[Перевод] Микросервисное безумие пройдет в 2018 году
Именно с таким тезисом выступил Дэйв Керр, статья которого собрала за месяц 90 комментариев, вызвала бурные дискуссии на Reddit и Hacker News, а нас заинтересовала настолько, что мы решили срочно ее перевести. Пользуясь случаем, поинтересуемся: хотите ли допечатку основополагающей книги Сэма Ньюмена «Создание микросервисов», которая в последний раз выходила у нас еще в 2016 году, либо скепсис господина Керра кажется вам обоснованным?
Читайте и комментируйте!
В последние пару лет тема микросервисов стала очень популярна. «Фанатизм» любителей микросервисов сводится примерно к такому силлогизму:
В Netflix замечательно устроена практика devops. Netfix занимается микросервисами. Следовательно: если я стану заниматься микросервисами, то преуспею в devops.
Есть примеры, когда микросервисные паттерны внедрялись ценой огромных усилий, причем, их сторонники не вполне понимали, каковы издержки этой работы, и так ли велика польза микросервисов при решении данной конкретной задачи.
Здесь я подробно опишу, что такое микросервисы, почему эта парадигма так привлекательна, и каковы основные вызовы, которые она перед вами ставит.
В финале я сформулирую несколько простых вопросов, на которые, вероятно, стоит ответить самому, размышляя –, а подходят ли микросервисы именно для вас?

Что такое микросервисы, и почему они так популярны?
Начнем с азов. Вот как можно реализовать гипотетическую платформу для совместного использования видео: сначала в виде монолита (единая большая структура), а затем в виде микросервисов:
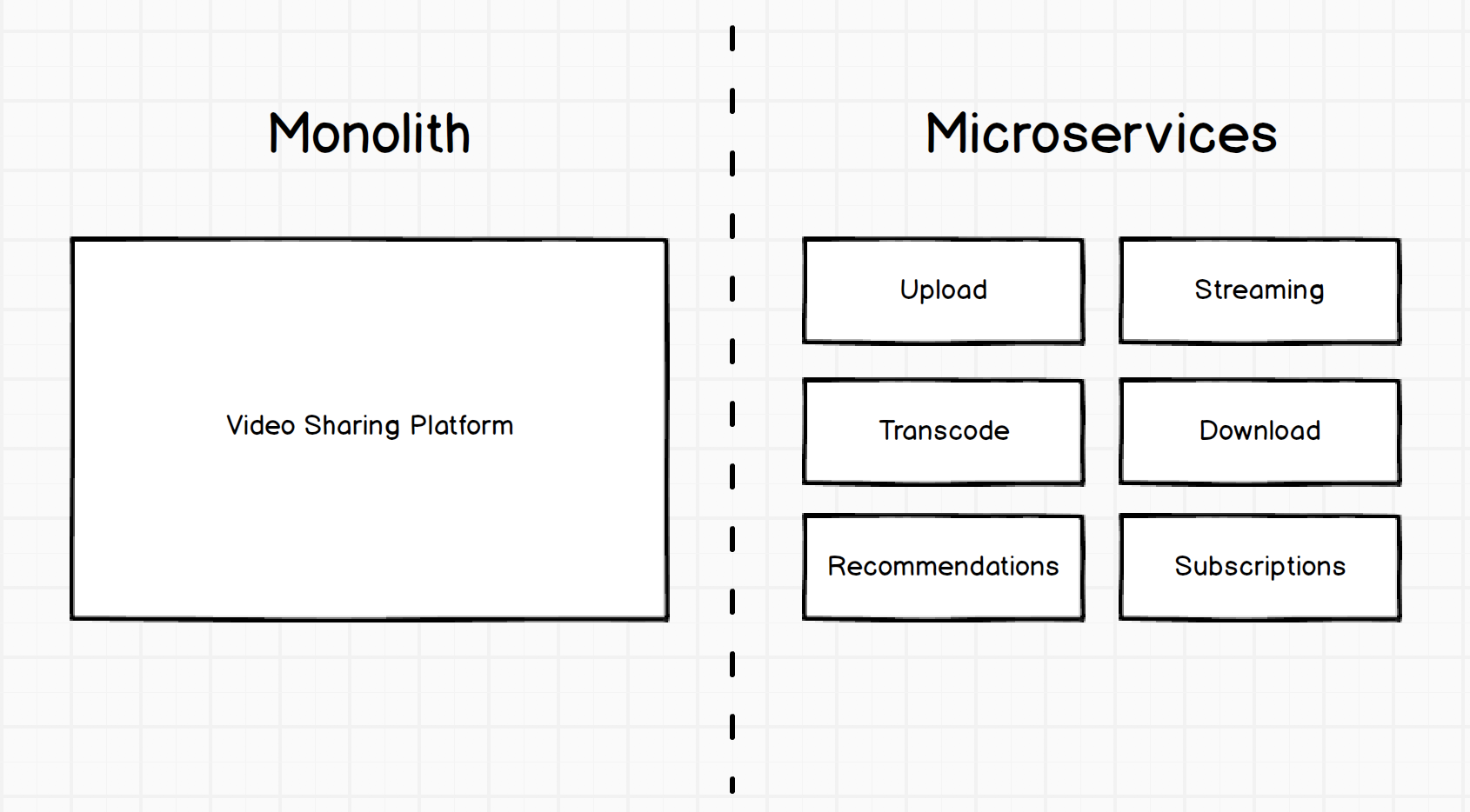
Разница заключается в том, что в первом случае мы имеем одну большую конструкцию, а во втором — набор маленьких специфичных сервисов. Каждый сервис играет конкретную роль.
Если начертить схему именно с такой детализацией — она, конечно, привлекательна. Сплошные потенциальные достоинства:
Независимая разработка: небольшие независимые компоненты можно создавать силами маленьких независимых команд. Группа может дорабатывать изменения в сервисе «Закачка», не вмешиваясь в разработку сервиса «Перекодировка» — или даже не зная о нем. Значительно сокращается время, требуемое для знакомства с компонентом, разрабатывать новые возможности легче.
Независимое развертывание: Каждый отдельный компонент можно развернуть независимо от остальных. Таким образом, новые фичи можно выкатывать быстрее, с меньшим риском. Если мы дорабатываем или фиксим компонент «Потоковое видео», то можем развертывать его по мере надобности, и развертывать другие компоненты нам для этого не требуется.
Независимая масштабируемость: Все компоненты можно масштабировать независимо друг от друга. В горячую пору, когда выходят новые шоу, компонент «Скачать» можно усилить, чтобы справиться с возросшей нагрузкой, и для этого не требуется наращивать все прочие компоненты. Эластичное масштабирование, оказывается, не так и сложно реализовать, стоимость разработки снижается.
Многократное использование: Каждый компонент выполняет небольшую специфическую функцию. Таким образом, их легко адаптировать для применения в других системах, сервисах или продуктах. Так, компонент «перекодировка» можно использовать в бизнес-элементах или даже превратить в новый компонент бизнес-логики, возможно, предоставляющий возможности перекодировки для других групп.
При таком приближении превосходство микросервисов над монолитом кажется очевидным. Итак, в чем же дело — почему эта парадигма совсем недавно в фаворе? Где она была раньше?
Если они такие классные, почему раньше никто ими не занимался?
На этот вопрос есть два ответа. Первый: занимались — насколько позволяли наши технические возможности. Второй: лишь новейшие технологические прорывы позволили вывести микросервисную технологию на новый уровень.
Когда я стал писать ответ на этот вопрос, у меня вышло длинное объяснение, поэтому я решил вынести его в отдельную статью и опубликовать попозже. На данном этапе я не буду описывать пути от одной программы ко многим, не буду останавливаться на ESB и сервис-ориентированной архитектуре, дизайне компонентов, ограниченных контекстах и т.д.
