[Перевод] Почему KRaft заменил ZooKeeper

Зачем менять ZooKeeper на встроенный лог Apache Kafka® для управления метаданными? В этой статье вы узнаете, зачем нужна была эта замена, какие преимущества даёт протокол консенсуса на основе кворума, вроде Raft, и как работает контроллер кворума поверх протоколов KRaft.
Что не так с ZooKeeper?
Контроллер Kafka для репликации внутри кластера был реализован ещё в 2012 году и с тех пор почти не изменился: у каждого кластера есть один узел в роли контроллера, он выбирается вотчерами в ZooKeeper. Он хранит логи партиций, обрабатывает потребление/создание запросов, как другие брокеры, а ещё отвечает за метаданные кластера — ID и серверные стойки брокеров, топики, партиции, информацию о ведущих узлах и наборах синхронизированных реплик (in-sync replicas, ISR), конфигурации кластера и топиков, а также учётные данные для безопасности. Вся эта информация хранится в ZooKeeper как источник истины, в итоге почти все операции чтения и записи в ZooKeeper проходят через контроллер.
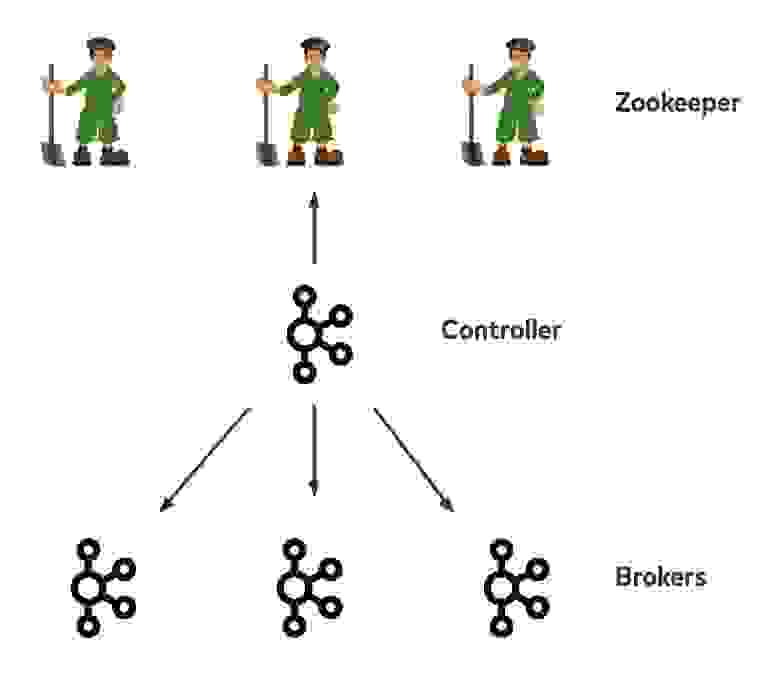
Иногда и другие брокеры, кроме контроллера, могут общаться с ZooKeeper напрямую, например, когда ведущий узел обновляет информацию о ISR. Контроллер регистрирует вотчеров в ZooKeeper в случае любого изменения метаданных. Метаданные могут меняться самим контроллером, другими брокерами или клиентами, которые записывают в ZooKeeper данные напрямую.
В большинстве случаев, когда такой вотчер срабатывает, контроллер обрабатывает его в однопоточном цикле и распространяет обновлённые метаданные по остальным брокерам. Если вы знакомы с историей Kafka, то в курсе, что раньше и другие клиенты, например, консьюмеры, могли общаться с ZooKeeper напрямую. Сейчас все проходит через брокеры, чтобы снизить нагрузку чтения/записи на серверы ZooKeeper. По большей части для доступа в ZooKeeper используется один контроллер, но когда брокеров и партиций в кластере становится больше, возникают узкие места, потому что ZooKeeper по-прежнему используется как источник истины для метаданных в Kafka.
