[Перевод] Обработка данных NBA за 30 лет с помощью MongoDB Aggregation
Прим. перев.: Американский писатель Майкл Льюис известен не только своими историями о трейдерах с Уолл Стрит, но и (в первую очередь) книгой Moneyball, по которой впоследствии был снят одноименный фильм («Человек, который изменил все»). Главный ее герой — Билли Бин, генеральный менеджер бейсбольной команды «Oakland Athleticks», создает конкурентоспособную команду исключительно на основе анализа статистических показателей игроков.Памятуя об этом, мы решили опубликовать один любопытный материал о том, к каким интересным и нетривиальным выводам можно прийти, анализируя публично доступную статистику игр NBA за последние 30 лет с помощью фреймворка MongoDB Aggregation. Несмотря на то, что в данном примере автор анализирует показатели команд в целом, а не статистику по отдельным игрокам (она также находится в открытом доступе), он приходит к весьма занимательным выводам — руководствуясь его выкладками вполне реально провести самостоятельный анализ, подобно тому, как в свое время поступили герои Moneyball.
При поиске средства анализа массивов данных больших объемов и сложной структуры вы можете инстинктивно обратиться к Hadoop. С другой стороны, если вы храните свои данные в MongoDB, использование Hadoop Connector кажется излишним, особенно если все ваши данные помещаются на ноутбук. К счастью, встроенный фреймворк MongoDB Aggregation предлагает быстрое решение для проведения комплексной аналитики прямо с экземпляра MongoDB без установки дополнительного ПО.
Будучи с детства баскетбольным фанатом, я всегда мечтал научиться проводить комплексную аналитику статистики NBA. Когда настало время хакатона MongoDB Driver Days, и ведущий Ruby-инженер Гэри Мураками предложил составить интересный массив данных, мы сели и с полудня до вечера писали и запускали скрепер [англ. scraper, программа для извлечения данных с веб-страниц] для сайта basketball-reference.com. Полученный массив данных состоял из итогового счета и статистики игроков для каждого матча регулярного чемпионата NBA начиная с сезона 1985–1986 годов.
В документации к фреймворкам агрегирования [данных] часто используются массивы данных почтовых индексов, демонстрирующие способы использования подобного фреймворка. Однако обработка данных о населении США не сильно поражает мое воображение, и есть определенные форматы использования фреймворка агрегирования, которые не получится проиллюстрировать на примере массива почтовых индексов. Надеюсь, этот массив данных позволить вам по-новому взглянуть на фреймворк агрегирования, а вам понравится разбираться в статистике NBA. Вы можете скачать массив данных здесь и вставить его в свой экземпляр MongoDB с помощью команды mongorestore.
Исследуем данные
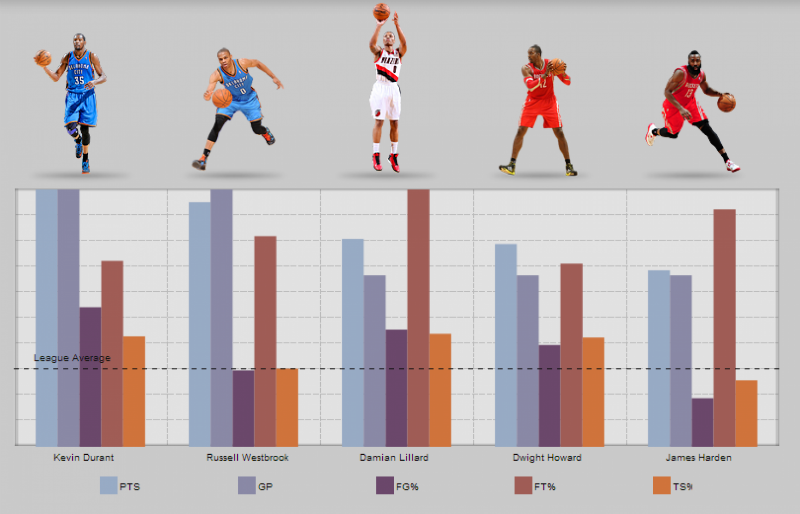
Для начала давайте рассмотрим структуру данных. Начиная с сезона 1985–86, в регулярном чемпионате NBA было сыграно 31 686 игр. Каждый отдельный документ представляет собой сведения об одной игре. Ниже представлены метаданные матча открытия сезона 1985–86 между командами «Washington Bullets» и «Atlanta Hawks», как показано в RoboMongo, универсальном графическом интерфейсе MongoDB: 
В состав документа входят вложенный подраздел с подробной статистикой матча, поле даты и информация об игравших командах. Можно увидеть, что «Bullets» одержали победу на выезде со счетом 100–91. Данные статистики матча (box score) похожим образом разбиты по командам в массиве, начиная с победившей. Обратите внимание, что флажок «won» является элементом верхнеуровневого объекта box score наряду с элементами «team» и «players».
