[Перевод] Методика разработки высоконадёжных серверов на Go
Время от времени перед веб-программистами встают задачи, способные нагнать страху даже на профессионалов. Речь идёт о разработке серверных приложений, которые не имеют права на ошибку, о проектах, в которых стоимость сбоя чрезвычайно высока. Автор материала, перевод которого мы сегодня публикуем, расскажет о том, как подходить к решению таких задач.

Какой уровень надёжности нужен вашему проекту?
Прежде чем углубляться в детали разработки высоконадёжных серверных приложений, вам стоит задаться вопросом о том, действительно ли вашему проекту нужен максимально достижимый уровень надёжности. Процесс разработки систем, рассчитанных на сценарии работы, в которых ошибка сродни вселенской катастрофе, может оказаться неоправданно сложным для большинства проектов, в которых последствия возможных ошибок не особенно страшны.
Если стоимость ошибки не оказывается чрезвычайно высокой, приемлем подход, при реализации которого разработчик прилагает максимально разумные усилия для обеспечения работоспособности проекта, а при возникновении проблемных ситуаций просто с ними разбирается. Современные средства мониторинга и рабочие процессы непрерывного развёртывания ПО позволяют быстро выявлять проблемы в продакшне и практически моментально их исправлять. Во многих случаях этого вполне достаточно.
В проекте, над которым я сегодня работаю, это не так. Речь идёт о реализации блокчейна — распределённой серверной инфраструктуры для безопасного выполнения кода в среде с низким уровнем доверия при достижения консенсуса. Одно из применений этой технологии — цифровые валюты. Это — классический пример системы с чрезвычайно высокой стоимостью ошибки. В данном случае разработчикам проекта действительно нужно сделать так, чтобы он был очень и очень надёжным.
Однако, и в некоторых других проектах, даже если они не имеют отношения к финансам, стремление к высочайшей надёжности кода имеет смысл. Стоимость обслуживания часто ломающейся кодовой базы очень быстро способна достичь астрономических величин. Возможность идентифицировать проблемы на ранних этапах процесса разработки, когда стоимость их устранения всё ещё невысока, выглядит как вполне реальное вознаграждение за своевременные вложения сил и времени в методологию разработки высоконадёжных систем.
Возможно, решение — это TDD?
Разработку через тестирование (Test Driven Development, TDD), часто считают лучшим лекарством от сбойного кода. TDD — это пуристическая методология разработки, при применении которой сначала пишут тесты, а уже потом — код, который добавляется в проект лишь тогда, когда тесты, которые его проверяют, перестают выдавать ошибки. Этот процесс гарантирует 100% покрытие кода тестами и часто даёт иллюзию того, что код протестирован во всех возможных вариантах его использования.
Однако, это не так. TDD — отличная методология, которая хорошо работает в некоторых областях, но, для разработки по-настоящему надёжного кода, лишь её недостаточно. Ещё хуже то, что TDD внушает разработчику ложную уверенность и применение этой методологии может привести к тому, что он попросту не станет, из лености, писать тесты для проверки системы на сбои в ситуациях, возникновение которых, с точки зрения здравого смысла, практически невозможно. Мы поговорим об этом позже.
Тесты — ключ к надёжности
На самом деле, неважно — создаёте ли вы тесты до того, как пишите код, или после, используете ли методологию разработки вроде TDD, или нет. Главное — это сам факт наличия тестов. Тесты представляют собой самое лучшее оборонительное укрепление, которое защищает ваш код от проблем в продакшне.
Так как мы собираемся запускать наши тесты очень часто, в идеале — после добавления в код каждой новой строки, необходимо, чтобы тесты были бы автоматизированными. Наша уверенность в качестве кода никоим образом не должна основываться на его ручных проверках. Всё дело в том, что людям свойственно ошибаться. Внимание человека к деталям ослабевает после того, как он выполнит одну и ту же однообразную задачу много раз подряд.
Тесты должны быть быстрыми. Очень быстрыми.
Если выполнение набора тестов занимает больше нескольких секунд, разработчики, вероятнее всего, начнут лениться, будут добавлять код в проект, не тестируя его. Скорость — это одна из сильнейших сторон Go. Набор инструментов для разработки на этом языке является одним из самых быстрых среди существующих. Компиляция, перестроение и тестирование проектов выполняются за считанные секунды.
Тесты, кроме того, являются одной из важных движущих сил опенсорсных проектов. Например, это относится ко всему тому, что связано с блокчейн-технологиями. Опенсорс здесь — это почти что религия. Кодовая база для того, чтобы добиться доверия к ней у тех, кто будет ей пользоваться, должна быть открытой. Это позволяет, например, проводить её аудит, это создаёт атмосферу децентрализованности, в которой нет неких сущностей, контролирующих проект.
