[Перевод] Массивы в РНР 7: хэш-таблицы
В Сети есть немало замечательных статей, подробно освещающих устройство хэш-таблиц и их реализации. Начать можно с http://preshing.com/. Но имейте в виду, вариантов структуры хэш-таблиц — несметное множество, и ни один из них не совершенен, в каждом есть компромиссы, несмотря на оптимизацию циклов процессора, использования памяти или хорошее масштабирование потокового окружения (threaded environment). Одни варианты лучше при добавлении данных, другие — при поиске и т. д. Выбирайте реализацию в зависимости от того, что для вас важнее.
Хэш-таблицы в РНР 5 подробно рассмотрены в материале phpinteralsbook, который я написал вместе с Nikic, автором хорошей статьи про хэш-таблицы в РНР 7. Возможно, её вы тоже сочтёте интересной. Правда, она писалась до релиза, поэтому некоторые вещи в ней слегка отличаются.
Здесь же мы подробно рассмотрим, как устроены хэш-таблицы в РНР 7, как с ними можно работать с точки зрения языка С и как ими управлять средствами РНР (используя структуры, называемые массивами). Исходный код в основном доступен в zend_hash.c. Не забывайте, что хэш-таблицы мы используем везде (обычно в роли словарей), следовательно, нужно проектировать их так, чтобы они быстро обрабатывались процессором и потребляли мало памяти. Эти структуры решающе влияют на общую производительность РНР, поскольку местные массивы не единственное место, где используются хэш-таблицы.
Есть ряд положений, которые мы далее подробно рассмотрим:
- Ключ может быть строкой или целочисленным. В первом случае используется структура
zend_string, во втором —zend_ulong. - Хэш-таблица всегда должна помнить порядок добавления её элементов.
- Размер хэш-таблицы меняется автоматически. В зависимости от обстоятельств она самостоятельно уменьшается или увеличивается.
- С точки зрения внутренней реализации размер таблицы всегда равен двойке в степени. Это делается для улучшения производительности и выравнивания размещения данных в памяти.
- Все значения в хэш-таблице хранятся в структуре
zval, больше нигде.Zval«ы могут содержать данные любых типов.
Рассмотрим структуру
HashTable: struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar reserve)
} v;
uint32_t flags; /* доступно 32 флага */
} u;
uint32_t nTableMask; /* маска — nTableSize */
Bucket *arData; /* полезное хранилище данных */
uint32_t nNumUsed; /* следующая доступная ячейка в arData */
uint32_t nNumOfElements; /* общее количество занятых элементов в arData */
uint32_t nTableSize; /* размер таблицы, всегда равен двойке в степени */
uint32_t nInternalPointer; /* используется для итерации */
zend_long nNextFreeElement; /* следующий доступный целочисленный ключ */
dtor_func_t pDestructor; /* деструктор данных */
};
Некоторые поля используются редко, и поэтому мы о них говорить не будем.
Размер этой структуры — 56 байт (согласно модели LP64).
Самое интересное поле данных — arData, это своеобразный указатель на область памяти цепочки Bucket. Сама Bucket представляет собой одну ячейку в массиве:
typedef struct _Bucket {
zval val; /* значение */
zend_ulong h; /* хэш (или числовой индекс) */
zend_string *key; /* строковый ключ или NULL для числовых значений */
} Bucket;
Как вы могли заметить, в структуре
Bucket будет храниться zval. Обратите внимание, что здесь используется не указатель на zval, а именно сама структура. Так сделано потому, что в РНР 7 zval«ы больше не размещаются в куче (в отличие от PHP 5), но при этом в РНР 7 может размещаться целевое значение, хранящееся в zval в виде указателя (например, строка РНР).Давайте посмотрим на картинке, как происходит размещение в памяти:

Как видите, помещаемые в хэш-таблицу данные хранятся в смежном разделе памяти: arData.
