[Перевод] Multi-Target в Albumentations

Этот текст — это перевод блог поста Multi-Target in Albumentations от 27 июля 2020. Автор есть на Хабре, но переводить текст на русский поленился. И этот перевод сделан по его просьбе.
Я перевела на русский все, что можно, но какие-то технические термины на английском звучат более естественно. В таком виде они и оставлены. Если вам в голову приходит адекватный перевод — комментируйте — поправлю.
Аугментации изображений — это интерпретируемый метод регуляризации. Вы преобразуете существующие размеченные данные в новые, тем самым увеличивая размер датасета.

Вы можете использовать Albumentations в PyTorch, Keras, Tensorflow или любом другом фреймворке, который может обрабатывать изображение как numpy array.
Лучше всего библиотека работает со стандартными задачами классификации, сегментации, детекции объектов и ключевых точeк. Чуть реже встречаются задачи, когда в каждом элементе тренировочной выборки не один, а множество различных объектов.
Для такого рода ситуаций была добавлена функциональность multi-target.
Ситуации, где это может пригодиться:
- Сиамские сети
- Обработка кадров в видео
- Задачи Image2image
- Multilabel semantic segmentation
- Instance segmentation
- Panoptic segmentation
Немного выпендрежа для привлечения внимания
- Библиотека родилась из топовых решений с Kaggle и других площадок соревновательного машинного обучения. В основной команде разработчиков один Kaggle Grandmaster, три Kaggle Masters, один Kaggle Expert.
- Селим Сефербеков, победитель конкурса Deepfake Challenge с призовыми в миллион долларов, использовал Albumentations в своем решении.
- Библиотека является частью PyTorch ecosystem
- 5700 звезд на GitHub.
- Библиотеку цитировали в научных статьях более 80 раз . Упоминали в трех книгах.
В течение последних трех лет мы работали над функциональностью и оптимизировали производительность.
Сейчас же мы сосредоточились на документации и туториалах.
Как минимум раз в неделю пользователи просят добавить поддержку преобразования для нескольких сегментационных масок.
Она у нас уже давно есть.
В этой статье мы поделимся примерами того, как работать с multiple targets в albumentations.
Сценарий 1: Одно изображение, одна маска
Наиболее распространенным вариантом использования является сегментация изображений. У вас есть изображение и маска. Вы хотите применить к ним набор пространственных преобразований, и это должен быть один и тот же набор.
В этом коде мы применяем HorizontalFlip и ShiftScaleRotate.
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(border_mode=cv2.BORDER_CONSTANT,
scale_limit=0.3,
rotate_limit=(10, 30),
p=0.5)
], p=1)
transformed = transform(image=image, mask=mask)
image_transformed = transformed['image']
mask_transformed = transformed['mask']
→ Ссылка на gistfile1.py

Сценарий 2: Одно изображение и несколько масок

Для некоторых задач у вас может быть несколько меток, соответствующих одному и тому же пикселю.
Давайте применим HorizontalFlip, GridDistortion, RandomCrop.
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.GridDistortion(p=0.5),
A.RandomCrop(height=1024, width=1024, p=0.5),
], p=1)
transformed = transform(image=image, masks=[mask, mask2])
image_transformed = transformed['image']
mask_transformed = transformed['masks'][0]
mask2_transformed = transformed['masks'][1]
→ Ссылка на gistfile1.py
Сценарий 3: Несколько изображений, масок, ключевых точек и боксов

Вы можете применить пространственные преобразования к нескольким целям.
В этом примере мы имеем два изображения, две маски, два бокса и два набора ключевых точек.
Давайте применим последовательность из HorizontalFlip и ShiftScaleRotate.
import albumentations as A
transform = A.Compose([A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(border_mode=cv2.BORDER_CONSTANT, scale_limit=0.3, p=0.5)],
bbox_params=albu.BboxParams(format='pascal_voc', label_fields=['category_ids']),
keypoint_params=albu.KeypointParams(format='xy'),
additional_targets={
"image1": "image",
"bboxes1": "bboxes",
"mask1": "mask",
'keypoints1': "keypoints"},
p=1)
transformed = transform(image=image,
image1=image1,
mask=mask,
mask1=mask1,
bboxes=bboxes,
bboxes1=bboxes1,
keypoints=keypoints,
keypoints1=keypoints1,
category_ids=["face"]
)
image_transformed = transformed['image']
image1_transformed = transformed['image1']
mask_transformed = transformed['mask']
mask1_transformed = transformed['mask1']
bboxes_transformed = transformed['bboxes']
bboxes1_transformed = transformed['bboxes1']
keypoints_transformed = transformed['keypoints']
keypoints1_transformed = transformed['keypoints1']
→ Ссылка на gistfile1.py

