[Перевод] Об архитектурах систем хранения данных
 Каким образом нужно классифицировать архитектурные схемы СХД? Мне кажется, актуальность этого вопроса в дальнейшем будет только расти. Как разобраться во всём этом многообразии предложений, имеющихся на рынке? Сразу хочу предупредить, что этот пост не предназначен для ленивых или не желающих много читать.
Каким образом нужно классифицировать архитектурные схемы СХД? Мне кажется, актуальность этого вопроса в дальнейшем будет только расти. Как разобраться во всём этом многообразии предложений, имеющихся на рынке? Сразу хочу предупредить, что этот пост не предназначен для ленивых или не желающих много читать.
Можно вполне успешно классифицировать системы хранения, наподобие того, как биологи выстраивают родственные связи между видами живых организмов. Если хотите, можно назвать это «древом жизни» мира технологий хранения информации.Построение подобных древ помогает лучше понимать окружающий мир. В частности, можно выстроить схему происхождения и развития любых видов СХД, и быстро понять, что же лежит в основе любой новой технологии, появляющейся на рынке. Это позволяет сразу определить сильные и слабые стороны того или иного решения.
Хранилища, позволяющие работать с информацией любого вида, архитектурно можно разделить на 4 основные группы. Главное, не зацикливаться на некоторых вещах, которые сбивают с толку. Многие склонны классифицировать платформы на основе таких «физических» критериев, как межкомпонентное соединение (interconnect) («У них у всех есть внутренняя шина между нодами!»), или протокол («Это блок, или NAS, или многопротокольная система!»), или делят на аппаратные и программные («Это же просто ПО на сервере!»).
Это совершенно неправильный подход к классифицированию. Единственно верным критерием является программная архитектура, используемая в том или ином решении, поскольку от этого зависят все основные характеристики системы. Остальные компоненты СХД зависят от того, какая именно программная архитектура была выбрана разработчиками. И с этой точки зрения «аппаратные» и «программные» системы могут быть лишь вариациями той или иной архитектуры.
Но не поймите меня неправильно, я не хочу сказать, что разница между ними невелика. Просто она не фундаментальна.
И хочу ещё кое-что уточнить, прежде чем перейти к делу. Для нашей натуры свойственно задавать вопросы «А что из этого самое лучшее/правильное?». Ответить на это можно только одно: «Есть лучшие решения для каких-то конкретных ситуаций или видов нагрузки, но не существует универсального идеального решения». Именно особенности нагрузки диктуют выбор архитектуры, и больше ничто другое.
К слову, недавно я участвовал в забавной беседе на тему ЦОД, работающих исключительно на флэш-накопителях. Мне импонирует страстность в любых проявлениях, и совершенно очевидно, что флэш вне конкуренции в ситуациях, когда производительность и время задержки играют решающую роль (помимо многих других факторов). Но должен признать, что мои собеседники были неправы. У нас есть один клиент, его услугами, даже не подозревая об этом, ежедневно пользуется множество людей. Может ли он полностью перейти на флэш? Нет.

Это большой клиент. А вот другой, ОГРОМНЫЙ, раз в 10 больше. И я опять не могу согласиться с тем, что этот клиент может перейти исключительно на флэш:

Обычно в качестве контраргумента заявляют, что в конце концов флэш достигнет такого уровня развития, что затмит магнитные накопители. С оговоркой, что флэш будет применяться с паре с дедупликацией. Но не во всех случаях целесообразно применять дедупликацию, как и компрессию.
Ну, с одной стороны, флэш-память будет дешеветь, до определённого предела. Мне казалось, что это будет происходить несколько быстрее, но уже доступны SSD-накопители ёмкостью 1 Тб за $550, это большой прогресс. Конечно, разработчики традиционных винчестеров тоже не сидят сложа руки. В районе 2017–2018 годов конкуренция должна усилиться, поскольку будут внедряться новые технологии (вероятнее всего, фазовый сдвиг и углеродные нанотрубки). Но дело вовсе не в противостоянии флэш и винчестеров, или даже программных и аппаратных решений, главное — архитектура.
