[Перевод] Об ответственном использовании Google Таблиц в роли баз данных
Хотя технологии баз данных и другие подобные инструменты существуют много лет и в наши дни чрезвычайно развиты, им всё ещё нелегко обойти самые обычные электронные таблицы в плане универсальности и интуитивной понятности. Правда, базы данных, основанные на электронных таблицах, лучше не применять в по-настоящему серьёзных проектах. Например — в приложениях, используемых для работы с данными о тех, кто заболел COVID-19. Но тот факт, что буквально все вокруг знают о том, как пользоваться электронными таблицами, означает, что таблицы отлично подходят для маленьких проектов, реализуемых в разнородных командах, когда просматривать и редактировать данные может понадобиться людям, далёким от программирования.
В этом руководстве я расскажу о том, как использовать Google Таблицы в роли базы данных. Рассмотренный мной учебный проект будет оснащён API, работать с которым можно по HTTP. Здесь мы воспользуемся Autocode — платформой для разработки Node.js-API, поддерживающей удобный редактор кода. Мы развернём простое приложение и организуем процесс прохождения аутентификации Google. Кроме того, я расскажу об ограничениях Google Таблиц, среди которых можно отметить возможности их применения в больших проектах. Я расскажу и о ситуациях, в которых тем, кто пользуется Google Таблицами, есть смысл поискать более продвинутые альтернативы.

База данных, основанная на электронной таблице
Вот пример запроса к базе данных, основанной на электронной таблице, который возвращает записи обо всех людях и других существах, имена которых начинаются с bil. Регистр символов при этом не учитывается.
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/select/name/istartswith/?query=bil'
Вот что приходит в ответ на этот запрос:
[
{
"Name": "Bilbo Baggins",
"Job": "Burglar",
"Fictional": "TRUE",
"Born On": "9/21/1937",
"Updated At": ""
},
{
"Name": "Bill Nye",
"Job": "Scientist",
"Fictional": "FALSE",
"Born On": "11/27/1955",
"Updated At": ""
},
{
"Name": "billie eilish",
"Job": "Artist",
"Fictional": "FALSE",
"Born On": "12/18/2001",
"Updated At": ""
}
]
Для того чтобы воспроизвести у себя мои эксперименты вам понадобится лишь учётная запись Google и бесплатный аккаунт на autocode.com.
Краткий обзор проекта
Для тех, кому не терпится приняться за дело, я подготовил сильно сжатый вариант этого материала, приведённый в этом разделе.
Итак, для того чтобы воспользоваться Google Таблицами в роли базы данных, вам, для начала понадобится сделать себе копию моей таблицы, перейдя по этой ссылке и щёлкнув по кнопке Использовать шаблон, расположенной в правом верхнем углу страницы. В результате у вас, в вашей учётной записи Google, окажется таблица, с которой мы будем работать.
После того, как вы это сделаете, посетите эту страницу на сайте Autocode, дающую доступ к простому приложению, использующему Google Таблицы в роли базы данных. Если хотите — посмотрите код этого приложения, а потом установите его в своём аккаунте Autocode, нажав на большую зелёную кнопку. Когда вам предложат подключить приложение к таблице — следуйте инструкциям. Подключите к Autocode свою учётную запись Google и выберите таблицу, копию которой вы создали на предыдущем шаге.
После этого ваше приложение должно заработать! Попробуйте, воспользовавшись соответствующими URL, обратиться к нескольким конечным точкам, взгляните на то, что произойдёт, на то, как работает база данных, основанная на электронной таблице. Примеры запросов к базе данных можно найти ниже, в разделе Конечные точки.
Ограничения
Краткий обзор проекта может создать впечатление того, что работа с базой данных, основанной на Google Таблицах, организована крайне просто. Тут может возникнуть вопрос о том, почему соответствующий функционал не входит в состав инструментов, предлагаемых Google.
Хотя использование бэкенда, который можно подготовить к работе за 30 секунд, выглядит крайне привлекательным, особенно учитывая универсальность готового решения и широкие возможности по работе с данными, у такого подхода есть вполне очевидные ограничения. Так, при использовании электронной таблицы в роли базы данных в нашем распоряжении не будет возможностей, встроенных в платформу, позволяющих работать с несколькими таблицами, или позволяющих настраивать взаимоотношения таблиц. Тут нет концепции ограничения типов данных, хранящихся в столбцах таблиц, нет понятия «транзакция», нет встроенных средств создания резервных копий данных, нет стандартных средств шифрования. Поэтому важные данные, вроде тех, что связаны с COVID-19, вероятно, лучше хранить где-нибудь ещё.
Если говорить о масштабируемости решения, то размеры электронных таблиц, с которыми можно работать в сервисе Google Таблицы, жёстко ограничены 5000000 ячеек (включая пустые ячейки). Когда я попытался это проверить, то, создавая таблицу соответствующего размера, я встретился с серьёзными проблемами, касающимися производительности. Произошло это ещё до того, как таблица достигла максимально допустимого размера.
