[Перевод] Назад к микросервисам вместе с Istio. Часть 2

Прим. перев.: Первая часть этого цикла была посвящена знакомству с возможностями Istio и их демонстрации в действии. Теперь же речь пойдёт про более сложные аспекты конфигурации и использования этого service mesh, а в частности — про тонко настраиваемую маршрутизацию и управление сетевым трафиком.
Напоминаем также, что в статье используются конфигурации (манифесты для Kubernetes и Istio) из репозитория istio-mastery.
Управление трафиком
С Istio в кластере появляются новые возможности, позволяющие обеспечить:
- Динамическую маршрутизацию запросов: канареечные выкаты, A/B-тестирование;
- Балансировку нагрузки: простую и непротиворечивую, основанную на хэшах;
- Восстановление после падений: таймауты, повторные попытки, circuit breakers;
- Внесение неисправностей: задержки, обрыв запросов и т.п.
В продолжении статьи эти возможности будут показаны на примере выбранного приложения и попутно представлены новые концепции. Первой такой концепцией станет DestinationRules (т.е. правила о получателе трафика/запросов — прим. перев.), с помощью которых мы активируем A/B-тестирование.
A/B-тестирование: DestinationRules на практике
A/B-тестирование применяется в случаях, когда существуют две версии приложения (обычно они отличаются визуально) и мы не уверены на 100%, какая из них улучшит взаимодействие с пользователем. Поэтому мы одновременно запускаем обе версии и собираем метрики.
Для деплоя второй версии фронтенда, необходимой для демонстрации A/B-тестирования, выполните следующую команду:
$ kubectl apply -f resource-manifests/kube/ab-testing/sa-frontend-green-deployment.yaml
deployment.extensions/sa-frontend-green created
Манифест deployment’а для «зелёной версии» отличается в двух местах:
- Образ основан на ином теге —
istio-green, - Pod’ы имеют лейбл
version: green.
Поскольку оба deployment’а имеют лейбл app: sa-frontend, запросы, маршрутизируемые виртуальным сервисом sa-external-services на сервис sa-frontend, будут перенаправлены на все его экземпляры и нагрузка распределится посредством алгоритма round-robin, что приведёт к следующей ситуации:
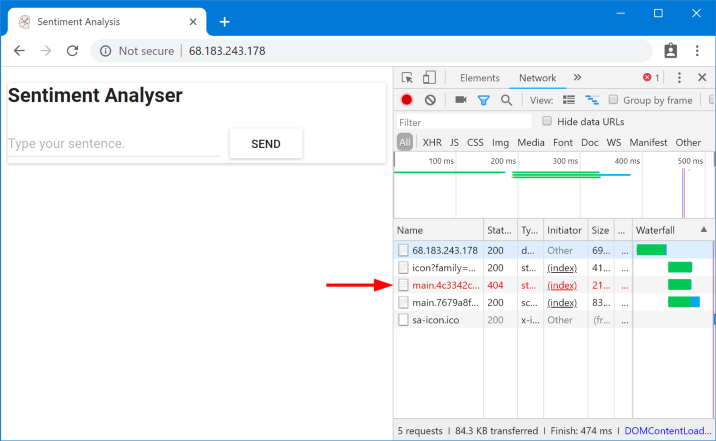
Запрашиваемые файлы не найдены
Эти файлы не были найдены из-за того, что они по-разному называются в разных версиях приложения. Давайте убедимся в этом:
$ curl --silent http://$EXTERNAL_IP/ | tr '"' '\n' | grep main
/static/css/main.c7071b22.css
/static/js/main.059f8e9c.js
$ curl --silent http://$EXTERNAL_IP/ | tr '"' '\n' | grep main
/static/css/main.f87cd8c9.css
/static/js/main.f7659dbb.js
Это означает, что index.html, запрашивающий одну версию статических файлов, может быть отправлен балансировщиком нагрузки на pod’ы, имеющие другую версию, где, по понятным причинам, таких файлов не существует. Поэтому для того, чтобы приложение заработало, нам необходимо поставить ограничение:»та же версия приложения, что отдала index.html, должна обслужить и последующие запросы».
Мы добьёмся цели с помощью непротиворечивой балансировки нагрузки на основе хэшей (Consistent Hash Loadbalancing). В этом случае запросы от одного клиента отправляются в один и тот же экземпляр бэкенда, для чего используется предопределённое свойство — например, HTTP-заголовок. Реализуется с помощью DestinationRules.
