[Перевод] Первое слово из нераспечатанного Геркуланумского папируса обнаружено 21-летним студентом факультета информатики
Главный приз «Вызова Везувия» в размере $700 000 «теперь точно достижим»

Эта надпись была скрыта в течение 2000 лет.
Геркуланумские папирусы — древние свитки, хранившиеся в библиотеке частной виллы близ Помпеи, — были погребены и обуглены в результате извержения Везувия в 79 году нашей эры. Почти 2 тыс. лет эта единственная сохранившаяся библиотека античности была погребена под 20-метровым слоем вулканической грязи. Их раскопали в XVIII веке, и хотя они в какой-то мере сохранились благодаря извержению, они были настолько хрупкими, что при неправильном обращении превращались в пыль. Как читать свиток, который нельзя открыть? Сотни лет этот вопрос оставался без ответа.
И только в августе этого года Люк Фарритор, участник конкурса «Везувий», стал первым за последние два тысячелетия человеком, увидевшим целое слово из нераспечатанного свитка. За это мы с радостью вручаем Люку приз в размере 40 000 долларов США — приз «Первые буквы», в рамках которого участники должны были найти не менее 10 букв на площади 4 см2 в свитке.

Заявка на премию «Первые буквы» от Люка Фарритора

*Люк в лаборатории EduceLab держит тестовый свиток, изготовленный им на костре *
Вскоре после этого другой участник конкурса, Юсеф Надер, самостоятельно обнаружил то же самое слово в той же области, причём с ещё более чёткими результатами, и получил приз за второе место в размере 10 000 долл.
Ещё более четкое представление слова от Юсефа
Оба открытия были сделаны благодаря участнику конкурса Кейси Хандмеру, который первым обнаружил существенные и убедительные доказательства наличия чернил в нераспечатанных свитках, о чём он рассказал в своём блоге и в видеоролике. Его выводы привели непосредственно к открытию Люка, а также к улучшению понимания распознавания чернил. Мы присуждаем ему премию в размере $10 000 долл. Поздравляем Кейси, Люка и Юссефа!
Как же мы к этому пришли и как работают эти модели? Давайте начнём с небольшой истории.
Сканы из EduceLab
Наша история началась в 2019 г., когда профессор Брент Силз из лаборатории EduceLab Университета Кентукки получил изображения геркуланумских свитков на ускорителе частиц, создав 3D-томограммы с разрешением до 4 мкм.

Профессор Силз и его команда сканируют свитки на ускорителе частиц.
Его команда также отсканировала и сфотографировала отделённые фрагменты свитков с видимыми чернилами, что позволило получить набор опорных данных.

Обучение модели машинного обучения на основе опорных данных, полученных с помощью оторванных фрагментов. Из кандидатской диссертации Стивена Парсонса.
Аспирант профессора Силса, Стивен Парсонс, работал над обнаружением чернил на томограммах с помощью моделей машинного обучения и добился успеха на оторванных кусочках свитков. Этот успех привлёк внимание технологических предпринимателей Ната Фридмана и Дэниела Гросса, которые организовали конкурс Vesuvius Challenge, чтобы ускорить этот прогресс. Они объявили открытый конкурс в марте 2023 г. и наряду с главным призом в $700 000 назначили несколько небольших призов за разработку инструментов и методов с открытым исходным кодом.
В начале лета к нашей работе присоединилась небольшая команда аннотаторов («команда сегментации»). Они начали картировать трёхмерную структуру свитка, используя инструменты, изначально созданные EduceLab и усовершенствованные нашим сообществом. К июлю мы сегментировали и «виртуально сплющили» сотни квадратных сантиметров папируса.

Прогресс составления карты свитков, площадь (см²), из электронной таблицы Segment Directory.
Узор из трещин от Кейси
В начале августа участник конкурса Кейси Хэндмер, бывший основатель стартапа в JPL и эрудит, написал в своём блоге сообщение о том, что он обнаружил «узор из трещин», похожий на чернила.
Кейси обнаружил этот узор, глядя на сегментированные томограммы в течение нескольких часов подряд. Это было важное и неожиданное открытие. Стивен Парсонс и раньше видел прямые свидетельства наличия чернил в отделившихся фрагментах, но в свитках их ещё не было.
Кейси стал первым человеком за последние 2000 лет, обнаружившим чернила — и письмо — внутри нераспечатанного свитка.