Q: Можно ли работать более чем с двумя изображениями?
А: Вы можете брать столько изображений, сколько захотите.
Q: Должно ли количество изображений, маски, боксов и ключевых точек быть одинаковым?
A: У вас может быть N изображений, M масок, K ключевых точек и B боксов. N, M, K и B могут быть разными.
Q: Существуют ли ситуации, когда функциональность multi target не сработает или сработает не так как ожидалось?
A: В целом, вы можете использовать multi-target для набора изображений, имеющих разные размеры. Некоторые преобразования зависит от входных данных. Например, вы не можете выполнить сделать crop, который больше самого изображения. Другой пример: MaskDropout, который может зависеть от исходной маски. Как он поведет себя, когда у нас будет набор масок, непонятно. На практике они встречаются крайне редко.
Q: Сколько преобразований можно сочетать вместе?
A: Вы можете сочетать преобразования в сложный пайплайн кучей разных способов.
В библиотеке более 30 пространственных преобразований. Все они поддерживают изображения и маски, большинство поддерживают боксы и ключевые точки.
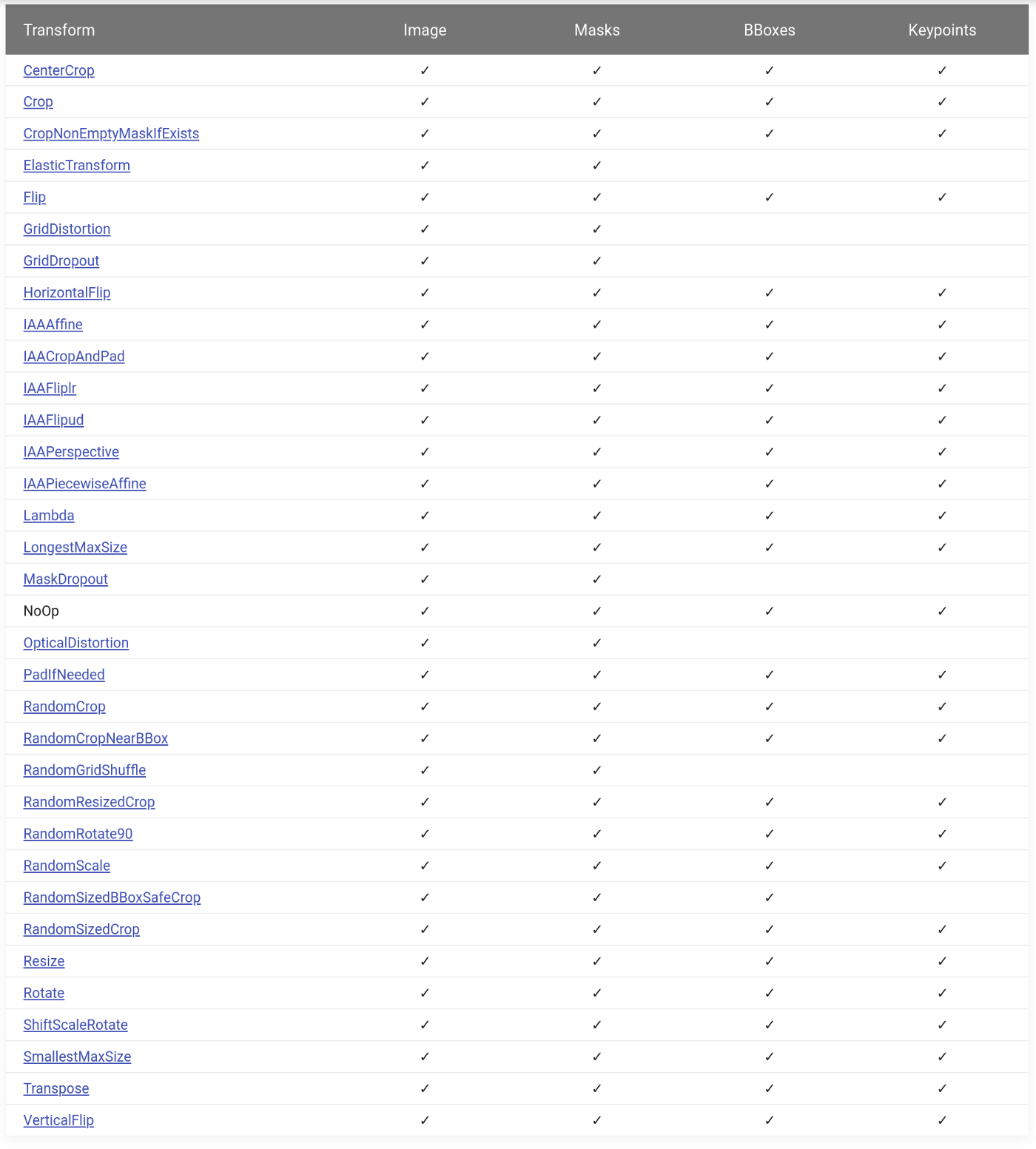
→ Ссылка на источник
Их можно сочитать с более чем 40 преобразованиями, которые изменяют значения пикселей изображения. Например: RandomBrightnessContrast, Blur, или что-то более экзотическое, например RandomRain.
Работа над open-source проектом сложная, но очень увлекательна. Я хотел бы поблагодарить команду разработчиков:
и всех контрибьюторов, которые помогли создать библиотеку библиотеку и довести ее до текущего уровня.