Ограничения при масштабировании со старым контроллером: остановка брокера
Представьте себе остановку брокера при старом контроллере. Допустим, у нас есть одна партиция с тремя репликами на брокерах 1, 2 и 3. Все три реплики синхронизированы и находятся в списке ISR. Брокер слева сейчас ведущий, но собирается завершить работу. Он должен отправить запрос контроллеру. Контроллер посмотрит, какие партиции размещены в брокере, и попробует обновить метаданные. Затем нужно будет выбрать новый ведущий брокер и перенести в него партиции, которые размещались на старом. Обновленная информация об ISR записывается в ZooKeeper, и контроллер распространяет новые метаданные по остальным брокерам. В итоге контроллер отправляет два типа запросов: UpdateMetadata, чтобы обновить локальный кэш метаданных для всех брокеров, и LeaderAndISR для всех реплик в соответствующих партициях, чтобы изменить ведущий брокер и список ISR.
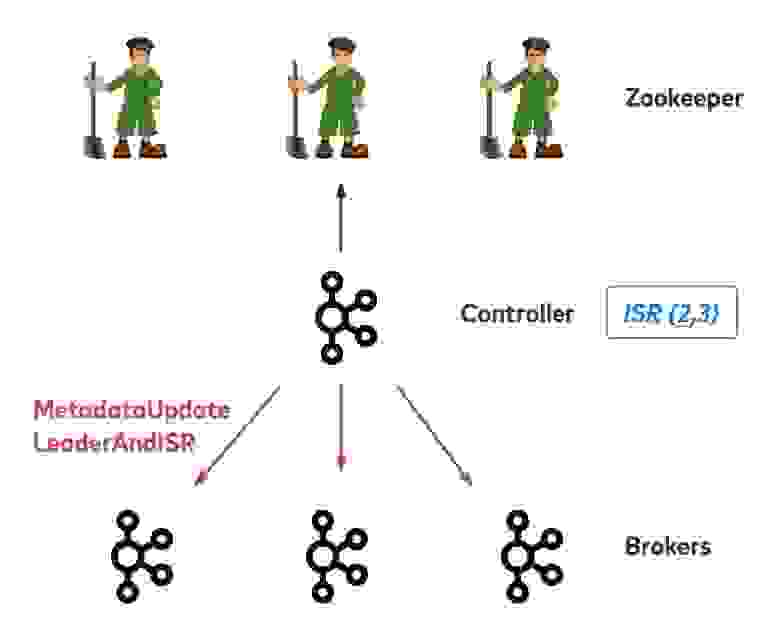
Когда контроллер удалит брокер 1 из всех партиций, которые на нём размещаются, он разрешит брокеру 1 завершить работу. В этом примере на брокере всего одна партиция, но на практике их могут быть тысячи, и контроллеру придётся записать в ZooKeeper много данных, чтобы изменить метаданные для каждой партиции. На это может уйти несколько секунд. Более того, контроллеру придётся передать новые метаданные остальным брокерам по одному за раз. Наконец, если клиенты пытаются узнать о новом ведущем узле у случайного брокера, они действуют наудачу — не факт, что на этом конкретном брокере информация уже обновилась. При таком раскладе у некоторых запросов может истекать время ожидания.
Ограничения при масштабировании со старым контроллером: смена контроллера при сбое
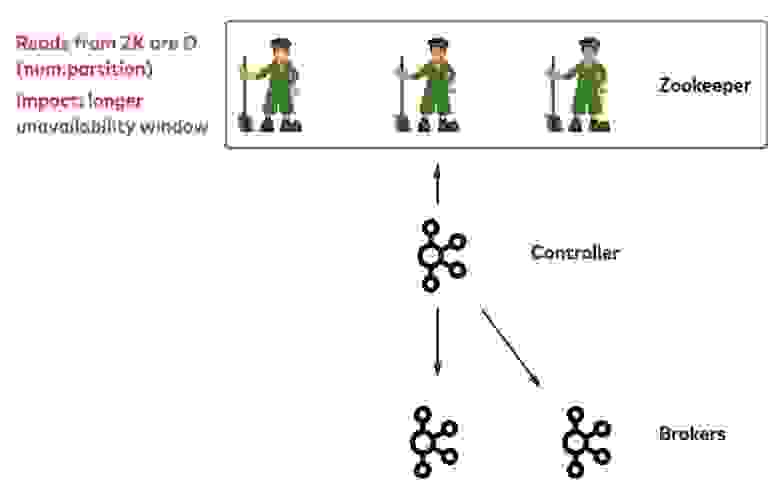
Теперь рассмотрим сценарий неожиданного сбоя контроллера. В этом случае срабатывает зарегистрированный вотчер ZooKeeper, все брокеры получают уведомление и сразу пытаются зарегистрироваться в ZooKeeper. Кто успеет первым, становится новым контроллером. Первым делом новый контроллер получает от ZooKeeper метаданные, в том числе информацию обо всех партициях в топиках по всем путям ZooKeeper. Затем он обновляет все метаданные партиций, которые размещались на прежнем контроллере, записывает новые метаданные в ZooKeeper и распространяет эти метаданные по остальным брокерам.