DestinationRules
После того, как VirtualService направил запрос в нужный сервис, с помощью DestinationRules мы можем определить политики, которые будут применяться к трафику, предназначаемому экземплярам этого сервиса:
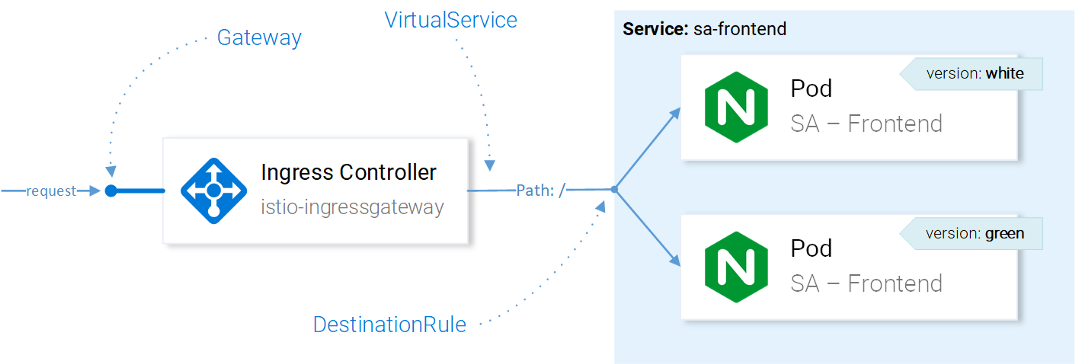
Управление трафиком с ресурсами Istio
Примечание: Влияние ресурсов Istio на сетевой трафик представлено здесь в упрощённом для понимания виде. Если быть точным, то решение, на какой экземпляр отправлять запрос, делается Envoy’ем в Ingress Gateway, настроенным в CRD.
С помощью Destination Rules мы можем настроить балансировку нагрузки так, чтобы использовались непротиворечивые хэши и гарантировались ответы одного и того же экземпляра сервиса одному и тому же пользователю. Следующая конфигурация позволяет добиться этого (destinationrule-sa-frontend.yaml):
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: sa-frontend
spec:
host: sa-frontend
trafficPolicy:
loadBalancer:
consistentHash:
httpHeaderName: version # 1
1 — хэш будет генерироваться на основе содержимого HTTP-заголовка version.
Примените конфигурацию следующей командой:
$ kubectl apply -f resource-manifests/istio/ab-testing/destinationrule-sa-frontend.yaml
destinationrule.networking.istio.io/sa-frontend created
А теперь выполните команду ниже и убедитесь, что получаете нужные файлы, когда указываете заголовок version:
$ curl --silent -H "version: yogo" http://$EXTERNAL_IP/ | tr '"' '\n' | grep main
Примечание: Чтобы добавлять различные значения в заголовке и тестировать результаты прямо в браузере, можно воспользоваться этим расширением к Chrome (или вот этим для Firefox — прим. перев.).
Вообще же, у DestinationRules есть больше возможностей в области балансировки нагрузки — подробности уточняйте в официальной документации.
Перед тем, как изучать VirtualService дальше, удалим «зелёную версию» приложения и соответствующее правило по направлению трафика, выполнив следующие команды:
$ kubectl delete -f resource-manifests/kube/ab-testing/sa-frontend-green-deployment.yaml
deployment.extensions "sa-frontend-green” deleted
$ kubectl delete -f resource-manifests/istio/ab-testing/destinationrule-sa-frontend.yaml
destinationrule.networking.istio.io "sa-frontend” deleted
Зеркалирование: Virtual Services на практике
Shadowing («экранирование») или Mirroring («зеркалирование») применяется в тех случаях, когда мы хотим протестировать изменение в production, не затронув конечных пользователей: для этого мы дублируем («зеркалируем») запросы на второй экземпляр, где произведены нужные изменения, и смотрим на последствия. Проще говоря, это когда ваш (а) коллега выбирает самый критичный issue и делает pull request в виде такого огромного комка грязи, что никто не может в действительности сделать ему ревью.
