[Перевод] NL2API: создание естественно-языковых интерфейсов для Web API
Привет, Хабр! Совсем недавно мы кратко рассказывали о Natural Language Interfaces (Естественно-Языковых Интерфейсах). Ну, а сегодня у нас не кратко. Под катом вы найдете полноценный рассказ о создании NL2API для Web-API. Наши коллеги из подразделения Research опробовали уникальный подход к сбору обучающих данных для фреймворка. Присоединяйтесь!

Аннотация
По мере того как Интернет развивается в направлении сервис-ориентированной архитектуры, программные интерфейсы (API) приобретают все более высокую важность как способ предоставления доступа к данным, службам и устройствам. Мы работаем над проблемой создания естественно-языкового интерфейса для API (NL2API), уделяя основное внимание веб-службам. Решения NL2API имеют множество потенциальных преимуществ, например, помогают упростить интеграцию веб-служб в виртуальных помощников.
Мы предлагаем первую комплексную платформу (фреймворк), позволяющую создать NL2API для конкретного веб-API. Ключевой задачей является сбор данных для обучения, то есть пар «команда NL — вызов API», позволяющих NL2API изучить семантику как команд NL, не имеющих строго определенного формата, так и формализованных вызовов API. Мы предлагаем собственный уникальный подход к сбору обучающих данных для NL2API с помощью краудсорсинга — привлечения многочисленных удаленных работников к генерации различных команд NL. Сам процесс краудсорсинга мы оптимизируем с целью сокращения затрат.
В частности, мы предлагаем принципиально новую иерархическую вероятностную модель, которая поможет нам распределить бюджет для краудсорсинга, в основном, между теми вызовами API, которые имеют высокую ценность для обучения NL2API. Мы применяем наш фреймворк к реальным API и показываем, что он позволяет собирать качественные обучающие данные с минимальными затратами, а также создавать высокопроизводительные NL2API с нуля. Мы также демонстрируем, что наша модель краудсорсинга повышает эффективность этого процесса, то есть обучающие данные, собранные в ее рамках, обеспечивают более высокую производительность NL2API, значительно превосходящую базовые показатели.
Введение
Программные интерфейсы приложения (API) играют все более важную роль и в виртуальном, и в физическом мире благодаря развитию таких технологий, как сервис-ориентированная архитектура (SOA), облачные вычисления и Интернет вещей (IoT). Например, размещенные в облаке веб-службы (погода, спорт, финансы и др.) через веб-API предоставляют данные и услуги конечным пользователям, а устройства IoT дают возможность другим сетевым устройствам использовать свою функциональность.

Рисунок 1. Пары «NL-команда (слева) и вызов API (справа)», собранные
нашим фреймворком, и сравнение с IFTTT. GET-Messages и GET-Events — два веб-API для поиска электронных писем и событий календаря соответственно. API можно вызывать с различными параметрами. Мы концентрируемся на полностью параметризованных вызовах API, в то время как IFTTT ограничивается API с простыми параметрами.
Обычно API используются в различном программном обеспечении: в приложениях для рабочего стола, веб-сайтах и мобильных приложениях. Также они обслуживают пользователей с помощью графического пользовательского интерфейса (GUI). GUI внес большой вклад в популяризацию компьютеров, но, по мере развития вычислительной техники, все чаще проявляются его многочисленные ограничения. С одной стороны, поскольку устройства становятся все меньше размером, мобильнее и умнее, требования к графическому изображению на экране постоянно повышаются, например, в отношении переносных устройств или устройств, подключенных к IoT.
С другой стороны, пользователям приходится адаптироваться к различным специализированным GUI для различных служб и устройств. По мере увеличения числа доступных сервисов и устройств расходы на обучение и адаптацию пользователей также растут. Естественно-языковые интерфейсы (NLI), например, виртуальные помощники Apple Siri и Microsoft Cortana, которые также называют разговорными или диалоговыми интерфейсами (CUI), демонстрируют значительный потенциал в качестве единого интеллектуального инструмента для широкого спектра серверных служб и устройств.
В этой работе рассматривается проблема создания естественно-языкового интерфейса для API (NL2API). Но, в отличие от виртуальных помощников, это не NLI общего назначения,
мы разрабатываем подходы к созданию NLI для конкретных веб-API, то есть API веб-служб, подобных мультиспортивному сервису ESPN1. Такие NL2APIs могут решить проблему масштабируемости NLI общего назначения, предоставив возможность распределенной разработки. Полезность виртуального помощника во многом зависит от широты его возможностей, то есть от количества поддерживаемых им сервисов.