Самое заметное ограничение в этой процедуре — время, которое требуется контроллеру, чтобы получить метаданные от ZooKeeper. Оно зависит от общего количества партиций в кластере. До завершения инициализации новый контроллер не сможет обрабатывать административные запросы, например, на перебалансировку партиций. Это означает проблемы с доступностью.
Ограничения при масштабировании со старым контроллером: сводка
Когда контроллер распространяет изменения метаданных по брокерам, продолжительность процесса зависит от количества партиций.
Контроллер записывает обновленные метаданные в ZooKeeper, чтобы сохранить их, и чем больше метаданных, тем больше времени на это уйдет.
У ZooKeeper есть и другие недостатки. Например, лимиты на размер znode и количество вотчеров, а также дополнительные проверки для брокеров, потому что набор метаданных на брокерах может различаться при переупорядочивании или задержке обновления.
Защита, апгрейд и отладка требуют больших усилий. Чем проще распределённая система, тем она долговечнее и стабильнее.
Чем KRaft лучше?
Наша цель — создать решение для тысяч брокеров и миллионов партиций, но сначала давайте поймём, что мы на самом деле храним в ZooKeeper.
На первый взгляд кажется, что мы храним текущие снапшоты метаданных из путей ZooKeeper. На самом деле у нас столько вотчеров и версий путей, что мы отслеживаем последовательность событий изменения метаданных, то есть лог метаданных. По сути, в ZooKeeper API все записанные данные тоже хранятся в виде лога транзакций.
Реализация лога метаданных
Зачем усложнять и прятать логи метаданных куда-то в Zookeeper, если можно хранить их в самой Kafka? В конце концов, логи — это специализация Kafka. Почему бы контроллеру не вести лог метаданных как простой топик Kafka? В этом случае операции, связанные с метаданными, можно естественным образом упорядочить по смещениям записей, а затем объединить и передавать вместе асинхронно для улучшения производительности.
Если нужно распространить изменения метаданных, брокеры реплицируют ченджлог, обходясь без RPC. Расхождения между брокерами больше не будут проблемой — локальное материализованное представление метаданных на каждом брокере будет в конечном итоге согласовано, ведь данные поступают из одного лога, а изменения определяются смещением в логе метаданных, с которым они синхронизируются.
Ещё одно преимущество — управлять логом метаданных контроллера можно независимо от остальных логов (управляющий уровень изолирован от пути передачи данных), с отдельными портами, очередями запросов, метриками, потоками и т. д.
Наконец, можно создать небольшую группу брокеров, которые будут синхронно реплицировать лог метаданных, чтобы у нас был кворум, а не один контроллер. При этом если текущий контроллер падает и эту роль берет на себя другой контроллер в кворуме, новый контроллер инициализируется очень быстро, потому что на нём уже есть реплицированный лог метаданных. В итоге лог метаданных, управляемый кворумом контроллеров и реплицируемый по всем брокерам, станет главным логом метаданных для всех логов данных.
