[Перевод] Пишем операционную систему на Rust. Страничная организация памяти
В этой статье представляем страницы, очень распространённую схему управления памятью, которую мы тоже применим в нашей ОС. Статья объясняет, почему необходима изоляция памяти, как работает сегментация, что такое виртуальная память и как страницы решают проблему фрагментации. Также исследуем схему многоуровневых таблиц страниц в архитектуре x86_64.
Этот блог выложен на GitHub. Если у вас какие-то вопросы или проблемы, открывайте там соответствующий запрос.
Одна из основных задач операционной системы — изоляция программ друг от друга. Например, браузер не должен вмешиваться в работу текстового редактора. Существуют различные подходы в зависимости от аппаратного обеспечения и реализации ОС.
Например, в некоторых процессорах ARM Cortex-M (во встраиваемых системах) есть блок защиты памяти (MPU), который определяет небольшое количество (например, 8) областей памяти с различными разрешениями доступа (например, нет доступа, только для чтения, для чтения и записи). При каждом доступе к памяти MPU гарантирует, что адрес находится в области с правильными разрешениями, в противном случае выдаёт исключение. Изменяя области и разрешения доступа, ОС гарантирует, что у каждого процесса есть доступ только к своей памяти, чтобы изолировать процессы друг от друга.
На x86 поддерживается два различных подхода к защите памяти: сегментация и страничная организация.
Сегментацию реализовали ещё в 1978 году, первоначально для увеличения объёма адресуемой памяти. В то время CPU поддерживали только 16-разрядные адреса, что ограничивало объём адресуемой памяти 64 КБ. Чтобы увеличить этот объём, ввели дополнительные сегментные регистры, каждый из которых содержит адрес смещения. CPU автоматически добавляет это смещение при каждом доступе к памяти, адресуя таким образом до 1 МБ памяти.
CPU автоматически выбирает сегментный регистр в зависимости от типа доступа к памяти: для получения инструкций используется регистр кодового сегмента CS, а для операций стека (push/pop) — регистр стекового сегмента SS. Другие инструкции используют регистр сегмента данных DS или регистр дополнительного сегмента ES. Позже для свободного использования были добавлены два дополнительных сегментных регистра FS и GS.
В первой версии сегментации регистры непосредственно содержали смещение и управление доступом не выполнялось. С появлением защищенного режима механизм изменился. Когда CPU работает в таком режиме, дескрипторы сегментов хранят индекс в локальной или глобальной таблице дескрипторов, которая в дополнение к адресу смещения содержит размер сегмента и разрешения доступа. Загружая отдельные глобальные/локальные таблицы дескрипторов для каждого процесса, ОС может изолировать процессы друг от друга.
Изменяя адреса памяти перед фактическим доступом, сегментация реализовала метод, который теперь используется почти везде: это виртуальная память.
Виртуальная память
Идея виртуальной памяти заключается в абстрагировании адресов памяти от физического устройства. Вместо прямого доступа к устройству хранения данных сначала выполняется шаг преобразования. В случае сегментации на этапе трансляции добавляется адрес смещения активного сегмента. Представьте программу, которая обращается к адресу памяти 0x1234000 в сегменте со смещением 0x1111000: в действительности обращение идёт к адресу 0x2345000.
Чтобы различать два типа адресов, адреса до преобразования называются виртуальными, а адреса после преобразования — физическими. Между ними одно важное различие: физические адреса уникальны и всегда ссылаются на одно и то же уникальное расположение в памяти. С другой стороны, виртуальные адреса зависят от функции преобразования. Два разных виртуальных адреса вполне могут ссылаться на один физический адрес. Кроме того, идентичные виртуальные адреса могут ссылаться на разные физические адреса после преобразования.
В качестве примера полезного использования этого свойства можно привести параллельный запуск одной и той же программы дважды:
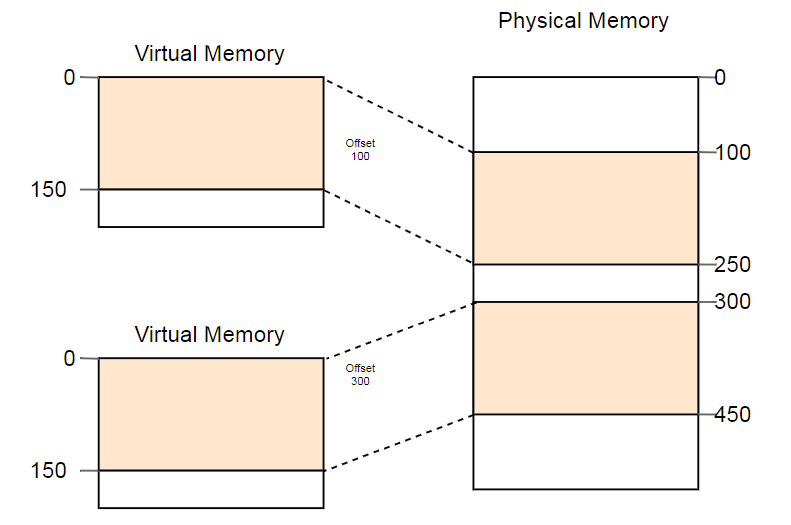
Здесь одна и та же программа запускается дважды, но с разными функциями преобразования. У первого экземпляра смещение сегмента 100, так что его виртуальные адреса 0–150 преобразуются в физические адреса 100–250. У второго экземпляра смещение 300, которое преобразует виртуальные адреса 0–150 в физические адреса 300–450. Это позволяет обеим программам выполнять один и тот же код и использовать одни и те же виртуальные адреса, не мешая друг другу.
Ещё одно преимущество в том, что теперь программы можно размещать в произвольных местах физической памяти. Таким образом, ОС использует весь объём доступной памяти без необходимости перекомпиляции программ.
