[Перевод] Отладка гейзенбагов: история о параллельной обработке
Гейзенбаг (существительное)
Баг, исчезающий при попытке его отладить
Пролог
Недавно мы занимались крупнейшей миграцией в кодовой базе Python Analyzer, стремясь её ускорить. Среди прочих изменений одно крупное улучшение заключалось в следующем: теперь анализатор стал использовать concurrent.futures.ProcessPoolExecutor для параллельного выполнения независимых задач — таким образом мы могли задействовать все ядра ЦП.
И всё сработало довольно хорошо — в больших репозиториях мы наблюдали существенное увеличение скорости, и со временем ситуация бы только улучшилась. Мы смогли бы лучше контролировать, как функционируют инспекторы ошибок.
Глава 0: Первый камень преткновения
В течение первых двух недель после того, как было развёрнуто обновление, мы стали фиксировать аварийное завершение некоторых аналитических прогонов. Отчасти это было ожидаемо — при такой крупной миграции неизбежно возникнут пограничные случаи, и мы просто должны быть способны оперативно отлаживать любые возникающие проблемы.
Симптомы
Заглядывая в логи этих прогонов, мы заметили, что наш пул процессов аварийно завершается с ошибкой BrokenProcessPool. Обычно такие аварийные ситуации происходили только в больших репозиториях при попытке проанализировать большое количество файлов.
Так случалось не каждый раз. Иногда такой анализ проходил без проблем. То есть, прогоны были хрупкими.
Диагноз
Этот ответ подсказывает, что подобное могло происходить, поскольку процесс израсходовал всю доступную память. Время присмотреться к мониторингу.
Наши аналитические задания мы выполняем через Google Cloud, и они работают в контейнерах, мониторинг которых удобно осуществлять при помощи GCP Monitoring. Если перезапустить один из неудавшихся анализов и пронаблюдать, как используется RAM, видим следующее:
График использования памяти
(к сожалению, это оригинальный размер изображения)
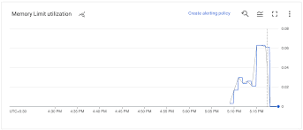
Очень похоже, что в контейнере заканчивается память.
Мы убедились, что контейнер действительно примерно на 100% выгребает тот лимит памяти, который для него установлен.
Задача
Проведя дополнительные исследования, мы стали понимать, что проблема, по-видимому, заключается в очереди задач.
Мы не совсем правильно задавали футуры. Вот, например, как бы мы поступили, чтобы параллельно применить процесс ко всем элементам в составе любого заданного набора данных:
def process(item):
... # do something here
data = get_data()
results = []
with concurrent.futures.ProcessPoolExecutor(CPU_COUNT) as executor:
futures = []
for item in data:
futures.append(executor.submit(process, item))
for future in concurrent.futures.as_completed(futures):
result = future.result()
results.append(result)
# Здесь что-то делаем с результатами
На первый взгляд код кажется прямолинейным и корректным, и в основном так и есть, но упускается из виду одна вещь: ограниченный объём памяти, имеющейся у нас в распоряжении.
При каждом вызове executor.submit создаётся футура. Теперь в этой футуре будет содержаться копия тех данных, что вы её передали. Затем приступаем к выполнению футур. В каждой футуре так или иначе выполняется выделение памяти, обработка, а затем возвращение результата. К моменту окончания вычислений у нас будет список футур, в котором будут содержаться все футуры до одной, а также их память.
Причём, элементов очень много: могут быть созданы сотни и даже тысячи футур, и все они поедают память. В результате мы столкнёмся с отказами при попытках выделить память, что, соответственно, приведёт к ошибкам BrokenProcessPool.
Исправление
Есть два способа это исправить. Во-первых, можно начать объединять задачи в пакеты, код которых будет выглядеть примерно так:
with concurrent.futures.ProcessPoolExecutor(CPU_COUNT) as executor:
while data:
futures = []
# Less jobs at a time
for item in data[:10]:
futures.append(executor.submit(process, item))
for future in concurrent.futures.as_completed(futures):
item, result = future.result()
results.append(result)
data.remove(item)
# Здесь что-то делаем с результатами
Теперь мы храним всего десять футур, а затем отбрасываем их, как только получим результат. Также мы удаляем те элементы, которые уже успели обработать.