Чтобы проверить этот сценарий в действии, создадим второй экземпляр SA-Logic с багами (buggy), выполнив следующую команду:
$ kubectl apply -f resource-manifests/kube/shadowing/sa-logic-service-buggy.yaml
deployment.extensions/sa-logic-buggy created
И теперь выполним команду, чтобы убедиться, что все экземпляры с app=sa-logic имеют ещё и лейблы с соответствующими версиями:
$ kubectl get pods -l app=sa-logic --show-labels
NAME READY LABELS
sa-logic-568498cb4d-2sjwj 2/2 app=sa-logic,version=v1
sa-logic-568498cb4d-p4f8c 2/2 app=sa-logic,version=v1
sa-logic-buggy-76dff55847-2fl66 2/2 app=sa-logic,version=v2
sa-logic-buggy-76dff55847-kx8zz 2/2 app=sa-logic,version=v2
Сервис sa-logic нацелен на pod’ы с лейблом app=sa-logic, поэтому все запросы будут распределены между всеми экземплярами:
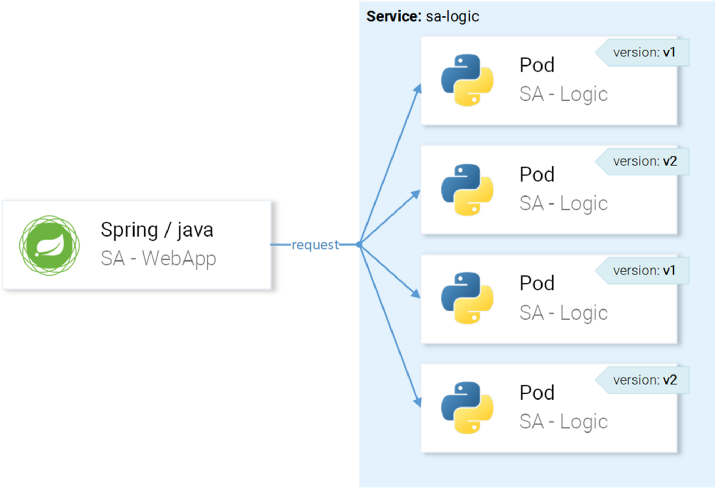
…, но мы хотим, чтобы запросы направлялись на экземпляры с версией v1 и зеркалировались на экземпляры с версией v2:
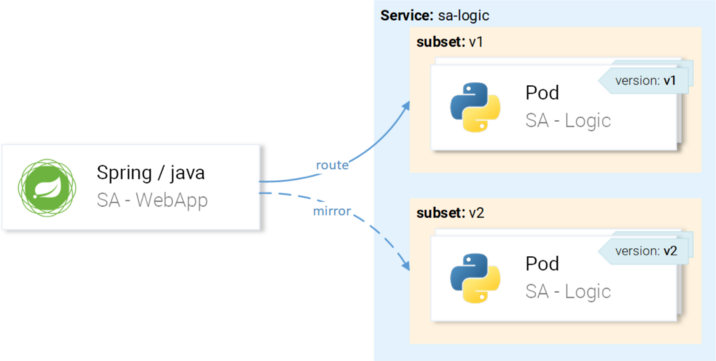
Добьёмся этого через VirtualService в комбинации с DestinationRule, где правила определят подмножества и маршруты VirtualService к конкретному подмножеству.
Определение подмножеств в Destination Rules
Подмножества (subsets) определяются следующей конфигурацией (sa-logic-subsets-destinationrule.yaml):
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: sa-logic
spec:
host: sa-logic # 1
subsets:
- name: v1 # 2
labels:
version: v1 # 3
- name: v2
labels:
version: v2
- Хост (
host) определяет, что это правило применяется только к случаям, когда маршрут идёт в сторону сервисаsa-logic; - Названия (
name) подмножеств используются при маршрутизации на экземпляры подмножества; - Лейбл (
label) определяет пары ключ-значение, которым должны соответствовать экземпляры, чтобы стать частью подмножества.
Примените конфигурацию следующей командой:
$ kubectl apply -f resource-manifests/istio/shadowing/sa-logic-subsets-destinationrule.yaml
destinationrule.networking.istio.io/sa-logic created
Теперь, когда подмножества определены, можно двигаться дальше и настроить VirtualService, чтобы применить правила к запросам к sa-logic, чтобы они:
- Маршрутизировались к подмножеству
v1, - Зеркалировались к подмножеству
v2.