Те, кто заинтересовался, могут почитать об этом пути отдельно. Предпочту сказать, что, так или иначе, мы занимались этим ранее, но, благодаря недавнему всплеску популярности контейнерных технологий (в частности, Docker) и оркестрации (например, Kubernetes, Mesos, Consul и т.д.) такой паттерн стало гораздо проще реализовать с технической точки зрения.
Итак, если принять как данность, что мы действительно можем возвести микросервисную систему, то далее следует тщательно подумать —, а нужно ли? Теоретически в самом общем плане преимущества ясны, а какие вызовы при этом возникают?
Что за проблема с микросервисами?
Если микросервисы так великолепны, так в чем же дело? Вот некоторые из важнейших проблем, которые я вижу.
Задача разработчика усложняется
Для разработчика все может серьезно усложниться. Если программист желает разработать целую последовательность, либо фичу, потенциально охватывающую множество сервисов, то ему придется запускать их все на одной машине, либо подключаться к ним. Зачастую это гораздо сложнее, чем взять и запустить единственную программу.
Эта проблема частично решается при помощи соответствующего инструментария, но, по мере того, как количество сервисов в системе увеличивается, разработчику будет все сложнее запускать всю систему целиком.
Задачи операторов усложняются
Для команд, которые не разрабатывают сервисы, а поддерживают их, рост сложности может быть взрывным. Приходится управлять не несколькими сервисами, а несколькими десятками, сотнями или тысячами. Больше сервисов, больше путей коммуникации, больше потенциальных точек отказа.
Задачи devops усложняются
Возможно, кого-то покоробило, что в двух предыдущих пунктах эксплуатация и поддержка трактуются отдельно, особенно с учетом того, как популярна сегодня практика devops (кстати, я обеими руками за нее). Разве devops не решает этих проблем?
Проблема в том, что во многих организациях эксплуатация и поддержка — по-прежнему выполняются разными командами, и именно в такой организации переход на микросервисы, скорее всего, забуксует.
Для организаций, уже практикующих devops, все тоже сложно. Быть разработчиком и оператором одновременно уже тяжело (но необходимо, чтобы писать хорошие программы), но, если вдобавок требуется понимать нюансы систем оркестрации контейнеров, особенно таких систем, которые стремительно развиваются — крайне тяжело. Здесь я подхожу к следующему пункту.
Нужен серьезный опыт
Если такой работой занимаются эксперты, то результат может быть великолепен. Но представьте себе организацию, где и при эксплуатации единственной системы-монолита не все гладко. Назовите хоть одну причину, по которой дела могут наладиться, если в компании увеличится количество систем, а значит — и сложность их эксплуатации?
Да, при эффективной автоматизации, мониторинге, оркестрации и т.д. все это возможно. Но проблема обычно не в технологии, а в дефиците людей, способных эффективно ее использовать. Такие наборы навыков сегодня очень востребованы, и найти хорошего специалиста сложно.
В реальных системах границы между компонентами зачастую нечеткие
Во всех примерах, на которых демонстрировались достоинства микросервисов, мы говорили о независимых компонентах. Однако, зачастую они просто не являются независимыми. На бумаге некоторые предметные области могут казаться четко очерченными, но, стоит углубиться в частности — и окажется, что проблема сложнее, чем вы предполагали.
Вот здесь все может стать совсем сложно. Если границы компонентов в вашей системе определены нечетко, то происходит вот что: хотя, теоретически, сервисы и можно развертывать независимо друг от друга, на практике оказывается, что они связаны взаимными зависимостями, и поэтому приходится развертывать набор сервисов как целую группу.
Это означает, что приходится управлять согласованными версиями сервисов, то есть, сервисами, надежность которых доказана, взаимодействия проверены. Но в таком случае речь уже не идет о независимо развертываемой системе, поскольку для разработки новой фичи требуется тщательно оркестровать одновременное развертывание множества сервисов.
Часто игнорируются сложности, связанные с состоянием
В предыдущем примере я упоминал, что для развертывания фич может потребоваться одновременно выкатывать множество версий разных сервисов единой группой. Тянет предположить, что эта проблема снимается, если применяешь толковые приемы развертывания, например, голубые/зеленые варианты развертывания (что без особых усилий делается на большинстве оркестровочных платформ), либо при параллельной эксплуатации нескольких версий сервиса — при этом потребляющие каналы сами определяют, какую версию использовать.