Добавление элементов с сохранением очерёдности
РНР должен сохранять очерёдность элементов при их добавлении в массив. Если применить к массиву инструкцию
foreach, то вы получите данные именно в том порядке, в котором они помещались в массив, вне зависимости от их ключей: $a = [9=>"foo", 2 => 42, []];
var_dump($a);
array(3) {
[9]=>
string(3) "foo"
[2]=>
int(42)
[10]=>
array(0) {
}
}
Это важный момент, наложивший ряд ограничений при реализации хэш-таблиц. Все данные размещаются в памяти рядом друг с другом. В
zval«ах они хранятся упакованными в Bucket«ы, которые располагаются в полях С-массива arData. Примерно так: $a = [3=> 'foo', 8 => 'bar', 'baz' => []];

Благодаря этому подходу можно легко итерировать хэш-таблицу: достаточно всего лишь итерировать массив arData. По сути, это быстрое последовательное сканирование памяти, потребляющее очень мало ресурсов процессорного кэша. В одной строке могут помещаться все данные из arData, а доступ к каждой ячейке занимает около 1 наносекунды. Обратите внимание: чтобы повысить эффективность использования процессорного кэша, arData выравнен в соответствии с 64-битной моделью (также используется оптимизирующее выравнивание 64-битных полных инструкций). Код итерирования хэш-таблицы может выглядеть так:
size_t i;
Bucket p;
zval val;
for (i=0; i < ht->nTableSize; i++) {
p = ht->arData[i];
val = p.val;
/* можно что-нибудь сделать с val */
}
Данные сортируются и передаются в следующую ячейку
arData. Для выполнения этой процедуры достаточно просто помнить следующую доступную ячейку в этом массиве, хранящуюся в поле nNumUsed. При каждом добавлении нового значения мы помещаем его ht->nNumUsed++. Когда количество элементов в nNumUsed достигает количества элементов в хэш-таблице (nNumOfElements), мы запускаем алгоритм уплотнения или изменения размера (compact or resize), о котором поговорим ниже.Упрощённое представление добавления элементов в хэш-таблицу с использованием строковых ключей:
idx = ht->nNumUsed++; /* берём номер следующей доступной ячейки */
ht->nNumOfElements++; /* инкрементируем количество элементов */
/* ... */
p = ht->arData + idx; /* получаем в этой ячейке bucket от arData */
p->key = key; /* Affect it the key we want to insert at */
/* ... */
p->h = h = ZSTR_H(key); /* сохраняем в bucket хэш текущего ключа */
ZVAL_COPY_VALUE(&p->val, pData); /* копируем значение в значение bucket’а: операция добавления */
Стирание значений
При удалении значения массив
arData не уменьшается и не перегруппируется. В противном случае производительность бы катастрофически упала, поскольку нам бы приходилось перемещать данные в памяти. Поэтому при удалении данных из хэш-таблицы соответствующая ячейка в arData просто помечается специальным образом: zval UNDEF.
Следовательно, итерационный код нужно немного перестроить, чтобы он мог обрабатывать такие «пустые» ячейки:
size_t i;
Bucket p;
zval val;
for (i=0; i < ht->nTableSize; i++) {
p = ht->arData[i];
val = p.val;
if (Z_TYPE(val) == IS_UNDEF) {
continue;
}
/* можно что-нибудь сделать с val */
}
Ниже мы рассмотрим, что происходит при изменении размера хэш-таблицы и как должен быть реорганизован массив
arData, чтобы исчезли «пустые» ячейки (уплотнение).Хэширование ключей
Ключи необходимо хэшировать и сжимать, затем преобразовывать из сжатого хэшированного значения и индексировать в
arData. Ключ сожмётся, даже если он целочисленный. Это необходимо для того, чтобы он вписался в границы массива. Нужно помнить, что мы не можем индексировать сжатые значения как есть напрямую в arData. Ведь это будет означать, что использованные для индекса массива ключи прямо соответствуют ключам, полученным из хэша, что нарушает одно из свойств хэш-таблиц в РНР: сохранения порядка элементов.
Например: если добавить сначала по ключу foo, а потом по ключу bar, то первый будет хэширован/сжат до ключа 5, а второй — до ключа 3. Если данные foo хранить в arData[5], а данные bar — в arData[3], то получится, что данные bar идут до данных foo. И при итерировании arData элементы будут передаваться уже не в том порядке, в котором они добавлялись.

Итак, мы хэшируем, а потом сжимаем ключ, чтобы он поместился в отведённые границы arData. Но мы не используем его как есть, в отличие от PHP 5. Необходимо сначала преобразовать ключ с помощью таблицы преобразования (translation table). Она просто сопоставляет одно целочисленное значение, полученное в результате хэширования/сжатия, и другое целочисленное значение, используемое для адресации в рамках массива arData.
Тут есть один нюанс: память таблицы преобразования предусмотрительно располагается за вектором arData. Это не даёт таблице использовать иную область памяти, ведь она уже размещена рядом с arData и, значит, остаётся в том же адресном пространстве. Это позволяет улучшить локальность данных. Вот так выглядит описанная схема в случае с 8-элементной хэш-таблицей (минимально возможный размер):

Теперь наш ключ foo хэширован в DJB33X и сжат по модулю до необходимого размера (nTableMask). Полученное значение — это индекс, который можно использовать, чтобы обращаться к ячейкам преобразования arData (а не к прямым ячейкам!).
Доступ к этим ячейкам происходит с помощью отрицательного сдвига от начальной позиции arData. Две области памяти были объединены, поэтому мы можем хранить данные в памяти последовательно. nTableMask соответствует отрицательному значению размера таблицы, так что, взяв его в качестве модуля, получим значение от 0 до –7. Теперь можно обращаться к памяти. При размещении в ней всего буфера arData мы рассчитываем его размер по формуле:
Размер таблицы * размер bucket’а + размер таблицы * размер(uint32) ячеек преобразования.