Следующий манифест позволяет добиться задуманного (sa-logic-subsets-shadowing-vs.yaml):
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: sa-logic
spec:
hosts:
- sa-logic
http:
- route:
- destination:
host: sa-logic
subset: v1
mirror:
host: sa-logic
subset: v2
Пояснения здесь не требуются, так что просто посмотрим в действии:
$ kubectl apply -f resource-manifests/istio/shadowing/sa-logic-subsets-shadowing-vs.yaml
virtualservice.networking.istio.io/sa-logic created
Добавим нагрузку вызовом такой команды:
$ while true; do curl -v http://$EXTERNAL_IP/sentiment \
-H "Content-type: application/json" \
-d '{"sentence": "I love yogobella"}'; \
sleep .8; done
Посмотрим на результаты в Grafana, где можно увидеть, что версия с багами (buggy) приводит к сбою для ~60% запросов, но ни один из этих сбоев не затрагивает конечных пользователей, поскольку им отвечает работающий сервис.
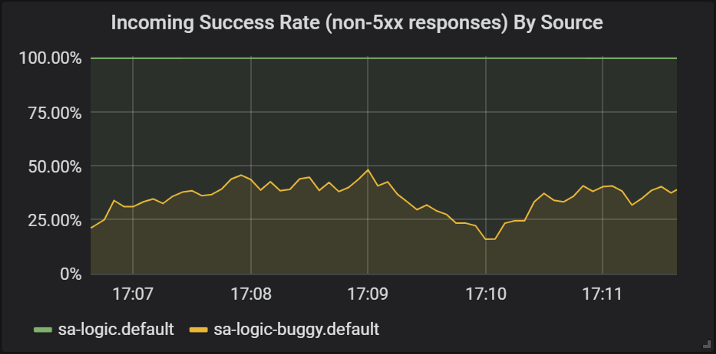
Успешность ответов разных версий сервиса sa-logic
Здесь мы впервые увидели, как VirtualService применяется по отношению к Envoy’ям наших сервисов: когда sa-web-app делает запрос к sa-logic, он проходит через sidecar Envoy, который — через VirtualService — настроен на маршрутизацию запроса к подмножеству v1 и зеркалированию запроса к подмножеству v2 сервиса sa-logic.
Знаю: вы уже успели подумать, что Virtual Services просты. В следующем разделе мы расширим это мнение тем, что они ещё и по-настоящему великолепны.
Канареечные выкаты
Canary Deployment — процесс выкатывания новой версии приложения для небольшого числа пользователей. Его используют, чтобы убедиться в отсутствии проблем в релизе и только после этого, уже будучи уверенным в достаточном его (релиза) качестве, распространить на большую аудиторию.
Для демонстрации канареечных выкатов мы продолжим работу с подмножеством buggy у sa-logic.
Не будем мелочиться и сразу же отправим 20% пользователей на версию с багами (она и будет представлять наш канареечный выкат), а оставшиеся 80% — на нормальный сервис. Для этого применим следующий VirtualService (sa-logic-subsets-canary-vs.yaml):
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: sa-logic
spec:
hosts:
- sa-logic
http:
- route:
- destination:
host: sa-logic
subset: v1
weight: 80 # 1
- destination:
host: sa-logic
subset: v2
weight: 20 # 1
1 — это вес (weight), определяющий процент запросов, которые будут направлены на получателя или подмножество получателя.
Обновим прошлую конфигурацию VirtualService для sa-logic следующей командой:
$ kubectl apply -f resource-manifests/istio/canary/sa-logic-subsets-canary-vs.yaml
virtualservice.networking.istio.io/sa-logic configured
… и сразу же увидим, что часть запросов приводит к сбоям:
$ while true; do \
curl -i http://$EXTERNAL_IP/sentiment \
-H "Content-type: application/json" \
-d '{"sentence": "I love yogobella"}' \
--silent -w "Time: %{time_total}s \t Status: %{http_code}\n" \
-o /dev/null; sleep .1; done
Time: 0.153075s Status: 200
Time: 0.137581s Status: 200
Time: 0.139345s Status: 200
Time: 30.291806s Status: 500
VirtualServices активируют канареечные выкаты: в данном случае мы сузили потенциальные последствия от проблем до 20% от пользовательской базы. Прекрасно! Теперь в каждом случае, когда мы не уверены в своём коде (иными словами — всегда…), мы можем использовать зеркалирование и канареечные выкаты.
Таймауты и повторные попытки
Но не всегда баги оказываются в коде. В списке из »8 заблуждений в распределённых вычислениях» на первом месте значится ошибочное мнение, что «сеть надёжна». В действительности сеть не надёжна, и по этой причине нам нужны таймауты (timeouts) и повторные попытки (retries).