Такие приемы позволяют снять множество проблем, если сервисы не сохраняют состояния. Но, честно говоря, и работать с такими сервисами просто. На самом деле, если вы работаете с сервисами, не сохраняющими состояния, лучше вообще не связываться с микросервисной конфигурацией и сразу попробовать бессервисную модель.
На самом деле, многие сервисы требуют сохранять состояние. Продолжая пример с нашей платформой для обмена видео, примером такого сервиса на ней может быть подписка. Новые версии сервиса подписки могут хранить информацию в подписочной базе данных в разной конфигурации. Если вы эксплуатируете оба сервиса параллельно, то в вашей системе одновременно работает две схемы. Если вы реализуете зеленое/голубое развертывание, а другие сервисы зависят от данных, оформленных в этой новой конфигурации, то обновлять их нужно одновременно. Если же развернуть сервис подписки не удается и приходится идти на откат, то, возможно, потребуется откатить и все зависимые сервисы, что может обернуться лавинообразными последствиями.
Опять же, тянет предположить, что при использовании NoSQL-баз данных такие проблемы со схемами исчезают —, но это не так. Базы данных, не навязывающие конкретной схемы, не порождают бессхемных систем — просто управление такой схемой обычно реализуется на уровне приложения, а не на уровне базы данных. Ключевая проблема в данном случае — понимать конфигурацию ваших данных, как они развиваются. От нее никуда не уйти.
Часто игнорируются сложности, связанные с коммуникацией
При выстраивании обширной сети взаимозависимых сервисов вполне вероятно, что придется обеспечивать активную коммуникацию между ними. Здесь возникает еще несколько проблем. Во-первых, значительно увеличивается количество потенциальных точек отказа. Следует учитывать, что некоторые сетевые вызовы не пройдут, и это означает, что, когда один сервис вызывает другой, он должен быть запрограммирован на какое-то минимальное количество попыток.
Теперь, когда сервис потенциально может вызывать множество других сервисов, мы оказываемся в сложной ситуации.
Допустим, пользователь загружает на нашу видеоплатформу новое видео. Нам нужно запустить сервис закачки, передать данные сервису перекодировки, обновить подписки, обновить рекомендации и т.д. Все эти вызовы в той или иной степени требуют оркестрации, а если вызов не пройдет — нужно попытаться выполнить его еще раз.
Такая логика повторных попыток может стать сложноуправляемой. Синхронное выполнение операций часто оказывается неосуществимым, поскольку потенциальных точек отказа слишком много. В данном случае наиболее разумно организовать коммуникацию с применением асинхронных паттернов. Самое сложное в данном случае, что система с асинхронной коммуникацией по определению требует выстраивания системы с сохранением состояния. Как я упоминал в предыдущем пункте, управлять системами с сохранением состояния и с распределенными состояниями очень сложно.
Если коммуникация между сервисами микросервисной системе осуществляется при помощи очередей сообщений, у нас, в сущности, возникает большая база данных (очередь сообщений или брокер), «склеивающая» эти сервисы. Опять же, на первый взгляд такая система может и не казаться проблематичной, но впоследствии аукнется вам. Сервис в версии X может записать сообщение в определенном формате, и другие сервисы, зависящие от этого сообщения, также потребуется обновить, если сервис-отправитель изменит детали отсылаемого им сообщения.
Можно написать такие сервисы, которые смогут обрабатывать сообщения во множестве разных форматов, но управлять такими сервисами будет тяжело. В таком случае при развертывании новых версий сервисов возможны ситуации, когда разные сервисы пытаются обрабатывать сообщения из одной очереди, возможно, даже переданные различными версиями сервиса-отправителя. Тогда могут возникать сложные пограничные случаи. Во избежание их может быть проще допустить существование лишь определенных версий сообщений: то есть, разворачивать набор версий некоторого множества сервисов как согласованное целое и гарантировать, что устаревшие версии сообщений будут отбрасываться в первую очередь.