Фрагментация
Различие виртуальных и физических адресов — реальное достижение сегментации. Но есть и проблема. Представьте, что мы хотим запустить третью копию программы, которую видели выше:
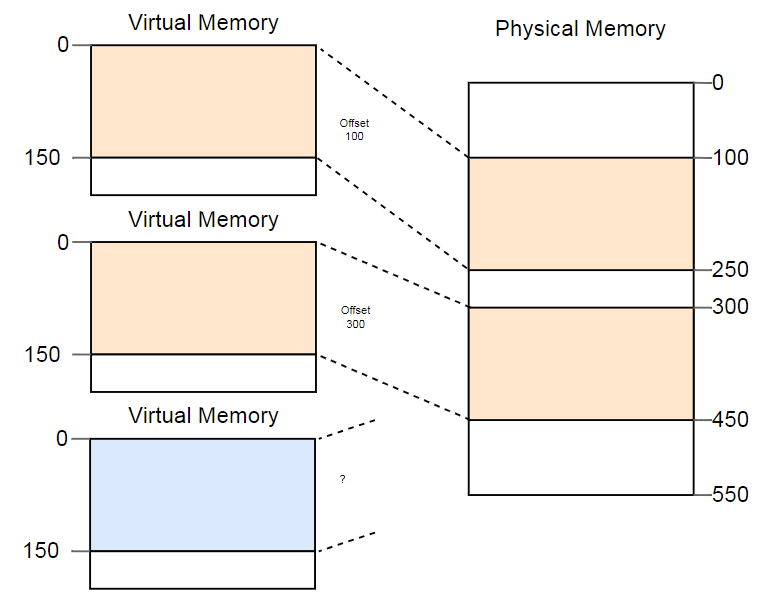
Хотя в физической памяти более чем достаточно места, третий экземпляр никуда не помещается. Проблема в том, что ему нужен непрерывный фрагмент памяти и мы не можем использовать отдельные свободные участки.
Один из способов борьбы с фрагментацией — приостановить выполнение программ, переместить используемые части памяти ближе друг к другу, обновить преобразование, а затем возобновить выполнение:
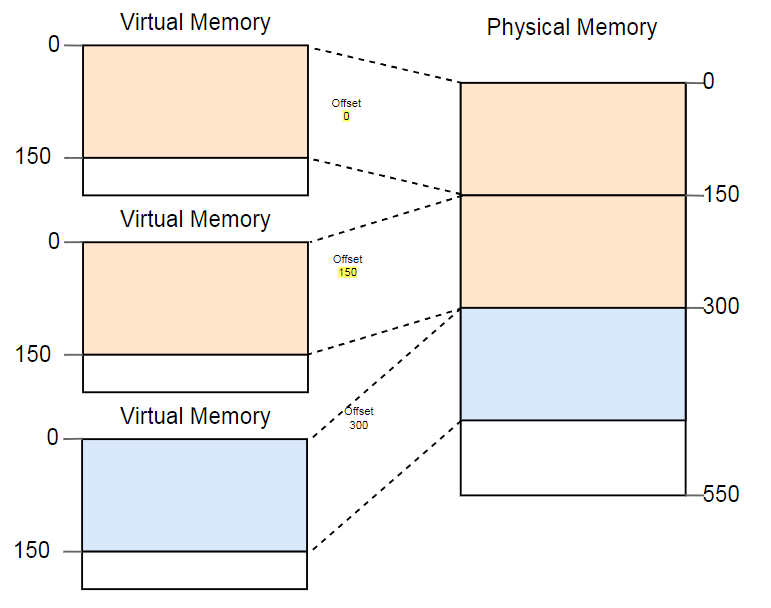
Теперь для запуска третьего экземпляра достаточно места.
Недостаток такой дефрагментации — необходимость копирования больших объёмов памяти, что снижает производительность. Данную процедуру приходится выполнять регулярно, пока память не стала слишком фрагментированной. Производительность становится непредсказуемой, программы останавливаются в произвольное время и могут перестать отвечать на запросы.
Фрагментация — одна из причин, почему в большинстве систем не используется сегментация. На самом деле она больше не поддерживается даже в 64-разрядном режиме на x86. Вместо сегментации используются страницы, которые полностью исключают проблему фрагментации.
Идея состоит в том, чтобы разделить пространство виртуальной и физической памяти на небольшие блоки фиксированного размера. Блоки виртуальной памяти называются страницами, а блоки физического адресного пространства — фреймами. Каждая страница индивидуально сопоставляется с фреймом, что позволяет разделить большие области памяти между несмежными физическими фреймами.
Преимущество становится очевидным, если повторить пример с фрагментированным пространством памяти, но на этот раз с использованием страниц вместо сегментации:
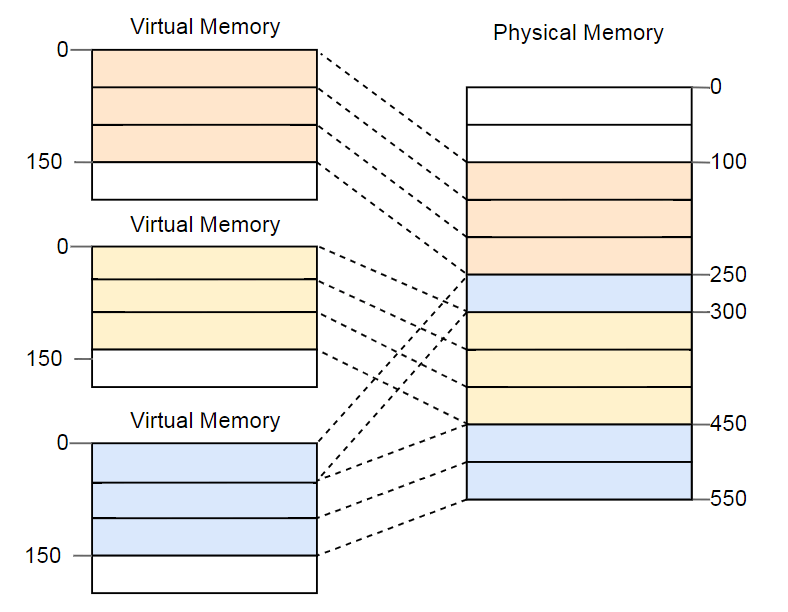
В этом примере размер страницы 50 байт, то есть каждая из областей памяти разделена на три страницы. Каждая страница сопоставляется с отдельным фреймом, поэтому непрерывную область виртуальной памяти можно сопоставить с изолированными физическими фреймами. Это позволяет запустить третий экземпляр программы без дефрагментации.