Нет смысла ждать значительного вклада в опенсорсный проект от внешних разработчиков, если этот проект не будет включать в себя качественные тесты. Внешним участникам проекта нужны механизмы, позволяющие быстро проверить совместимость того, что они написали, с тем, что уже добавлено в проект. Весь набор тестов, на самом деле, должен выполняться автоматически при поступлении каждого запроса на добавление нового кода в проект. Если то, что предполагается добавить в проект посредством подобного запроса, что-то ломает, тест должен тут же об этом сообщить.
Полное покрытие кодовой базы тестами — это обманчивая, но важная метрика. Цель достижения 100% покрытия кода тестами может показаться чрезмерной, но, если об этом поразмыслить, окажется, что при неполном покрытии кода тестами некоторая часть кода отправляется в продакшн непроверенной, ранее никогда не выполнявшейся.
Полное покрытие кода тестами не обязательно означает, что в проекте имеется достаточно тестов, и не означает, что это — тесты, которые предусматривают абсолютно все варианты использования кода. С уверенностью можно говорить лишь о том, что если проект покрыт тестами не на 100%, у разработчика не может быть уверенности в абсолютной надёжности кода, так как некоторые части кода никогда не тестируются.
Несмотря на вышесказанное, встречаются ситуации, когда тестов слишком много. В идеале, каждая возможная ошибка должна приводить к отказу одного теста. Если число тестов избыточно, то есть, разные тесты проверяют одни и те же фрагменты кода, то модификация существующего кода и изменение существующего поведения системы приведут к тому, что для того, чтобы имеющиеся тесты соответствовали новому коду, придётся потратить слишком много времени на их переработку.
Почему Go — это отличный выбор для высоконадёжных проектов?
Go является языком со статической типизацией. Типы — это контракт между различными фрагментами кода, выполняющимися совместно. Без автоматической проверки типов в процессе сборки проекта, если нужно придерживаться строгих правил покрытия кода тестами, нам пришлось бы реализовывать тесты, проверяющие эти «контракты» самостоятельно. Так, например, происходит в серверных и клиентских проектах, основанных на JavaScript. Написание сложных тестов, направленных лишь на то, чтобы проверить типы, означает массу дополнительной работы, которой, в случае с Go, можно избежать.
Go — простой и догматичный язык. Как известно, Go включает в себя множество традиционных для языков программирования идей, вроде классического ООП-наследования. Сложность — худший враг надёжного кода. Проблемы имеют тенденцию прятаться на стыках соединений сложных конструкций. Выражается это в том, что хотя типичные варианты использования некоей конструкции протестировать просто, существуют причудливые пограничные случаи, о которых разработчик тестов может даже и не подумать. Проект, в итоге, повалит именно один из таких случаев. В этом смысле догматизм — это тоже полезно. В Go нередко существует лишь один способ выполнить какое-то действие. Это может показаться фактором, сдерживающим свободный дух программиста, но, когда нечто можно сделать лишь одним способом, это нечто сложно сделать неправильно.
Go лаконичен, но выразителен. Читабельный код легче проанализировать и подвергнуть аудиту. Если код слишком многословен, его основная цель может утонуть в «шуме» вспомогательных конструкций. Если же код слишком лаконичен, программы на нём могут оказаться сложными для чтения и понимания. Go поддерживает баланс между лаконичностью и выразительностью. Например, в нём не так много вспомогательных конструкций, как в таких языках, как Java или C++. При этом конструкции Go, относящиеся, например, к таким областям, как обработка ошибок, являются весьма ясными и достаточно подробными, что упрощает работу программиста, помогая ему убедиться, например, в том, что он проверил всё, что можно.
В Go имеются чёткие механизмы обработки ошибок и восстановления работоспособности программ после сбоев. Хорошо отлаженные механизмы обработки ошибок времени выполнения — это краеугольный камень высоконадёжного кода. В Go имеются строгие правила, определяющие возврат и распространение ошибок. В средах вроде Node.js смешение таких подходов к управлению потоком выполнения программы, как коллбэки, промисы и асинхронные функции, часто ведёт к появлению необработанных ошибок, вроде необработанного отклонения промиса. Восстановление работы программы после подобных событий практически невозможно.
В Go имеется обширная стандартная библиотека. Зависимости — это риск, особенно, когда их источником являются проекты, в которых недостаточно внимания уделяется надёжности кода. Серверное приложение, которое уходит в продакшн, содержит в себе и все зависимости. При этом, если что-то пойдёт не так, отвечать за это будет разработчик готового приложения, а не тот, кто создал одну из используемых им библиотек. Как результат, в средах, проекты, написанные для которых, переполнены мелкими зависимостями, сложнее создавать надёжные приложения.