Алгоритмы репликации: все узлы или кворум узлов
Как мы будем синхронизировать «лог логов» с репликами? Для логов данных Kafka использует алгоритм репликации с ведущим узлом (primary-backup), при котором все данные записываются на ведущий узел (Leader), а затем реплицируются по фолловерам (Follower-1, 2 и т. д.). Когда все фолловеры подтвердят получение данных, ведущий узел считает запись зафиксированной и отвечает клиенту. Для репликации лога метаданных можно использовать тот же алгоритм, то есть ждать подтверждения от всех реплик.
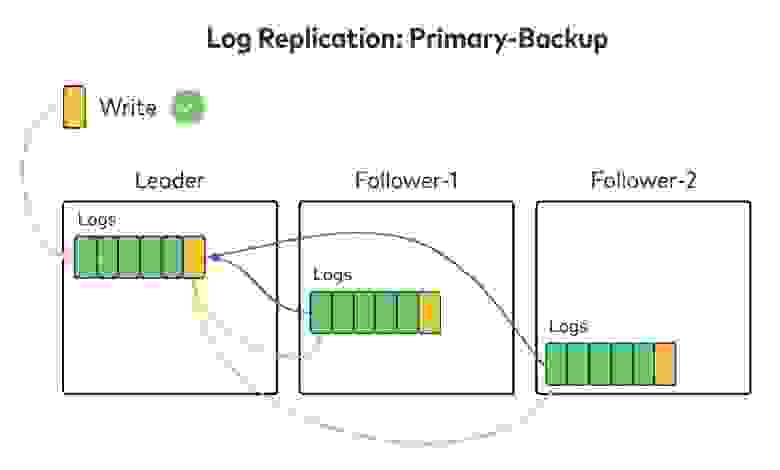
Есть ещё один популярный алгоритм репликации — репликация с кворумом. Ведущий узел по-прежнему один, но подтверждения он ждёт не от всех фоловеров, а только от большинства реплик, включая себя. Достигнув кворума, ведущий узел считает данные записанными и отвечает клиенту. В литературе по распределённым системам описаны разные алгоритмы консенсуса, которые работают по этой схеме. Например, Paxos и Raft.
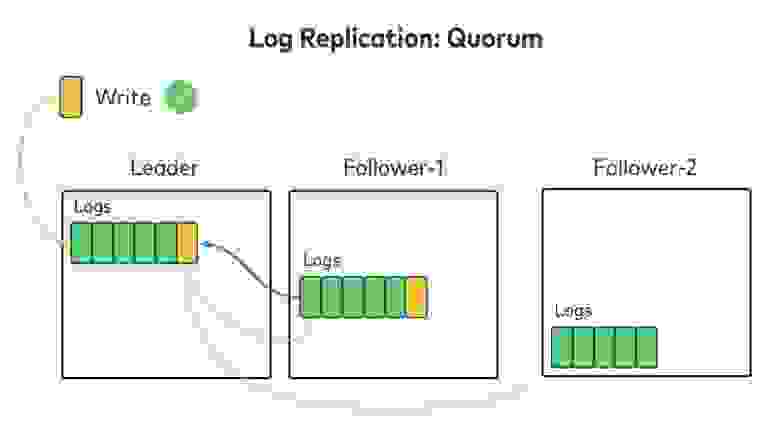
Если мы ждём подтверждения не от всех реплик, а только от кворума, доступность повышается и репликация идёт быстрее. В Kafka используется режим отказа f + 1, то есть для устойчивости при f сбоев нам нужно минимум f + 1 реплик. При репликации с кворумом реплик должно быть 2f + 1.
KRaft — реализация Raft в Kafka
С новым контроллером для лога метаданных будет использоваться алгоритм репликации, который требует подтверждения от кворума, а не от всех узлов. Причины очевидны:
Мы можем позволить себе больше синхронизированных реплик для этого важного лога, чтобы повысить доступность.
При добавлении записей в лог метаданных задержки особенно нежелательны, иначе замедлится работа всего кластера.
Команда Kafka реализовала новый модуль репликации — KRaft. С одной стороны, он использует алгоритм Raft для репликации на основе кворума, а с другой — существующие возможности Kafka, вроде ограничения количества запросов (throttling) или сжатия. В итоге мы можем использовать для нового лога знакомые инструменты и методы устранения неполадок.