Скрытая фрагментация
По сравнению с сегментацией, в страничной организации используется множество небольших областей памяти фиксированного размера вместо нескольких больших областей переменного размера. У каждого фрейма одинаковый размер, так что фрагментация из-за слишком маленьких фреймов невозможна.
Но это только видимость. На самом деле существует скрытый вид фрагментации, так называемая внутренняя фрагментация из-за того, что не каждая область памяти в точности кратна размеру страницы. Представьте в вышеприведённом примере программу размером 101: ей всё равно понадобятся три страницы размером 50, поэтому она займёт на 49 байт больше, чем нужно. Для ясности фрагментацию из-за сегментации называют внешней фрагментацией.
Во внутренней фрагментации ничего хорошего, но часто это меньшее зло, чем внешняя фрагментация. По-прежнему расходуется лишняя память, но теперь не нужно проводить дефрагментацию, а объём фрагментации предсказуем (в среднем полстраницы на каждую область памяти).
Таблицы страниц
Мы увидели, что каждая из миллионов возможных страниц индивидуально сопоставляется с фреймом. Эту информацию о трансляции адресов нужно где-то хранить. При сегментации используются отдельные регистры сегментов для каждой активной области памяти, что невозможно в случае со страницами, потому что их намного больше, чем регистров. Вместо этого здесь используется структура под названием таблицы страниц.
Для вышеприведённого примера таблицы будут выглядеть следующим образом:
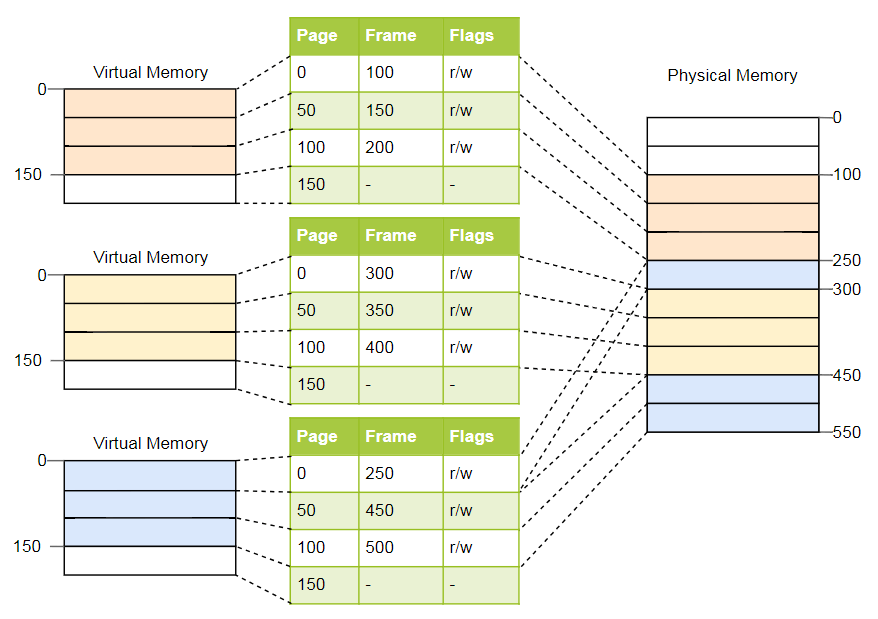
Как видим, у каждого экземпляра программы своя таблица страниц. Указатель на текущую активную таблицу хранится в специальном регистре CPU. На x86 он называется CR3. Перед запуском каждого экземпляра программы операционная система должна загрузить туда указатель на правильную таблицу страниц.
При каждом доступе к памяти CPU считывает указатель таблицы из регистра и ищет соответствующий фрейм в таблице. Это полностью аппаратная функция, которая выполняется полностью прозрачно для запущенной программы. Для ускорения процесса во многих процессорных архитектурах есть специальный кэш, который запоминает результаты последних преобразований.
В зависимости от архитектуры, в поле флагов таблицы страниц могут храниться и атрибуты, такие как права доступа. В приведенном выше примере флаг r/w делает страницу доступной для чтения и записи.
Многоуровневые таблицы страниц
У простых таблиц страниц проблема с большими адресными пространствами: память тратится впустую. Например, программа использует четыре виртуальные страницы 0, 1_000_000, 1_000_050 и 1_000_100 (используем _ в качестве разделителя разрядов):
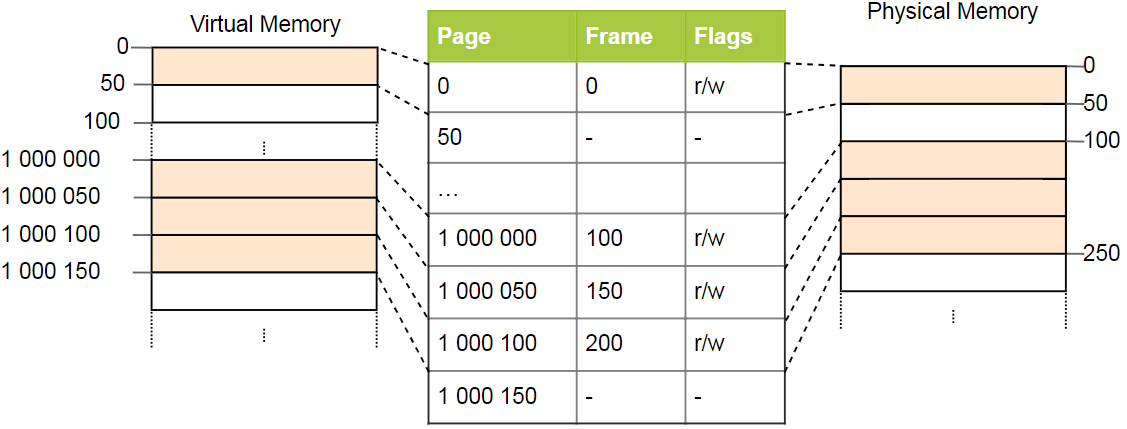
Требуется всего четыре физических фрейма, но в таблице страниц более миллиона записей. Мы не можем пропустить пустые записи, потому что тогда CPU в процессе преобразования не сможет перейти напрямую к правильной записи (например, больше не гарантируется, что четвёртая страница использует четвёртую запись).