Однако интегрировать веб-сервисы в виртуального помощника по одному — невероятно кропотливая работа. Если бы у индивидуальных провайдеров веб-сервисов был недорогой способ создания NLI для своих API, то затраты на интеграцию удалось бы значительно сократить. А виртуальному помощнику не пришлось бы обрабатывать разные интерфейсы для разных веб-сервисов. Ему достаточно было бы просто интегрировать отдельные NL2API, которые достигают единообразия благодаря естественному языку. С другой стороны, NL2API также могут упростить обнаружение веб-служб и программирование систем рекомендаций и помощи для API, что избавит от необходимости запоминать большое количество доступных веб-API и их синтаксис.
Пример 1. Два примера показаны на рисунке 1. API можно вызывать с различными параметрами. В случае с API поиска электронных писем пользователи могут фильтровать электронную почту по определенным свойствам или искать письма по ключевым словам. Главная задача NL2API заключается в сопоставлении NL-команд с соответствующими вызовами API.
Задача. Сбор обучающих данных — одна из наиболее важных задач, связанных с исследованиями в области разработки интерфейсов NLI и их практического применения. Интерфейсы NLI используют контролируемые обучающие данные, которые в случае NL2API состоят из пар «команда NL — вызов API», чтобы изучить семантику и однозначно сопоставить NL-команды с соответствующими формализованными представлениями. Естественный язык очень гибкий, поэтому пользователи могут описывать вызов API синтаксически различными способами, то есть имеет место парафразирование.
Рассмотрим второй пример на рисунке 1. Пользователи могут перефразировать этот вопрос следующим образом: «Где пройдет следующая встреча» или «Найди место проведения следующей встречи». Поэтому крайне важно собрать достаточные обучающие данные, чтобы система в дальнейшем распознавала подобные варианты. Существующие NLI обычно придерживаются принципа «лучшее из возможного» в процессе сбора данных. Например, наиболее близкий аналог нашей методологии для сопоставления NL-команд с вызовами API использует концепцию IF-This-Then-That (IFTTT) — «если это, тогда то» (рисунок 1). Обучающие данные поступают напрямую с сайта IFTTT.
Однако если API не поддерживается или поддерживается не полностью, никакого способа исправить ситуацию нет. Кроме того, обучающие данные, собранные таким образом, малоприменимы для поддержки расширенных команд с несколькими параметрами. Например, мы проанализировали анонимизированные журналы вызовов API Microsoft для поиска электронных писем за месяц и обнаружили, что около 90% из них используют два или три параметра (примерно в одинаковых количествах), и эти параметры довольно разнообразны. Поэтому мы стремимся обеспечить полную поддержку параметризации API и реализовать расширенные NL-команды. Проблема развертывания активного и настраиваемого процесса сбора обучающих данных для конкретного API в настоящее время остается нерешенной.
Вопросы применения NLI в сочетании с другими формализованными представлениями, такими как реляционные базы данных, базы знаний и веб-таблицы, проработаны достаточно хорошо, при этом разработке NLI для веб-API внимание практически не уделялось. Мы предлагаем первую комплексную платформу (фреймворк), позволяющую создать NL2API для конкретного веб-API с нуля. В реализации для веб-API наш фреймворк включает три этапа: (1) Представление. Исходный HTTP-формат веб-API содержит множество избыточных и, значит, отвлекающих деталей с точки зрения интерфейса NLI.
Мы предлагаем использовать промежуточное семантическое представление для веб-API, чтобы не перегружать NLI лишней информацией. (2) Набор обучающих данных. Мы предлагаем новый подход к получению контролируемых обучающих данных на основе краудсорсинга. (3) NL2API. Мы также предлагаем две модели NL2API: модель извлечения на основе языковой модели и модель рекуррентной нейронной сети (Seq2Seq).
Одним из ключевых технических результатов этой работы является принципиально новый подход к активному сбору обучающих данных для NL2API на основе краудсорсинга — мы привлекаем удаленных исполнителей для аннотирования вызовов API при их сопоставлении с NL-командами. Это позволяет достичь трех целей проектирования, обеспечив: (1) Настраиваемость. Необходимо обеспечить возможность указать, какие параметры для какого API использовать и какой объем обучающих данных собрать. (2) Низкие затраты. Услуги краудсорсинговых работников стоят на порядок дешевле услуг профильных специалистов, поэтому именно их и нужно нанимать. (3) Высокое качество. Качество обучающих данных не должно снижаться.