Раз ZooKeeper больше не выбирает новый ведущий брокер для лога метаданных, нужен отдельный протокол выбора. Причём этот протокол должен предотвращать ситуации, в которых будет выбрано нескольких ведущих брокеров или ни одного (из-за полной блокировки при определённых условиях).
Выбор ведущего брокера
Протокол KRaft использует имеющийся в Kafka механизм периода ведущего узла (leader epoch), который гарантирует, что в один период будет существовать только один ведущий брокер. У брокера в кластере может быть одна из трех ролей: ведущий (leader), голосующий (voter) или наблюдатель (observer). Ведущий брокер и другие голосующие образуют кворум и отвечают за согласованность реплицированного лога, а также за выбор новых ведущих при необходимости. Остальные брокеры в кластере — наблюдатели. Они пассивно читают реплицированный лог, чтобы синхронизироваться с кворумом. Каждая запись в журнале связана с конкретным периодом ведущего брокера.
При запуске все брокеры в настроенном кворуме инициализируются как голосующие и берут значение периода из локальных логов. На схеме ниже предполагается, что в кворум входит три голосующих брокера. У каждого в локальном логе есть по шесть записей из периода 1 (зеленый) и 2 (желтый).

Они ищут ведущий брокер, не находят, в итоге один из голосующих увеличивает значение периода на 1 и временно становится кандидатом в ведущие. Он отправляет всем брокерам в кворуме запрос, призывая проголосовать за него как за новый ведущий брокер этого периода.
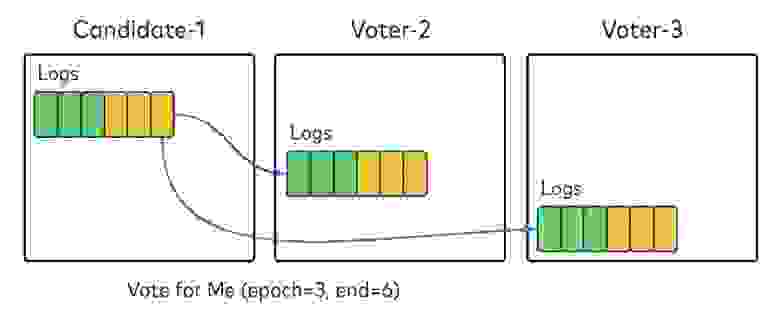
В запросе будет указан период, за который нужно голосовать, и смещение локального лога кандидата. При получении запроса каждый голосующий брокер должен проверить, что:
1. Указанное в запросе значение периода не превышает его собственное значение периода.
2. Он уже проголосовал за этот период.
3. Его локальный лог длиннее, чем указанное смещение.
Если ничто из этого не истинно, он голосует за этого кандидата для этого периода. Голоса сохраняются локально, так что брокеры в кворуме не забудут об отданном голосе даже после начала периода. Когда кандидат получит большинство голосов кворума, включая себя, он считает выборы успешными.
Если кандидат не наберёт достаточно голосов за указанный период, он увеличивает значение ещё на единицу и пробует снова. Чтобы избежать блокировок, например, когда несколько брокеров выставляют свою кандидатуру одновременно и мешают друг другу набрать достаточно голосов, перед повторной попыткой должно пройти рандомное время бэкапа.
С помощью проверки условий и механизма таймаута при голосовании мы гарантируем, что в конкретный период в KRaft будет выбран только один ведущий брокер, и этот брокер будет содержать все зафиксированные записи вплоть до периода, в который его выбрали.
Репликация логов
KRaft использует механизм репликации на основе pull (как Kafka), а не push (как исходный протокол Raft). На схеме ниже ведущий брокер Leader-1 содержит две записи (красный) для периода 3, а голосующий брокер Voter-2 получает (fetch) от него нужные данные.