Для уменьшения потерь памяти можно использовать двухуровневую организацию. Идея в том, что мы используем разные таблицы для разных областей. Дополнительная таблица, которая называется таблицей страниц второго уровня, выполняет преобразование между областями адресов и таблицами страниц первого уровня.
Это лучше всего объяснить на примере. Определим, что каждая таблица страниц уровня 1 отвечает за область размером 10_000. Тогда в вышеприведённом примере будут существовать следующие таблицы:
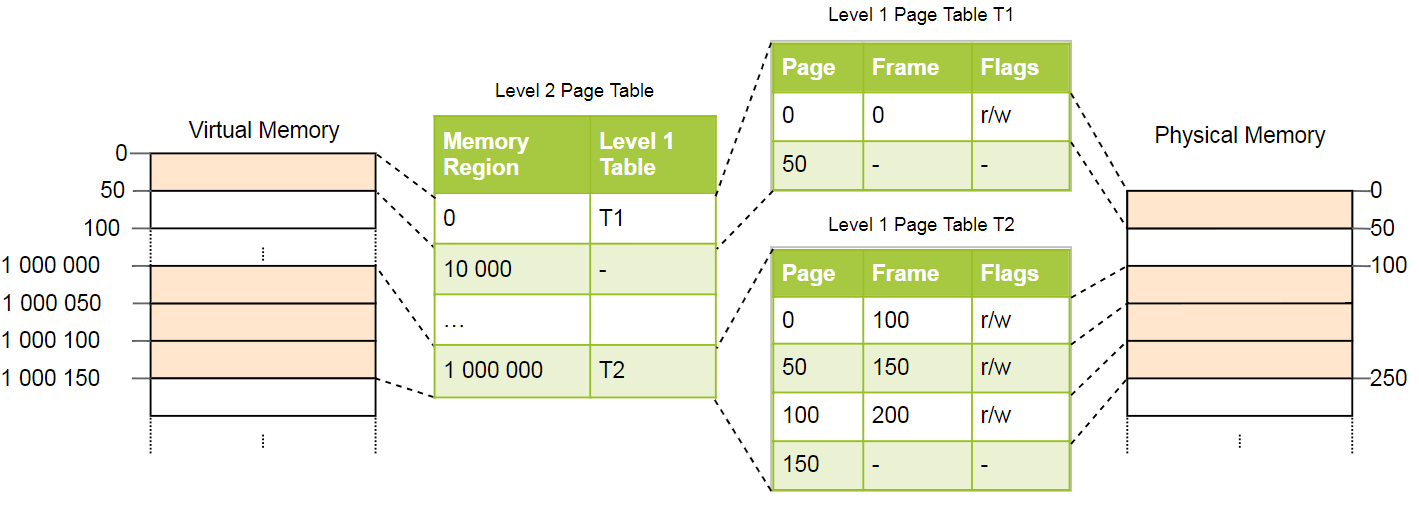
Страница 0 попадает в первую область 10_000 байт, поэтому использует первую запись таблицы страниц второго уровня. Эта запись указывает на таблицу страниц T1 первого уровня, которая определяет, что страница 0 ссылается на фрейм 0.
Страницы 1_000_000, 1_000_050 и 1_000_100 попадают в 100-ю байтовую область 10_000, поэтому используют 100-ю запись таблицы страниц уровня 2. Эта запись указывает на другой таблицу T2 первого уровня, которая переводит три страницы во фреймы 100, 150 и 200. Обратите внимание, что адрес страницы в таблицах первого уровня не содержит смещения региона, поэтому, например, запись для страницы 1_000_050 составляет всего 50.
У нас по-прежнему 100 пустых записей в таблице второго уровня, но это гораздо меньше, чем прежний миллион. Причина экономии в том, что не нужно создавать таблицы страниц первого уровня для несопоставленных областей памяти между 10_000 и 1_000_000.
Принцип двухуровневых таблиц можно расширить на три, четыре и больше уровней. В целом такая система называется многоуровневой или иерархической таблицей страниц.
Зная о страничной организации и многоуровневых таблицах, можно посмотреть, как реализована страничная организация в архитектуре x86_64 (предполагаем, что процессор работает в 64-разрядном режиме).
Архитектура x86_64 использует четырёхуровневую таблицу с размером страницы 4 КБ. Независимо от уровня, в каждой странице 512 элементов. Каждая запись имеет размер 8 байт, поэтому размеры таблиц 512 × 8 байт = 4 КБ.

Как видим, каждый табличный индекс содержит 9 бит, что имеет смысл, потому что в таблицах 2^9 = 512 записей. Нижние 12 бит — это смещение в 4-килобайтную страницу (2^12 байт = 4 КБ). Биты от 48 до 64 отбрасываются, так что x86_64 на самом деле не 64-разрядная система, а поддерживает только 48-разрядные адреса. Есть планы расширить размер адреса до 57 бит через 5-уровневую таблицу страниц, но ещё не создан такой процессор.
Хотя биты от 48 до 64 отбрасываются, им нельзя задать произвольные значения. Все биты в этом диапазоне должны быть копиями бита 47, чтобы сохранить уникальные адреса и разрешить будущее расширение, например, до 5-уровневой таблицы страниц. Это называется расширением знака (sign-extension), потому что очень похоже на расширение знака в дополнительном коде. Если неправильно расширить адрес, CPU выдаёт исключение.