При проектировании такого подхода возникают две основные проблемы. Во-первых, вызовы API с расширенной параметризацией, как на рисунке 1, непонятны для среднего пользователя, поэтому нужно решить, как сформулировать задачу аннотирования таким образом, чтобы краудсорсинговые работники могли с легкостью справиться с ней. Мы начинаем с разработки промежуточного семантического представления для веб-API (см. раздел 2.2), которое позволяет нам беспрепятственно генерировать вызовы API с требуемыми параметрами.
Затем мы продумываем грамматику для автоматического преобразования каждого вызова API в каноническую NL-команду, которая может оказаться довольно громоздкой, но зато будет понятна среднему краудсорсинговому работнику (см. раздел 3.1). Исполнителям останется только перефразировать каноническую команду, чтобы она звучала более естественно. Такой подход позволяет предотвратить многие ошибки при сборе обучающих данных, поскольку задача перефразирования намного проще и понятнее для среднего краудсорсингового работника.
Во-вторых, необходимо понять, как определять и аннотировать только те вызовы API, которые представляют реальную ценность для обучения NL2API. Возникающий при параметризации «комбинаторный взрыв» приводит к тому, что количество вызовов даже для одного API может быть довольно большим. Аннотировать все вызовы не имеет смысла. Мы предлагаем принципиально новую иерархическую вероятностную модель для реализации процесса краудсорсинга (см. раздел 3.2). По аналогии с языковым моделированием с целью получения информации, мы предполагаем, что NL-команды генерируются на основе соответствующих вызовов API, поэтому языковую модель следует использовать для каждого вызова API, чтобы зарегистрировать этот «порождающий» процесс.
Наша модель базируется на композиционной природе вызовов API или формализованных представлений смысловой структуры в целом. На интуитивном уровне, если вызов API состоит из более простых вызовов (например, «непрочитанные электронные письма о заявке на получение степени кандидата наук» = «непрочитанные электронные письма» + «электронные письма о заявке на получение степени кандидата наук», мы можем построить его языковую модель из простых вызовов API даже без аннотирования. Поэтому, аннотируя небольшое количество вызовов API, мы можем рассчитать языковую модель для всех остальных.
Конечно, рассчитанные языковые модели далеки от идеала, иначе мы бы уже решили проблему создания NL2API. Тем не менее такая экстраполяция языковой модели на неаннотированные вызовы API дает нам целостное представление о всем пространстве вызовов API, а также о взаимодействии естественного языка и вызовов API, что позволяет оптимизировать процесс краудсорсинга. В разделе 3.3 мы описываем алгоритм выборочного аннотирования вызовов API, помогающий сделать вызовы API более различимыми, то есть обеспечить максимальное расхождение их языковых моделей.
Мы применяем наш фреймворк к двум развернутым API из пакета Microsoft Graph API2. Мы демонстрируем, что высококачественные обучающие данные можно собирать с минимальными затратами при условии использования предложенного подхода3. Мы также показываем, что наш подход повышает эффективность краудсорсинга. При аналогичных затратах мы собираем более качественные обучающие данные, значительно превосходя базовые показатели. Как следствие, наши решения NL2API обеспечивают более высокую точность.
В целом, наш основной вклад включает три аспекта:
- Мы одними из первых начали изучать проблематику NL2API и предложили комплексный фреймворк для создания NL2API с нуля.
- Мы предложили уникальный подход к сбору обучающих данных с помощью краудсорсинга и принципиально новую иерархическую вероятностную модель для оптимизации этого процесса.
- Мы применили наш фреймворк к реальным веб-API и продемонстрировали, что достаточно эффективное решение NL2API может быть создано с нуля.
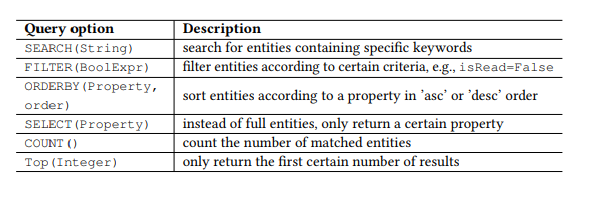
Таблица 1. Параметры запроса OData.