Зависимости — это ещё и риск с точки зрения безопасности, так как уровень уязвимости проекта соответствует уровню уязвимости его самой небезопасной зависимости. Обширная стандартная библиотека Go поддерживается её разработчиками в очень хорошем состоянии, её существование снижает потребность во внешних зависимостях.
Высокая скорость разработки. Основная привлекательная черта окружений вроде Node.js — это чрезвычайно короткий цикл разработки. Написание кода занимает меньше времени, в результате программист становится более продуктивным.
Для Go также характерна высокая скорость разработки. Набор инструментов для сборки проектов достаточно быстр для того, чтобы можно было мгновенно посмотреть на код в действии. Время компиляции чрезвычайно мало, в результате запуск кода на Go воспринимается так, будто он не компилируется, а интерпретируется. При этом язык имеет достаточно абстракций, вроде системы сборки мусора, что позволяет разработчикам направлятьусилия на реализации функционала их проекта, а не на решении вспомогательных задач.
Практический эксперимент
Теперь, когда мы озвучили достаточно общих положений, пришло время взглянуть на код. Нам нужен пример, который достаточно прост для того, чтобы мы, изучая его, могли бы сосредоточиться на методологии разработки, но, в то же время, он должен быть достаточно продвинутым для того, чтобы нам, исследуя его, было о чём говорить. Я решил, что легче всего будет взять что-то из того, чем я ежедневно занимаюсь. Поэтому предлагаю разобрать создание сервера, который обрабатывает нечто, напоминающее финансовые транзакции. Пользователи этого сервера смогут проверять балансы счетов, связанных с их учётными записями. Кроме того, они смогут переводить средства с одного счёта на другой.
Мы постараемся не усложнять этот пример. В нашей системе будет один сервер. Мы не будем связываться с системами аутентификации и криптографии. Это — неотъемлемые составные части рабочих проектов. Нам же нужно сосредоточиться на ядре такого проекта, показать, как сделать его настолько надёжным, насколько это возможно.
▍Разбиение сложного проекта на части, которыми удобно управлять
Сложность — это худший враг надёжности. Один из лучших подходов при работе со сложными системами заключается в применении давно известного принципа «разделяй и властвуй». Задачу нужно разбить на маленькие подзадачи и решать каждую из них по отдельности. С какой стороны подойти к разбиению нашей задачи? Мы будем следовать принципу разделения ответственности. У каждой части нашего проекта должна быть собственная сфера ответственности.
Эта идея отлично согласуется с популярной архитектурой микросервисов. Наш сервер будет состоять из отдельных сервисов. У каждого сервиса будет чётко определённая сфера ответственности и чётко описанный интерфейс для взаимодействия с другими сервисами.
После того, как мы структурируем подобным образом сервер, мы сможем принимать решения о том, как должен работать каждый из сервисов. Все сервисы можно выполнять вместе, в одном и том же процессе, из каждого из них можно сделать отдельный сервер и наладить их взаимодействие с использованием RPC, можно разделить сервисы и выполнять каждый из них на отдельном компьютере.
Не станем переусложнять задачу, выберем простейший вариант. А именно, все сервисы будут выполняться в одном и том же процессе, они будут обмениваться информацией напрямую, как библиотеки. При необходимости, в будущем это архитектурное решение можно будет без проблем пересмотреть и изменить.
Итак, какие сервисы нам нужны? Наш сервер, пожалуй, слишком прост для того, чтобы делить его на части, но, в учебных целях, мы его, всё же, его разделим. Нам нужно отвечать на HTTP-запросы клиентов, направленные на проверку балансов и выполнение транзакций. Один из сервисов может работать с HTTP-интерфейсом для клиентов. Назовём его PublicApi. Ещё один сервис будет владеть информацией о состоянии системы — журналом балансов. Назовём его StateStorage. Третий сервис будет соединять два вышеописанных и реализовывать логику «контрактов», направленную на изменение балансов. Задачей третьего сервиса будет выполнение контрактов. Назовём его VirtualMachine.