Она настолько важна, что практически невозможно поменять архитектуру СХД, не переделав практически всё. То есть, по сути, не создав новую систему. Поэтому хранилища обычно создаются, развиваются и умирают в рамках какой-то одной изначально выбранной архитектуры.
Четыре типа систем хранения данныхТип 1. Кластеризованные архитектуры. Они не рассчитаны на совместное использование памяти нодами, по сути, все данные находятся в одном ноде. Одной из особенностей архитектуры является то, что иногда устройства «пересекаются» (trespass), даже если они «доступны из нескольких нодов». Другая особенность заключается в том, что вы можете выбрать машину, указать ей какие-то накопители и сказать «эта машина имеет доступ к данным на этих носителях». Синим на рисунке обозначены ЦПУ/память/система ввода-вывода, а зелёным — носители, на которых хранятся данные (флэш или магнитные накопители).Для данного типа архитектур характерен прямой и очень быстрый доступ к данным. Между машинами будут возникать небольшие задержки, поскольку для обеспечения высокой доступности применяется зеркалирование ввода-вывода и кэширование. Но в целом обеспечивается относительно прямой доступ по ветви кода. Программные хранилища достаточно просты и имеют малое время задержки, поэтому зачастую обладают богатым функционалом, службы данных легко добавляются. Неудивительно, что большинство стартапов начинают с подобных хранилищ.
Обратите внимание, что одной из разновидностей этого типа архитектур является PCIe-оборудование для не HA-серверов (карты расширения Fusion-IO, XtremeCache). Если добавить к нему ПО для распределённого хранилища, когерентность и HA-модель, то подобное программное хранилище будет соответствовать одному из четырёх типов архитектур, описываемых в этом посте.

Применение «федеративных моделей» помогает улучшить горизонтальную масштабируемость архитектур этого типа с точки зрения менеджмента. В данных моделях могут использоваться разные подходы к повышению мобильности данных для перебалансировки между управляющими машинами и хранилищами. Например, в рамках VNX это означает «мобильность VDM». Но я считаю, что называть это «горизонтально масштабируемой архитектурой» будет натяжкой. И, по моему опыту, большинство клиентов разделяют эту точку зрения. Причиной тому расположение данных на одной управляющей машине, иногда — «в аппаратном шкафе» (behind an enclosure). Их можно перемещать, но они всегда будут в каком-то одном месте. С одной стороны, это позволяет снизить количество циклов и задержку при записи. С другой стороны, все ваши данные обслуживаются единственной управляющей машиной (возможен непрямой доступ с другой машины). В отличие от второго и третьего типов архитектур, о которых поговорим ниже, здесь балансировка и настройка играют важную роль.
Объективно говоря, этот абстрактный федеративный уровень влечёт за собой и некоторое увеличение задержки, поскольку использует программное перенаправление. Это аналогично усложнению кода и увеличению задержки в типах архитектур 2 и 3, и отчасти нивелирует преимущества первого типа. В качестве конкретного примера можно привести UCS Invicta, этакий «Silicon Storage Routers». В случае с NetApp FAS 8.x, работающим в кластерном режиме, код изрядно усложнён внедрением федеративной модели.
Продукты, использующие кластерные архитектуры — VNX или NetApp FAS, Pure, Tintri, Nimble, Nexenta и (я думаю) UCS Invicta/UCS. Одни представляют собой «аппаратные» решения, другие — «чисто программные», третьи — «программные в виде аппаратных комплексов». Все они ОЧЕНЬ сильно различаются с точки зрения обработки данных (в Pure и UCS Invicta/Whiptail подразумевается использование только флэш-накопителей). Но архитектурно все перечисленные продукты родственны. Например, вы настраиваете службы обработки данных исключительно для резервного копирования, программный стек становится Data Domain, ваш NAS работает как лучший в мире инструмент для бэкапа — и это тоже архитектура «первого типа».

