[Перевод] Наглядно о том, как работает свёрточная нейронная сеть

К старту курса о машинном и глубоком обучении мы решили поделиться переводом статьи с наглядным объяснением того, как работают CNN — сети, основанные на принципах работы визуальной коры человеческого мозга. Ненавязчиво, как бы между строк, автор наталкивает на размышления о причинах эффективности CNN и на простых примерах разъясняет происходящие внутри этих нейронных сетей преобразования.
Начинаем сначала
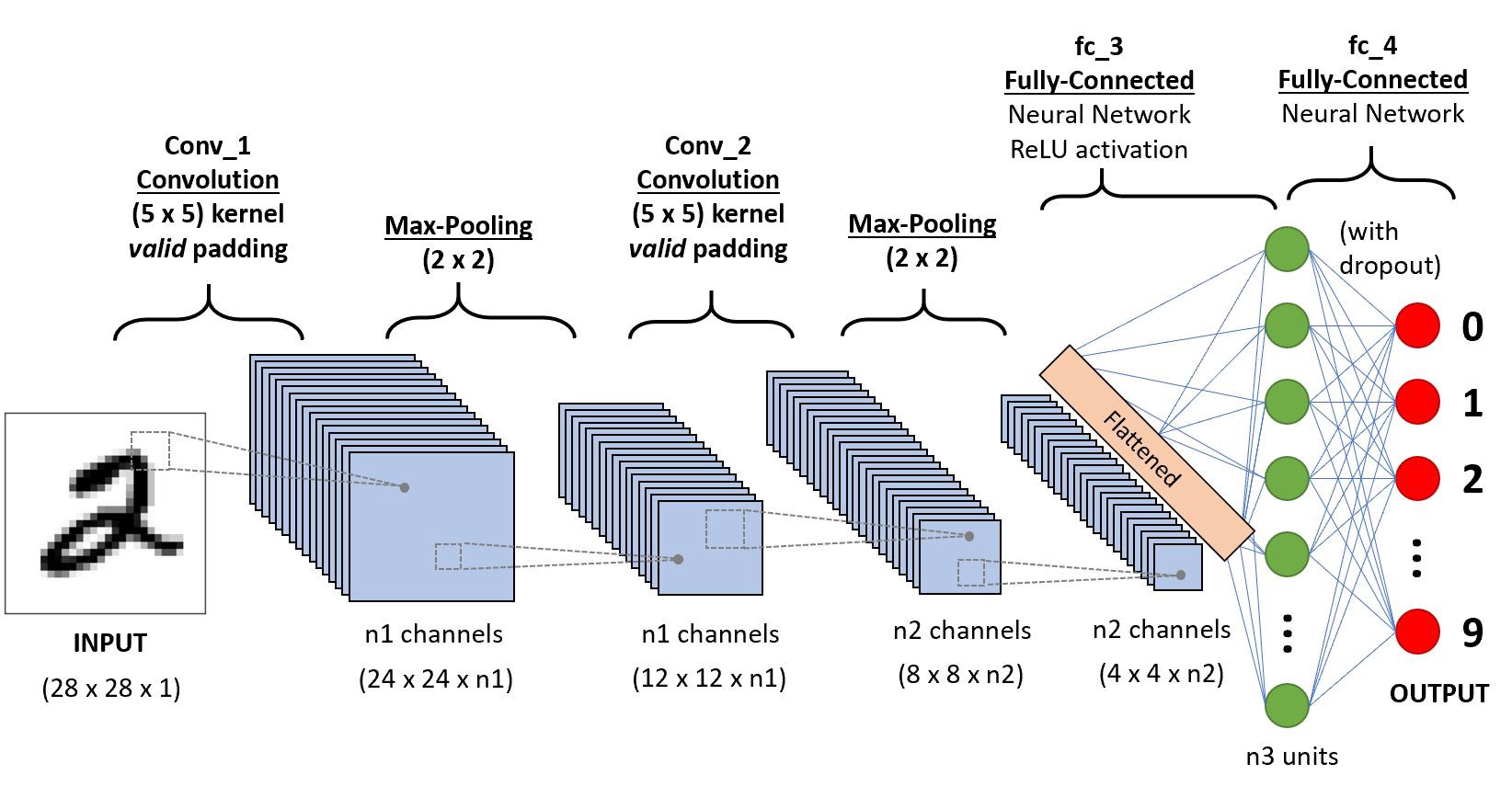 Начнём с последовательности CNN, которая классифицирует рукописные цифры
Начнём с последовательности CNN, которая классифицирует рукописные цифрыСвёрточная нейронная сеть (ConvNet/CNN) — это алгоритм глубокого обучения, который может принимать входное изображение, присваивать важность (изучаемые веса и смещения) аспектам или объектам изображении и отличать одно от другого. При этом изображения в сравнении с другими алгоритмами требуют гораздо меньше предварительной обработки. В примитивных методах фильтры разрабатываются вручную, но достаточно обученные сети CNN сети учатся применять эти фильтры/характеристики.