Слева: чернила видны в виде потрескавшейся текстуры. Справа: аннотация, показывающая местоположение чернил. Это может быть «пи» или нижняя часть заглавной буквы «eta». Из сообщения в блоге Кейси.
Модель Люка Фарритора
После этой находки несколько участников конкурса начали искать трещины, но они оказались довольно редкими. Люк Фарритор, студент колледжа и летний стажёр SpaceX, работающий на Starbase, узнал о конкурсе «Везувий» из подкаст-интервью Дваркеша Пателя с Натом.
Он увидел, что модель трещин Кейси обсуждается в Discord, и начал проводить вечера и поздние ночи, тренируя модель машинного обучения на модели трещин. С каждой новой найденной трещинкой модель улучшалась, обнаруживая всё больше трещинок в свитке, раскручивая цикл открытий и уточнений.
Он нашёл несколько десятков чернильных штрихов и несколько целых букв, которые можно было пометить и использовать в качестве обучающих данных.

Слева: потрескавшиеся чернила видны на фоне папирусного волокна. Справа: Полученная бинарная чернильная метка.
Вскоре модель обнаружила невидимые глазу следы трещин. Вскоре эти следы стали складываться в буквы и намёки на настоящие слова.
Люк подал заявку на участие в конкурсе «Первые буквы», в рамках которого участники должны были найти не менее 10 букв на площади 4 см2. Это была его первая работа:
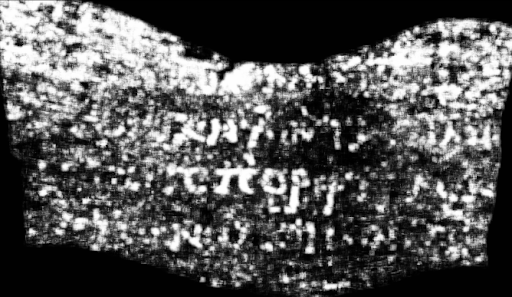
Первое сообщение от Люка, на котором слабо различимо слово ΠΟΡΦΥΡΑϹ (porphyras).
Когда профессор Силз показал это изображение нашей команде папирологов, специализирующихся на работах на папирусе, они ахнули: несмотря на слабые буквы, они сразу же смогли прочитать слово «porphyras».
После тщательной технической экспертизы мы отправили группе папирологов новый вариант его изображения. Независимо и единодушно они аннотировали 13 букв, хотя и с разной степенью уверенности:

Каждый квадрат представляет собой одну рецензию. Зелёный: более 80% уверенности. Жёлтый: 50–80% уверенности. Красный: менее 50%.
И найденное слово выдержало тщательную проверку. Слово «порфира» — очень интересное: оно означает «пурпурный» и довольно редко встречается в древних текстах.
Один из папирологов отмечает:
«Последовательность πορφυ̣ρ̣ας̣ может быть πορφύ̣ρ̣ας̣ (существительное, пурпурный краситель или ткани пурпурного цвета) или πορφυ̣ρ̣ᾶς̣ (прилагательное, пурпурный). Из-за отсутствия контекста невозможно исключить πορφύ̣ρ̣α ς̣κ[ или πορφυ̣ρ̣ᾶ ς̣κ[».
Если вы пытаетесь найти эти буквы на изображении, имейте в виду, что наши современные символы выглядят несколько иначе. Буквы древнего письма выглядят примерно так: ΠΟΡΦΥΡΑϹ. Заметим, что в текстах этого времени не использовались пробелы, что затрудняет определение границ слов.
Материалы, представленные на конкурс «Первые письма Луки», уже доступны на GitHub.
Открытие Юсефа
Тем временем другой участник конкурса, Юсеф Надер, египетский аспирант, изучающий биоробототехнику в Берлине, использовал другой подход. Вдохновлённый результатами Кейси и Люка, он проанализировал работы победителей конкурса Kaggle «Поиск чернил», который был посвящён совершенствованию подхода Стивена Парсонса к машинному обучению на отдельных фрагментах. Для адаптации этих моделей к свиткам он использовал технику переноса домена: предварительное обучение без подконтрольной проверки на данных свитка с последующей тонкой настройкой на метках фрагментов.