Тип 2. Слабо сопряжённые, горизонтально масштабированные архитектуры. Ноды не используют память совместно, но сами данные по нескольким нодам. Эта архитектура подразумевает использование большего количества межнодовых связей для записи данных, что увеличивает количество циклов. Хоть операции записи и распределены, но всегда когерентны.
Обратите внимание, что в этих архитектурах не обеспечивается высокая доступность нода в связи с операциями копирования и распределения данных. По той же причине здесь всегда больше операций ввода-вывода по сравнению с простыми кластерными архитектурами. Так что производительность получается несколько ниже, несмотря на небольшой уровень задержки при записи (NVRAM, SSD и т.д.).
В некоторых разновидностях архитектур часто нодов собираются в подгруппы, а остальные используются для управления подгруппами (ноды метаданных). Но здесь проявляются эффекты, описанные выше для «федеративных моделей».

Подобные архитектуры довольно просто масштабируются. Поскольку данные хранятся в нескольких местах и могут обрабатываться многочисленными нодами, эти архитектуры могут отлично подойти для задач, когда требуется распределённое чтение. Кроме того, они хорошо сочетаются с ПО для серверов/хранилищ. Но лучше всего применять подобные архитектуры в условиях транзакционных нагрузок: благодаря их распределённости вы можете не использовать HA-сервер, а слабая сопряжённость позволяет обойтись Ethernet.
Этот тип архитектур используется в таких продуктах, как EMC ScaleIO и Isilon, VSAN, Nutanix и Simplivity. Как в случае с Типом 1, все эти решения совершенно непохожи друг на друга.
Слабая сопряжённость означает, что зачастую эти архитектуры позволяют заметно увеличивать количество нодов. Но, напомню, они НЕ используют память совместно, код каждого нода работает независимо от других. Но дьявол, как говорится, в деталях:
Чем больше распределены операции записи, тем выше задержки и ниже эффективность IOP. Например, в Isilon уровень распределённости очень высок файлов, и хотя с каждым обновлением задержки уменьшаются, но всё же он никогда не продемонстрирует высочайшей производительности. Зато Isilon чрезвычайно силён с точки зрения распаралеллеливания.
Если уменьшить степень распределённости (пусть и при большом количестве нодов), то задержки могут снизиться, но при этом вы урежете свои возможности по распараллеливанию чтения данных. Например, во VSAN используется модель «виртуальная машина как объект», что позволяет запускать многочисленные копии. Казалось бы, виртуальная машина должна быть доступна определённому хосту. Но, по факту, во VSAN она «сдвигается» по направлению к ноду, который хранит её данные. Если вы используете это решение, то можете сами посмотреть, как увеличение количества копий объекта влияет на задержку и операции ввода-вывода в рамках всей системы. Подсказка: больше копий = выше нагрузка на систему в целом, причём зависимость нелинейная, как вы могли бы ожидать. Но для VSAN это не проблема благодаря преимуществам модели «виртуальная машина как объект».
Можно добиться низкой задержки в условиях высокого масштабирования и распараллеливания при чтении, но только при условии точного разделения данных и записи небольшого количества копий. Этот подход используется в ScaleIO. Каждый том разделён на большое количество фрагментов (по умолчанию по 1 Мб), которые распределены по всем задействованным нодам. В результате достигается чрезвычайно высокая скорость чтения и перераспределения наряду с мощным распараллеливанием. Задержка при записи может быть менее 1 мсек при использовании соответствующей сетевой инфраструктуры и SSD/PCIe Flash в нодах кластера. Однако каждая операция записи производится в двух нодах. Конечно, в отличие от VSAN здесь виртуальная машина не рассматривается как объект. Но если бы рассматривалась, то масштабируемость была бы хуже.

Тип 3. Сильно сопряжённые, горизонтально масштабированные архитектуры. Здесь применяется совместное использование памяти (для кэширования и некоторых типов метаданных). Данные распределены по различным нодам. Этот тип архитектур подразумевает использование очень большого количества межнодовых соединений для всех видов операций.