Архитектура CNN аналогична структуре связей нейронов в мозгу человека, учёные черпали вдохновение в организации зрительной коры головного мозга. Отдельные нейроны реагируют на стимулы только в некоторой области поля зрения, также известного как перцептивное поле. Множество перцептивных полей перекрывается, полностью покрывая поле зрения CNN.
Почему слои свёртки расположены над сетью с прямой связью
 Матрица 3×3 в виде вектора 9×1
Матрица 3×3 в виде вектора 9×1Изображение — не что иное, как матрица значений пикселей, верно? Так почему бы не сделать его плоским (например, матрицу 3×3 сделать вектором 9×1) и скормить этот вектор многослойному перцептрону, чтобы тот выполнил классификацию? Хм… всё не так просто.
В случаях простейших двоичных изображений при выполнении прогнозирования классов метод может показать среднюю точность, но на практике, когда речь пойдёт о сложных изображениях, в которых повсюду пиксельные зависимости, он окажется неточным.
Сеть CNN способна с успехом схватывать пространственные и временные зависимости в изображении через применение соответствующих фильтров. Такая архитектура за счёт сокращения числа задействованных параметров и возможности повторного использования весов даёт лучшее соответствие набору данных изображений. Иными словами, сеть можно научить лучше понимать сложность изображения.
Входное изображение
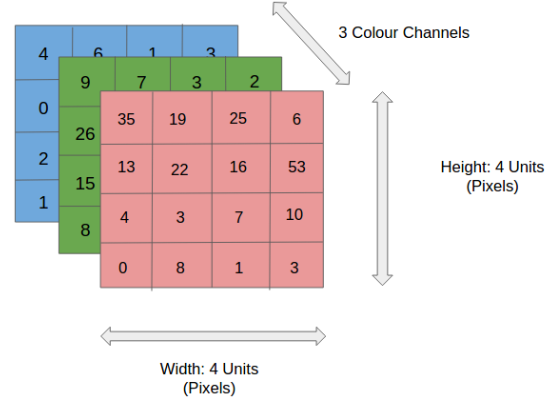 RGB-изображение 4×4×3
RGB-изображение 4×4×3На рисунке мы видим разделённое на три цветовых плоскости (красную, зелёную и синюю) RGB-изображение, которое можно описать в разных цветовых пространствах — в оттенках серого (Grayscale), RGB, HSV, CMYK и т. д.
Можно представить, насколько интенсивными будут вычисления, когда изображения достигнут размеров, например, 8 K (76804320). Роль CNN заключается в том, чтобы привести изображения в форму, которую легче обрабатывать, без потери признаков, имеющих решающее значение в получении хорошего прогноза. Это важно при разработке архитектуры, которая не только хорошо изучает функции, но и масштабируется для массивных наборов данных.