Один из оторванных фрагментов с известными данными сканируется на ускорителе частиц.
Он представил свою идею на соискание премии «Ink Detection Followup Prize» и получил небольшую премию. Идея показалась перспективной, но, насколько мы знали, на этом всё и закончилось. Несколько недель спустя Юсеф подал свою заявку на премию «Первые буквы». Он увидел первые результаты Люка, которыми тот делился в Twitter и Discord, и решил сфокусироваться на той же области в рамках свитка.
С помощью модифицированной модели, полученной на конкурсе Kaggle, ему удалось найти несколько букв, хотя и без использования метода Кейси по поиску трещин вручную. Затем он приписал к данным метки, которые выглядели как буквы.

Самое раннее изображение от Юсефа.

Первый набор предполагаемых чернильных меток.
Он последовательно повторял эту псевдоразметку, в результате чего были получены метки для ряда сегментов свитка. Модели, обученные на этих метках, были способны обнаруживать чернила внутри свитка, а обучающие данные, полученные на отделённых фрагментах свитка, в итоге были удалены.
В итоге модели, обученные исключительно на внутренних сегментах свитка, позволили получить изображение, представленное ниже, что и принесло Юссефу награду.

Окончательный вариант от Юсефа.
На этот раз папирологи сошлись во мнении относительно букв. Они даже начали строить предположения о возможных словах выше (ανυοντα / ANYONTA, «достижение») и ниже (ομοιων / OMOIωN, «подобный»).
Если там действительно есть эти слова, то этот папирусный свиток, скорее всего, содержит совершенно новый текст, незнакомый современному миру.
Работа Юсефа, представленная на соискание премии «Первые письма», уже доступна на GitHub.
Как мы добились успеха?
На сложном пути к этим открытиям разные люди внесли множество вкладов. Наше сочетание конкуренции и открытого источника (через «призы за прогресс»), похоже, сработало! Выделим несколько ключевых вкладов:
Юсеф использовал модель, полученную на конкурсе Kaggle, и был вдохновлён результатами Люка на поиск в той же области.
Поиск трещин, который провёл Люк, был непосредственно вдохновлён работой Кейси.
Кейси смог просмотреть множество листов папируса, потому что наша команда сегментации нанесла на карту сотни см2.
Команда сегментации смогла нанести на карту большое количество папируса благодаря инструментарию, созданному участниками конкурса, работавшими над «Призами за инструментарий сегментации» (работы Джулиана Шиллигера, Чака, Яо Сяо и многих других).
Достижения в области инструментов сегментации стали возможны благодаря тому, что участники конкурса создавали инструменты на основе уже существующих открытых программных средств, разработанных командой профессора Силса (работы Сета Паркера, Стивена Парсонса и многих других). И, конечно, сам конкурс был бы невозможен без того фундамента, который заложили и продолжают поддерживать доктор Силс и его команда, а также спонсоры.
Оглядываясь назад, на то, что привело нас к этому моменту, можно сказать, что почти всё, что мы делали до сих пор в ходе проведения конкурса, было сложным. Мы не совсем понимаем, что с этим делать! Возможно, прогресс более хрупок, а успех более условен, чем это часто кажется в ретроспективе.
Что дальше?
Команда сегментаторов и участники конкурса продолжают продвигаться вперёд, и несколько дней назад модель Юсефа создала новое изображение потрясающей чёткости и размера:

Последнее изображение от Юсефа, из сегментов 20230929220924 и 20231005123333.
На этом изображении хорошо видны четыре с половиной колонки текста, разделённые полями. Теперь видно гораздо больше букв, хотя не все из них можно сразу разобрать. Наша папирологическая группа работает над дальнейшим изучением этого результата, и в ближайшее время мы сообщим об этом.
Эти успехи свидетельствуют о том, что главный приз в размере $700 000 долларов находится в пределах досягаемости. Наш оптимизм находится на самом высоком уровне.
Сейчас самое время принять в этом участие! Присоединяйтесь к нашему активному сообществу Discord, подписывайтесь на рассылку новостей через Substack или следите за @scrollprize на сайте X. Чтобы начать работу, загрузите данные, пройдитесь по нашим учебным пособиям и ознакомьтесь с успехами участников конкурса, посмотрев на победителей и инструменты сообщества.
Может быть, вы станете человеком, который откроет знания, содержащиеся в сотнях свитков — удвоив количество известных текстов древности — и, возможно, в тысячах других, которые ещё предстоит раскопать, став последним героем Римской империи и выиграв $700 000 в процессе?
Гонка продолжается.