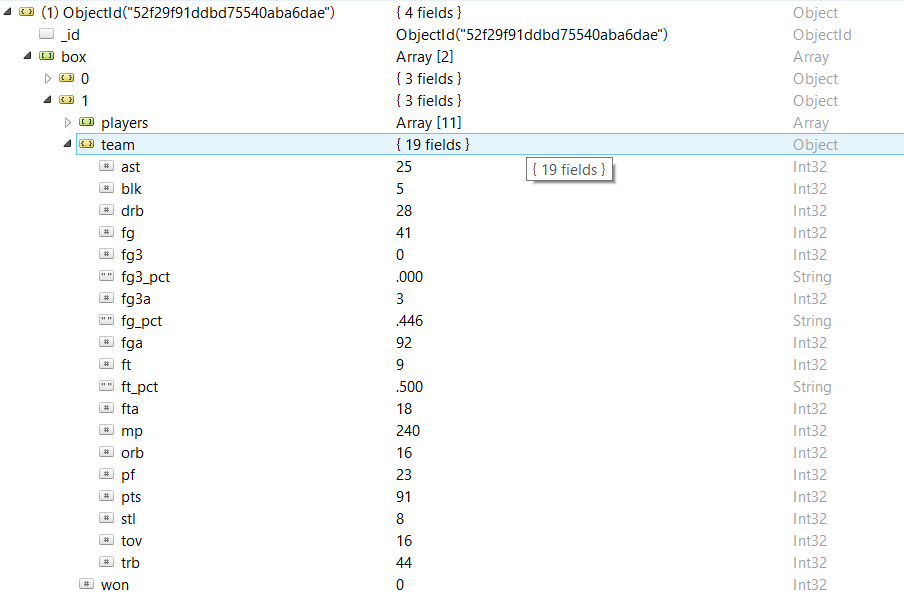
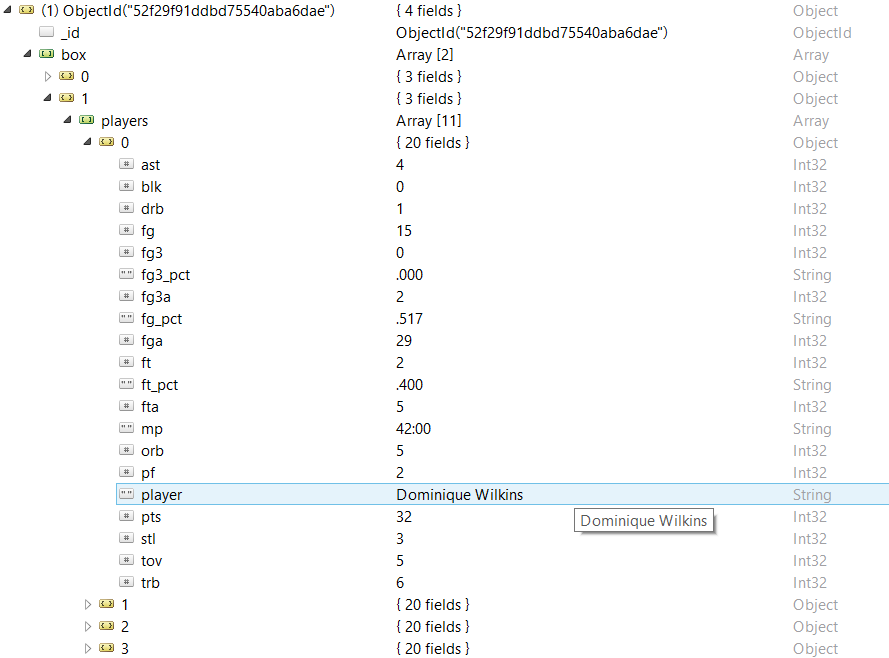
Далее статистика игры разбивается на статистику команды и статистику игроков. Статистика команды на рисунке выше отображает общие данные по команде «Atlanta Hawks», согласно которым они реализовали 41 из 92 бросков с игры и забросили всего лишь 9 из 18 мячей с линии штрафной. В массиве данных игроков представлена та же информация, но распределенная по отдельным игрокам. К примеру, ниже вы увидите, что звезда «Hawks» Доминик Уилкинс набрал 32 очка при 15 результативных бросках с игры из 29 и записал на свой счет 3 перехвата.