Пример преобразования
Рассмотрим на примере, как работает преобразование адреса:
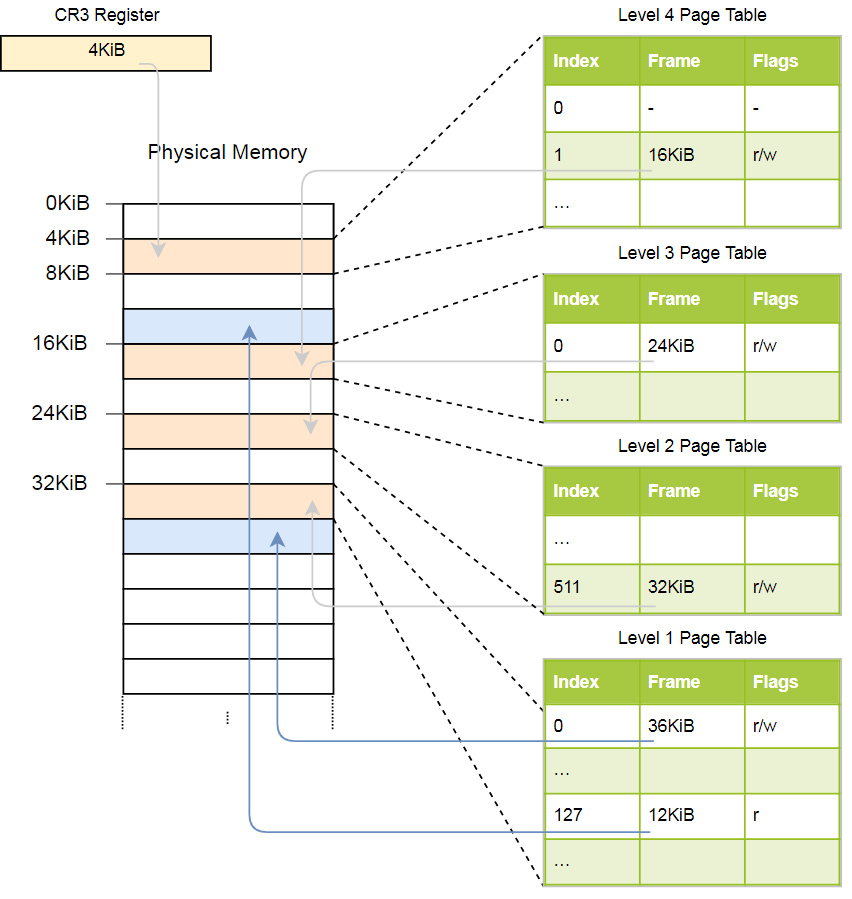
Физический адрес текущей активной таблицы страниц уровня 4, которая является корневой таблицей страниц этого уровня, сохраняется в регистре CR3. Затем каждая запись таблицы страниц указывает на физический фрейм таблицы следующего уровня. Запись таблицы уровня 1 указывает на отображённый фрейм. Обратите внимание, что все адреса в таблицах страниц физические, а не виртуальные, так как в противном случае CPU потребуется преобразовать эти адреса (что может привести к бесконечной рекурсии).
Вышеприведённая иерархия преобразует две страницы (синим цветом). Из индексов можно сделать вывод, что виртуальные адреса этих страниц 0x803fe7f000 и 0x803FE00000. Посмотрим, что происходит, когда программа пытается прочитать память по адресу 0x803FE7F5CE. Сначала преобразуем адрес в двоичный и определим индексы таблицы страниц и смещение для адреса:

С помощью этих индексов мы теперь можем пойти по иерархии таблиц страниц и найти соответствующий фрейм:
- Считываем адрес таблицы четвёртого уровня из регистра
CR3. - Индекс четвёртого уровня равен 1, поэтому смотрим на запись с индексом 1 в этой таблице. Она говорит, что таблица уровня 3 хранится по адресу 16 КБ.
- Загружаем с этого адреса таблицу третьего уровня и смотрим на запись с индексом 0, который указывает на таблицу второго уровня по адресу 24 КБ.
- Индекс второго уровня равен 511, поэтому ищем последнюю запись на этой странице, чтобы узнать адрес таблицы первого уровня.
- По записи с индексом 127 в таблице первого уровня мы, наконец, узнаём, что страница соответствует фрейму 12 КБ или 0xc000 в шестнадцатеричном формате.
- Последним шагом является добавление смещения к адресу фрейма, чтобы получить физический адрес: 0xc000 + 0×5ce = 0xc5ce.
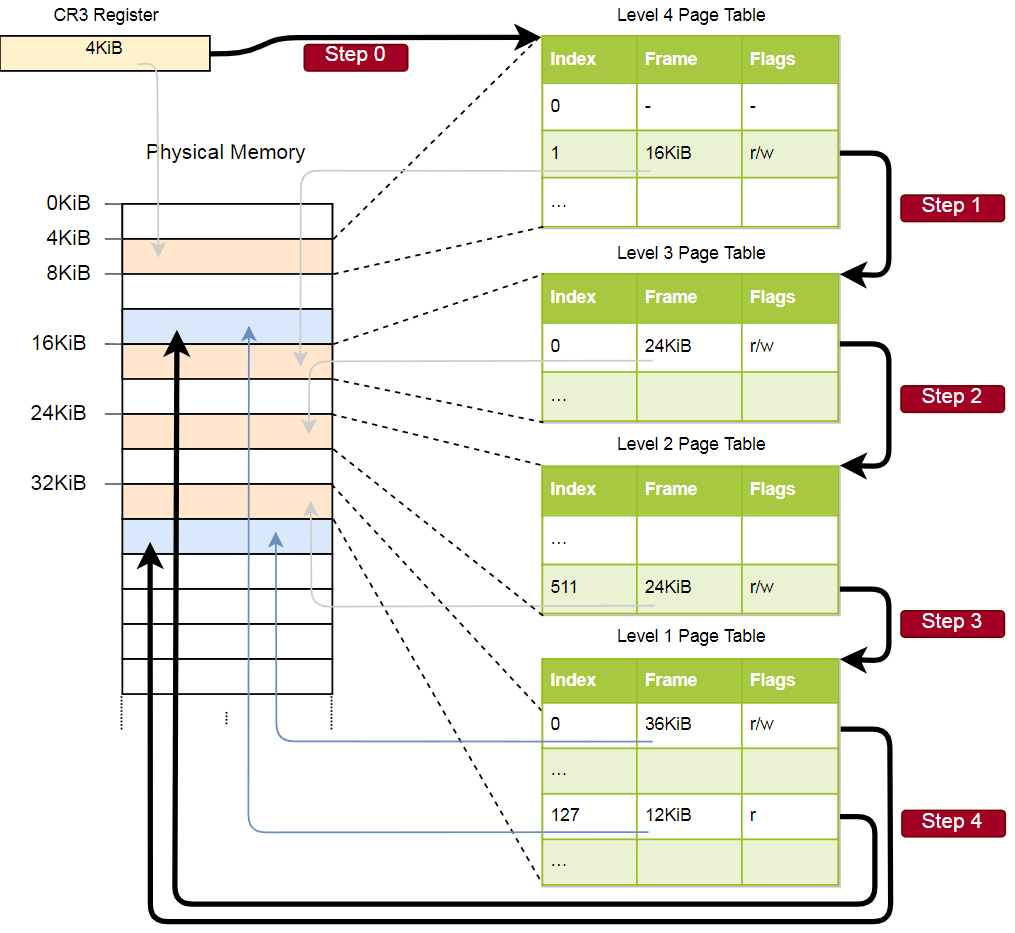
Для страницы в таблице первого уровня указан флаг r, то есть разрешено только чтение. На аппаратном уровне будет выдано исключение, если мы попытаемся произвести туда запись. Разрешения таблиц более высокого уровня распространяются на нижние уровни, так что если мы установим на третьем уровне флаг «только для чтения», ни одна последующая страница нижнего уровня не будет доступна для записи, даже если там указаны флаги, разрешающие запись.
