[Перевод] Новое в Hadoop: познакомимся с различными форматами файлов в Hadoop
Всем привет! Публикуем перевод статьи, подготовленный для студентов новой группы курса «Data Engineer». Если интересно узнать, как построить эффективную и масштабируемую систему обработки данных с минимальными затратами, посмотрите запись мастер-класса Егора Матешука!

Несколько недель назад я написал о Hadoop статью, где осветил различные его
части и разобрался в том, какую роль он играет в области data engineering. В этой статье я
дам краткое описание различных файловых форматов в Hadoop. Это быстрая и легкая
тема. Если вы пытаетесь понять, как работает Hadoop и какое место он занимает в работе
Data Engineer, ознакомьтесь с моей статье о Hadoop здесь.
Форматы файлов в Hadoop делятся на две категории: row-oriented и column-
oriented.
Row-oriented:
Строки (row) данных одного типа хранятся вместе, образуя непрерывное
хранилище: SequenceFile, MapFile, Avro Datafile. Таким образом, если необходимо
получать доступ только к небольшому количеству данных из строки, все равно вся строка
будет считана в память. Задержка сериализации может до определенной степени
облегчить проблему, но полностью от накладных расходов чтения всей строки данных с
диска избавиться не удастся. Хранилище, ориентированное на строки (row-oriented)
походит в тех случаях, когда необходимо одновременно обрабатывать всю строку
данных.
Column-oriented:
Весь файл разрезается на несколько столбцов данных и все столбцы данных
хранятся вместе: Parquet, RCFile, ORCFile. Формат, ориентированный на столбцы (column-
oriented), позволяет пропускать ненужные столбцы при чтении данных, что подходит для
ситуации, когда необходим небольшой объем строк. Но такой формат чтения и записи
требует больше места в памяти, поскольку вся строка кэша должна находиться в памяти
(чтобы получить столбец из нескольких строк). В то же время он не подходит для
потоковой записи, потому что после сбоя записи текущий файл не сможет быть
восстановлен, а линейно-ориентированные данные могут быть повторно
синхронизированы с последней точки синхронизации в случае ошибки записи, поэтому,
например, Flume использует линейно-ориентированный (line-oriented) формат хранения.

Рисунок 1 (слева). Показана логическая таблица
Рисунок 2 (справа). Row-oriented расположение (Sequence-файл)

Рисунок 3. Column-oriented расположение
Если вы еще не до конца поняли, что такое ориентация на столбцы или на строки,
не переживайте. Вы можете перейти по этой ссылке, чтобы понять разницу между ними.
Вот несколько форматов файлов, которые широко используются в системе Hadoop:
Формат хранения меняется в зависимости от того, является ли хранилище сжатым,
использует ли оно сжатие записи или сжатие блока:

Рисунок 4. Внутренняя структура sequence-файла без сжатия и со сжатием записей.
Без сжатия:
Хранение в порядке, соответствующем длине записи, длине Key, степени Value,
значению Key и значению Value. Диапазон — это количество байтов. Сериализация
выполняется с использованием указанной.
Сжатие записи:
Сжимается только значение, а сжатый кодек хранится в заголовке.
Сжатие блока:
Происходит сжатие нескольких записей, чтобы можно было воспользоваться
преимуществами сходства между двумя записями и сэкономить место. Флаги
синхронизации добавляются в начало и в конец блока. Минимальное значение блока
задается атрибутом o.seqfile.compress.blocksizeset.

Рисунок 4. Внутренняя структура sequence-файла со сжатием блоков.
Map-файл — это разновидность sequence-файла. После добавления индекса к
sequence-файлу и его сортировки получается map-файл. Индекс хранится как отдельный
файл, в котором обычно лежат индексы каждой из 128 записей. Индексы могут быть
загружены в память для быстрого поиска, поскольку файлы, в которых хранятся данные,
расположены в порядке, определенном ключом.
Записи map-файла должны быть расположены по порядку. В противном случае мы
получаем IOException.
Производные типы map-файла:
- SetFile: специальный map-файл для хранений последовательности ключей типа
Writable. Ключи записываются в определенном порядке. - ArrayFile: ключ — это целое число, означающее позицию в массиве, значение
типа Writable. - BloomMapFile: оптимизирован для метода get () map-файла с использованием
динамических фильтров Bloom. Фильтр хранится в памяти, и обычный метод
get () вызывается для выполнения чтения, только если значение ключа
существует.
Файлы, перечисленные ниже в системе Hadoop включают RCFile, ORCFile и Parquet.
Column-oriented версия Avro — это Trevni.
Hive«s Record Columnar File — этот тип файла сначала делит данные на группы строк,
а внутри группы строк, данные хранятся в столбцах. Его структура выглядит следующим
образом:

Рисунок 5. Расположение данных RC-файла в HDFS-блоке.
Сравним с чистыми row-oriented и column-oriented:
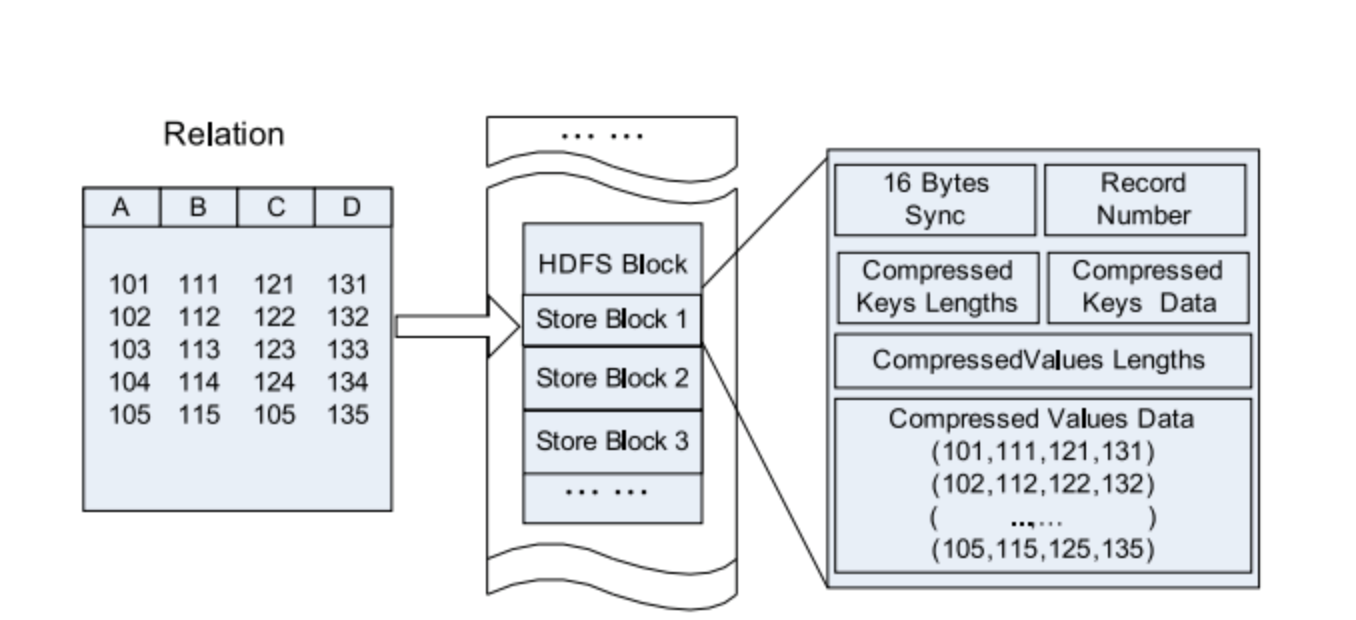
Рисунок 6. Хранение по строкам в HDFS-блоке.
Рисунок 7. Группировка по столбцам в HDFS-блок.
ORCFile (Optimized Record Columnar File) — является более эффективным форматом
файла, чем RCFile. Он внутренне делит данные на полосы (stripe) размером 250М каждая.
Каждая полоса имеет индекс, данные и Footer. Индекс хранит минимальное и
максимальное значение каждого столбца, а также положение каждой строки в столбце.