Однако, есть даже более простой способ решить эту задачу:
with concurrent.futures.ProcessPoolExecutor(CPU_COUNT) as executor:
futures = (executor.submit(process, item) for item in data)
for future in concurrent.futures.as_completed(futures):
result = future.result()
results.append(result)
# Здесь что-то делаем с результатами
Это интересно: мы превратили футуры в генератор.
Теперь мы уже не храним список футур, как ранее, и ситуация меняется: ведь генератор ленивый. Он создаст футуру, только, если мы об этом попросим. А as_completed запрашивает у него футуру только при условии, что имеется пространство, в котором её можно было бы запустить. Поскольку мы используем футуру только в цикле for, она попадает под сборку мусора на каждой итерации.
Таким образом, мы получаем результат, а затем сразу же избавляемся от уже не нужной нами футуры. Память не пожирается, проблема решена! Верно?
Глава 1: Фантомные задержки
Теперь в большинстве случаев анализатор работал идеально, как и ожидалось. Но в некоторых редких случаях начинали наблюдаться какие-то задержки.
Мы установили пороговое значение в 25 минут — в качестве максимальной длительности анализа в одном репозитории. При превышении этого порога мы отменяем анализ и сбрасываем его с пометкой «timed out» (время истекло). 25 минут — это очень долго для анализа, и обычно такие задержки случаются только при наличии какого-либо бага в анализаторе.
Симптомы
Такое поведение казалось очень хаотичным и непредсказуемым.
То и дело в ходе анализа, примерно через 10 минут после пуска, вывод логов просто прекращался. Как будто контейнер переставал их печатать потому, что в нём прекращались всякие события.
Через 25 минут контейнер приходилось убить. Поскольку никакого результата при этом не генерировалось, ситуация подавалась как задержка.
Не было никакого реального способа подробнее выяснить причины такого зависания, поскольку извне зайти в продакшен-контейнеры невозможно.
Диагноз
На первый взгляд, это классическая проблема из области многопроцессорной разработки. Казалось, что либо у нас взаимная блокировка, либо какой-то рабочий процесс, которого мы дожидаемся, застрял в бесконечном цикле. Поэтому мы принялись закапываться в исходный код:
• Есть ли где-нибудь в базе кода бесконечные циклы, любые циклы while? Нет.
• Чрезвычайно длительная обработка? Для каждого процесса, который мы порождали, предусматривалась задержка, поэтому и здесь проблем не могло возникать.
• Взаимные блокировки? Возможно. Но в состоянии взаимной блокировки процессы не должны потреблять ЦП.
Всё время продолжали поступать новые процессы с памятью. В качестве предохранительной меры против неуловимых ошибок BrokenProcessPool мы модифицировали код — так, чтобы воссоздавать пул, если такая ошибка произойдёт:
executor = concurrent.futures.ProcessPoolExecutor(CPU_COUNT)
process_pool_broke = False
while data:
futures = ...
try:
for future in concurrent.futures.as_completed(futures):
item, result = future.result()
results.append(result)
data.remove(item)
except BrokenProcessPool:
executor.shutdown(wait=False)
logger.info("Re creating pool...")
executor = concurrent.futures.ProcessPoolExecutor(CPU_COUNT)
executor.shutdown()
# Здесь что-то делаем с результатами
В логах мы также наблюдаем воссоздание пула. Соответственно, память в данном случае тоже съедалась. До того мы не уделяли этому пристального внимания, поскольку все признаки указывали на взаимную блокировку.
Изыскания
Теперь проблема заключается в том, что мы должны как-то воссоздать это поведение. Тот репозиторий, из-за которого подвисал анализ, оказался приватным, поэтому мы не могли воссоздать на локальной машине ровно то же окружение. Требовалось найти публичный репозиторий, при работе с которым провоцируется такая же проблема. Правда, была одна ниточка: представлялось, что в репозитории должно быть 800 или около того файлов на Python, то есть, речь шла о большом проекте.