Ниже хорошо видно, как буфер делится на две части:
#define HT_HASH_SIZE(nTableMask) (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t))
#define HT_DATA_SIZE(nTableSize) ((size_t)(nTableSize) * sizeof(Bucket))
#define HT_SIZE_EX(nTableSize, nTableMask) (HT_DATA_SIZE((nTableSize)) + HT_HASH_SIZE((nTableMask)))
#define HT_SIZE(ht) HT_SIZE_EX((ht)->nTableSize, (ht)->nTableMask)
Bucket *arData;
arData = emalloc(HT_SIZE(ht)); /* теперь разместим это в памяти */
Когда макросы выполнены, мы получаем:
(((size_t)(((ht)->nTableSize)) * sizeof(Bucket)) + (((size_t)(uint32_t)-(int32_t)(((ht)->nTableMask))) * sizeof(uint32_t)))
Замечательно.
Разрешение коллизий
Теперь разберёмся, как разрешаются коллизии. Как вы помните, в хэш-таблице несколько ключей при хэшировании и сжатии могут соответствовать одному и тому же индексу преобразования. Так что, получив индекс преобразования, мы с его помощью извлекаем данные обратно из
arData и сравниваем хэши и ключи, проверяя, то ли это, что нужно. Если данные неправильные, мы проходим по связному списку с помощью поля zval.u2.next, в котором отражается следующая ячейка для внесения данных.Обратите внимание, что связный список не рассеян по памяти, как традиционные связные списки. Вместо того чтобы ходить по нескольким размещённым в памяти указателям, полученным от кучи — и наверняка разбросанным по адресному пространству, — мы считываем из памяти полный вектор arData. И это одна из главных причин увеличения производительности хэш-таблиц в РНР 7, а также всего языка.
В РНР 7 у хэш-таблиц очень высокая локальность данных. В большинстве случаев доступ происходит за 1 наносекунду, поскольку данные обычно находятся в процессорном кэше первого уровня.
Давайте посмотрим, как можно добавлять элементы в хэш, а также разруливать коллизии:
idx = ht->nNumUsed++; /* берём номер следующей доступной ячейки */
ht->nNumOfElements++; /* инкрементируем количество элементов */
/* ... */
p = ht->arData + idx; /* получаем от arData bucket в этой ячейке */
p->key = key; /* помечаем ключ для вставки */
/* ... */
p->h = h = ZSTR_H(key); /* сохраняем в bucket хэш текущего ключа */
ZVAL_COPY_VALUE(&p->val, pData); /* копируем значение в значение bucket’а: операция добавления */
nIndex = h | ht->nTableMask; /* получаем индекс таблицы преобразования */
Z_NEXT(p->val) = HT_HASH(ht, nIndex); /* помести следующего из нас как фактический элемент */
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx); /* помести нас в фактическую ячейку преобразования */
То же самое и с удалением:
h = zend_string_hash_val(key); /* получаем хэш из строкового ключа */
nIndex = h | ht->nTableMask; /* получаем индекс таблицы преобразования */
idx = HT_HASH(ht, nIndex); /* получаем ячейку, соответствующую индексу преобразования */
while (idx != HT_INVALID_IDX) { /* если есть соответствующая ячейка */
p = HT_HASH_TO_BUCKET(ht, idx); /* получаем bucket из этой ячейки */
if ((p->key == key) || /* это правильный? Тот же указатель ключа? */
(p->h == h && /* ...или тот же хэш */
p->key && /* и ключ (на базе строкового ключа) */
ZSTR_LEN(p->key) == ZSTR_LEN(key) && /* и та же длина ключа */
memcmp(ZSTR_VAL(p->key), ZSTR_VAL(key), ZSTR_LEN(key)) == 0)) { /* и то же содержимое ключа? */
_zend_hash_del_el_ex(ht, idx, p, prev); /* вот они мы! Удаляй нас */
return SUCCESS;
}
prev = p;
idx = Z_NEXT(p->val); /* переместиться к следующей ячейке */
}
return FAILURE;
Ячейки преобразования и инициализация хэша
HT_INVALID_IDX — специальный флаг, который мы помещаем в таблицу преобразования. Он означает «это преобразование никуда не ведёт, продолжать не нужно».Двухэтапная инициализация даёт определённые преимущества, позволяя максимально уменьшить влияние пустой, только что созданной хэш-таблицы (частый случай в РНР). При создании таблицы мы одновременно создаём ячейки bucket«ов в arData и две ячейки преобразования, в которые помещаем флаг HT_INVALID_IDX. Затем накладываем маску, которая направляет в первую ячейку преобразования (HT_INVALID_IDX, здесь нет данных).