Хотя в этом примере используется только один экземпляр каждой таблицы, обычно в каждом адресном пространстве присутствует несколько экземпляров каждого уровня. Максимум:
- одна таблица четвёртого уровня,
- 512 таблиц третьего уровня (поскольку в таблице четвёртого уровня 512 записей),
- 512×512 таблиц второго уровня (поскольку в каждая из таблиц третьего уровня 512 записей), и
- 512×512 * 512 таблиц первого уровня (512 записей для каждой таблицы второго уровня).
Формат таблицы страниц
В архитектуре x86_64 таблицы страниц по сути представляют собой массивы из 512 записей. В синтаксисе Rust:
#[repr(align(4096))]
pub struct PageTable {
entries: [PageTableEntry; 512],
}
Как указано в атрибуте repr, таблицы должны быть выровнены по странице, т. е. по границе 4 КБ. Это требование гарантирует, что таблица всегда оптимально заполняет всю страницу, делая записи очень компактными.
Размер каждой записи 8 байт (64 бита) и следующий формат:
| Бит (ы) | Название | Значение |
|---|---|---|
| 0 | present | страница в памяти |
| 1 | writable | разрешена запись |
| 2 | user accessible | если бит не установлен, то доступ к странице только у ядра |
| 3 | write through caching | запись напрямую в память |
| 4 | disable cache | отключить кэш для этой страницы |
| 5 | accessed | CPU устанавливает этот бит, когда страница используется |
| 6 | dirty | CPU устанавливает этот бит, когда происходит запись на страницу |
| 7 | huge page/null | нулевой бит в P1 и P4 создаёт страницы 1 КБ в P3, страницу 2 МБ в P2 |
| 8 | global | страница не заполняется из кэша при переключении адресного пространства (должен быть установлен бит PGE регистра CR4) |
| 9–11 | available | ОС может их свободно использовать |
| 12–51 | physical address | выровненный по странице 52-битный физический адрес фрейма или следующей таблицы страниц |
| 52–62 | available | ОС может их свободно использовать |
| 63 | no execute | запрещает выполнение кода на этой страницу (должен быть установлен бит NXE в регистре EFER) |
Мы видим, что для хранения физического адреса фрейма используются только биты 12–51, а остальные работают как флаги или могут свободно использоваться операционной системой. Такое возможно, потому что мы всегда указываем или на выровненный по 4096 байтам адрес, или на выровненную страницу таблиц, или на начало соответствующего фрейма. Это означает, что биты 0–11 всегда равны нулю, так что их можно не хранить, они просто обнуляются на аппаратном уровне перед использованием адреса. То же самое относится и к битам 52–63, поскольку архитектура x86_64 поддерживает только 52-разрядные физические адреса (и только 48-разрядные виртуальные адреса).
Подробнее рассмотрим доступные флаги:
- Флаг
presentотличает отображённые страницы от неотображённых. Его можно использовать для временного сохранения страниц на диск, когда заполнена основная память. При последующем обращении к странице возникает специальное исключение PageFault, на которое реагирует ОС, подкачивая страницу с диска — работа программы продолжается. - Флаги
writableиno executeопределяют, является ли содержимое страницы доступным для записи или содержит исполняемые инструкции, соответственно. - Флаги
accessedиdirtyавтоматически устанавливает процессор при чтении или записи на страницу. ОС может использовать эту информацию, например, если меняет страницы местами или при проверке, изменилось ли содержимое страницы с момента последней откачки на диск. - Флаги
write through cachingиdisable cacheпозволяют управлять кэшем для каждой страницы в отдельности. - Флаг
user accessibleделает страницу доступной для кода из пользовательского простанства, в противном случае она доступна только для ядра. Эту функцию можно использовать для ускорения системных вызовов, сохраняя сопоставление адресов для ядра во время работы пользовательской программы. Тем не менее, уязвимость Spectre позволяет читать эти страницы программам из пользовательского пространства. - Флаг
globalсигнализирует оборудованию, что страница доступна во всех адресных пространствах и её нельзя удалять из кэша преобразования адресов (см. раздел о TLB ниже) на переключателях адресного пространства (address space switch). Обычно одновременно очищается флаг useraccessibleдля трансляции кода ядра во все адресные пространства. - Флаг
huge pageпозволяет создание страниц больших размеров, чтобы записи таблиц страниц уровня 2 или 3 непосредственно указывали на отображённый фрейм. Это увеличивает размер страницы в 512 раз: на втором уровне до 2 МБ = 512 × 4 КБ, а на третьем уровне до 1 ГБ = 512 × 2 МБ. Для больших страниц требуется меньше строк кэша преобразования адресов и меньше таблиц страниц.
Архитектура x86_64 определяет формат таблиц страниц и их записей, поэтому нам не придётся создавать эти структуры самостоятельно.