Мы пробовали прогонять через продакшен-анализатор большие проекты, например, Django — и нам не везло. Всякий раз анализ проходил как по маслу.
Мы искали свидетельства о задержках в истории анализатора, чтобы найти другие крупные репозитории, в которых такие задержки ранее фиксировались, и нашли пару подобных репозиториев с открытым исходным кодом. Каким-то образом, попытав счастья примерно с дюжиной репозиториев и ни разу не сумев получить взаимную блокировку, мы нашли такой, в котором удалось воспроизвести проблему. Проект назывался weblate.
Мы попытались повторно запустить анализатор, чтобы посмотреть, можно ли уверенно воспроизвести баг в этом репозитории weblate. И… неудачно.
Попробовали несколько раз — нет задержки. Действительно, самый настоящий гейзенбаг. Что ж, хотя бы в этом отношении поведение развивается последовательно: те задержки, которые побудили нас заняться этим расследованием, тоже исчезали при попытке повторно прогнать тот же самый анализ.
Попытка проанализировать weblate на нашем внутреннем инстансе DeepSource нам также не помогла: никаких задержек, никаких зависаний.
Докопаться до истины
Итак, у нас был один случайным образом отказывающий репозиторий, а теперь их стало два. Может показаться, будто мы вдвое усугубили проблему, но на самом деле это был не тупик — теперь можно было приступать к проведению параллелей между двумя прогонами, искать, в чём же они схожи. Может быть, нам удалось бы точнее охарактеризовать те условия, которые должны быть соблюдены, чтобы этот баг проявился.
Порывшись в логах двух проектов, мы нашли кое-что странное. В самом начале там есть одна строка:
INFO: Running analysis in parallel mode, core count: 24
Это было чуть странно, поскольку, как мы заметили, у нас в кластере одновременно выполняется 24 процесса, а количество процессов, переданных исполнителю, вдвое превышает количество ядер:
for item in data[: CPU_COUNT * 2]:
futures.append(executor.submit(process, item))
Мы добавили дополнительное логирование, стараясь воспроизвести эту проблему — и, действительно, в ходе обоих неудавшихся анализах одновременно работало по 48 процессов, а не по 24, как ожидалось.
Мы проверили логи тех внутренних прогонов, которые не приводили к задержкам, и логи показали:
INFO: Running analysis in parallel mode, core count: 12
12 ядер, 24 процесса.
Анализ проходит успешно, когда в деле 12 ядер, и неуспешно — когда 24. Мы нашли общий знаменатель. Теперь, чтобы быть на 100% уверенными, мы должны были надёжно воспроизвести этот баг.
Давайте рассмотрим определение CPU_COUNT:
# Откат к 4 ядрам, если заданное количество недоступно
CPU_COUNT = os.cpu_count() or 4
Заменили это значение на жёстко запрограммированное:
CPU_COUNT = 24
Сделали это, попытались проанализировать weblate на нашем внутреннем инстансе анализатора — и, вуаля! Воспроизводится. Анализ из раза в раз застревает спустя 10 минут работы.
Наконец-то мы прижучили баг: Когда число os.cpu_count () велико, получаются задержки.
Реальная проблема
Наши контейнеры работают на Google Kubernetes Engine, представляющем собой управляемый многоядерный кластер k8s. Но у нас в аналитических кластерах лимитируются ресурсы, так, что анализ допускается проводить не более чем на 4 ядрах ЦП одновременно.
Так вот в чём дело. Почитав документацию, удалось выяснить, что лимитирование ресурсов в Kubernetes обычно осуществляется путём ограничения «процессорного времени», а не количества задействованных ядер.
Таким образом, если указать процессу, что он может «использовать 4 ядра ЦП», то на практике он будет использовать не 4 ядра, а все до одного ядра в кластере. Но планировщику будет приказано ограничить количество циклов ЦП, которые могут быть использованы данным кластером, так, чтобы это количество было эквивалентно эксплуатации 4 ядер.