Здесь, опять же, можно убедиться, что на практике независимое развертывание организуется не так просто, если присмотреться к деталям.
Версионирование может быть сложным
Чтобы частично снять вышеупомянутые проблемы, нужно очень аккуратно управлять версионированием. Опять же, зачастую кажется, что если придерживаться стандарта вроде semserver, то такая проблема решаема. Нет, не решается. Придерживаться Semserver разумно, но все равно придется отслеживать версии сервисов и API, смотреть, какие из них могут взаимодействовать.
Такие проблемы могут очень быстро крайне осложниться, и дойти до такой точки, когда вы уже сами не будете представлять, какие сервисы нормально взаимодействуют друг с другом.
Печально известно, как сложно бывает управлять зависимостями в системе, состоящей из модулей Java, библиотек C и т.п. Сложности с конфликтами между независимыми компонентами, потребляемыми конкретным объектом, решаются очень тяжело.
Они сложны, даже если зависимости статичны — и их можно патчить, обновлять, редактировать и т.д.; но, если сами зависимости являются живыми сервисами, то их уже, вероятно, невозможно просто обновить; придется гонять сразу множество версий (сопутствующие сложности описаны выше), либо останавливать систему, пока она не будет полностью обновлена и заново зафиксирована.
Распределенные транзакции
В ситуациях, когда требуется сохранять целостность транзакций в пределах всей операции, микросервисы могут стать настоящей головной болью. Работать с распределенным состоянием сложно, оркестровка множества мелких модулей, каждый из которых может отказать — та еще задача.
Можно попытаться обойти эту проблему, сделав операции идемпотентными, предусмотрев возможность повторных попыток и т.д., во многих случаях это сработает. Но возможны сценарии, когда нам потребуется реализовать всего два исхода транзакции — «удалась» или «не удалась», а промежуточное состояние не предусматривать. Цена такого маневра или попытка реализовать такую систему при помощи микросервисов может быть очень высока.
Микросервисы могут быть замаскированным монолитом
Да, одиночные сервисы и компоненты могут развертываться по отдельности, но в большинстве случаев придется задействовать какую-либо оркестровочную платформу, например, Kubernetes. Если вы пользуетесь управляемым сервисом, например, GKE от Google или EKS от Amazon, то сложное управление кластером в значительной степени удастся автоматизировать.
Однако, если вы управляете кластером сами, то имеете дело с крупной, сложной системой, отказы в которой недопустимы. Да, отдельный сервис может обладать всеми вышеописанными достоинствами, но управлять кластером нужно будет очень осторожно. Развертывать такую систему может быть сложно, обновлять — сложно, восстанавливать после отказа — сложно и т.д.
Зачастую принципиальные преимущества никуда не деваются, но здесь важно не упрощать систему и не недооценивать дополнительные сложности, связанные с управлением еще одной крупной и сложной системой. Да, могут пригодиться управляемые сервисы, но многие из них только-только появились (например, Amazon EKS появился лишь в конце 2017 года).
Напоследок: не путайте микросервисы с архитектурой
Я специально старался не употреблять в этой статье слова на букву «а». Но мой друг Золтан, вычитывавший эту статью (мы написали ее в соавторстве), подметил очень важную вещь.
Микросервисной архитектуры не существует. Микросервисы — просто еще один принцип реализации компонентов, ни больше, ни меньше. Присутствие или отсутствие микросервисов в системе еще не означает, что ее архитектурные проблемы решены.
Во многих отношениях микросервисы скорее связаны с упаковкой и эксплуатацией, а не с проектированием системы как таковым. При инженерии таких систем одной из важнейших задач остается грамотное разграничение компонентов.
Независимо от того, какого размера ваши сервисы, упакованы они в контейнеры Docker или нет — всегда важно задумываться о том, как сложить систему из элементов. Однозначного ответа не существует, вариантов всегда много.