Слой свёртки — ядро
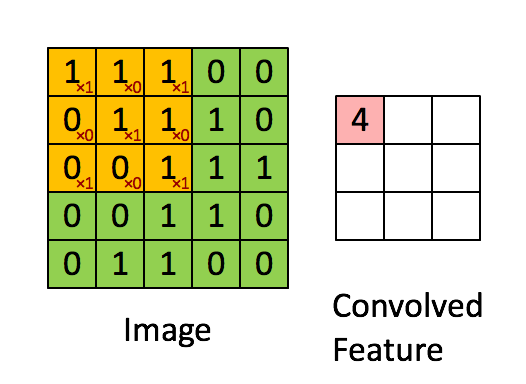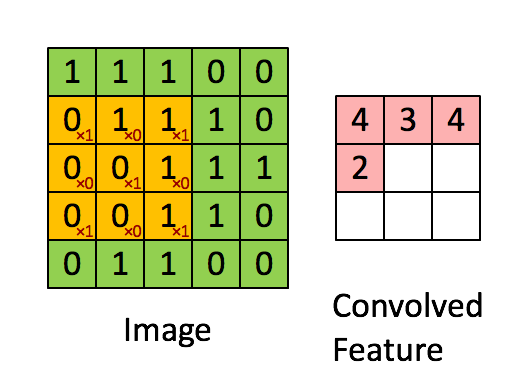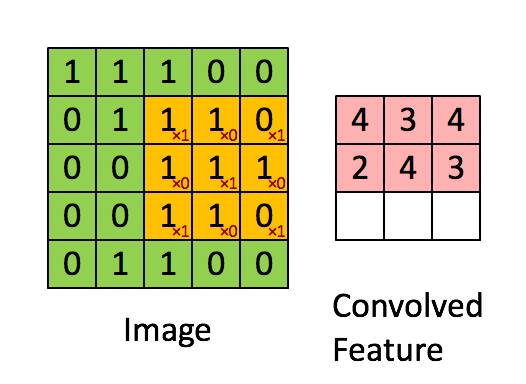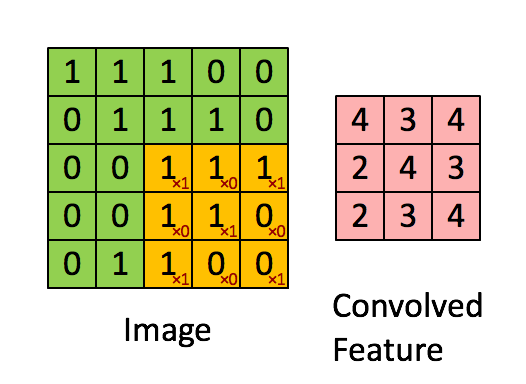 Свёртка изображения 5×5×1 с ядром 3×3×1 для получения свёрнутого признака 3×3×1
Свёртка изображения 5×5×1 с ядром 3×3×1 для получения свёрнутого признака 3×3×1Размеры изображения:
5 — высота;
5 — ширина;
1 — количество каналов, например, RGB.
В демонстрации выше зелёная секция напоминает наше входное изображение 5×5×1. Элемент, участвующий в выполнении операции свёртки в первой части слоя свёртки, называется ядром/фильтром K, он представлен жёлтым цветом. Пусть K будет матрицей 3×3×1:
Kernel/Filter, K =
1 0 1
0 1 0
1 0 1Ядро смещается 9 раз из-за длины шага в единицу (то есть шага нет), каждый раз выполняя операцию умножения матрицы K на матрицу P, над которой находится ядро.
 Перемещение ядра
Перемещение ядраФильтр перемещается вправо с определённым значением шага, пока не проанализирует всю ширину. Двигаясь дальше, он переходит к началу изображения (слева) с тем же значением шага и повторяет процесс до тех пор, пока не проходит всё изображение.
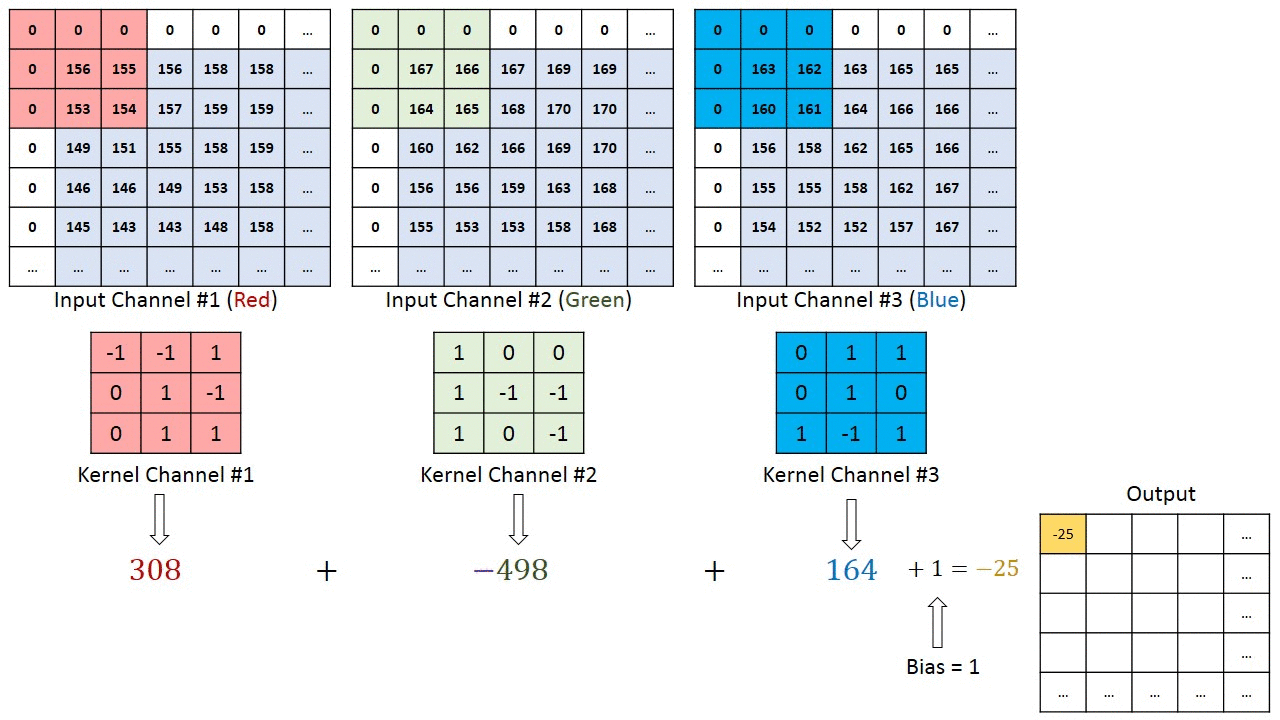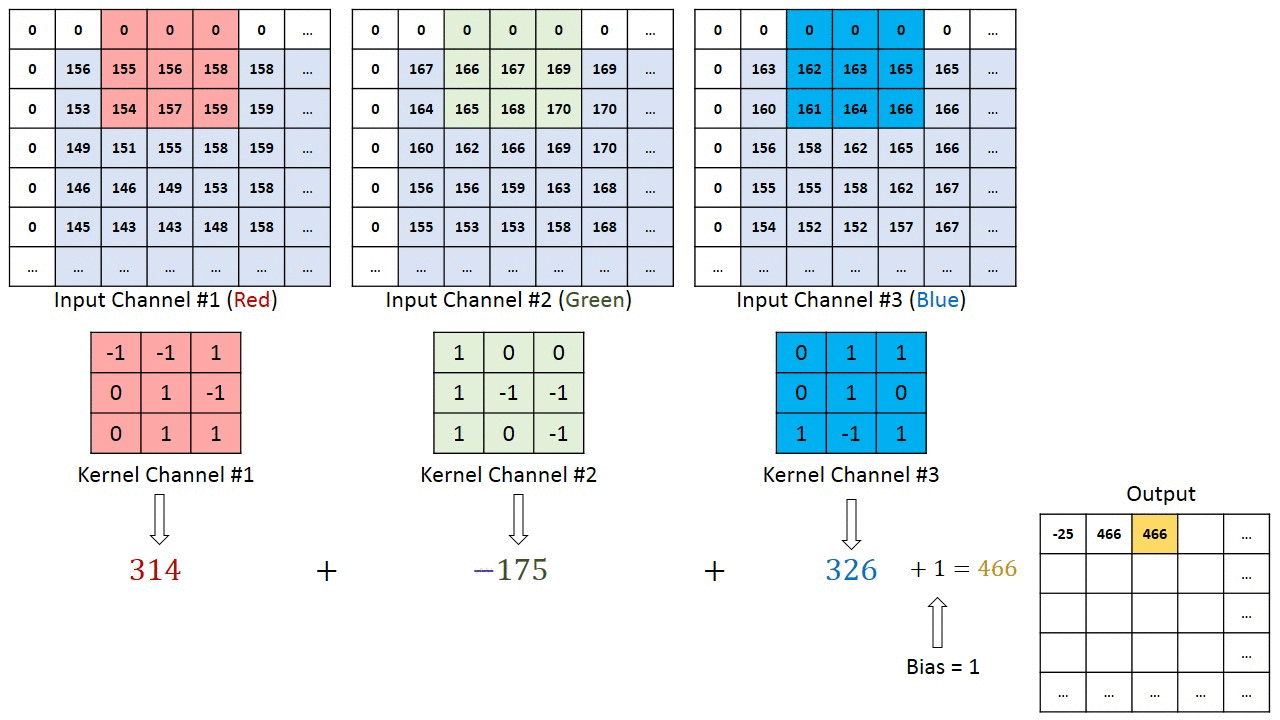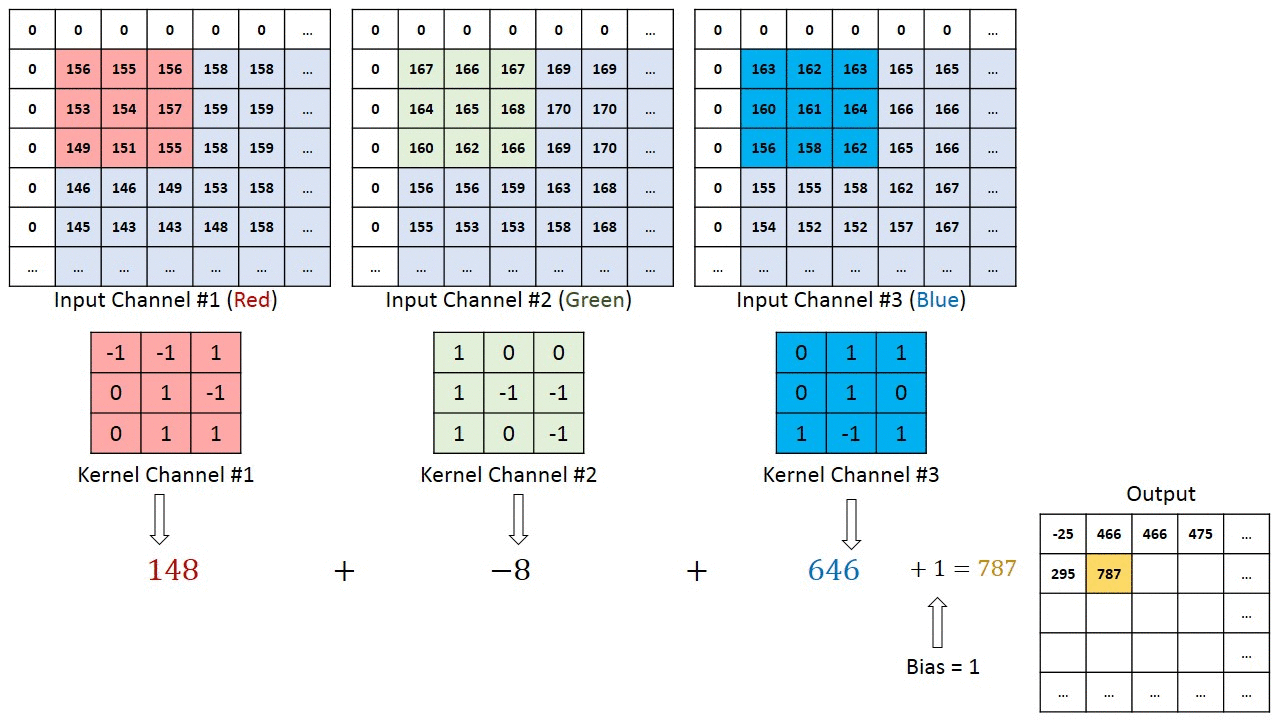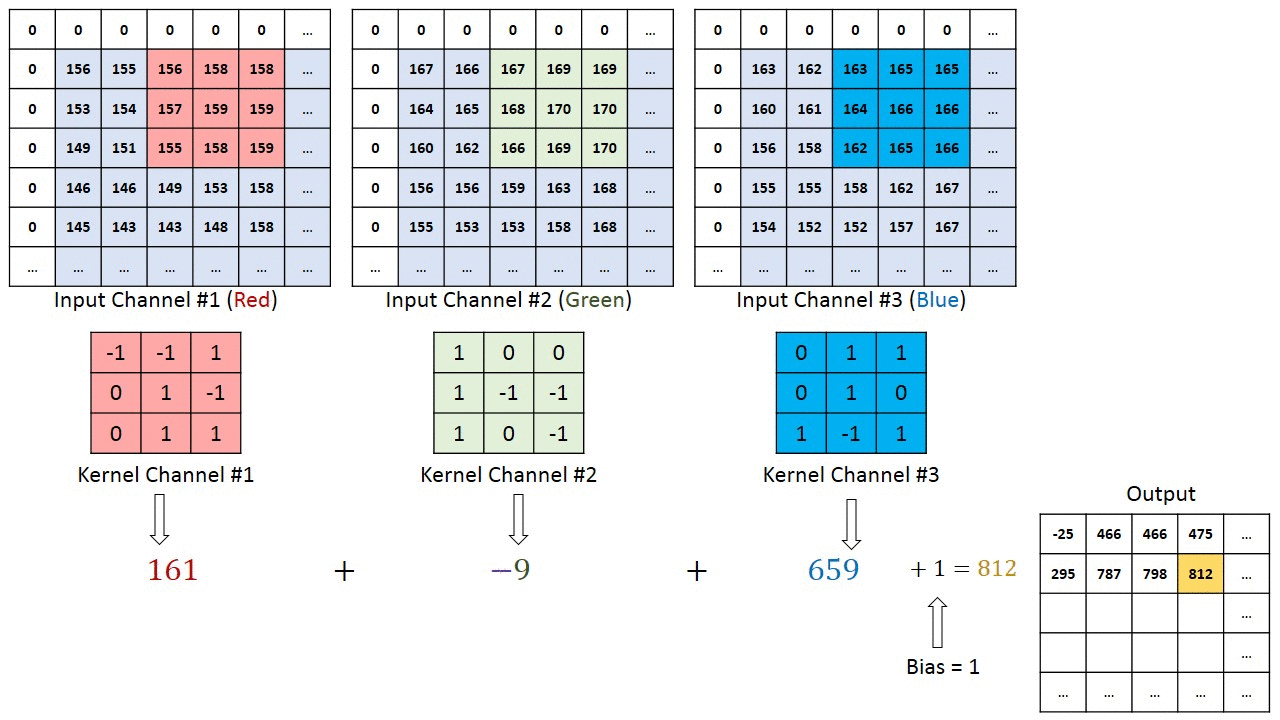 Операция свёртки на матрице изображения M×N×3 с ядром 3×3×3
Операция свёртки на матрице изображения M×N×3 с ядром 3×3×3В случае изображений с несколькими каналами (например, RGB) ядро имеет ту же глубину, что и у входного изображения. Матричное умножение выполняется между стеками Kn и In ([K1, I1]; [K2, I2]; [K3, I3]), все результаты суммируются со смещением, чтобы получить уплощённый канал вывода свёрнутых признаков с глубиной в 1.