Рисунок 8. Расположение данных в ORC-файле
В Hive для использования ORC-файла используются следующие команды:
Универсальный column-oriented формат хранилища, основанный на Google Dremel.
Особенно хорош при обработке данных с высокой степенью вложенности.
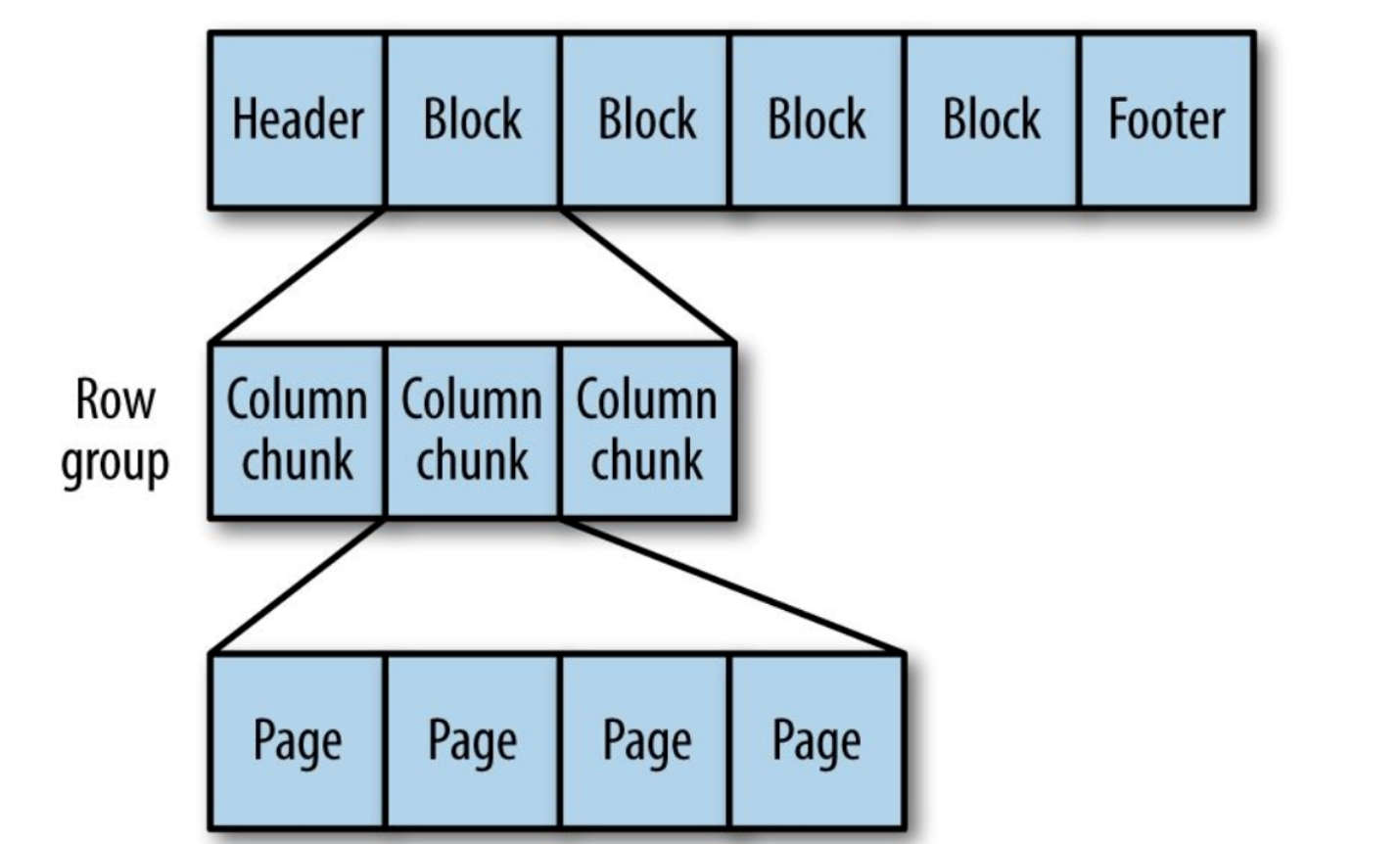
Рисунок 9. Внутренняя структура Parquet-файла.
Вложенные структуры Parquet преобразует в хранилище плоских столбцов,
которое представлено Repeat-уровнем и Definition-уровнем (R и D) и использует
метаданные для восстановления записи при чтении данных, чтобы восстановить весь
файл. Дальше вы увидите пример R и D:
AddressBook {
contacts: {
phoneNumber: "555 987 6543”
}
contacts: {
}
}
AddressBook {
}
Вот и все. Теперь вы знаете о различиях форматов файлов в Hadoop. Если
обнаружите какие-либо ошибки или неточности, пожалуйста, не стесняйтесь обращаться
ко мне. Вы можете связаться со мной в LinkedIn.