#define HT_MIN_MASK ((uint32_t) -2)
#define HT_HASH_SIZE(nTableMask) (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t))
#define HT_SET_DATA_ADDR(ht, ptr) do { (ht)->arData = (Bucket*)(((char*)(ptr)) + HT_HASH_SIZE((ht)->nTableMask)); } while (0)
static const uint32_t uninitialized_bucket[-HT_MIN_MASK] = {HT_INVALID_IDX, HT_INVALID_IDX};
/* hash lazy init */
ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC)
{
/* ... */
ht->nTableSize = zend_hash_check_size(nSize);
ht->nTableMask = HT_MIN_MASK;
HT_SET_DATA_ADDR(ht, &uninitialized_bucket);
ht->nNumUsed = 0;
ht->nNumOfElements = 0;
}
Обратите внимание, что здесь можно не пользоваться кучей. Вполне достаточно статической постоянной области памяти (static const memory zone), так получается гораздо легче (
uninitialized_bucket).После добавления первого элемента мы полностью инициализируем хэш-таблицу. Иными словами, создаём последние необходимые ячейки преобразования в зависимости от запрошенного размера (по умолчанию начинается с 8 ячеек). Размещение в памяти происходит из кучи.
(ht)->nTableMask = -(ht)->nTableSize;
HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_PERSISTENT));
memset(&HT_HASH(ht, (ht)->nTableMask), HT_INVALID_IDX, HT_HASH_SIZE((ht)->nTableMask))
Макрос
HT_HASH позволяет обращаться к ячейкам преобразования в той части размещённого в памяти буфера, для которой использовано отрицательное смещение. Табличная маска всегда отрицательная, потому что ячейки таблицы преобразования индексируются в минус от начала буфера arData. Здесь во всей красе раскрывается программирование на С: вам доступны миллиарды ячеек, плавайте в этой бесконечности, только не утоните.Пример лениво инициализированной (lazy-initialized) хэш-таблицы: она создана, но пока ни один хэш в неё не помещён.
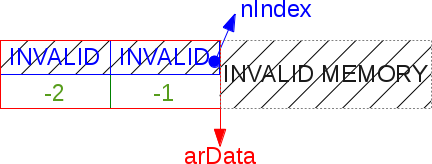
Фрагментация хэшей, увеличение и уплотнение
Если хэш-таблица заполнена целиком и нужно добавить новые элементы, приходится увеличивать её размер. Это большое преимущество хэш-таблиц по сравнению с классическими жёстко ограниченными массивами в С. При каждом увеличении размер хэш-таблицы вырастает вдвое. Напоминаю, что при увеличении размера таблицы мы предварительно распределяем в памяти С-массив
arBucket, а в пустые ячейки помещаем специальные значения UNDEF. В результате мы бодро теряем память. Потери вычисляются по формуле: (новый размер – старый размер) * размер Bucket
Вся эта память состоит из UNDEF-ячеек и ждёт, когда в неё поместят данные.
К примеру, у вас в хэш-таблице 1024 ячейки, и вы добавляете новый элемент. Таблица разрастается до 2048 ячеек, из которых 1023 — пустые. 1023×32 байта = примерно 32 Кб. Это один из недостатков реализации хэш-таблиц в РНР.
Нужно помнить, что хэш-таблица может целиком состоять из одних UNDEF-ячеек. Если добавлять и удалять по много элементов, то таблица будет фрагментироваться. Но ради сохранения порядка следования элементов мы всё новое добавляем только в конце arData, а не вставляем в образовавшиеся пробелы. Поэтому может возникнуть ситуация, когда мы доходим до конца arData, хотя в нём ещё присутствуют UNDEF-ячейки.
Пример сильно фрагментированной 8-ячеечной хэш-таблицы:
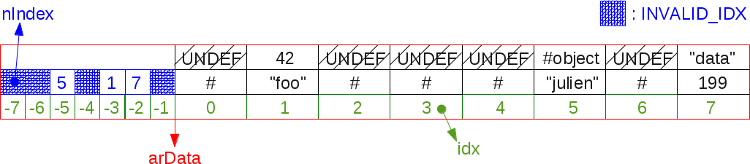
Как вы помните, в UNDEF-ячейках нельзя хранить новые значения. В вышеприведённой схеме при итерировании хэш-таблицы мы идём от arData[0] к arData[7].
Увеличив размер, можно сократить вектор arData и в конце концов заполнить пустые ячейки, просто перераспределив данные. Когда таблице дают команду на изменение размера, то в первую очередь она пытается себя уплотнить. Затем вычисляет, придётся ли ей после уплотнения снова увеличиваться. И если оказывается, что да, то таблица увеличивается в два раза. После этого вектор arData начинает занимать вдвое больше памяти (realloc()). Если же увеличиваться не нужно, то данные просто перераспределяются в уже размещённых в памяти ячейках. Здесь используется алгоритм, который мы не можем применять при каждом удалении элементов, поскольку он слишком часто тратит ресурсы процессора, а выхлоп не так велик. Вы же помните о знаменитом программистском компромиссе между процессором и памятью?
На этой иллюстрации представлена предыдущая фрагментированная хэш-таблица после уплотнения:
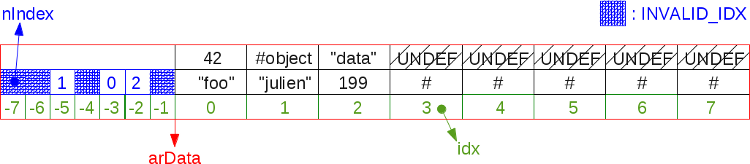
Алгоритм просматривает arData и заполняет каждую UNDEF-ячейку данными из следующей неUNDEF-ячейки. Упрощённо это выглядит так:
Bucket *p;
uint32_t nIndex, i;
HT_HASH_RESET(ht);
i = 0;
p = ht->arData;
do {
if (UNEXPECTED(Z_TYPE(p->val) == IS_UNDEF)) {
uint32_t j = i;
Bucket *q = p;
while (++i < ht->nNumUsed) {
p++;
if (EXPECTED(Z_TYPE_INFO(p->val) != IS_UNDEF)) {
ZVAL_COPY_VALUE(&q->val, &p->val);
q->h = p->h;
nIndex = q->h | ht->nTableMask;
q->key = p->key;
Z_NEXT(q->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(j);
if (UNEXPECTED(ht->nInternalPointer == i)) {
ht->nInternalPointer = j;
}
q++;
j++;
}
}
ht->nNumUsed = j;
break;
}
nIndex = p->h | ht->nTableMask;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(i);
p++;
} while (++i < ht->nNumUsed);
API хэш-таблицы
Ну что же, теперь мы знаем основные моменты реализации хэш-таблицы в PHP 7. Давайте теперь рассмотрим её публичный API.
Тут особо говорить не о чем (ну, в РНР 5 API сделан куда лучше). Просто при использовании функции API не забывайте о трёх вещах:
- О вашей операции (добавление, удаление, очистка, уничтожение и т. д.).
- О типе вашего ключа (целочисленный или строчный).
- О типе данных, которые вы хотите хранить.
Каким бы ни был ваш ключ, строчным или целочисленным, главное: API должен знать о том, что строчные ключи получают хэши от zend_string, а целочисленные сразу используются в качестве хэша. Поэтому вы можете встретить zend_hash_add(ht, zend_string, data) или zend_hash_index_add(ht, long, data).
Иногда ключ может представлять собой простую пару (char* / int). В этом случае нужно использовать другой API, например zend_hash_str_add(ht, char *, int, data). Помните, что, как бы там ни было, хэш-таблица обратится к zend_string, превратив в него ваш строковый ключ и вычислив его хэш, потратив какое-то количество ресурсов процессора. Если можете использовать zend_string, используйте. Наверняка они уже вычислили свои хэши, поэтому API просто возьмёт их. Например, компилятор РНР вычисляет хэш каждой части используемого строкового, как zend_string. OPCache хранит подобный хэш в памяти общего доступа. Как автор расширений, рекомендую инициализировать в MINIT все ваши литералы zend_string.
Теперь о данных, которые вы собираетесь хранить в хэш-таблице. Опять же, это может быть что угодно, хэш-таблица всё равно поместит данные в zval, имеющийся в каждом Bucket. В РНР 7 zval«ы могут хранить любые данные любого типа. В целом API хэш-таблицы ожидает, что вы упакуете данные в zval, который API воспринимает как значение.
Ситуацию можно несколько упростить, если у вас есть указатель на хранилище или область памяти (данные, на которые ссылается указатель). Тогда API поместит в zval этот указатель или область памяти, а потом сам zval использует указатель в качестве данных.