Для демонстрации мы продолжим использовать ту же проблему версию sa-logic (buggy), а ненадёжность сети будем симулировать случайными сбоями.
Пусть наш сервис с багами имеет ⅓ шанс на слишком долгий ответ, ⅓ — на завершение с ошибкой Internal Server Error и ⅓ — на успешную отдачу страницы.
Чтобы смягчить последствия от подобных проблем и сделать жизнь пользователей лучше, мы можем:
- добавить таймаут, если сервис отвечает дольше 8 секунд,
- предпринимать повторную попытку, если у запроса происходит сбой.
Для реализации воспользуемся таким определением ресурса (sa-logic-retries-timeouts-vs.yaml):
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: sa-logic
spec:
hosts:
- sa-logic
http:
- route:
- destination:
host: sa-logic
subset: v1
weight: 50
- destination:
host: sa-logic
subset: v2
weight: 50
timeout: 8s # 1
retries:
attempts: 3 # 2
perTryTimeout: 3s # 3
- Таймаут для запроса установлен в 8 секунд;
- Повторные попытки запросов предпринимаются по 3 раза;
- И каждая попытка считается неудачной, если время ответа превышает 3 секунды.
Так мы добились оптимизации, поскольку пользователю не придётся ждать более 8 секунд и мы предпримем три новые попытки получить ответ в случае сбоев, повышая шанс на успешный ответ.
Примените обновлённую конфигурацию следующей командой:
$ kubectl apply -f resource-manifests/istio/retries/sa-logic-retries-timeouts-vs.yaml
virtualservice.networking.istio.io/sa-logic configured
И проверьте в графиках Grafana, что количество успешных ответов стало свыше:
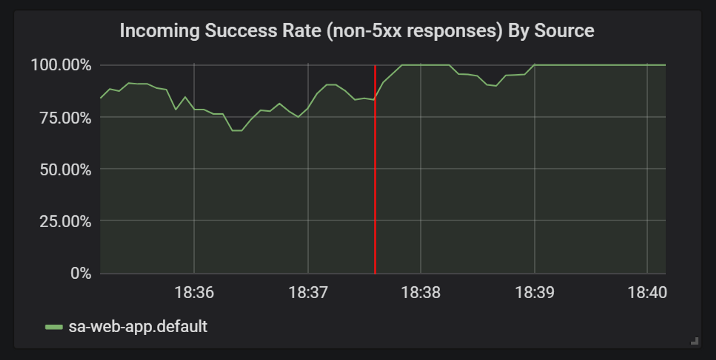
Улучшения в статистике успешных ответов после добавления таймаутов и повторных попыток
Перед тем, как переходить к следующему разделу (а точнее — уже к следующей части статьи, т.к. в этой практических экспериментов больше не будет — прим. перев.), удалите sa-logic-buggy и VirtualService, выполнив следующие команды:
$ kubectl delete deployment sa-logic-buggy
deployment.extensions "sa-logic-buggy” deleted
$ kubectl delete virtualservice sa-logic
virtualservice.networking.istio.io "sa-logic” deleted
Паттерны Circuit Breaker и Bulkhead
Речь идёт о двух важных паттернах в микросервисной архитектуре, которые позволяют добиться самостоятельного восстановления (self-healing) сервисов.
Circuit Breaker («автоматический выключатель») используется для прекращения запросов, поступающих на экземпляр сервиса, который считается нездоровым, и его восстановления в то время, как запросы клиентов перенаправляются на здоровые экземпляры этого сервиса (что повышает процент успешных ответов). (Прим. перев.: Более подробное описание паттерна можно найти, например, здесь.)
Bulkhead («перегородка») изолирует сбои в сервисах от поражения всей системы. Например, сервис B сломан, а другой сервис (клиент сервиса B) делает запрос к сервису B, в результате чего он израсходует свой пул потоков и не сможет обслуживать другие запросы (даже если они не относятся к сервису B). (Прим. перев.: Более подробное описание паттерна можно найти, например, здесь.)
Я опущу детали по реализации этих паттернов, потому что их легко найти в официальной документации, а также очень уже хочется показать аутентификацию и авторизацию, о чём и пойдёт речь в следующей части статьи.
P.S. от переводчика
Читайте также в нашем блоге:
