[Перевод] Надлежащая оценка производительности для диагностирования и устранения проблем, возникающих при .Net-сериализации
 Уважаемые читатели! Представляю вашему вниманию перевод статьи Скота Ханселмана под названием «Proper benchmarking to diagnose and solve a .NET serialization bottleneck».Для начала, несколько оговорок и комментариев. Во-первых, процесс оценки производительности сложен. Трудно выполнять измерения. Но настоящая проблема состоит в том, что часто мы забываем, ДЛЯ ЧЕГО мы оцениваем производительность чего-либо. Мы берем сложную многомашинную финансовую систему и внезапно чрезвычайно фокусируемся на куске кода, выполняющем сериализацию, который, по нашему убеждению, и ЕСТЬ проблема. «Если я смогу оптимизировать эту сериализацию, написав for-цикл из 10000 итерации и сократив время его выполнения на x миллисекунд, все будет путем».Во-вторых, это не пост с результатами сравнения производительности. Не ссылайтесь на него и не говорите «видишь! Библиотека X лучше библиотеки Y. Или .Net лучше чем Java!» Вместо этого, рассматривайте его как поучительную историю, а также набор общих рекомендаций. Я попросту использую эту историю, чтобы подчеркнуть следующее:
Уважаемые читатели! Представляю вашему вниманию перевод статьи Скота Ханселмана под названием «Proper benchmarking to diagnose and solve a .NET serialization bottleneck».Для начала, несколько оговорок и комментариев. Во-первых, процесс оценки производительности сложен. Трудно выполнять измерения. Но настоящая проблема состоит в том, что часто мы забываем, ДЛЯ ЧЕГО мы оцениваем производительность чего-либо. Мы берем сложную многомашинную финансовую систему и внезапно чрезвычайно фокусируемся на куске кода, выполняющем сериализацию, который, по нашему убеждению, и ЕСТЬ проблема. «Если я смогу оптимизировать эту сериализацию, написав for-цикл из 10000 итерации и сократив время его выполнения на x миллисекунд, все будет путем».Во-вторых, это не пост с результатами сравнения производительности. Не ссылайтесь на него и не говорите «видишь! Библиотека X лучше библиотеки Y. Или .Net лучше чем Java!» Вместо этого, рассматривайте его как поучительную историю, а также набор общих рекомендаций. Я попросту использую эту историю, чтобы подчеркнуть следующее:
Вы на 100% понимаете, что вы измеряете? Запускали ли вы профайлер типа Visual Studio profiler, ANTS или .dotTrace? Вы учитываете время разогрева? Отбрасываете резко выделяющиеся значения измерений? Ваши результаты статистически значимы? Оптимизированы ли используемые вами библиотеки под ваш сценарий использования? Вы уверены в том, что знаете, каков ваш сценарий использования? Одна плохая оценка производительностиОдин читатель недавно прислал мне e-mail с вопросами по сериализации в .Net. Ребята прочитали один очень старый пост 2009-го года о производительности, который включал графики и диаграммы, и самостоятельно провели какие-то тесты. Они зафиксировали, что время сериализации (десятков тысяч элементов) составляет более 700 миллисекунд, а объемы около 2-х мегабайт. В тесте выполнялась сериализация их типовых структур данных, как на C#, так и на Java, с помощью набора различных библиотек. Среди библиотек был собственный сериализатор их компании, бинарный .Net DataContract, а также JSON.NET. В одном случае сериализация давала малый объем данных (1,8МБ для большой структуры), в другом — работала быстро (94 мс.), но очевидного победителя не было. Читатель был на грани потери рассудка и решил, в каком-то смысле, что .Net не должен использоваться для решения их задачи.По-моему, с такой оценкой производительности что-то неладно. Не ясно, что измерялось. Не ясно, были ли измерения достоверны, а говоря конкретнее, универсальное заключение о том, что ».Net медленный» не было обоснованным, учитывая представленные данные.
Хм… То есть .Net не может сериализовать несколько десятков тысяч структур данных быстро? Я знаю, что может.
Смотрите также: Create benchmarks and results that have value и Responsible benchmarking от @Kellabyte
Я не эксперт, но все же немного поигрался с этим кодом.Первое: правильно ли мы измеряем? В тестах использовался DateTime.UtcNow, который не советуют использовать в таких случаях. startTime = DateTime.UtcNow; resultData = TestSerialization (foo); endTime = DateTime.UtcNow; Не используйте DateTime.Now или DateTime.Utc для измерений там, где нужна какая-либо точность. DateTime не имеет достаточной точности и возвращает время с погрешностью до 30 мс.DateTime представляет дату и время. Это не высокоточный таймер или секундомер.