Примеры помогут понять идею:
zend_hash_str_add_mem(hashtable *, char *, size_t, void *)
zend_hash_index_del(hashtable *, zend_ulong)
zend_hash_update_ptr(hashtable *, zend_string *, void *)
zend_hash_index_add_empty_element(hashtable *, zend_ulong)
При извлечении данных вы получите либо zval *, либо NULL. Если в качестве значения используется указатель, API может вернуть как есть:
zend_hash_index_find(hashtable *, zend_string *) : zval *
zend_hash_find_ptr(hashtable *, zend_string *) : void *
zend_hash_index_find(hashtable *, zend_ulong) : zval *
Что касается _new API наподобие
zend_hash_add_new(), его лучше не использовать. Его применяет движок для внутренних нужд. Этот API заставляет хэш-таблицу хранить данные, даже если они уже доступны в хэше (тот же ключ). В результате у вас появятся дубли, что может не лучшим образом сказаться на работе. Так что использовать этот API можно, только если вы полностью уверены, что в хэше нет данных, которые вы собираетесь добавить. Тем самым вы избежите необходимости искать их.Напоследок: как и в РНР 5, API zend_symtable_api() заботится о преобразовании текстового написания чисел непосредственно в числовое:
static zend_always_inline zval *zend_symtable_update(HashTable *ht, zend_string *key, zval *pData)
{
zend_ulong idx;
if (ZEND_HANDLE_NUMERIC(key, idx)) { /* handle numeric key */
return zend_hash_index_update(ht, idx, pData);
} else {
return zend_hash_update(ht, key, pData);
}
}
Вы можете использовать множество макросов для итераций в зависимости от того, какие данные хотите получить в цикле: ключ, zval… Все эти макросы основаны на
ZEND_HASH_FOREACH: #define ZEND_HASH_FOREACH(_ht, indirect) do { \
Bucket *_p = (_ht)->arData; \
Bucket *_end = _p + (_ht)->nNumUsed; \
for (; _p != _end; _p++) { \
zval *_z = &_p->val; \
if (indirect && Z_TYPE_P(_z) == IS_INDIRECT) { \
_z = Z_INDIRECT_P(_z); \
} \
if (UNEXPECTED(Z_TYPE_P(_z) == IS_UNDEF)) continue;
#define ZEND_HASH_FOREACH_END() \
} \
} while (0)
Оптимизация «упакованная хэш-таблица»
Итак, вспомните о критически важном правиле: мы добавляем данные в
arData в порядке возрастания, от нуля и до конца, а затем формируем вектор arData. Это позволяет легко и дёшево итерировать хэш-таблицу: достаточно просто итерировать С-массив arData. Поскольку в качестве ключа хэш-таблицы может быть использована строка или взятое не по порядку целочисленное значение, то нам нужна таблица преобразования для возможности проанализировать хэш.Но в одном случае такие таблицы бесполезны: если пользователь применяет только целочисленные ключи и только в порядке возрастания. Тогда при просмотре arData от начала до конца мы получим данные в том же порядке, в котором они были помещены. А раз в этом случае таблица преобразования бесполезна, то можно и не размещать её в памяти.
Эта оптимизация называется «упакованная хэш-таблица» (packed hashtable):

Как видите, все ключи целочисленные и размещены просто в порядке возрастания. При итерировании arData[0] с самого начала мы будем получать элементы в правильной очерёдности. Так что таблица преобразования была уменьшена всего до двух ячеек, 2 * uint32 = 8 байт. Больше ячеек преобразования не нужно. Звучит странно, но с этими двумя ячейками производительность выше, чем совсем без них.
Должен вас предупредить: если вы нарушите правило, скажем, вставив строчный ключ (после хэширования/сжатия), то упакованную хэш-таблицу обязательно придётся преобразовать в классическую. С созданием всех необходимых ячеек преобразования и реорганизацией bucket«ов.
ZEND_API void ZEND_FASTCALL zend_hash_packed_to_hash(HashTable *ht)
{
void *new_data, *old_data = HT_GET_DATA_ADDR(ht);
Bucket *old_buckets = ht->arData;
ht->u.flags &= ~HASH_FLAG_PACKED;
new_data = pemalloc(HT_SIZE_EX(ht->nTableSize, -ht->nTableSize), (ht)->u.flags & HASH_FLAG_PERSISTENT);
ht->nTableMask = -ht->nTableSize;
HT_SET_DATA_ADDR(ht, new_data);
memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed);
pefree(old_data, (ht)->u.flags & HASH_FLAG_PERSISTENT);
zend_hash_rehash(ht);
}
Хэш-таблица
u.flags используется для того, чтобы определить, упакованная ли основная хэш-таблица. Если да, то её поведение будет отличаться от поведения традиционной хэш-таблицы, ей не понадобятся ячейки преобразования. В исходном коде вы можете найти немало мест, когда упакованные и классические хэши идут по разным ветвям кода. Например: static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag ZEND_FILE_LINE_DC)
{
uint32_t nIndex;
uint32_t idx;
Bucket *p;
/* ... */
if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) {
CHECK_INIT(ht, h < ht->nTableSize);
if (h < ht->nTableSize) {
p = ht->arData + h;
goto add_to_packed;
}
goto add_to_hash;
} else if (ht->u.flags & HASH_FLAG_PACKED) {
/* ... */
} else if (EXPECTED(h < ht->nTableSize)) {
p = ht->arData + h;
} else if ((h >> 1) < ht->nTableSize &&
(ht->nTableSize >> 1) < ht->nNumOfElements) {
zend_hash_packed_grow(ht);
p = ht->arData + h;
} else {
goto convert_to_hash;
}
/* ... */
Подытожим: упакованные хэш-таблицы позволяют оптимизировать использование и памяти, и процессора.