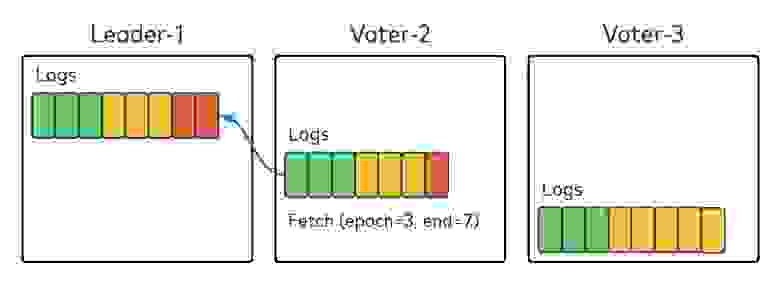
Алгоритм такой же, как при получении реплик в Kafka: Voter-2 указывает в запросе fetch два значения: период, из которого нужны данные, а также лог и смещение. Leader-1 получает запрос и сначала проверяет период. Если всё в порядке, возвращает данные, начиная с указанного смещения. Брокер Voter-2 добавляет полученные данные в локальный лог и запрашивает новые данные с нового смещения. Тут ничего нового, стандартные процедуры получения реплик.
Давайте представим, что один из голосующих брокеров содержит записи, которых нет у остальных. На нашей схеме у брокера Voter-3, который бы ведущим в период 2, в локальном логе есть записи, не реплицированные на большинство брокеров в кворуме, а значит не зафиксированные. Брокер Voter-3 видит, что начался новый период и Leader-1 стал ведущим брокером, и посылает к Leader-1 запрос fetch, указав период 2, лог и смещение. Leader-1 получает запрос, видит, что период и смещение не соответствуют друг другу и возвращает код ошибки, говоря брокеру Voter-3, что в период 2 они дошли только до смещения 6. Voter-3 обрезает локальный лог до смещения 6.
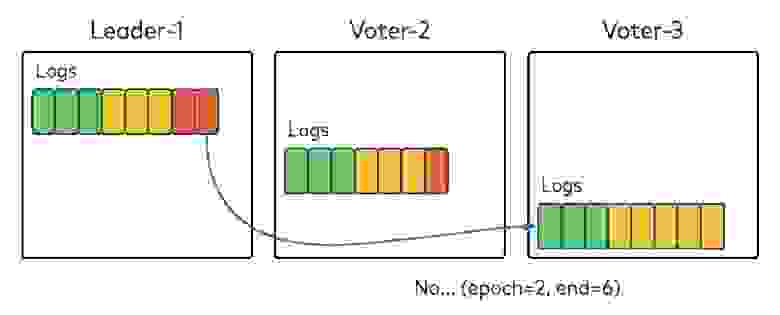
Затем Voter-3 снова отправляет запрос fetch, на этот раз указав период 2 и смещение 6. Leader-1 возвращает брокеру Voter-3 данные из нового периода, и Voter-3 узнает о новом периоде, добавляя возвращенные данные в свой локальный лог.
Если брокеры Voter-2 и Voter-3 не получат ответ от Leader-1 в ожидаемое время, они начнут новый период и попробуют стать ведущим брокером на период 4. Как видите, запрос fetch не только извлекает данные, но и проверяет, жив ли ведущий брокер.
Механизм репликации: pull или push?
Исходный протокол Raft использует метод push, а в KRaft реализован механизм pull, который упрощает согласование данных — получив ответ на запрос fetch, голосующие брокеры могут обрезать лог до актуального смещения, прежде чем отправлять следующий запрос. В модели push придётся отправлять туда и обратно лишние запросы, ведь ведущий брокер должен определить, в какое место лога отправить данные.
Благодаря механизму pull протокол KRaft не так уязвим к деструктивному поведению брокеров, которые не знают, что их удалили из кворума, например, в результате переконфигурации. Если изгнанные брокеры продолжат отправлять ведущему узлу запросы fetch в модели pull, ведущий в ответ отправит код ошибки, чтобы сообщить брокеру, что его исключили из кворума и он может считать себя наблюдателем. При использовании Raft ведущий узел не знает, кто из удалённых голосующих брокеров продолжит считать, что входит в кворум. Удалённый сервер перестанет получать от ведущего узла данные и попытается стать новым лидером.