Как говорит Eric Lippert:
Словом, «сколько времени?» и «как долго это продолжалось?» совершенно разные вопросы; не используйте средство, спроектированное чтобы ответить на один вопрос, для ответа на другой.
И как говорит Raymond Chen: Точность (precision) — не то же самое, что достоверность (accuracy). Достоверность — это то, насколько вы близки к правильному ответу; точность — насколько высоко разрешение (resolution) данного ответа.
Итак, мы будем использовать Stopwatch там, где нам нужен секундомер. До того как я перевел пример на Stopwatch, я получал значения в миллисекундах вроде 90,106,103,165,94, а после перевода на Stopwatch результаты были 99,94,95,95,94. Колебания значений стали значительно меньше. Stopwatch sw = new Stopwatch (); sw.Start (); // stuff sw.Stop (); Также, вам может потребоваться привязка процесса к одному ядру процессора, если вы пытаетесь получить достоверную оценку производительности. В то время, как это не должно иметь значения и Stopwatch использует Win32 QueryPerformanceCounter (исходный код для Stopwatch в .Net здесь), на старых системах имели место некоторые проблемы, если тест начинался на одном процессоре, а заканчивался на другом. // One Core var p = Process.GetCurrentProcess (); p.ProcessorAffinity = (IntPtr)1; Если вы не используете Stopwatch, поищите простую и хорошо приспособленную для оценки производительности библиотеку.Второе: считаем результаты В примере кода, который мне дали, около 10 строк содержали собственно измерения, и 735 строк — «инфраструктуру», отвечающую за сбор и отображение полученных данных. Возможно, вы уже видели подобное? Справедливо сказать, что оценка производительности может потеряться в «инфраструктуре».Послушайте мой недавний подкаст с Matt Warren на тему «Performance as a Feature» и взгляните на Matt’s performance blog, а также убедитесь, что воспользовались книгой Ben Watson под названием «Writing High Performance .NET Code».
Также имейте ввиду, что в настоящее время Matt экспериментирует с созданием компактной инфраструктуры для оценки производительности на GitHub. Эта система довольно многообещающая и могла бы свести процесс выполнения оценки к применению атрибута [Benchmark] непосредственно внутри модульных тестов.
Рассмотрите возможность использования существующих инфраструктур для простых оценок производительности. Одна из них SimpleSpeedTester от Yan Cui. Она делает приятные таблички и выполняет множество нудной работы для вас. Вот скриншоты, которые я украл одолжил в блоге Yan.
 Немного более продвинутое средство, на которое стоит взглянуть, это HdrHistogram, библиотека «разработанная для записи гистограмм измеряемых значений в приложениях, чувствительных к времени ожидания и производительности». Она также на GitHub и включает реализации на Java, C, и C#.
Немного более продвинутое средство, на которое стоит взглянуть, это HdrHistogram, библиотека «разработанная для записи гистограмм измеряемых значений в приложениях, чувствительных к времени ожидания и производительности». Она также на GitHub и включает реализации на Java, C, и C#.
 И серьезно. Используйте профайлер.
И серьезно. Используйте профайлер.
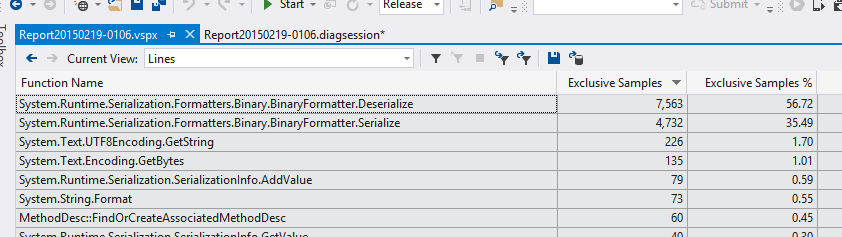
Третье: вы запускали профайлер? Используйте Visual Studio Profiler, или скачайте триал Redgate ANTS Performance Profiler или JetBrains dotTrace profiler.На что наше приложение тратит время? Думаю, мы все встречали людей, которые делали сложные тесты и изучали работу черного ящика вместо того, чтобы просто запустить профайлер.
 К слову: есть ли более новые/подходящие/изученные способы решения проблемы?
Это мое мнение, но я думаю, что оно заслуживает внимания и есть цифры, которые это доказывают. Часть кода, выполняющего сериализацию в .Net, довольно стара, написана в 2003 или 2005 году и может не использовать преимущества новых технологий и знаний. К тому же, это довольно гибкий, «подходящий для всех» код, в отличие от очень узкоспециализированного кода.У людей разные потребности, связанные с сериализацией. Вы не можете сериализовать нечто в XML и ожидать, что результат будет небольшим и компактным. Точно так же вы не можете сериализовать структуру в JSON и ждать, что это будет так же быстро, как при бинарной сериализации.
К слову: есть ли более новые/подходящие/изученные способы решения проблемы?
Это мое мнение, но я думаю, что оно заслуживает внимания и есть цифры, которые это доказывают. Часть кода, выполняющего сериализацию в .Net, довольно стара, написана в 2003 или 2005 году и может не использовать преимущества новых технологий и знаний. К тому же, это довольно гибкий, «подходящий для всех» код, в отличие от очень узкоспециализированного кода.У людей разные потребности, связанные с сериализацией. Вы не можете сериализовать нечто в XML и ожидать, что результат будет небольшим и компактным. Точно так же вы не можете сериализовать структуру в JSON и ждать, что это будет так же быстро, как при бинарной сериализации.
Измерьте свой код, проанализируйте свои требования, сделайте шаг назад и рассмотрите все варианты.
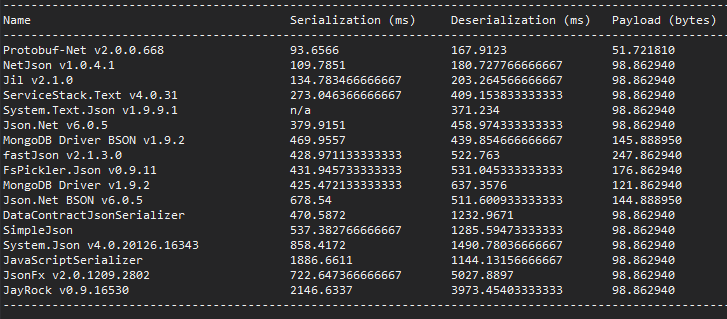
Четвертое: новые .Net-сериализаторы, которые стоит рассмотреть Теперь, когда у меня есть понимание того, что происходит и как измерять затраченное время, стало понятно, что все те сериализаторы не соответствовали целям нашего читателя. Некоторые, как я уже говорил, написаны давно. Так какие же существуют более продвинутые и современные варианты? Есть два действительно хороших сериализатора, на которые следует обратить внимание. Это Jil от Kevin Montrose, и protobuf-net от Marc Gravell. Оба являются удивительными, а широта охвата поддерживаемых фреймворков и система построения protobuf-net — просто загляденье. Существуют также другие впечатляющие сериализаторы, входящие в ServiceStack.NET и включающие поддержку не только JSON, но также и JSV и CSV.
Protobuf-net — protocol buffers для .NET Protocol buffers — это формат описания структур данных от Google, а protobuf-net — высокопроизводительная реализация protocol buffers под .NET. Представьте, что это XML, только компактнее и быстрее. Кроме того, с возможностью кросс-языковой сериализации. Вот, что указано на их сайте: Protocol buffers имеют множество преимуществ при сериализации структурированных данных, по сравнению с XML. Они:
проще
от 3 до 10 раз меньше
от 20 до 100 раз быстрее
более однозначны
генерируют классы доступа к данным (data access classes), которые проще использовать в программном коде
Добавить это было просто. Существует много способов декорировать ваши структуры данных, но по существу:
var r = ProtoBuf.Serializer.Deserialize
Также стоит отметить, что некоторые сериализаторы работают со строкой в памяти, в то время как другие, например Json.NET и DataContractSerializer, работают с потоком (stream). Это означает, что вам стоит принять во внимание размер того, что вы собираетесь сериализовать, когда выбираете библиотеку.Jil впечатляет многим, но особенно тем, что он динамически эмитит custom-сериализатор (как это делали когда-то делали XmlSerializer-ы).
Jil крайне прост в использовании. Он просто работает. Я добавил его в пример и он выполнил сериализацию за 84 мс.
result = Jil.JSON.Deserialize
»[Имеет место] мета-проблема, связанная со сравнением производительности. Микро-оптимизация и забота о производительности тогда, когда это не имеет значения, это то, чем грешат многие разработчики. Документация, производительность разработчиков и гибкость важнее, чем сотая доля миллисекунды.»
James указал на старую (но недавно исправленную) ошибку ASP.NET в Twitter. Это важная ошибка, влияющая на производительность, но она, тем не менее, меркнет в свете того времени, которое тратится на передачу данных по сети. Эта ошибка подтверждает мысль о том, что множество разработчиков заботятся о производительности тогда, когда это не имеет значения— James Newton-King (@JamesNK) 13 Февраля 2015 г.
Спасибо Marc Gravell и James Newton-King за их помощь при подготовке этого поста.Оригинал статьи доступен по этой ссылке