- Память: разница в потреблении байт по сравнению с классической:
(размер_таблицы - 2) * размер(uint32). Если у вас тысячи ячеек, то счёт идёт на килобайты. - Процессор: при каждой операции нам не нужно проверять ячейки преобразования и выполнять преобразование. Это экономит несколько процессорных инструкций на каждую операцию, что выливается в миллисекунды при работе с активно используемым массивом.
Тем не менее если вы начнёте использовать строчные ключи или нарушите порядок сортировки целочисленных ключей (скажем, вставите 42 после 60), то хэш-таблицу придётся конвертировать в «классическую». На это вы потратите немного ресурсов процессора (на крупных массивах — несколько больше) и дополнительный объём памяти. Для создания упакованной хэш-таблицы достаточно сказать API:
void ZEND_FASTCALL zend_hash_real_init(HashTable *ht, zend_bool packed)
Имейте в виду, что
zend_hash_real_init() — полный этап инициализации, а не «ленивый» (zend_hash_init()). Обычно, если инициализация «ленивая», то хэш-таблица изначально упакованная. А когда складываются соответствующие обстоятельства, она преобразуется в классический хэш. Массивы в РНРДавайте посмотрим, как можно проверить детали реализации хэш-таблиц в рамках пользовательского кода.
Память хэш-таблиц и оптимизация упакованных массивов
Сначала продемонстрируем оптимизацию упакованных массивов (packed array):
function m()
{
printf("%d\n", memory_get_usage());
}
$a = range(1,20000); /* range() создаёт упакованный массив */
m();
for($i=0; $i<5000; $i++) {
/* Продолжаем добавлять ключи в порядке возрастания,
* поэтому контракт упакованного массива всё ещё действителен:
* мы остаёмся в «упакованном» режиме */
$a[] = $i;
}
m();
/* Мы неожиданно нарушили контракт упакованного массива и заставили
* хэш-таблицу превратиться в «классическую», потратив больше
* памяти на ячейки преобразования */
$a['foo'] = 'bar';
m();
Как и ожидалось, результаты потребления памяти:
1406744
1406776
1533752
При переходе от упакованного массива к классическому хэшу потребление памяти выросло примерно на 130 Кб (для массива с 25 000 элементов).
Теперь продемонстрируем действие алгоритма уплотнения или увеличения:
function m()
{
printf("%d\n", memory_get_usage());
}
/* Размер хэш-таблицы соответствует двойке в степени. Давайте создадим
* массив из 32 768 ячеек (2^15). Используем упакованный массив */
for ($i=0; $i<32768; $i++) {
$a[$i] = $i;
}
m();
/* Теперь очистим его */
for ($i=0; $i<32768; $i++) {
unset($a[$i]);
}
m();
/* Добавим один элемент. Размер хэш-таблицы превысит предел,
* что запустит работу алгоритма уплотнения или увеличения */
$a[] = 42;
m();
Результаты:
1406864
1406896
1533872
Когда таблица заполнена и мы её опустошаем, потребляемая память не изменяется (шум по модулю, modulo noise). После применения
unset() к каждому значению наша таблица будет иметь arData на 32 768 ячеек, заполненных UNDEF-zval«ами.Теперь добавим что-нибудь в качестве следующего элемента. Помните nNumUsed, который используется для адресации arData и увеличивающийся при каждом добавлении? Теперь он переполнит размер таблицы, и нужно будет решать, уплотнять её или увеличивать размер.
Возможно ли уплотнение?
Ответ кажется очевидным — да, ведь у нас тут сплошные UNDEF-ячейки. Но на самом деле нет: нам нужно сохранять очерёдность данных, потому что мы используем упакованный массив и не хотели бы, чтобы он превратился в классический, пока нам совсем не припрёт. Если мы добавим элемент в уже существующую ячейку, то нарушим очерёдность, что запустит процедуру уплотнения, а не увеличения размера.
/* Код тот же, что и выше, но: */
/* здесь мы добавляем ещё один элемент к известному индексу (idx).
