[Перевод] Наш путь к нулевым простоям при непрерывном обновлении с помощью Ambassador

Мы в Lifion строим распределенную платформу и портфель продуктов для клиентов по всему миру. С учетом этого важно, чтобы мы могли выпускать обновления нашей платформы непрерывно прямо во время ее работы, прозрачно для наших пользователей, которым важна доступность системы, при этом они находятся в разных регионах и часовых поясах. В этой статье мы поделимся с вами путем, которым мы шли, чтобы получить нулевые простои при непрерывном обновлении с помощью Kubernetes. Мы запускаем наши нагрузки с помощью управляемого сервиса Kubernetes — AWS EKS. В качестве шлюза API мы применяем Ambassador, сборку Envoy с открытым исходным кодом, специально разработанную для Kubernetes. Наша платформа состоит из более чем 150 микросервисов, большинство из них написаны на Node.js, запускаются в многих подах поверх многочисленных рабочих узлов.
Состояние проблемы
Поскольку мы разворачиваем наше решение NextGen HGM для все большего числа клиентов, и требования к платформе растут, мы хотим в дальнейшем обеспечивать надежность нашей нижележащей инфраструктуры. Однако проблема, которую мы обнаружили при проведении непрерывного обновления некоторых наших сервисов в кластере Kubernetes, заключается в том, что поды отключаются сразу же, как только сервисы переходят в состояние Terminating, вместо мягкой остановки, как мы предполагали. Это привело к сбоям некоторых запросов во время таких обновлений, что нежелательно, а также потенциально может повлиять на работу пользователей.
Главная причина (Нет обработки SIGTERM)
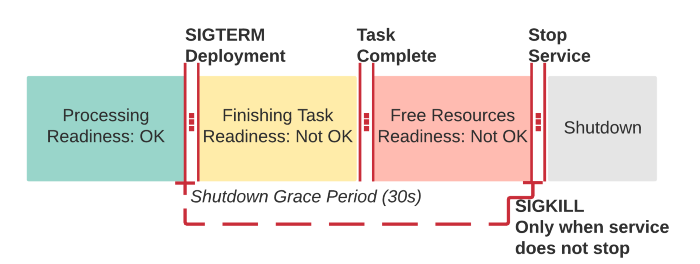
Среда запуска контейнеров в некоторой части жизненного цикла пода Kubernetes отправляет сигнал SIGTERM в старый под во время обновления, к примеру, когда новый под уже запущен и может принимать запросы для обслуживания. Проведя исследование, мы поняли, что часть наших команд инженеров запускали сервисы на Node.js в подах под PID1, так что SIGTERM явно не обрабатывался на уровне кода, несмотря на рекомендации:
Node.js не разработан для запуска под PID1, это может привести к неопределенному поведению при запуске внутри контейнера Docker. Например, процесс Node.js, запущенный под PID1 не будет отвечать на SIGINT (CTRL-C) и другие подобные сигналы.
Это значит, что во время обновления, когда поды получают сигнал SIGTERM, они ждут 30 секунд (промежуток времени для мягкого завершения), а затем им присылается SIGKILL, так что процессы с PID1 резко выключаются с кодом возврата 137. Это приводит к сбору существующих обрабатываемых в этот момент запросов к поду, на которые не будет дан ответ.
Решение (первая попытка)
В нашу библиотеку Node.js, поверх которой строятся наши микросервисы, мы добавили типовую обработку сигнала SIGTERM, который останавливает активное обслуживание запросов после некоторой задержки. Это значит, что оставшимся запросам дается некоторое время для завершения, прежде чем они будут закрыты и их соединения TCP с все еще активными keep-alive также будут завершены. Ну и наконец — сервис останавливается.
...
process.on('SIGINT', () => {
logger.warn('SIGINT received. Shutting down…');
process.exit(0);
});
process.on('SIGTERM', () => {
logger.warn('SIGTERM received. Initiating graceful shutdown…');
shutdown()
.catch((err) => {
logger.error('Ignoring error during graceful shutdown:', err);
})
.finally(() => {
logger.warn('Graceful shutdown completed.');
process.exit(0);
});?