Ещё одно преимущество механизма pull в том, что Kafka уже применяет эту модель для репликации логов, так что мы можем повторно использовать имеющуюся реализацию.
Правда, ведущему брокеру понадобится отдельный API начала периода, чтобы уведомить кворум, а в Raft это уведомление поступало с данными, которые лилер отправлял фоловерам. Кроме того, чтобы зафиксировать записи на основе большинства серверов в кворуме, ведущему узлу приходится ждать от голосующих следующего запроса fetch для увеличения смещений. Пришлось пойти на компромисс, зато исключенные брокеры не мешают работе. Более того, эта модель уже реализована в Kafka, так что не пришлось изобретать велосипед и писать лишние тысячи строк кода.
Узнайте больше о других деталях реализации KRaft, например, снапшотах метаданных или API конечного автомата поверх лога KRaft: KIP-500, KIP-595 и KIP-630.
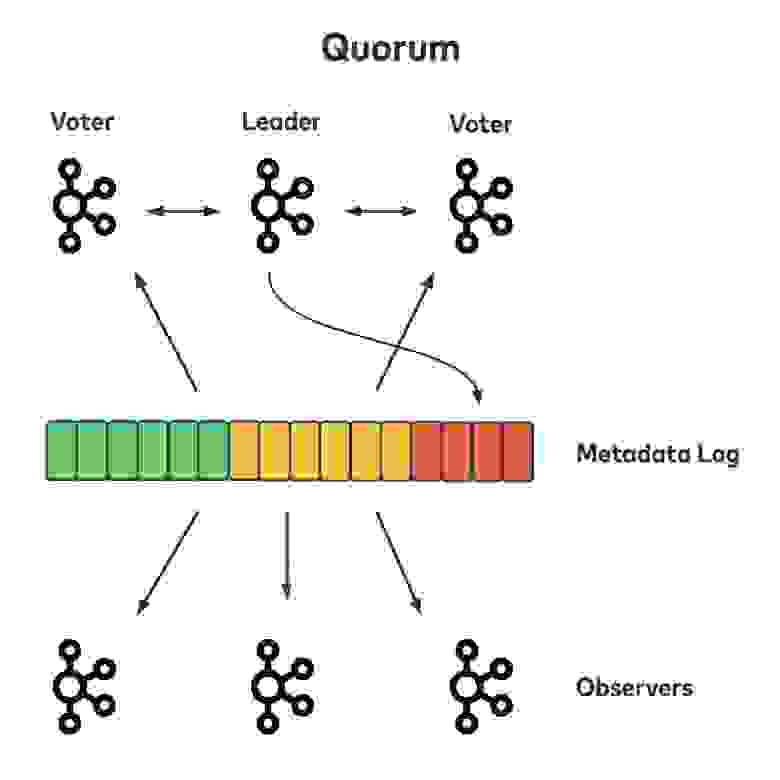
Как работает новый контроллер (контроллер кворума) без Zookeeper? Контроллер кворума создан поверх протокола KRaft. Теперь при запуске брокеров Kafka в кластере небольшая часть от общего количества брокеров образует кворум. Брокеры в кворуме выбирают себе ведущего по алгоритму KRaft, и этот ведущий брокер становится контроллером кворума.
Контроллер отвечает за регистрацию новых брокеров, обнаружение сбоев на брокерах и обработку всех запросов, которые изменят метаданные кластера. Все эти операции можно обрабатывать по очереди и упорядочивать по времени, когда соответствующие события изменений были добавлены в лог метаданных. Другие голосующие брокеры в кворуме активно реплицируют лог метаданных, чтобы новые записи зафиксировались.
Затем можно обновить конечный автомат, созданный поверх кластера и представляющий текущий снапшот метаданных в кластере. Брокеры, которые не входят в кворум, наблюдают за логом метаданных и просто получают от кворума зафиксированные записи, чтобы обновлять собственные кэши метаданных. При таком подходе все локальные снапшоты метаданных естественным образом синхронизируются с полученным смещением в логе, так что метаданные согласованы, а любые отклонения можно легко исправить.