* Размер хэша переполнится, запустится алгоритм уплотнения или увеличения */
$a[3] = 42;
m();
Использование памяти:
1406864
1406896
1406896
Видите разницу? Теперь алгоритм не увеличил нашу таблицу с 32 768 до 65 538 ячеек, а уплотнил её. У таблицы в памяти всё ещё размещено 32 767 ячеек. А поскольку ячейка представляет собой
Bucket, внутри которого находится zval, чей размер равен long (в нашем случае 42), то память не изменяется. Ведь в zval уже входит размер long. :) Следовательно, теперь мы можем повторно использовать эти 32 768 ячеек, поместив в них целочисленные значения, булевы, с плавающей запятой. А если в качестве значений мы используем строки, объекты, другие массивы и т. д., то выделится дополнительная память, указатель на которую будет храниться в предварительно размещённых в памяти UNDEF-zval«ах нашего «горячего» массива.То же самое мы можем проделать с классической хэш-таблицей, просто используя строчные ключи. Когда мы переполним её на один элемент, таблица уплотнится, а не увеличится, потому что здесь не нужно сохранять очерёдность. Мы в любом случае находимся в «неупакованном» режиме, просто добавляем ещё одно значение на крайнюю левую позицию (idx 0), а все последующие — это UNDEF-zval.
function m()
{
printf("%d\n", memory_get_usage());
}
/* Размер хэш-таблицы соответствует двойке в степени. Давайте создадим
* массив из 32 768 ячеек (2^15). Здесь мы НЕ используем упакованный массив */
for ($i=0; $i<32768; $i++) {
/* возьмём строковый ключ, чтобы у нас был классический хэш */
$a[' ' . $i] = $i;
}
m();
/* теперь очистим его */
for ($i=0; $i<32768; $i++) {
unset($a[' ' . $i]);
}
m();
/* здесь мы добавляем ещё один элемент к известному индексу.
* Размер хэша переполнится, запустится алгоритм уплотнения или увеличения */
$a[] = 42;
m();
Результаты по памяти:
2582480
1533936
1533936
Как и ожидалось. Массив потребляет около 2,5 Мб. После применения
unset() ко всем значениям потребление памяти снижается, мы освобождаем ключи. У нас 32 768 ключей zend_string, и после их освобождения массив начинает потреблять 1,5 Мб.Если теперь добавить один элемент, то произойдёт переполнение внутреннего размера таблицы, что запустит алгоритм уплотнения или увеличения. Поскольку массив не упакованный, не нужно сохранять очерёдность элементов, и таблица будет уплотнена. Новое значение 42 записывается в idx 0, объём памяти не меняется. Конец истории.
Как видите, в некоторых редких случаях упакованные хэш-таблицы могут нам даже навредить, увеличившись в размере вместо уплотнения. Но разве в реальных проектах вы станете использовать такой глупый код? Это не должно влиять на повседневное программирование, но если вам нужна действительно высокая производительность (фреймворки, вы меня слышите?) и/или вы хотите оптимизировать высоконагруженные пакетные скрипты, то это может быть хорошим решением. Вместо того чтобы ломать голову над переходом к чистому С при решении подобных задач. Если у вас нет многих тысяч элементов, то потребление памяти будет смехотворным. Но в наших примерах было «всего» от 20 до 32 тысяч элементов, а разница измерялась в килобайтах и мегабайтах.
Неизменяемые массивы (Immutable arrays)
Неизменяемые массивы — это характерная особенность OPCache. Не включив OPCache, вы не сможете воспользоваться преимуществами неизменяемых массивов, т. е. доступных только для чтения. Если же OPCache активирован, то он просматривает содержимое каждого скрипта и пытается скопировать многие вещи в совместно используемую память. В частности, константные AST-ноды. Собственно, константный массив — это константная AST-нода. Например:
$a = ['foo', 1, 'bar'];
Здесь
$a — константная AST-нода. Компилятор определяет, что это заполненный константами массив, и превращает его в константную ноду. Далее OPCache просматривает все скрипты в AST-ноде, копирует их связанный с процессом адрес (адрес кучи) в сегмент совместной используемой памяти, а затем этот адрес освобождает. Дополнительную информацию об OPCache вы можете найти в обзоре этого расширения.Кроме того, OPCache превращает массивы в неизменяемые, устанавливая им флаги IS_ARRAY_IMMUTABLE и IS_TYPE_IMMUTABLE. Когда движок встречает IS_IMMUTABLE, он обращается с этими данными особым образом. Если вы преобразуете неизменяемый массив в переменную, то он не будет дуплицирован. В противном случае создаётся полная копия массива.
Пример описанной оптимизации:
$ar = [];
for ($i = 0; $i < 1000000; ++$i) {
$ar[] = [1, 2, 3, 4, 5, 6, 7, 8];
}
Этот скрипт потребляет около 400 Мб памяти без OPCache, а с ним — примерно 35 Мб. Если OPCache отключён, то в скрипте движок создаёт полную копию 8-элементного массива в каждом слоте
$ar. В результате в памяти размещается один миллион 8-слотовых массивов. А если включить OPCache, то он пометит 8-слотовый массив как IS_IMMUTABLE и при запуске скрипта в слоты $ar будет копироваться всего лишь указатель массива, что предотвращает полное дуплицирование в каждом цикле. Очевидно, что если позднее вы измените один из этих массивов, скажем, $ar[42][3] = 'foo';, то 8-слотовый массив в $ar[42] будет полностью дуплицирован механизмом копирования при записи.
Во вну