Проведение агрегирования В общем смысле, фреймворк MongoDB Aggregation реализован в виде шелл-функции aggregate: она содержит набор операций, которые могут быть объединены в цепочки. Каждый этап в цепочке операций осуществляется на основе результатов предыдущего этапа, и на каждом этапе можно сформировать выборку и возвратить результат в виде документа.Прежде чем начать серьезные вычисления, предлагаю запустить простую проверку работоспособности системы и вычислить 5 команд, одержавших наибольшее количество побед в сезоне 1999–2000 годов. Эти команды можно определить, следуя цепочке операций из 6 этапов:
Используем оператор $match, чтобы работать дальше только с играми, проходившими в период между 1 августа 1999 года и 1 августа 2000 года — две даты, отстоящие достаточно далеко от любой из игр NBA и надежно ограничивающие этот сезон. Используем оператор $unwind, чтобы сгенерировать по одному документу для каждой команды в матче. Снова применяем оператор $match, чтобы отсеять только победившие команды. Используем оператор $group, чтобы посчитать, сколько раз данная команда появляется в качестве результата на шаге 3. Используем оператор $sort для сортировки количества побед по убыванию. Применяем оператор $limit, чтобы отобрать 5 команд с наибольшим числом побед. Итоговая шелл-команда представлена ниже. Эта команда на моем ноутбуке выполняется в режиме реального времени даже при отсутствии в базе индексов, так как в выборке всего 31 686 документов. db.games.aggregate ([ { $match: { date: { $gt: ISODate (»1999–08–01T00:00:00Z»), $lt: ISODate (»2000–08–01T00:00:00Z») } } }, { $unwind: '$teams' }, { $match: { 'teams.won' : 1 } }, { $group: { _id: '$teams.name', wins: { $sum: 1 } } }, { $sort: { wins: -1 } }, { $limit: 5 } ]); Этот простой пример можно обобщить для того, чтобы ответить на вопрос, какая из команд одержала больше всего побед в промежутке между сезонами 2000–2001 и 2009–2010 годов, заменяя на шаге использования функции $match время проведения игр на период между 1 августа 2000 года и 1 августа 2010 года. Выясняется, что «San Antonio Spurs» одержали в этот период 579 побед, ненамного обойдя «Dallas Mavericks» с 568 победами. db.games.aggregate ([ { $match: { date: { $gt: ISODate (»2000–08–01T00:00:00Z»), $lt: ISODate (»2010–08–01T00:00:00Z») } } }, { $unwind: '$teams' }, { $match: { 'teams.won' : 1 } }, { $group: { _id: '$teams.name', wins: { $sum: 1 } } }, { $sort: { wins: -1 } }, { $limit: 5 } ]); Определение связи статистики с числом побед Теперь сделаем кое-что немного более интересное, используя пару операторов агрегирования, которые нечасто встретишь при анализе массивов данных почтовых индексов: оператор $gte и оператор $cond на этапе $project. Используем эти операторы, для того чтобы вычислить, как часто побеждает команда, которая сделала больше подборов в защите, чем их противники, на всем массиве данных.Небольшая сложность здесь возникает при нахождении разности общего числа подборов в защите победившей и проигравшей команд. Фреймворк агрегирования вычисляет эту разность немного неоднозначно, но, используя оператор $cond, мы можем так преобразовать документ, что общее количество подборов в защите будет отрицательным, если команда проиграла. В этом случае мы сможем использовать оператор $group для вычисления разности подборов в защите в каждой игре. Пройдемся по алгоритму поэтапно:
Используем оператор $unwind для получения документа с подробной статистикой по каждой команде в данной игре.
Используем операторы $project и $cond, чтобы преобразовать каждый документ, так что общее число подборов команды в защите будет выражено отрицательным значением, если она проиграла: информация о результатах игры определяется по флажку «won».