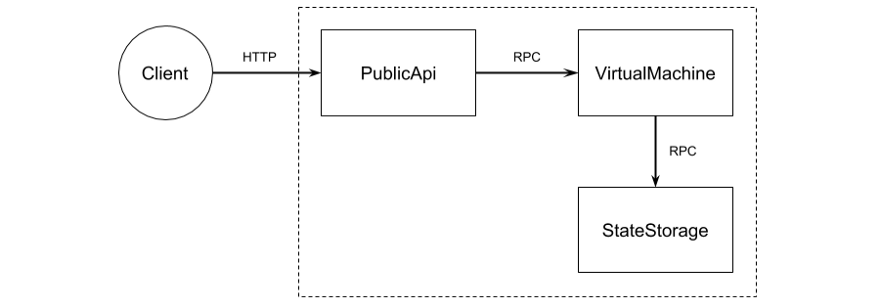
Архитектура серверной части приложения
Разместим код этих сервисов в папках проекта /services/publicapi, /services/virtualmachine и /services/statestorage.
▍Чёткое определение границ ответственности сервисов
В ходе реализации сервисов мы хотим иметь возможность работать с каждым из них по отдельности. Возможно, даже разделить разработку этих сервисов между разными программистами. Так как сервисы взаимозависимы, и мы хотим распараллелить их разработку, нам нужно начать работу с чёткого определения интерфейсов, которые они используют для взаимодействия друг с другом. Используя эти интерфейсы, мы сможем автономно протестировать сервисы, подготовив заглушки для всего того, что находится за пределами каждого из них.
Как описать интерфейс? Один из вариантов — всё задокументировать, но у документации есть свойство устаревать, в процессе работы над проектом между документацией и кодом начинают накапливаться расхождения. Кроме того, мы можем использовать объявления интерфейсов Go. Это интересный вариант, но лучше описать интерфейс так, чтобы это описание не зависело от конкретного языка программирования. Это пригодится нам во вполне реальной ситуации, если в процессе работы над проектом некоторые составляющие его сервисы будет решено реализовать на других языках, возможности которых лучше подходят для решения их задач.
Один из вариантов описания интерфейсов — воспользоваться protobuf. Это — простой протокол описания сообщений и конечных точек сервисов, разработанный Google и не зависящий от языка.
Начнём с интерфейса для сервиса StateStorage. Состояние приложения мы представим в виде структуры вида ключ-значение. Вот код файла statestorage.proto:
syntax = "proto3";
package statestorage;
service StateStorage {
rpc WriteKey (WriteKeyInput) returns (WriteKeyOutput);
rpc ReadKey (ReadKeyInput) returns (ReadKeyOutput);
}
message WriteKeyInput {
string key = 1;
int32 value = 2;
}
message WriteKeyOutput {
}
message ReadKeyInput {
string key = 1;
}
message ReadKeyOutput {
int32 value = 1;
}
Хотя с сервисом PublicApi клиенты работают по HTTP, ему тоже не помешает чёткий интерфейс, описанный теми же средствами, что и выше (файл publicapi.proto):
syntax = "proto3";
package publicapi;
import "protocol/transactions.proto";
service PublicApi {
rpc Transfer (TransferInput) returns (TransferOutput);
rpc GetBalance (GetBalanceInput) returns (GetBalanceOutput);
}
message TransferInput {
protocol.Transaction transaction = 1;
}
message TransferOutput {
string success = 1;
int32 result = 2;
}
message GetBalanceInput {
protocol.Address from = 1;
}
message GetBalanceOutput {
string success = 1;
int32 result = 2;
}
Теперь нам понадобится описать структуры данных Transaction и Address (файл transactions.proto):
syntax = "proto3";
package protocol;
message Address {
string username = 1;
}
message Transaction {
Address from = 1;
Address to = 2;
int32 amount = 3;
}
В проекте proto-описания для сервисов помещены в папке /types/services, а описания структур данных общего назначения — в папке /types/protocol.
После того, как описания интерфейсов будут готовы, их можно скомпилировать в код на Go.
Преимущества такого подхода заключаются в том, что код, который не соответствует описанию интерфейса, просто не окажется в результатах компиляции. Использование альтернативных методов потребовало бы от нас написания специальных тестов для проверки соответствия кода описаниям интерфейсов.
Полные определения, сгенерированные Go-файлы и инструкции компиляции можно найти здесь. Это возможно благодаря Square Engineering и их разработке goprotowrap.
Обратите внимание на то, что в нашем проекте не реализован транспортный уровень RPC и обмен данными между сервисами выглядит как обычные вызовы библиотек. Когда мы будем готовы к тому, чтобы разнести сервисы по разным серверам, мы можем добавить в систему транспортный уровень вроде gRPC.
▍Типы тестов, используемых в проекте
Так как тесты являются ключом к высоконадёжному коду, предлагаю сначала поговорить о том, какие тесты для нашего проекта мы будем писать.
Модульные тесты
Модульные тесты — это основа пирамиды тестирования. Мы будем тестировать каждый модуль в изоляции. Что такое модуль? В Go мы можем воспринимать модули в виде отдельных файлов в пакете. Например, если у нас имеется файл /services/publicapi/handlers.go, то модульный тест для него мы разместим в том же пакете по адресу /services/publicapi/handlers_test.go.
Лучше всего размещать модульные тесты в том же пакете, в котором находится тестируемый код, что позволит тестам иметь доступ к неэкспортируемым переменным и функциям.
Сервисные тесты
Следующий тип тестов известен под различными названиями. Это — так называемые сервисные, интеграционные или компонентные тесты. Их сущность заключается в том, чтобы взять несколько модулей и протестировать их совместную работу. Эти тесты находятся на уровень выше модульных в пирамиде тестирования. В нашем случае мы будем применять интеграционные тесты для проверки всего сервиса. Эти тесты определяют спецификации для сервиса. Например, тесты для сервиса StateStorage будут помещены в папку /services/statestorage/spec.
Лучше всего размещать эти тесты в пакете, отличающемся от того, в котором находится тестируемый код для того, чтобы доступ к возможностям этого кода осуществлялся только через экспортируемые интерфейсы.
Сквозные тесты
Эти тесты находятся на вершине пирамиды тестирования, с их помощью выполняется проверка всей системы и всех её сервисов. Такие тесты описывают сквозную (end-to-end, e2e) спецификацию для системы, поэтому мы разместим их в папке /e2e/spec.
Сквозные тесты, как и сервисные, нужно разместить в пакете, отличном от того, в котором расположен тестируемый код для того, чтобы работа с системой осуществлялась только через экспортируемые интерфейсы.
Какие тесты надо написать первыми? Начать с фундамента «пирамиды» и двигаться вверх? Или начать сверху и спускаться вниз? Любой из этих подходов имеет право на жизнь. Преимущества подхода «сверху вниз» заключаются в первоочередном создании спецификации для всей системы. Обычно легче всего в самом начале работы рассуждать об особенностях системы как единого целого. Даже если мы разделим систему на отдельные сервисы неправильно, системные спецификации останутся неизменными. Это, кроме того, поможет нам понять, что что-то, на более низком уровне, сделано неверно.
Минус подхода «сверху вниз» заключается в том, что сквозные тесты — это те тесты, которые используются после всех остальных, тогда, когда будет создана вся разрабатываемая система. Это означает, что они будут выдавать ошибки в течение длительного времени. Мы, при написании тестов для нашего проекта, будем пользоваться именно этим подходом.
▍Разработка тестов
Разработка сквозных тестов
Прежде чем создавать тесты, нам надо решить, будем ли мы писать их без применения вспомогательных средств или воспользуемся каким-нибудь фреймворком. Полагаться на фреймворк, используя его как зависимость разработки, менее опасно, чем полагаться на фреймворк в коде, который попадёт в продакшн. В нашем случае, так как стандартная библиотека Go не имеет достойной поддержки BDD, а этот формат отлично подходит для описания спецификаций, мы выберем вариант работы, предусматривающий использование фреймворка.
Существует немало отличных фреймворков, дающих то, что нам надо. Среди них — GoConvey и Ginkgo.
Лично мне нравится использовать сочетание Ginkgo и Gomega (ужасные названия, но что поделать), которые используют синтаксические конструкции вроде Describe() и It().
Как же будут выглядеть наши тесты? Например — вот тест для механизма проверки баланса пользователя (файл sanity.go):
package spec
import ...
var _ = Describe("Sanity", func() {
var (
node services.Node
)
BeforeEach(func() {
node = services.NewNode()
node.Start()
})
AfterEach(func() {
node.Stop()
})
It("should show balances with GET /api/balance", func() {
resp, err := http.Get("http://localhost:8080/api/balance?from=user1")
Expect(err).ToNot(HaveOccurred())
Expect(resp.StatusCode).To(Equal(http.StatusOK))
Expect(ResponseBodyAsString(resp)).To(Equal("0"))
})
})
Так как сервер доступен из внешнего мира по HTTP, мы будем работать с его веб-API с использование http.Get. А как насчёт тестирования выполнения транзакций? Вот код соответствующего теста:
It("should transfer funds with POST /api/transfer", func() {
resp, err := http.Get("http://localhost:8080/api/transfer?from=user1&to=user2&amount=17")
Expect(err).ToNot(HaveOccurred())
Expect(resp.StatusCode).To(Equal(http.StatusOK))
Expect(ResponseBodyAsString(resp)).To(Equal("-17"))
resp, err = http.Post("http://localhost:8080/api/balance?from=user2", "text/plain", nil)
Expect(err).ToNot(HaveOccurred())
Expect(resp.StatusCode).To(Equal(http.StatusOK))
Expect(ResponseBodyAsString(resp)).To(Equal("17"))
})
Код тестов отлично описывает их сущность, он даже может заменить документацию. Как видите, мы допускаем наличие отрицательных балансов счетов пользователей. Это — особенность нашего проекта. Если бы это было запрещено, данное решение было бы отражено в тесте.