Буфер ассоциативной трансляции (TLB)
Из-за четырёх уровней для каждого преобразование адреса требуется четыре доступа к памяти. Ради повышения производительности x86_64 кэширует последние несколько переводов в так называемом буфере ассоциативной трансляции (TLB). Это позволяет пропустить преобразование, если оно ещё в кэше.
В отличие от других кэшей процессора, TLB не полностью прозрачен, не обновляет и не удаляет преобразования при изменении содержимого таблиц страниц. Это означает, что ядро должно самостоятельно обновлять TLB всякий раз, когда изменяет таблицу страниц. Для этого существует специальная инструкция CPU под названием invlpg (invalidate page), которая удаляет трансляцию указанной страницы из TLB, так что при следующем доступе она снова загружается из таблицы страниц. TLB полностью очищается перезагрузкой регистра CR3, который имитирует переключатель адресного пространства. Через модуль tlb в Rust доступны оба варианта.
Важно не забывать чистить TLB после каждого изменения таблицы страниц, иначе CPU продолжит использовать старую трансляцию, что приведёт к непредсказуемым ошибкам, которые очень трудно отладить.
Мы не упомянули одну вещь: наше ядро уже поддерживает страничную организацию. Загрузчик из статьи «Минимальное ядро на Rust» уже установил четырёхуровневую иерархию, которая сопоставляет каждую страницу нашего ядра с физическим фреймом, потому что страничная организация обязательна в 64-разрядном режиме на x86_64.
Это означает, что в нашем ядре все адреса памяти виртуальные. Доступ к буферу VGA по адресу 0xb8000 работал только потому, что идентификатор загрузчика транслировал эту страницу в память, то есть сопоставил виртуальную страницу 0xb8000 с физическим фреймом 0xb8000.
Благодаря страничной организации ядро уже относительно безопасно: каждый доступ за пределы допустимой памяти вызывает ошибку страницы, а не допускает запись в физическую память. Загрузчик даже установил правильные разрешения доступа для каждой страницы: исполняемыми будут только страницы с кодом, а доступны для записи только страницы с данными
Ошибки страницы (PageFault)
Попробуем вызвать PageFault, обратившись к памяти за пределами ядра. Во-первых, создаём обработчик ошибок и регистрируем его в нашем IDT, чтобы видеть специфическое исключение вместо двойной ошибки общего типа:
// in src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
[…]
idt.page_fault.set_handler_fn(page_fault_handler); // new
idt
};
}
use x86_64::structures::idt::PageFaultErrorCode;
extern "x86-interrupt" fn page_fault_handler(
stack_frame: &mut ExceptionStackFrame,
_error_code: PageFaultErrorCode,
) {
use crate::hlt_loop;
use x86_64::registers::control::Cr2;
println!("EXCEPTION: PAGE FAULT");
println!("Accessed Address: {:?}", Cr2::read());
println!("{:#?}", stack_frame);
hlt_loop();
}
При сбое страницы CPU автоматически устанавливает регистр CR2. Он содержит виртуальный адрес страницы, которая вызвала сбой. Для чтения и вывода этого адреса используем функцию Cr2::read. Обычно тип PageFaultErrorCode выдаёт больше информации о вызвавшем ошибку типе доступа к памяти, но из-за бага LLVM передаётся недопустимый код ошибки, поэтому мы пока игнорируем эту инфомрацию. Выполнение программы нельзя продолжить, пока мы не устраним ошибку страницы, поэтому вставляем в конце hlt_loop.
Теперь получаем доступ к памяти вне ядра:
// in src/main.rs
#[cfg(not(test))]
#[no_mangle]
pub extern "C" fn _start() -> ! {
use blog_os::interrupts::PICS;
println!("Hello World{}", "!");
// set up the IDT first, otherwise we would enter a boot loop instead of
// invoking our page fault handler
blog_os::gdt::init();
blog_os::interrupts::init_idt();
unsafe { PICS.lock().initialize() };
x86_64::instructions::interrupts::enable();
// new
let ptr = 0xdeadbeaf as *mut u32;
unsafe { *ptr = 42; }
println!("It did not crash!");
blog_os::hlt_loop();
}
После запуска мы видим, что происходит вызов обработчика ошибок страницы:
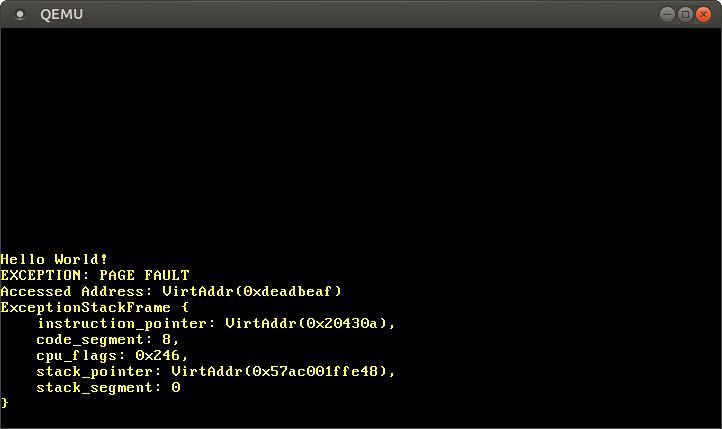
Регистр CR2 действительно содержит адрес 0xdeadbeaf, к которому мы хотели получить доступ.
Текущий указатель инструкции — 0x20430a, поэтому мы знаем, что данный адрес указывает на кодовую страницу. Кодовые страницы отображаются загрузчиком только для чтения, поэтому чтение с этого адреса работает, а запись вызовет ошибку. Попробуйте изменить указатель 0xdeadbeaf на 0x20430a:
// Note: The actual address might be different for you. Use the address that
// your page fault handler reports.
let ptr = 0x20430a as *mut u32;
// read from a code page -> works
unsafe { let x = *ptr; }
// write to a code page -> page fault
unsafe { *ptr = 42; }
Если закомментить последнюю строку, то мы можем убедиться, что чтение работает, а запись вызывает ошибку PageFault.
