базовые метрики (длину текста, длину страницы, соотношение количества слов и пробелов), так и более сложные (процент английских слов, процент нераспознанных слов, процент чисел), а также следить за предупреждениями типа подозрительных или неожиданных символов.
Что мы можем посоветовать для извлечения текста из PDF? Прежде всего убедиться, что у текста нет более удобного источника.
Если интересующие вас данные идут только в формате PDF, тогда важно понимать, что эта проблема кажется простой лишь на первый взгляд, а решить её со 100% точностью может и не получиться.