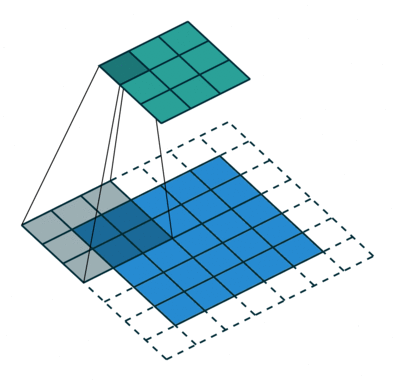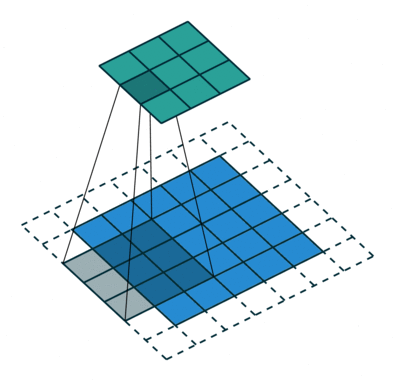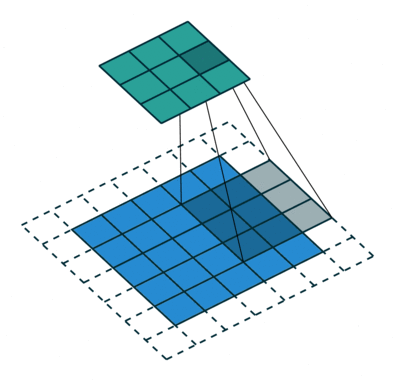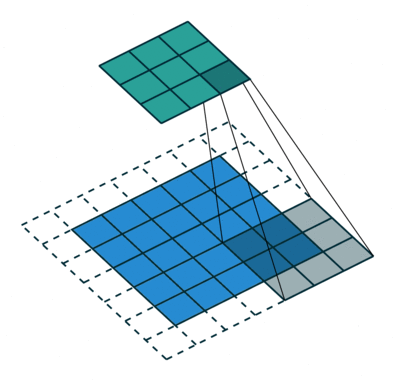 Операция свёртки с длиной шага, равной 2
Операция свёртки с длиной шага, равной 2Свёртка делается, чтобы извлечь высокоуровневые признаки, например края входного изображения. Сеть не нужно ограничивать единственным слоем. Первый слой условно несёт ответственность за схватывание признаков низкого уровня, таких как кромки, цвет, ориентация градиента и т. д. Через дополнительные слои архитектура адаптируется к признакам высокого уровня, мы получаем сеть со здравым пониманием изображений в наборе данных, похожем на наше.
У результатов свёртки два типа: первый — свёрнутый признак уменьшается в размере по сравнению с размером на входе, второй тип касается размерности — она либо остаётся прежней, либо увеличивается. Это делается путём применения допустимого заполнения в первом случае или нулевого заполнения — во втором.
 Нулевое заполнение: для создания изображения 6×6×1 изображение 5×5×1 дополняется нулями
Нулевое заполнение: для создания изображения 6×6×1 изображение 5×5×1 дополняется нулямиУвеличивая изображение 5×5×1 до 6×6×1, а затем проходя над ним ядром 3×3×1, мы обнаружим, что свёрнутая матрица будет обладать разрешением 5×5×1. Отсюда и название — нулевое заполнение. С другой стороны, проделав то же самое без заполнения, мы обнаружим матрицу с размерами самого ядра (3×3×1); эта операция называется допустимым заполнением.