Доступ к таблицам страниц
Теперь взглянем на таблицы страниц для ядра:
// in src/main.rs
#[cfg(not(test))]
#[no_mangle]
pub extern "C" fn _start() -> ! {
use x86_64::registers::control::Cr3;
let (level_4_page_table, _) = Cr3::read();
println!("Level 4 page table at: {:?}", level_4_page_table.start_address());
[…]
}
Функция Cr3::read из x86_64 возвращает из регистра CR3 текущую активную таблицу страниц четвёртого уровня. Возвращается пара PhysFrame и Cr3Flags. Нас интересует только первое.
После запуска видим такой результат:
Level 4 page table at: PhysAddr(0x1000)
Таким образом, в настоящее время активная таблица страниц четвёртого уровня хранится в физической памяти по адресу 0x1000, как указано типом PhysAddr. Теперь вопрос: как получить доступ к этой таблице из ядра?
При страничной организации прямой доступ к физической памяти невозможен, иначе программы смогут легко обойти защиту и получить доступ к памяти других программ. Таким образом, единственный способ получить доступ — через некую виртуальную страницу, которая транслируется в физический фрейм по адресу 0x1000. Это типичная проблема, потому что ядро должно регулярно обращаться к таблицам страниц, например, при выделении стека для нового потока.
Решения данной проблемы мы подробно опишем в следующей статье. Пока только скажем, что загрузчик использует метод под названием рекурсивные таблицы страниц. Последняя страница виртуального адресного пространства — 0xffff_ffff_ffff_f000, используем её для чтения некоторых записей этой таблицы:
// in src/main.rs
#[cfg(not(test))]
#[no_mangle]
pub extern "C" fn _start() -> ! {
let level_4_table_pointer = 0xffff_ffff_ffff_f000 as *const u64;
for i in 0..10 {
let entry = unsafe { *level_4_table_pointer.offset(i) };
println!("Entry {}: {:#x}", i, entry);
}
[…]
}
Мы свели адрес последней виртуальной страницы к указателю на u64. Как говорилось в предыдущем разделе, каждая запись таблицы страниц имеет размер 8 байт (64 бита), поэтому u64 представляет собой ровно одну запись. С помощью цикла for выводим первые 10 записей таблицы. Внутри цикла используем небезопасный блок для чтения прямо из указателя и метод offset для вычисления указателя.
После запуска видим такой результат:
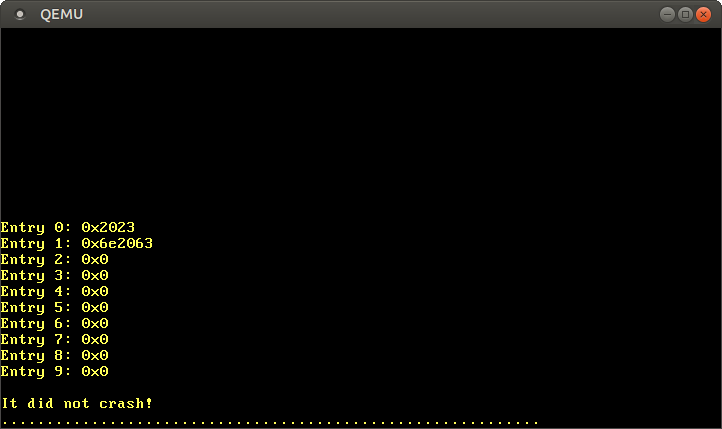
Согласно описанному выше формату, значение 0x2023 записи 0 означает наличие флагов present, writable, accessed и трансляцию во фрейм 0x2000. Запись 1 транслируется во фрейм 0x6e2000 и у неё такие же флаги, плюс dirty. Записи 2–9 отсутствуют, так что эти виртуальные диапазоны адресов не сопоставлены ни с какими физическими адресами.
Вместо работы с небезопасными указателями напрямую можно использовать тип PageTable из x86_64:
// in src/main.rs
#[cfg(not(test))]
#[no_mangle]
pub extern "C" fn _start() -> ! {
use x86_64::structures::paging::PageTable;
let level_4_table_ptr = 0xffff_ffff_ffff_f000 as *const PageTable;
let level_4_table = unsafe {&*level_4_table_ptr};
for i in 0..10 {
println!("Entry {}: {:?}", i, level_4_table[i]);
}
[…]
}
Здесь мы назначаем указателю 0xffff_ffff_ffff_f000 сначала указатель, а затем преобразуем его в ссылку Rust. Операция по-прежнему небезопасна, так как компилятор не может знать, что доступ к этому адресу допустим. Но после преобразования у нас безопасный тип &PageTable, который даёт доступ к отдельным записям через безопасные, проверенные границы операций индексирования.
x86_64 также предоставляет некоторые абстракции для отдельных записей, чтобы сразу увидеть установленные флаги:

Следующий шаг — последовать по указателям в записи 0 или записи 1 к таблице страниц уровня 3. Но теперь у нас опять возникает проблема, что 0x2000 и 0x6e5000 представляют собой физические адреса, поэтому мы не можем получить к ним прямой доступ. Эта проблема будет решена в следующей статье.
В статье представлены два метода защиты памяти: сегментация и страничная организация. Первый метод использует области памяти переменного размера и страдает от внешней фрагментации, второй использует страницы фиксированного размера и позволяет гораздо более детальный контроль над правами доступа.
Страничная организация хранит информацию о трансляции страниц в таблицах одного или нескольких уровней. Архитектура x86_64 использует четырёхуровневые таблицы с размером страницы 4 КБ. Оборудование автоматически обходит таблицы страниц и кэширует результаты преобразования в буфере ассоциативной трансляции (TLB). При изменении таблиц страниц его следует принудительно очищать.
Мы узнали, что наше ядро уже поддерживает страничную организацию, а при несанкционированном доступе к памяти выпадает PageFault. Мы попытались получить доступ к текущим активным таблицам страниц, но удалось получить доступ только к таблице четвёртого уровня, так как в таблицах страниц хранятся физические адреса, а мы не можем получить к ним доступ напрямую из ядра.
Следующая статья базируется на фундаментальных основах, которые мы сейчас усвоили. Для доступа к таблицам страниц из ядра используется продвинутая техника под названием рекурсивные таблицы страниц, чтобы пересечь иерархию таблиц и реализовывать программную трансляцию адресов. Статья также объяснить, как создавать новые трансляции в таблицах страниц.