Пока не укладывается в голове? Давайте объясню на примере:
Допустим, у вас в кластере имеется 40 ядер. Если вы укажете, что каждый кластер должен использовать максимум 4 ядра, то процессор будет ограничен не 4 ядрами, а 10% процессорного времени. Если в настоящее время у вас фактически работает только один контейнер, то процесс будет потреблять 10% процессорного времени на каждом из ядер ЦП, работающих в этом кластере.
Это означает две вещи:
1. os.cpu_count () будет видеть все ядра, присутствующие в кластере, даже если для ЦП будут заданы ограничения. А поскольку мы используем такое количество ядер для порождения некоторого числа процессов, мы будем порождать большее количество процессов на то же количество «процессорного времени».
В предыдущем примере, если мы порождали 5%, то каждый процесс получал 2% от общей доли в 10% процессорного времени. Но, если породить 10 процессов, то каждый из них вдруг замедляется вдвое, поскольку получает всего по 1% от общего количества ресурсов.
Итак, если на той машине, где работает процесс, ядер ЦП больше, чем ожидалось, то каждый создаваемый нами параллельный процесс вдруг начинает работать вдвое медленнее без какой-либо причины.
2. Чем больше процессов мы порождаем, тем больше памяти в итоге используем. Если вместо 12 ядер на машине окажется 24 ядра, то расход памяти у нас внезапно удвоится. А поскольку использование памяти у нас в контейнере никак не лимитировано, проблемы с памятью нам обеспечены.
Итак, суть бага заключалась не в параллельной обработке, а в планировании. Это объясняет, почему он не воспроизводился на внутреннем инстансе: наш внутренний инстанс запускал в кластер более мелкие машины, тогда как в продакшен-кластере были более крупные машины, и ядер на них тоже было больше.
Исправление
Проблема исправлялась незамысловато: требовалось задать сократить максимальное количество процессов, остановиться, например, на 8:
CPU_COUNT = os.cpu_count() or 4
PROCESS_COUNT = min(2 * CPU_COUNT, 8)
...
with executor:
for item in data[: PROCESS_COUNT]: # Changed from CPU_COUNT * 2
futures.append(executor.submit(process, item))
# Оставшаяся часть кода – без изменений
После того, как мы это проделали, все задержки исчезли.
Производительность нашего анализатора от этого не снижается, поскольку пока ваши процессы используют 100% процессорного времени, выделяемого вашему контейнеру, вы работаете с максимальной достижимой скоростью.
Фактически, производительность в таком случае даже возрастает, поскольку при использовании меньшего объёма памяти меньше ресурсов тратится на подкачку страниц, пробуксовку памяти и т.д. — в конечном итоге, скорость работы у каждого отдельного процесса возрастает.
Заключение
Вся эта отладочная сага не научила нас чему-либо особенно новому. Но вот какие уроки мы извлекли из проделанной работы:
• Первым делом нужно воспроизвести проблему. Если не удаётся надёжно воспроизвести баг, то, каких бы исправлений вы ни вносили, вы не можете знать наверняка, сработают ли они.
• Второй шаг — это исключение и отыскание общих паттернов. Заметив схожести между двумя экземплярами бага, добавив логи и устранив возможные источники проблемы вы, в конце концов, доберётесь до корня проблем.
• Свою инфраструктуру нужно знать, даже, если вы работаете в контейнере. Docker решает множество проблем, изолируя ваше рабочее окружение, но не проблему ограничений, накладываемых на ресурсы.
Эпилог
К моменту, когда эти исправления были внесены, схожие проблемы с памятью стали просматриваться в нашем анализаторе Ruby — возникали исключения DeadWorker. Точно такое же исправление (ограничение, согласно которому анализатор может порождать максимум 8 процессов) позволило устранить задержки и в данном случае.
Неделю спустя то же самое произошло с PHP, и наше исправление снова сработало same.
Так мы расправились с одним гнусным гейзенбагом.
P.S.
На сайте издательства продолжается весенняя распродажа.