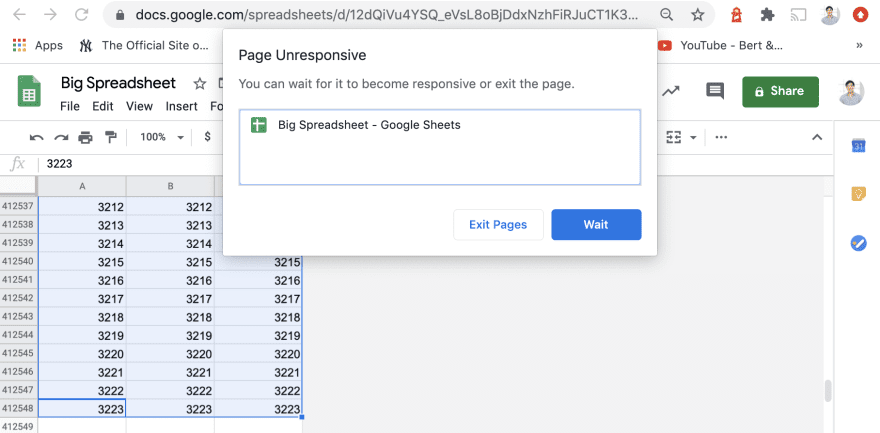
Проблемы с производительностью
Крупномасштабные операции, вроде вставки в таблицу большого количества ячеек, сначала замедляются, а потом, на уровне примерно в 1 миллион ячеек, начинают давать сбои. Работа с большими таблицами выглядит довольно медленной.
Мои эксперименты, касающиеся работы с таблицами посредством API, показали похожие результаты. А именно, возникает такое ощущение, что скорость выполнения запросов линейно зависит от количества ячеек.
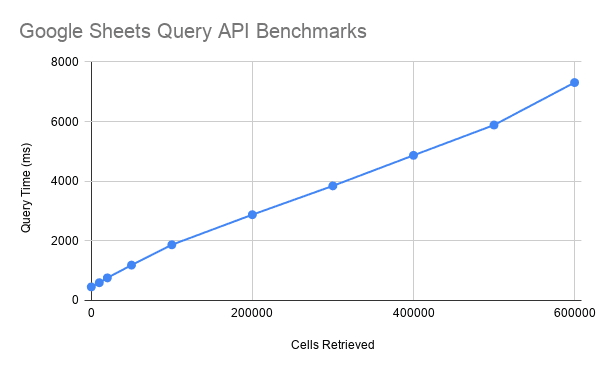
Исследования быстродействия API
Запросы становятся недопустимо медленными при достижении отметки примерно в 500000 ячеек. Но при этом запросы, если речь идёт о 100000 ячеек, выполняются менее чем за 2 секунды. Это говорит о том, что если вы планируете работать с наборами данных, размеры которых превышают несколько сотен тысяч ячеек, то, вероятно, разумнее будет выбрать что-то, лучше поддающееся масштабированию.
Работа с базой данных
После того, как вы подключили копию электронной таблицы к приложению на Autocode и установили это приложение в свою учётную запись, платформа Autocode сама решит вопросы аутентификации приложения в Google, используя его токен (взгляните на строку const lib = require('lib')({token: process.env.STDLIB_SECRET_TOKEN}), которая находится над кодом, имеющим отношение к конечным точкам).
В описании каждой конечной точки имеется Node.js-код, отвечающий за выполнение запроса, в котором вызываются методы API googlesheets.query. Эти методы принимают параметр range, содержащий данные в формате A1. Этот параметр описывает часть таблицы, которую вызов API должен считать частью базы данных.
let queryResult = await lib.googlesheets.query['@0.3.0'].select({
range: `A:E`,
bounds: 'FULL_RANGE',
where: [{
'Name__istartswith': query
}]
});
Значение A:E, записанное в range, представляет собой сокращённую запись следующего указания системе: «используй, в качестве базы данных, все строки в столбцах от A до E». Запрос интерпретирует первую строку каждого столбца этого диапазона как имя для данных, хранящихся в столбце. Если выполнить запрос, код которого показан выше, обратившись к таблице, копию которой вам предлагалось сделать в начале материала, то в ходе выполнения запроса будут проверены значения строк в столбце A (он называется Names), в них будет осуществляться поиск того, что задано параметром query.
Подобные обращения к API используют язык запросов KeyQL. На странице этого проекта, если интересно, вы можете найти его подробное описание и примеры запросов.
Обращение к конечным точкам
Как уже было сказано, к конечным точкам нашего API можно обращаться посредством HTTP-запросов. Поэтому с ними можно работать, используя fetch, cURL, или HTTP-клиент, который вам нравится. Для работы с ними можно пользоваться и браузером.
Обращение к API с использованием браузера
Можно даже воспользоваться той же Node.js-библиотекой, lib-node, которая применяется в коде конечных точек для вызова API Google Таблиц.