Преамбула
RESTful API
В последнее время веб-API, отвечающие архитектурному стилю REST, то есть RESTful API, становятся все более популярными благодаря своей простоте. Интерфейсы RESTful API также применяются в смартфонах и IoT-устройствах. Restful API работают с ресурсами, адресуемыми через URI, и предоставляют доступ к этим ресурсам для широкого круга клиентов с помощью простых команд HTTP: GET, PUT, POST и др. Мы, в основном, будем работать с RESTful API, но базовые методы можно применять и к другим интерфейсам API.
Для примера возьмем популярный протокол открытых данных (OData) для RESTful API и два веб-API из пакета Microsoft Graph API (рисунок 1), которые, соответственно, используются для поиска электронных писем и событий календаря пользователя. Ресурсы в OData представляют собой сущности, каждая из которых связана со списком свойств. Например, сущность Message — электронное письмо — обладает такими свойствами, как subject (тема), from (от), isRead (прочитано), receivedDateTime (дата и время получения) и т. д.
Кроме того, OData определяет набор параметров запроса, позволяя выполнять расширенные манипуляции над ресурсами. Например, параметр FILTER (ФИЛЬТР) позволяет искать электронные письма от конкретного отправителя или письма, полученные на конкретную дату. Параметры запроса, которые будем использовать мы, представлены в таблице 1. Мы вызываем каждую комбинацию команды HTTP и сущности (или набор сущностей) как API, например, GET-Messages — для поиска электронных писем. Любой параметризованный запрос, например, FILTER (isRead=False), называется параметром, а вызов API — это API со списком параметров.
NL2API
Основная задача NLI заключается в сопоставлении высказывания (команды на естественном языке) с определенным формализованным представлением, например, логических форм или запросов SPARQL для баз знаний или веб-API в нашем случае. Когда необходимо сосредоточиться на семантическом отображении, не отвлекаясь на несущественные детали, обычно используется промежуточное семантическое представление, чтобы не работать непосредственно с целевым. Например, комбинаторная категориальная грамматика широко применяется при создании интерфейсов NLI для баз данных и баз знаний. Подобный подход к абстракции также очень важен для NL2API. Множество деталей, включая соглашения URL, заголовки HTTP и коды ответов, могут «отвлекать» NL2API от решения главной задачи — семантического отображения.
Поэтому мы создаем промежуточное представление для интерфейсов RESTful API (рисунок 2) с именем API frame, это представление отражает семантику кадра. Кадр API состоит из пяти частей. HTTP Verb (Команда HTTP) и Resource (Ресурс) — базовые элементы для RESTful API. Return Type (Возвращаемый тип) позволяет создавать составные API, то есть объединять несколько вызовов API для выполнения более сложной операции. Required Parameters (Обязательные параметры) чаще всего используется в вызовах PUT или POST в API, например, для отправки электронной почты обязательными параметрами являются адресат, заголовок и тело письма. Optional Parameters (Дополнительные параметры) часто присутствуют в вызовах GET в API, они помогают сузить информационный запрос.
Если обязательные параметры отсутствуют, мы выполняем сериализацию кадра API, например: GET-messages{FILTER (isRead=False), SEARCH («PhD application»), COUNT ()}. Кадр API может быть детерминирован и преобразован в реальный вызов API. В процессе преобразования будут добавлены необходимые контекстные данные, включая идентификатор пользователя, местоположение, дату и время. Во втором примере (рисунок 1) значение now в параметре FILTER будет заменено на дату и время выполнения соответствующей команды в ходе преобразования кадра API в реальный вызов API. Далее понятия кадра API и вызова API мы будем использовать как взаимозаменяемые.

Рисунок 2. Кадр API. Сверху: команда на естественном языке. Посередине: Кадр API. Снизу: Вызов API.
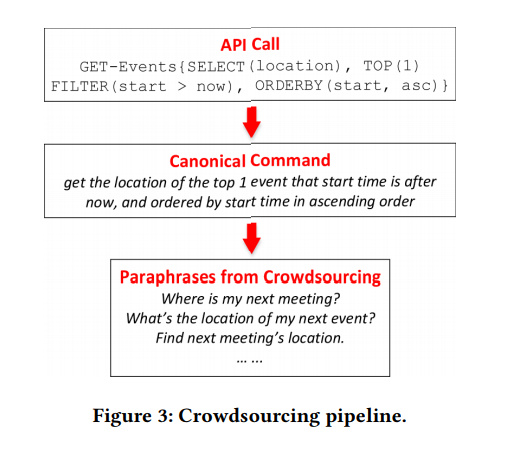
Рисунок 3. Конвейер краудсорсинга.