Совместное использование памяти является краеугольным камнем этих архитектур. Исторически сложилось, что через все управляющие машины могут осуществляться симметричные операции ввода-вывода (см. иллюстрацию). Это позволяет перебалансировать нагрузку в случае возникновения каких-либо сбоев. Данная идея закладывалась в основу таких продуктов, как Symmetrix, IBM DS, HDS USP и VSP. В них осуществляется совместны доступ к кэшу, поэтому процедура ввод-вывода можно управлять с любой машины.
Верхняя диаграмма на иллюстрации отражает архитектуру EMC XtremIO. На первый взгляд, она аналогична Типу 2, но это не так. В данном случае модель совместно используемых распределённых метаданных подразумевает использование IB и удалённого прямого доступа к памяти, чтобы все ноды имели доступ к метаданным. При этом каждый нод представляет собой HA-пару. Как видите, Isilon и XtremIO сильно различаются архитектурно, хотя это и не так очевидно. Да, у обоих горизонтально масштабированные архитектуры, в обоих для межкомпонентного соединения используется IB. Но в Isilon, в отличие от XtremIO, это делается для максимального снижения задержки при обмене данными между нодами. Также в Isilon для связи между нодами можно использовать Ethernet (фактически, именно так на нём работает виртуальная машина), но это увеличивает задержки при операциях ввода-вывода. Что касается XtremIO, то для его производительности большое значение имеет удалённый прямой доступ к памяти.
Кстати, пусть вас не вводит в заблуждение наличие двух диаграмм на иллюстрации — на самом деле, архитектурно они одинаковые. В обоих случаях используются пары HA-контроллеров, совместный доступ к памяти и межкомпонентные соединение с очень низким уровнем задержки. Кстати, в VMAX используется проприетарная межкомпонентная шина, но в будущем появится возможность применения IB.
Для сильно сопряжённых архитектур характерна высокая сложность программного кода. Это одна из причин их невысокой распространённости. Излишняя сложность ПО влияет и на количество добавляемых служб обработки данных, поскольку это представляет собой более трудную вычислительную задачу.
К преимуществам этого типа архитектур можно отнести устойчивость к сбоям (симметричные операции ввода-вывода во всех управляющих машинах), а также, в случае с XtremIO, большие возможности в сфере AFA. Раз речь снова зашла об XtremIO, то стоит упомянуть, что его архитектура подразумевает распределённость всех служб обработки данных. Также это единственное на рынке AFA-решение с горизонтально масштабированной архитектурой, хотя динамическое добавление/отключение нодов ещё не внедрено. Помимо прочего, в XtremIO используется «естественная» дедупликация, то есть она постоянно активна и «бесплатна» с точки зрения производительности. Правда, всё это повышает сложность обслуживания системы.
Важно понимать принципиальную разницу между Типом 2 и Типом 3. Чем более сопряжённая архитектура, тем лучше и более прогнозируемо она позволяет обеспечивать низкий уровень задержек. С другой стороны, в рамках подобной архитектуры сложнее добавлять ноды и масштабировать систему. Ведь когда вы используете совместный доступ к памяти, она представляет собой единую сильно сопряжённую распределённую систему. Сложность решений растёт, а вместе с этим и вероятность ошибок. Поэтому VMAX может иметь до 16 управляющих машин в 8 движках, а XtemIO — до 8 машин в 4 X-Brick (скоро увеличится до 16 машин в 8 блоках). Учетверение, или даже удвоение этих архитектур представляет собой невероятно трудную инженерную проблему. Для сравнения, VSAN может быть масштабирован до «размера кластеров vSphere» (сейчас 32 нода), Isilon может содержать более 100 нодов, а ScaleIO позволяет создать систему из более чем 1000 нодов. При этом всё это архитектуры второго типа.
Снова хочу подчеркнуть — архитектура не зависит от реализации. В вышеупомянутых продуктах используется и Ethernet, и IB. Одни представляют собой чисто программные решения, другие являются программно-аппаратными комплексами, но при этом их объединяют архитектурные схемы.