→ Вот полный код теста
Разработка сервисных тестов
Теперь, после разработки сквозных тестов, мы спускаемся по пирамиде тестирования и приступаем к созданию сервисных тестов. Такие тесты разрабатываются для каждого отдельного сервиса. Выберем сервис, у которого есть зависимость от другого сервиса, так как этот случай интереснее разработки тестов для независимого сервиса.
Начнём с сервиса VirtualMachine. Здесь можно найти интерфейс с proto-описаниями для этого сервиса. Так как сервис VirtualMachine полагается на сервис StateStorage и выполняет обращения к нему, нам надо будет создать объект-заглушку (mock object) для сервиса StateStorage для того, чтобы протестировать сервис VirtualMachine в изоляции. Объект-заглушка позволит нам управлять ответами StateStorage во время тестирования.
Как реализовать объект-заглушку в Go? Это можно сделать исключительно средствам языка, без вспомогательных инструментов, а можно прибегнуть к соответствующей библиотеке, которая, кроме того, даст возможность работать в процессе тестирования с утверждениями. Для этой цели я предпочитаю использовать библиотеку go-mock.
Код заглушки разместим в файле /services/statestorage/mock.go. Лучше всего размещать объекты-заглушки там же, где находятся сущности, которые они имитируют для того, чтобы предоставить им доступ к неэкспортируемым переменным и функциям. Заглушка на данном этапе представляет собой схематичную реализацию сервиса, но, по мере развития сервиса, нам может понадобится развивать и реализацию заглушки. Вот код объекта-заглушки (файл mock.go):
package statestorage
import ...
type MockService struct {
mock.Mock
}
func (s *MockService) Start() {
s.Called()
}
func (s *MockService) Stop() {
s.Called()
}
func (s *MockService) IsStarted() bool {
return s.Called().Bool(0)
}
func (s *MockService) WriteKey(input *statestorage.WriteKeyInput) (*statestorage.WriteKeyOutput, error) {
ret := s.Called(input)
return ret.Get(0).(*statestorage.WriteKeyOutput), ret.Error(1)
}
func (s *MockService) ReadKey(input *statestorage.ReadKeyInput) (*statestorage.ReadKeyOutput, error) {
ret := s.Called(input)
return ret.Get(0).(*statestorage.ReadKeyOutput), ret.Error(1)
}
Если вы отдаёте разработку отдельных сервисов разным программистам, имеет смысл сначала создавать заглушки и передавать их команде.
Вернёмся к разработке сервисного теста для VirtualMachine. Какой сценарий нужно здесь проверить? Лучше всего ориентироваться на интерфейс сервиса и разрабатывать тесты для каждой конечной точки. Мы реализуем тест для конечной точки CallContract() с аргументом, представляющим метод "GetBalance". Вот соответствующий код (файл contracts.go):
package spec
import ...
var _ = Describe("Contracts", func() {
var (
service uut.Service
stateStorage *_statestorage.MockService
)
BeforeEach(func() {
service = uut.NewService()
stateStorage = &_statestorage.MockService{}
service.Start(stateStorage)
})
AfterEach(func() {
service.Stop()
})
It("should support 'GetBalance' contract method", func() {
stateStorage.When("ReadKey", &statestorage.ReadKeyInput{Key: "user1"}).Return(&statestorage.ReadKeyOutput{Value: 100}, nil).Times(1)
addr := protocol.Address{Username: "user1"}
out, err := service.CallContract(&virtualmachine.CallContractInput{Method: "GetBalance", Arg: &addr})
Expect(err).ToNot(HaveOccurred())
Expect(out.Result).To(BeEquivalentTo(100))
Expect(stateStorage).To(ExecuteAsPlanned())
})
})
Обратите внимание на то, что сервис, который мы тестируем, VirtualMachine, получает указатель на свою зависимость, StateStorage, в методе Start() посредством простого механизма внедрения зависимостей. Именно здесь мы передаём экземпляр объекта-заглушки. Кроме того, обратите внимание на строку stateStorage.When("ReadKey", &statestorage.ReadKeyInput{Key…, где мы сообщаем объекту-заглушке о том, как он должен вести себя при обращении к нему. Когда вызывается метод ReadKey, он должен возвратить значение 100. Затем мы, в строке Expect(stateStorage).To(ExecuteAsPlanned()), проверяем, чтобы эта команда была вызвана ровно один раз.