Сбор обучающих данных
В этом разделе описан предлагаемый нами принципиально новый подход к сбору обучающих данных для решений NL2API с помощью краудсорсинга. Сначала мы генерируем вызовы API и преобразуем каждый из них в каноническую команду, опираясь на простую грамматику (раздел 3.1), а затем привлекаем краудсорсинговых работников для перефразирования канонических команд (рисунок 3). Учитывая композиционный характер вызовов API, мы предложили иерархическую вероятностную модель краудсорсинга (раздел 3.2), а также алгоритм оптимизации краудсорсинга (раздел 3.3).
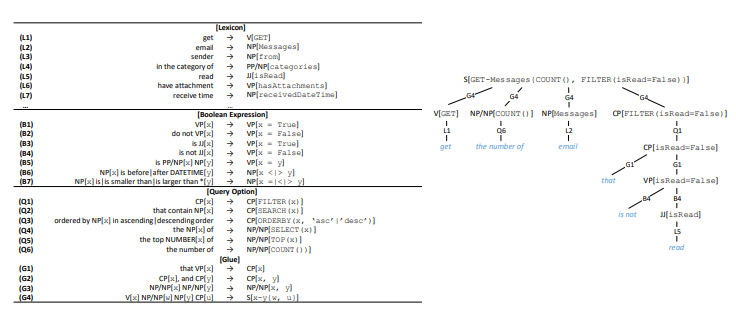
Рисунок 4. Генерация канонической команды. Слева: лексикон и грамматика. Справа: пример деривации.
Вызов API и каноническая команда
Мы генерируем вызовы API исключительно на основе спецификации API. Помимо элементов схемы, таких как параметры запроса и свойства сущности, нам необходимы значения свойств для генерации вызовов API, которые спецификацией API не предусмотрены. Для свойств со значениями перечислимого типа, например Boolean, мы перечисляем возможные значения (True/False).
Для свойств со значениями неограниченного типа, например Datetime, мы синтезируем несколько репрезентативных значений, например today или this_week для receivedDateTime. Необходимо понимать, что это абстрактные значения на уровне кадра API и они будут преобразованы в реальные в соответствии с контекстом (например, реальную дату и время) при преобразовании кадра API в реальный вызов API.
Перечислить все комбинации параметров запроса, свойств и значений свойств для создания вызовов API несложно. Простая эвристика позволяет отсеять не совсем подходящие комбинации. Например, к сортированному списку применяется TOP, поэтому использовать этот параметр необходимо в сочетании с ORDERBY. Кроме того, свойства типа Boolean, например isRead, в ORDERBY использоваться не могут. Тем не менее «комбинаторный взрыв» в любом случае обусловливает наличие большого количества вызовов API для каждого API.
Среднему пользователю сложно понять вызовы API. По аналогии с мы преобразуем вызов API в каноническую команду. Мы формируем специфический для API лексикон и общую для API грамматику (рисунок 4). Лексикон позволяет получить лексическую форму и синтаксическую категорию для каждого элемента (команды HTTP, сущности, свойства и значения свойств). Например, лексическая запись ⟨sender → NP[from]⟩ показывает, что лексической формой свойства from является «sender», а синтаксической категорией — именное словосочетание (NP), которое будет использоваться в грамматике.
Синтаксические категории также могут быть глаголами (V), глагольными словосочетаниями (VP), прилагательными (JJ), словосочетаниями-номинализаторами (CP), обобщенными именными словосочетаниями, за которыми следуют другие именные словосочетания (NP/NP), обобщенными предложными словосочетаниями (PP/NP), предложениями (S) и т. д.
Необходимо отметить, что хотя лексикон специфичен для каждого API и должен быть предоставлен администратором, грамматика разработана как общая и поэтому может тиражироваться на любой RESTful API на основе протокола OData — «как есть» или после незначительных модификаций. 17 грамматических правил на рисунке 4 позволяют охватить все вызовы API, используемые в следующих экспериментах (раздел 5).