В этом репозитории содержится множество таких GIF-файлов, они помогут лучше понять, как заполнение и длина шага работают вместе для достижения необходимых результатов.
Слой объединения
 Объединение 3×3 над свёрнутым признаком 5×5
Объединение 3×3 над свёрнутым признаком 5×5Подобно свёрточному слою, слой объединения отвечает за уменьшение размера свёрнутого объекта в пространстве. Это делается для уменьшения необходимой при обработке данных вычислительной мощности за счёт сокращения размерности. Кроме того, это полезно для извлечения доминирующих признаков, которые являются вращательными и позиционными инвариантами, тем самым позволяя поддерживать процесс эффективного обучения модели.
Есть два типа объединения: максимальное и среднее. Первое возвращает максимальное значение из покрытой ядром части изображения. А среднее объединение возвращает среднее значение из всех значений покрытой ядром части.
Максимальное объединение также выполняет функцию шумоподавления. Оно полностью отбрасывает зашумленные активации, а также устраняет шум вместе с уменьшением размерности. С другой стороны, среднее объединение для подавления шума просто снижает размерность. Значит, можно сказать, что максимальное объединение работает намного лучше среднего объединения.
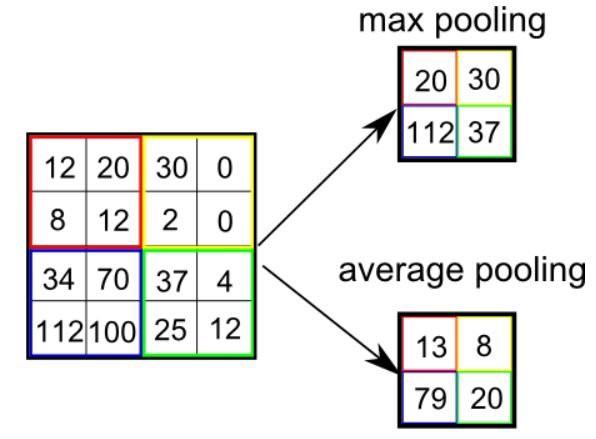 Типы объединения
Типы объединенияСлои объединения и свёртки вместе образуют i-тый слой свёрточной нейронной сети. Количество таких слоёв может быть увеличено в зависимости от сложности изображений, чтобы лучше схватывать детали, но это делается за счёт увеличения вычислительной мощности.
Выполнение процесса выше позволяет модели понимать особенности изображения. Преобразуем результат в столбцовый вектор и скормим его обычной классифицирующей нейронной сети.
Классификация — полносвязный слой

Добавление полносвязного слоя — это (обычно) вычислительно недорогой способ обучения нелинейным комбинациям высокоуровневых признаков, которые представлены на выходе слоя свёртки. Полносвязный слой изучает функцию в этом пространстве, которая может быть нелинейной.
После преобразования входного изображения в подходящую для многоуровневого перцептрона форму мы должны сгладить изображение в вектор столбец. Сглаженный выходной сигнал подаётся на нейронную сеть с прямой связью, при этом на каждой итерации обучения применяется обратное распространение. За серию эпох модель обретает способность различать доминирующие и некоторые низкоуровневые признаки в изображениях и классифицировать их методом классификации Softmax.
У CNN есть различные архитектуры, сыгравшие ключевую роль в построении алгоритмов, на которых стоит и в обозримом будущем будет стоять искусственный интеллект в целом. Некоторые из этих архитектур перечислены ниже:
LeNet;
AlexNet;
VGGNet;
GoogLeNet;
ResNet;
ZFNet.
Репозиторий с проектом по распознаванию цифр.
CNN имеет огромное количество практических приложений; и если вам интересны эксперименты и поиски в области ИИ, обратите внимание на наш курс о машинном и глубоком обучении или прокачайтесь в работе с данными или освойте перспективную специальность с помощью нашего флагманского курса о Data Science.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Другие профессии и курсыПРОФЕССИИ
КУРСЫ