Подобные тесты становятся спецификациями для сервиса. Полный набор тестов для сервиса VirtualMachine можно найти здесь. Наборы тестов для других сервисов нашего проекта можно найти здесь и здесь.
Разработка модульных тестов
Пожалуй, реализация контракта для метода "GetBalance" слишком проста, поэтому поговорим о реализации несколько более сложного метода "Transfer". Контракт перевода средств со счёта на счёт, представленный этим методом, нуждается в чтении данных о балансах отправителя и получателя средств, в вычислении новых балансов и в записи того, что получилось, в состояние приложения. Сервисный тест для всего этого очень похож на тот, который мы только что реализовали (файл transactions.go):
It("should support 'Transfer' transaction method", func() {
stateStorage.When("ReadKey", &statestorage.ReadKeyInput{Key: "user1"}).Return(&statestorage.ReadKeyOutput{Value: 100}, nil).Times(1)
stateStorage.When("ReadKey", &statestorage.ReadKeyInput{Key: "user2"}).Return(&statestorage.ReadKeyOutput{Value: 50}, nil).Times(1)
stateStorage.When("WriteKey", &statestorage.WriteKeyInput{Key: "user1", Value: 90}).Return(&statestorage.WriteKeyOutput{}, nil).Times(1)
stateStorage.When("WriteKey", &statestorage.WriteKeyInput{Key: "user2", Value: 60}).Return(&statestorage.WriteKeyOutput{}, nil).Times(1)
t := protocol.Transaction{From: &protocol.Address{Username: "user1"}, To: &protocol.Address{Username: "user2"}, Amount: 10}
out, err := service.ProcessTransaction(&virtualmachine.ProcessTransactionInput{Method: "Transfer", Arg: &t})
Expect(err).ToNot(HaveOccurred())
Expect(out.Result).To(BeEquivalentTo(90))
Expect(stateStorage).To(ExecuteAsPlanned())
})
В процессе работы над проектом мы, наконец доходим до создания его внутренних механизмов и создаём модуль, размещаемый в файле processor.go, который содержит реализацию контракта. Вот как будет выглядеть его исходный вариант (файл processor.go):
package virtualmachine
import ...
func (s *service) processTransfer(fromUsername string, toUsername string, amount int32) (int32, error) {
fromBalance, err := s.stateStorage.ReadKey(&statestorage.ReadKeyInput{Key: fromUsername})
if err != nil {
return 0, err
}
toBalance, err := s.stateStorage.ReadKey(&statestorage.ReadKeyInput{Key: toUsername})
if err != nil {
return 0, err
}
_, err = s.stateStorage.WriteKey(&statestorage.WriteKeyInput{Key: fromUsername, Value: fromBalance.Value - amount})
if err != nil {
return 0, err
}
_, err = s.stateStorage.WriteKey(&statestorage.WriteKeyInput{Key: toUsername, Value: toBalance.Value + amount})
if err != nil {
return 0, err
}
return fromBalance.Value - amount, nil
}
Эта конструкция удовлетворяет сервисному тесту, но в нашем случае интеграционный тест содержит лишь проверку базового сценария. Как насчёт пограничных случаев и потенциальных сбоев? Как видите, любой из вызовов, которые мы выполняем к StateStorage, может оказаться неудачным. Если требуется 100% покрытие кода тестами, нам нужно проверить все эти ситуации. Модульный тест отлично подходит для реализации подобных проверок.
Так как мы собираемся вызывать функцию несколько раз с различными входными данными и имитировать параметры для достижения всех ветвей кода, мы, для того, чтобы сделать этот процесс эффективнее, можем прибегнуть к тестам, основанным на таблице (table driven test). В Go принято избегать экзотических фреймворков в модульных тестах. Мы можем отказаться от Ginkgo, но, вероятно, нам стоит оставить Gomega. В результате проверки, выполняемые здесь, будут похожи на те, которые мы выполняли в предыдущих тестах. Вот код теста (файл processor_test.go):
package virtualmachine
import ...