Грамматика дает понять, как шаг за шагом получить каноническую команду из вызова API. Это набор правил вида ⟨t1, t2, …, tn → c[z]⟩, где 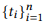 представляет собой последовательность токенов, z является частью вызова API, а c z — его синтаксической категорией. Обсудим пример на рисунке 4. К вызову API в корне дерева деривации, который имеет синтаксическую категорию S, мы сначала применяем правило G4, чтобы разбить исходный вызов API на четыре части. C учетом их синтаксической категории, первые три можно непосредственно преобразовать во фразы на естественном языке, в то время как последняя использует другое поддерево деривации и поэтому будет преобразована в словосочетание-номинализатор «that is not read».
представляет собой последовательность токенов, z является частью вызова API, а c z — его синтаксической категорией. Обсудим пример на рисунке 4. К вызову API в корне дерева деривации, который имеет синтаксическую категорию S, мы сначала применяем правило G4, чтобы разбить исходный вызов API на четыре части. C учетом их синтаксической категории, первые три можно непосредственно преобразовать во фразы на естественном языке, в то время как последняя использует другое поддерево деривации и поэтому будет преобразована в словосочетание-номинализатор «that is not read».
Следует отметить, что синтаксические категории допускают условную деривацию. Например, к VP[x = False] может применяться и правило B2, и правило B4, поэтому принять решение помогает синтаксическая категория x. Если x относится к синтаксической категории VP, выполняется правило B2 (например, x is hasAttachments → «do not have attachment»);, а если это JJ, то выполняется правило B4 (например, x is isRead → «is not read»). Это позволяет избегать громоздких канонических команд («do not read» or «is not have attachment») и делает сгенерированные канонические команды более естественными.
Семантическая сеть
Мы можем генерировать большое количество вызовов API, используя вышеуказанный подход, но аннотировать их все с помощью краудсорсинга нецелесообразно с экономической точки зрения. Поэтому мы предлагаем иерархическую вероятностную модель для организации краудсорсинга, которая помогает решить, какие вызовы API следует аннотировать. Насколько нам известно, это первая вероятностная модель применения краудсорсинга для создания интерфейсов NLI, позволяющая решить уникальную и интригующую задачу моделирования взаимодействия между представлениями на естественном языке и формализованными представлениями смысловой структуры. Формализованные представления смысловой структуры в целом и вызовы API в частности имеют композиционную природу. Например, z12 = GET-Messages {COUNT (), FILTER (isRead=False)} состоит из z1 = GET- Messages{FILTER (isRead=False)} и z2 = GET-Messages{COUNT ()} (эти примеры мы подробнее обсуждаем далее).
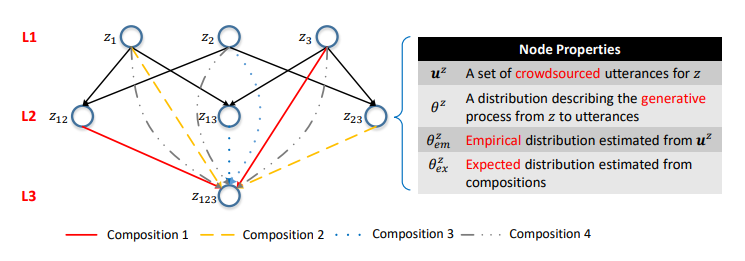
Рисунок 5. Семантическая сеть. i-й слой состоит из вызовов API с i параметрами. Ребра — это композиции. Распределения вероятностей на вершинах характеризуют соответствующие языковые модели.
Одним из ключевых результатов нашего исследования стало подтверждение того, что подобную композиционность можно использовать для моделирования процесса краудсорсинга.
Для начала мы определяем композицию на основе набора параметров вызовов API.
Определение 3.1 (композиция). Возьмем API и набор вызовов API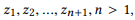 , если мы определим r (z) как набор параметров для z, то
, если мы определим r (z) как набор параметров для z, то 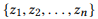 является композицией
является композицией 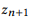 тогда и только тогда, когда
тогда и только тогда, когда 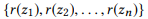 является частью
является частью 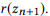
Опираясь на композиционные взаимосвязи вызовов API, можно организовать все вызовы API в единую иерархическую структуру. Вызовы API с одинаковым количеством параметров представлены как вершины одного слоя, а композиции представлены как
направленные ребра между слоями. Эту структуру мы называем сематической сетью (или SeMesh).
По аналогии с подходом на основе языкового моделирования в информационном поиске, мы предполагаем, что высказывания, соответствующие одному вызову API z, генерируются с помощью стохастического процесса, характеризуемого языковой моделью 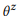 . В целях упрощения мы сосредоточимся на вероятностях слов, таким образом
. В целях упрощения мы сосредоточимся на вероятностях слов, таким образом  , где
, где 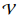 обозначает словарь.