Использование lib-node
Конечные точки реагируют на GET — и POST-запросы. При обработке GET-запросов их параметры берутся из строки запроса. При обработке POST-запросов параметры берутся из тела запроса. У каждой конечной точки, чтобы сделать работу с ними понятнее, есть набор параметров, применяемых по умолчанию. Ниже приведены примеры работы с конечными точками нашей системы.
Конечные точки
▍functions/select/job/contains.js
Эта конечная точка демонстрирует пример реализации KeyQL-запроса contains. Она выполняет запросы на поиск строк таблицы, поле Job которых содержит подстроку (чувствительную к регистру), соответствующую параметру query. Выполним следующий запрос к базе данных, представленной нашей экспериментальной таблицей:
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/select/job/contains/?query=ist'
Вот каким будет результат выполнения этого запроса:
[
{
"Job": "Mistborn",
"Born On": "2006-07-17",
"Fictional": "TRUE",
"Name": "Vin Venture",
"Updated At": ""
},
{
"Job": "Scientist",
"Born On": "1955-11-27",
"Name": "Bill Nye",
"Fictional": "FALSE",
"Updated At": ""
},
{
"Job": "Artist",
"Born On": "2001-12-18",
"Name": "billie eilish",
"Fictional": "FALSE",
"Updated At": ""
}
]
▍functions/select/born_on/date_gt.js
Эта конечная точка реализует KeyQL-запрос date_gt. А именно, речь идёт о поиске строк, в которых значение поля Born On идёт после значения, заданного в query и представленного в формате ГГГГ/ММ/ДД. Опробуем эту конечную точку:
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/select/born_on/date_gt/?query=2000/01/01'
Вот что получится:
[
{
"Job": "Mistborn",
"Born On": "2006/07/17",
"Fictional": "TRUE",
"Name": "Vin Venture",
"Updated At": ""
},
{
"Job": "Artist",
"Born On": "2001/12/18",
"Name": "billie eilish",
"Fictional": "FALSE",
"Updated At": ""
}
]
▍functions/select/name/istartswith.js
В этой конечной точке используется KeyQL-запрос istartswith. Тут выполняется поиск строк таблицы, содержимое поля Name которых начинается с того, что задано с помощью query (без учёта регистра символов). Испытаем эту конечную точку:
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/select/name/istartswith/?query=bil'
Посмотрим на результаты выполнения запроса:
[
{
"Job": "Scientist",
"Born On": "1955-11-27",
"Name": "Bill Nye",
"Fictional": "FALSE",
"Updated At": ""
},
{
"Job": "Artist",
"Born On": "2001-12-18",
"Name": "billie eilish",
"Fictional": "FALSE",
"Updated At": ""
},
{
"Job": "Burglar",
"Born On": "1937-09-21",
"Fictional": "TRUE",
"Name": "Bilbo Baggins",
"Updated At": ""
}
]
▍functions/insert.js
Эта конечная точка реализует возможности по вставке данных в таблицу. Она, при вызове API googlesheets.query.insert, передаёт свои входные параметры в параметр fieldsets. Например, для того чтобы добавить в таблицу запись о человеке с именем Bill Gates, можно выполнить следующий запрос (все параметры записаны в нижнем регистре):
$ curl --request POST \
--header "Content-Type: application/json" \
--data '{"name":"Bill Gates","job":"CEO","fictional":false,"bornOn":"10/28/1955"}' \
--url 'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/insert/'
Обратите внимание на то, что API Autocode основано на понятных именах конечных точек, это сделано для того чтобы минимизировать число ошибок, которые могут возникнуть при работе с API.
▍functions/update.js
Эта конечная точка демонстрирует пример запроса на обновление данных. Речь идёт о запросе, который записывает соответствующее значение в поля Updated At строк таблицы, содержащих сведения о людях и других существах, имена которых в точности соответствуют параметру name. Этот запрос обновляет другие поля подобных записей в соответствии с параметрами, переданными конечной точке. Здесь используется API googlesheets.query.update.
Рассмотрим пример. Нам нужно обновить поле Job для записи, в поле Name которой записано Bilbo Baggins. Новым значением поля Job должно стать Ring Bearer. Достичь этой цели можно так:
$ curl --request POST \
--header "Content-Type: application/json" \
--data '{"name":"Bilbo Baggins","job":"Ring Bearer"}' \
--url 'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/update/'
Используя подобные запросы, учитывайте то, что они могут повлиять на множество строк, соответствующих параметрам таких запросов.
▍functions/delete.js
Эта конечная точка реализует запрос на удаление данных. В частности, она удаляет из таблицы записи, поле Name которых в точности соответствует параметру запроса name. Тут используется API googlesheets.query.delete.
Например, для удаления записи Bilbo Baggins из таблицы можно выполнить такой запрос:
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/delete/?name=Bilbo%20Baggins'
Подобный запрос, как и запрос на обновление данных, может воздействовать на несколько строк таблицы.
Пользуетесь ли вы Google Таблицами в роли баз данных?