var transferTable = []struct{
to string // имя пользователя, которому переводят средства
read1Err error // требуется ли отказ первой операции чтения
read2Err error // требуется ли отказ второй операции чтения
write1Err error // требуется ли отказ первой операции записи
write2Err error // требуется ли отказ второй операции записи
output int32 // ожидаемый выход
errs bool // ожидаем ли мы возврат ошибки из функции
}{
{"user2", errors.New("a"), nil, nil, nil, 0, true},
{"user2", nil, errors.New("a"), nil, nil, 0, true},
{"user2", nil, nil, errors.New("a"), nil, 0, true},
{"user2", nil, nil, nil, errors.New("a"), 0, true},
{"user2", nil, nil, nil, nil, 90, false},
}
func TestTransfer(t *testing.T) {
Ω := NewGomegaWithT(t)
for _, tt := range transferTable {
s := NewService()
ss := &_statestorage.MockService{}
s.Start(ss)
ss.When("ReadKey", &statestorage.ReadKeyInput{Key: "user1"}).Return(&statestorage.ReadKeyOutput{Value: 100}, tt.read1Err)
ss.When("ReadKey", &statestorage.ReadKeyInput{Key: "user2"}).Return(&statestorage.ReadKeyOutput{Value: 50}, tt.read2Err)
ss.When("WriteKey", &statestorage.WriteKeyInput{Key: "user1", Value: 90}).Return(&statestorage.WriteKeyOutput{}, tt.write1Err)
ss.When("WriteKey", &statestorage.WriteKeyInput{Key: "user2", Value: 60}).Return(&statestorage.WriteKeyOutput{}, tt.write2Err)
output, err := s.(*service).processTransfer("user1", tt.to, 10)
if tt.errs {
Ω.Expect(err).To(HaveOccurred())
} else {
Ω.Expect(err).ToNot(HaveOccurred())
Ω.Expect(output).To(BeEquivalentTo(tt.output))
}
}
}
Если вы озадачены символом «Ω» — не беспокойтесь, так как это — обычное имя переменной (эта переменная хранит указатель на Gomega). Вы можете использовать для подобной переменной любое понравившееся вам имя.
Для того чтобы не тратить слишком много времени, мы не будем рассматривать здесь строгую методологию TDD, при применении которой новую строку кода пишут лишь для того, чтобы заставить правильно заработать тест, который до этого выдавал ошибку. При использовании этой методологии реализация метода processTransfer() и модульный тест для него создаются за несколько итераций.
Полный набор модульных тестов для сервиса VirtualMachine можно найти здесь. Модульные тесты для других сервисов находятся здесь и здесь.
Теперь мы достигли 100% покрытия кода тестами. Система успешно проходит сквозные, сервисные и модульные тесты. Код совершенно точно реализует предъявляемые к нему требования и всё это отлично протестировано.
Означает ли это, что теперь нашу систему можно признать надёжно работающей? К сожалению нет. В ней всё ещё есть некоторые неприятные ошибки, которые, в нашем простом проекте, лежат у всех на виду.
▍О важности стресс-тестов
До сих пор наши тесты проверяли работоспособность системы при обработке одного запроса за раз. А как насчёт проверки её на возможные проблемы синхронизации? Каждый HTTP-запрос в Go обрабатывается в собственной горутине (goroutine). Так как горутины выполняются параллельно, потенциально — в разных потоках ОС на разных ядрах процессора, перед нами встают проблемы синхронизации. Ошибки, которые могут проявляться в подобных ситуациях, весьма неприятны, их сложно отслеживать.
Один из подходов к поиску проблем с синхронизацией заключается в стресс-тестировании системы путём выполнения множества параллельных запросов к ней и проверки её работоспособности в таких условиях. Тест, выполняющий подобную проверку, должен быть сквозным, так как он направлен на проверку синхронизации во всей системе, на проверку слаженной работы всех составляющих её сервисов. Код стресс-тестов мы разместим в папке /e2e/stress. Вот код стресс-теста (файл stress.go):
package stress
import ...
const NUM_TRANSACTIONS = 20000
const NUM_USERS = 100
const TRANSACTIONS_PER_BATCH = 200
const BATCHES_PER_SEC = 40
var _ = Describe("Transaction Stress Test", func() {
var (
node services.Node
)
BeforeEach(func() {
node = services.NewNode()
node.Start()
})
AfterEach(func() {
node.Stop()
})
It("should handle lots and lots of transactions", func() {
// подготовим HTTP-клиент к выполнению множества соединений
transport := http.Transport{
IdleConnTimeout: time.Second*20,
MaxIdleConns: TRANSACTIONS_PER_BATCH*10,
MaxIdleConnsPerHost: TRANSACTIONS_PER_BATCH*10,
}
client := &http.Client{Transport: &transport}
// создадим локальный журнал для верификации
ledger := map[string]int32{}
for i := 0; i < NUM_USERS; i++ {
ledger[fmt.Sprintf("user%d", i+1)] = 0
}
// отправим все транзакции по HTTP в пакетах
rand.Seed(42)
done := make(chan error, TRANSACTIONS_PER_BATCH)
for i := 0; i < NUM_TRANSACTIONS / TRANSACTIONS_PER_BATCH; i++ {
log.Printf("Sending %d transactions...