обозначает словарь.
В силу причин, которые станут очевидны немного позже, вместо стандартной языковой униграм-модели мы предлагаем использовать набор распределений Бернулли (Bag of Bernoulli, BoB). Каждое распределение Бернулли соответствует случайной величине W, определяющей, появляется ли слово w в высказывании, сгенерированном на основе z, а распределение BoB — это набор распределений Бернулли для всех слов  . Мы будем использовать
. Мы будем использовать 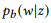 как краткое обозначение для
как краткое обозначение для 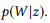 .
.
Предположим, мы сформировали (мульти)набор высказываний  для z,
для z,
оценка максимального правдоподобия (MLE) для распределения BoB позволяет отобрать высказывания, содержащие w:

Пример 2. Относительно упомянутого выше вызова API z1 предположим, что мы получили два высказывания u1 = «find unread emails» и u2 =«emails that are not read», то u = {u1, u2 }. pb («emails»|z) = 1.0, поскольку «emails» присутствует в обоих высказываниях. Аналогичным образом, pb («unread»|z) = 0.5 и pb («meeting»|z) = 0.0.
В семантической сети существует три основных операции на уровне вершин:
аннотирование, компоновка и интерполяция.
ANNOTATE (аннотировать) значит собирать высказывания для перефразирования канонической команды вершины z с помощью краудсорсинга и оценивать эмпирическое распределение 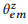 методом максимального правдоподобия.
методом максимального правдоподобия.
COMPOSE (компоновать) пытается вывести языковую модель на основе композиций вычислить ожидаемое распределение 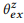 . Как мы покажем экспериментально, — это композиция для z. Если мы исходим из предположения о том, что соответствующие высказывания характеризуются этой же композиционной связью, то должно раскладываться на
. Как мы покажем экспериментально, — это композиция для z. Если мы исходим из предположения о том, что соответствующие высказывания характеризуются этой же композиционной связью, то должно раскладываться на  :
:

где f является композиционной функцией. Для распределения BoB композиционная функция будет выглядеть следующим образом:
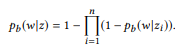
Другими словами, если ui является высказыванием zi, u — высказыванием 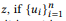 композиционно формирует u, то слово w не принадлежит u. Тогда и только тогда, когда оно не принадлежит какому-либо ui. Когда у z множество композиций, θe x вычисляется отдельно, а затем усредняется. Стандартная языковая униграм-модель не приводит к естественной композиционной функции. В процессе нормализации вероятностей слов участвует длина высказываний, которая, в свою очередь, учитывает сложность вызовов API, нарушая разложение в уравнении (2). Именно поэтому мы предлагаем распределение BoB.
композиционно формирует u, то слово w не принадлежит u. Тогда и только тогда, когда оно не принадлежит какому-либо ui. Когда у z множество композиций, θe x вычисляется отдельно, а затем усредняется. Стандартная языковая униграм-модель не приводит к естественной композиционной функции. В процессе нормализации вероятностей слов участвует длина высказываний, которая, в свою очередь, учитывает сложность вызовов API, нарушая разложение в уравнении (2). Именно поэтому мы предлагаем распределение BoB.
Пример 3. Предположим, мы подготовили аннотацию для упомянутых ранее вызовов API z1 и z2, в каждом из которых два высказывания: 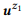 = {«find unread emails», «emails that are not read»} и
= {«find unread emails», «emails that are not read»} и 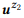 = {«how many emails do I have», «find the number of emails»}. Мы оценили языковые модели
= {«how many emails do I have», «find the number of emails»}. Мы оценили языковые модели 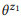 и
и 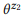 . Операция композиции пытается оценить
. Операция композиции пытается оценить 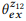 , не запрашивая
, не запрашивая 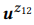 . Например, для слова «emails», pb («emails»|z1) = 1.0 и pb («emails»|z2) = 1.0, таким образом, из уравнения (3) следует, что pb («emails»|z12) = 1.0, то есть мы считаем, что это слово будет входить в любое высказывание z12. Аналогично, pb («find»|z1) = 0.5 и pb («find»|z2) = 0.5, таким образом, pb («find»|z12) = 0.75. Слово имеет хорошие шансы быть сгенерированным из любого z1 или z2, поэтому его вероятность для z12 должна быть выше.