});
....
module.exports = Object.assign(exposed, {
_listen: exposed.listen,
config,
listen: start,
listenAsync: startAsync,
reset,
setAfterShutdown: (fn) => {
hooks.afterShutdown = fn;
},
setBeforeShutdown: (fn) => {
hooks.beforeShutdown = fn;
},
start,
startAsync,
stop,
stopAsync: promisify(stop)
});Еще один барьер (получение запросов после SIGTERM)
После подключения обработки SIGTERM в нашей основной библиотеке мы получили еще одну проблему: один из инженеров сказал нам, что по факту его сервис все еще получал некоторые запросы после получения SIGTERM во время обновления. А если верить соглашению жизненного цикла пода в Kubernetes, как только под получил SIGTERM, он удаляется из endpoints сервиса, а значит, и из балансировщика нагрузки. Однако если под удаляется из кластера через API, то он только помечается для удаления на сервере метаданных. Сервер уже в свою очередь отправляет уведомление об удалении пода всем связанным подсистемам, обрабатывающим запрос на удаление:
kubelet, запускающий последовательности запуска и остановки пода- сервис
kube-proxy, удаляющий на всех узлах ip-адрес пода вiptables - контроллер endpoints удаляет под из списка корректных endpoints, что приводит к удалению пода из
Service
Мы можем воспроизвести эту проблему следующим кусочком кода:
function readyCheck() {
let ready = true;
process.on('SIGTERM', () => {
logger.info('SIGTERM received, making service as no longer ready');
ready = false;
});
return (req, res) => {
if (ready) {
logger.info('Successful ready check');
res.sendStatus(200);
} else {
res.sendStatus(503);
logger.info('Signaling ready check failure');
}
};
}
....
router.get('/ready', readyCheck());Во время исследований мы нашли ключевую причину этой проблемы, она была связана с нашим шлюзом API Ambassador/Envoy. Ambassador оборачивает для Envoy, создавая ему настройки. Команда Ambassador помогла нам в наших исследованиях, их официальный ответ от техподдержки был таким:
Envoy старается быть максимально эффективным при поддержке открытых соединений к вышестоящим сервисам. Поскольку фактические endpoints меняются, эти долгоживущие соединения все еще могут быть связаны с старым подом, который будет удален через некоторое короткое время. Проблема в том, что существует некая задержка между Kubernetes, отправляющим SIGTERM для отключения пода, и Ambassador, удаляющим под из списка endpoints. Стоит отметить, что проблема существует и в kube-proxy, если вы с ним работаете в больших масштабах.
Проще говоря, из-за оптимизации Envoy некоторые сервисы будут получать запросы после того, как они получили SIGTERM, что приведет к потере текущих запросов (запрос пришел до DIGTERM, но еще не обработан) во время обновления этого сервиса.
Решение (вторая попытка)
Envoy нужно некоторое время для остановки существующих соединений на время остановки пода до получения подом SIGTERM. Так что в качестве решения мы добавили поддержку preStopHook в Helm Chart для нашего сервиса:
lifecycle:
preStop:
exec:
command:
- sleep
- "10"Во время обновления процесс остановки старого пода ждет 10 секунд, чтобы дать возможность Envoy отключить все существующие соединения к поду, а также удостовериться, что под убран из endpoints балансировщика нагрузки. Сразу же после этого Kubernetes, как обычно, отправляет сигнал SIGTERM процессу с PID1.
Для гибкости мы расширили это изменение, так что команды инженеров могут также переопределять такое поведение по умолчанию, если это им понадобится. Например, у нас есть несколько сервисов, использующих NGINX для раздачи статического контента из пода, для них мы решили проблему следующими изменениями в helm chart:
lifecycle:
preStop:
exec:
command: [
"sh", "-c",
# Introduce a delay to the shutdown sequence to wait for the
# pod eviction event to propagate. Then, gracefully shutdown
# nginx.
"sleep 5 && /usr/sbin/nginx -s quit",
]Выводы
Если сложить все вместе, то эта статья покрывает:
- Принципы обработки жизненного цикла Kubernetes, используемые для мягкого и безопасного выключения приложений, при котором они не будут терять текущие запросы.
- Нюансы, с которыми поды удаляются из системы. Важность понимания и особенности обработки соответствующей процедуры выключения, особенно в крупных масштабах с применением Ambassador.
Если все эти функции применять вместе, мы можем достичь нашей цели: нулевого простоя при непрерывном обновлении сервисов.
N.B. Для тех, кому нужна практика построения систем с надежной архитектурой, готовых к перегрузкам, Слёрм проводит онлайн-интенсив по SRE. Интенсив пройдет 11—13 декабря 2020, до начала декабря можно купить билет со скидкой.