Несмотря на разнообразие межкомпонентных соединений, во всех приведённых примерах важнейшую роль играет использование распределённой записи. Это позволяет достичь транзакционности и атомарности, но при этом необходим тщательный контроль целостности данных. Также приходится решать проблему разрастания «области отказов». Эти два момента ограничивают максимально возможную степень масштабирования описанных типов архитектур.
Небольшая проверка того, насколько внимательно вы прочитали всё вышеизложенное: к какому типу относится Cisco UCS Invicta — 1 или 3? Физически выглядит как Тип 3, но ведь это набор USC-серверов серии С, соединённых по Ethernet, на которых работает программный стек Invicta (бывший Whiptail). Подсказываю: смотрите на архитектуру, а не конкретную реализацию :)
В случае с UCS Invicta данные хранятся в каждом ноде (UCS-сервер с флэш-накопителями на базе MLC). Единственный нод, не HA, представляющий собой отдельный сервер, может напрямую передавать номер логического устройства (LUN). Если вы решите добавить ещё ноды, возможно система масштабируется слабосопряжённо, как ScaleIO или VSAN. Всё это подводит нас к Типу 2.
Однако увеличение количества нодов, судя во всему, производится с помощью конфигурирования и миграции на «Invicta Scaling Appliance». При такой конфигурации у вас есть несколько «Silicon Storage Routers» (SSR) и адресное хранилище из нескольких аппаратных нодов. Доступ к данным осуществляется через единственный SSR-нод, но это можно сделать и через другой нод, работающий как HA-пара. Сами данные всегда находятся на единственном UCS-ноде серии С. Так какой же это тип архитектуры? Не важно, как выглядит решение физически, — это Тип 1. SSR представляет собой кластер (может быть больше 2). В конфигурации Scaling Appliance каждый UCS-сервер с MLC-накопителями выполняет функцию, аналогичную VNX или NetApp FAS — дисковое хранилище. Хоть и не подключён через SAS, но архитектура аналогичная.
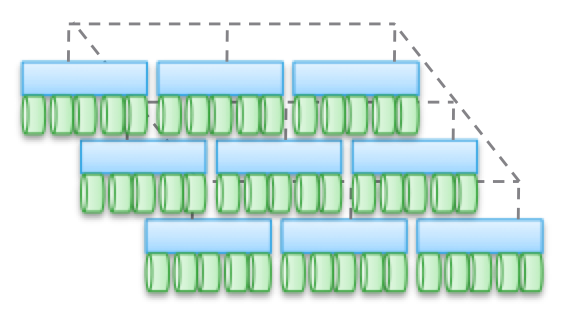
Тип 4. Распределённые архитектуры без совместно использования каких-либо ресурсов. Несмотря на то, что данные распределяются по разным нодам, делается это безо всякой транзакционности. Обычно данные складируются на каком-то одном ноде и там живут, и время от времени делаются копии на других нодах, ради обеспечения безопасности. Но эти копии не транзакционные. Это является ключевым отличием данного типа архитектур от Типа 2 и 3.
Связь между не-HA-нодами осуществляется с помощью Ethernet, поскольку это дёшево и универсально. Распределение по нодам делается принудительно и время от времени. «Корректность» данных соблюдается не всегда, но программный стек проверяется довольно часто, чтобы обеспечивать правильность используемых данных. При некоторых видах нагрузки (например, HDFS) данные распределяются так, чтобы находиться в памяти одновременно с тем процессом, для которого они требуются. Это свойство позволяет считать данный тип архитектур наиболее масштабируемым среди всех четырёх.
Но это далеко не единственное преимущество. Подобные архитектуры чрезвычайно просты, ими очень легко управлять. Они никоим образом не зависят от оборудования и могут быть развёрнуты на самом дешёвом «железе». Это почти всегда исключительно программные решения. Архитектурам этого типа оперировать петабайтами данных так же просто, как дргугим — терабайтами. Здесь применяются объекты и неPOSIX-файловые системы, причём и те, и другие зачастую располагаются поверх локальной файловой системы каждого рядового нода.
Эти архитектуры можно совмещать с блоками и транзакционными моделями представления данных на базе NAS, но это сильно ограничивает их возможности. Не надо создавать транзакционный стек, помещая Тип 1, 2 или 3 поверх Типа 4.
Лучше всего эти архитектуры «раскрываются» на тех задачах, для которых не свойственны какие-то ограничения.
Выше я приводил пример с очень большим клиентом, у которого 200 000 накопителей. В основе таких сервисов, как Dropbox, Syncplicity, iCloud, Facebook, eBay, YouTube и почти всех Web 2.0-проектов лежат хранилища, построенные по архитектурам четвёртого типа. Вся обрабатываемая информация в Hadoop-кластерах также содержится в хранилищах на базе Типа 4. В целом, в корпоративном сегменте это не очень распространённые архитектуры, но они очень быстро завоёвывают популярность.
Тип 4 лежит в основе таких продуктов, как AWS S3 (кстати, никто за пределами AWS не знает, как устроен EBS, но готов спорить, что это Тип 3), Haystack (используется в Facebook), Atmos, ViPR, Ceph, Swift (используется в Openstack), HDFS, Centera. Многие из перечисленных продуктов могут обретать разную форму, вид конкретной реализации определяется с помощью их API. Например, объектный стек ViPR можно реализовать через объектные API S3, Swift, Atmos, и даже HDFS! А в будущем в этот список попадёт и Centera. Для кого-то это будет очевидно, но Atmos и Centera будут использоваться ещё долго, правда, в виде API, а не конкретных продуктов. Реализации могут меняться, но API остаются чем-то незыблемым, что очень хорошо для клиентов.
Хочу ещё раз обратить ваше внимание на то, что «физическое воплощение» может сбить вас с толку, и архитектуры Типа 4 вы ошибочно отнесёте к Типу 2, поскольку они, зачастую, выглядят одинаково. На физическом уровне какое-от решение может выглядеть как ScaleIO, VSAN или Nutanix, хотя это будут просто серверы с Ethernet. И правильно классифицировать то или иное решение поможет наличие или отсутствие транзакционности.
А теперь я предлагаю вам второй проверочный тест. Давайте рассмотрим архитектуру UCS Invicta. Физически этот продукт выглядит как Тип 4 (серверы, соединённые по Ethernet), но архитектурно его невозможно масштабировать под соответствующие нагрузки, поскольку на самом деле это Тип 1. Причём Invicta, как и Pure, разрабатывался для AFA.
Примите мою искреннюю благодарность за уделённое время и внимание, если вы дочитали до этого места. Перечитал написанное выше — удивительно, что мне удалось жениться и завести детей :)
Для чего я всё это расписал? В мире IT хранилища занимают очень важное место, этакое «царство грибов». Разнообразие предлагаемых продуктов очень велико, и это идёт только на пользу всему делу. Но нужно уметь разбираться во всём этом, не позволять затуманить себе разум маркетинговыми слоганами и нюансами позиционирования. Ради блага как клиентов, так и самой индустрии, необходимо упростить процесс построения хранилищ. Поэтому мы прилагаем столько усилий, чтобы сделать из контроллера ViPR открытую бесплатную платформу.Но сами по себе хранилища трудно назвать захватывающими. Что я имею в виду? Представим некую абстрактную пирамиду, на вершине которой находится «пользователь». Ниже расположены «приложения», предназначенные для обслуживания «пользователя». Ещё ниже — «инфраструктура» (включая SDDC), обслуживающая «приложения» и, соответственно, «пользователя». А в самом низу «инфраструктуры» находится хранилище.
То есть можно представить иерархию в таком виде: Пользователь→Приложение/SaaS→PaaS→IaaS→Инфраструктура. Так вот: в конце концов, любое приложение, любой PaaS-стек должны вычислять или обрабатывать какую-то информацию. И эти четыре типа архитектур предназначены для работы с разными типами информации, разными видами нагрузки. В иерархии важности информация следует сразу за пользователем. Цель существования приложения заключается в том, чтобы дать пользователю возможность взаимодействовать с нужной ему информацией. Именно поэтому архитектуры систем хранения данных имеют столь важное значение в нашем мире.