. Например, для слова «emails», pb («emails»|z1) = 1.0 и pb («emails»|z2) = 1.0, таким образом, из уравнения (3) следует, что pb («emails»|z12) = 1.0, то есть мы считаем, что это слово будет входить в любое высказывание z12. Аналогично, pb («find»|z1) = 0.5 и pb («find»|z2) = 0.5, таким образом, pb («find»|z12) = 0.75. Слово имеет хорошие шансы быть сгенерированным из любого z1 или z2, поэтому его вероятность для z12 должна быть выше.
Разумеется, высказывания не всегда сочетаются композиционно. Например, несколько элементов в формализованном представлении смысловой структуры могут быть переданы одним словом или фразой на естественном языке, это явление получило название сублексической композиционности. Один такой пример показан на рисунке 3, где три параметра — TOP (1), FILTER (start>now) и ORDERBY (start, asc) — представлены одним словом «next». Тем не менее невозможно получить такую информацию без аннотирования вызова API, поэтому сама проблема напоминает проблему курицы и яйца. При отсутствии такой информации разумно придерживаться принятого по умолчанию предположения, что высказывания характеризуются той же композиционной связью, что и вызовы API.
Это — правдоподобное предположение. Стоит отметить, что это допущение используется только для моделирования процесса краудсорсинга с целью сбора данных. На этапе тестирования высказывания реальных пользователей могут не соответствовать этому предположению. Естественно-языковой интерфейс сможет справиться с такими некомпозиционными ситуациями, если они покрываются собранными обучающими данными.
INTERPOLATE (интерполяция) объединяет всю доступную информацию о z, то есть аннотированные высказывания z и информацию, полученную из композиций, и получает более точную оценку путем интерполяции и .
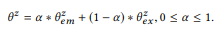
Балансовый параметр α контролирует компромиссные решения между аннотациями
текущей вершины, которые точны, но достаточны, а информация, полученная из композиций, основанных на предположении о композиционности, может быть не такой точной, зато она обеспечивает более широкий охват. В определенном смысле, служит той же цели, что и сглаживание в языковом моделировании, позволяющее лучше оценить распределение вероятностей при недостаточности данных (аннотаций). Чем больше 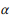 , тем больше вес в . Для корневой вершины, не имеющей композиции, = . Для неаннотированной вершины = .
, тем больше вес в . Для корневой вершины, не имеющей композиции, = . Для неаннотированной вершины = .
Далее мы опишем алгоритм обновления семантической сети, то есть вычисления для всех z (алгоритм 1), даже если была аннотирована лишь небольшая часть вершин. Мы предполагаем, что значение уже обновлено для всех аннотированных узлов. Спускаясь сверху вниз по слоям, мы последовательно вычисляем и для каждой вершины z. Сначала необходимо обновить верхние слои, чтобы можно было вычислить ожидаемое распределение вершин нижнего уровня. Мы аннотировали все корневые вершины, поэтому можем вычислить для всех вершин.
Алгоритм 1. Update Node Distributions of Semantic Mesh

3.3 Оптимизация краудсорсинга
Семантическая сеть формирует целостное представление обо всем пространстве вызовов API, а также о взаимодействии высказываний и вызовов. На основе этого представления мы можем выборочно аннотировать только подмножество вызовов API, имеющих высокую ценность. В этом разделе мы описываем предлагаемую нами стратегию дифференциального распространения для оптимизации краудсорсинга.
Рассмотрим семантическую сеть с множеством вершин Z. Наша задача — в рамках итеративного процесса определить подмножество вершин 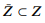 , которое будут аннотировать краудсорсинговые работники. Аннотированные ранее вершины мы назовем состоянием state,
, которое будут аннотировать краудсорсинговые работники. Аннотированные ранее вершины мы назовем состоянием state,
тогда нам нужно найти политику policy  для оценки каждой неаннотированной вершины с учетом текущего состояния.
для оценки каждой неаннотированной вершины с учетом текущего состояния.
Прежде чем углубиться в обсуждение подходов к вычислению эффективной политики, предположим, что она у нас уже есть, и дадим высокоуровневое описание нашего алгоритма краудсорсинга (алгоритм 2), чтобы описать сопутствующие методы. Говоря более конкретно, мы сначала аннотируем все корневые вершины, чтобы оценить распределение для всех вершин в Z (строка 3). При каждой итерации мы обновляем распределения вершин (строка 5), вычисляем
политику на основе текущего состояния семантической сети (строка 6), выбираем неаннотированную вершину с максимал