Если в кластер Kafka входит всего один брокер, он же и будет контроллером. По мере добавления брокеров они сами будут находить контроллер и регистрироваться в нем, а контроллер будет записывать информацию о брокерах в лог метаданных. Контроллер может запретить доступ к брокерам, пока они не перенесут назначенные им партиции и не будут готовы обслуживать клиентские запросы. При таком подходе будет ниже риск того, что время ожидания запроса истечет, если, например, новые брокеры отстают.
Новый контроллер кворума: остановка брокера и смена контроллера при сбое
Помните, мы рассматривали сценарии остановки брокера и смены контроллера в старой модели? Теперь рассмотрим их в новой.
Контроллер кворума получает данные о работоспособности всех зарегистрированных брокеров с помощью heartbeat-сообщений. Когда существующий брокер останавливается, он может сообщить о своем намерении в heartbeat-запросе, чтобы контроллер удалил его из всех партиций, как обычно, а ещё объединил все события по перемещению партиций и добавил их в лог метаданных вместе. При таком подходе задержки при завершении работы брокеров будут значительно меньше.

При сбое контроллера один из голосующих может стать новым ведущим брокером и сразу фиксировать данные в новом периоде, потому что все зафиксированные записи вплоть до нового периода уже будут реплицированы, так что не придётся тратить время на инициализацию нового ведущего из лога метаданных.
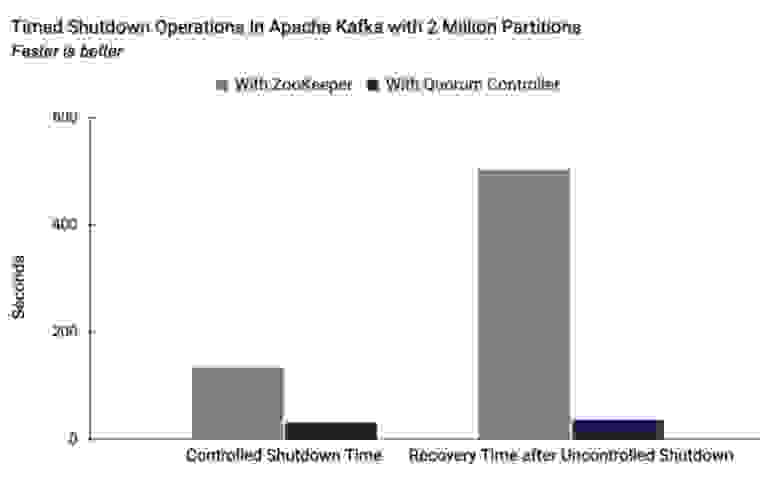
Эксперимент: ZooKeeper vs. контроллер кворума
Преимущества контроллера кворума по сравнению с контроллером в ZooKeeper наглядно видны в эксперименте, который был проведен в кластере Kafka с 2 млн партиций. На схеме показана задержка для контролируемой остановки и неконтролируемого сбоя. Очевидно, что при использовании контроллера кворума задержка гораздо меньше.
Если хотите узнать больше, читайте статью Apache Kafka Made Simple: A First Glimpse of a Kafka Without ZooKeeper.
Два ключевых момента этой статьи:
Метаданные лучше хранить в виде лога событий, как мы делаем это с остальными данными в Kafka.
Контроллер кворума поверх лога метаданных позволяет устранить узкие места при масштабировании и расширить кластер Kafka до тысяч брокеров и миллионов партиций.
Обучение Apache Kafka от Слёрма
— Курс «Apache Kafka База»: познакомимся с технологией, научимся настраивать распределённый отказоустойчивый кластер, отслеживать метрики, равномерно распределять нагрузку.
— Видеокурс «Apache Kafka для разработчиков». Это углублённый интенсив с практикой на Java или Golang и платформой Spring+Docker+Postgres. Интенсив даёт понимание, как организовать работу микросервисов и повысить общую надежность системы.
Купить комплектом 2 курса выгоднее на 30%: https://slurm.club/3KzRtzM