Используем операторы $group и $sum, чтобы подсчитать общее количество подборов в каждой игре. Так как в результате предыдущего этапа общее число подборов проигравшей команды стало отрицательным, то теперь в каждом документе есть разность между количеством подборов в защите победившей и проигравшей команд.
Используем операторы $project и $gte для создания документа, в котором будет содержаться флажок winningTeamHigher, принимающий значение «true», если победившая команда сделала больше подборов в защите, чем проигравшая.
Используем операторы $group и $sum, для того, чтобы вычислить, в скольких играх флажок winningTeamHigher принимал значение «true».
db.games.aggregate ([
{
$unwind: '$box'
},
{
$project: {
_id: '$_id',
stat: {
$cond: [
{ $gt: ['$box.won', 0] },
'$box.team.drb',
{ $multiply: ['$box.team.drb', -1] }
]
}
}
},
{
$group: {
_id: '$_id',
stat: { $sum: '$stat' }
}
},
{
$project: {
_id: '$_id',
winningTeamHigher: { $gte: ['$stat', 0] }
}
},
{
$group: {
_id: '$winningTeamHigher',
count: { $sum: 1 }
}
}
]);
Результат получился довольно любопытным: команда, записавшая на свой счет больше подборов в защите, побеждала в 75% случаев. Для сравнения, команда, на счету которой больше бросков с игры, чем у другой команды, выигрывает лишь в 78,8% случаев! Попробуйте переписать алгоритм агрегирования для других показателей, таких как броски с игры, трехочковые, количество потерь и др. Вы получите ряд довольно интересных результатов. Количество подборов в нападении, как оказывается, не стоит использовать для предсказания результата игры, так как команда, забравшая больше подборов в нападении, победила всего в 51% случаев. Оказывается, что по количеству трехочковых бросков предсказать победителя можно гораздо точнее: команда с большим числом трехочковых попаданий победила в 64% случаев.Сопоставляем подборы в защите и общее число подборов с процентом побед
Давайте проанализируем данные, для которых будет интересно нарисовать график. Будем вычислять процент побед команды как функцию от количества реализованных подборов в защите. Такую агрегацию провести довольно легко: все, что нужно сделать — это выполнить оператор $unwind для статистики матча и использовать $group, чтобы посчитать среднее число флажков «won» по всем значениям общего количества подборов в защите.
db.games.aggregate ([
{
$unwind: '$box'
},
{
$group: {
_id: '$box.team.drb',
winPercentage: { $avg: '$box.won' }
}
},
{
$sort: { _id: 1 }
}
]);
Если визуализировать результаты агрегирования, то можно получить неплохой график, четко показывающий довольно высокую корреляцию между числом подборов в защите и процентом побед. Любопытный факт: командой, забравшей наименьшее количество подборов в случае победы, были «Toronto Raptors» в сезоне 1995–96 годов, обыгравшие «Milwaukee Bucks» со счетом 93–87 26 декабря 1995 года, несмотря на всего лишь 14 подборов в защите, сделанных в этой игре.
Для того, чтобы провести подобный анализ для общего числа подборов по сравнению с подборами в защите, мы можем довольно легко поменять алгоритм агрегирования выше и посмотреть, изменятся ли результат.
db.games.aggregate ([ { $unwind: '$box' }, { $group: { _id: '$box.team.trb', winPercentage: { $avg: '$box.won' } } }, { $sort: { _id: 1 } } ]); И он действительно меняется! Где-то после результата в 53 общих подбора положительная корреляция между общим числом подборов и процентом побед полностью исчезает! Корреляция здесь явно не такая высокая, как в случае с подборами в защите. Кстати сказать, «Cleveland Cavaliers» взяли верх над «New York Knicks» со счетом 101–97 11 апреля 1996 года, несмотря на то, что в общем они забрали всего 21 подбор. С другой стороны, «San Antonio Spurs» уступили «Houston Rockets» со счетом 112–110 4 января 1992 года при том, что их общее число подборов составило 75.Заключение Я надеюсь, этот пост заинтересовал вас темой фреймворков агрегирования так же, как и меня. Еще раз напомню, что вы можете скачать массив данных здесь — я настоятельно рекомендую вам поработать с этими данными самостоятельно.
