[Перевод] Машинное обучение в канализации (в хорошем смысле)
Сточные воды… Казалось бы, что тут может быть связанного с технологиями. Ну, возможно, какой-нибудь датчик загрязненности. Но, оказывается, нет. Все намного интереснее. Ведь машинное обучение помогает выявлять аномалии и отклонения в системе контроля сточных вод. Подробности под катом!

Обзор
В следующем примере кода представлен инновационный метод выявления аномалий и ожидаемых отклонений с помощью Microsoft Anomaly Detection API и двоичной классификации, поддерживающей фильтрацию динамических рядов.
Ситуация
Компания Carl Data Solutions разрабатывает программные инструменты Flow Works, используемые муниципальными организациями для контроля инфраструктуры сточных вод. Эти инструменты получают данные со множества датчиков, измеряющих такие показатели, как расход воды, скорость и глубина.
Датчики иногда выходят из строя или ведут себя непредсказуемым образом, что вызывает отклонения показателей. Поскольку прогностические модели создаются на основе полученных с датчиков показаний, их отклонения могут снизить точность модели. В настоящее время муниципальные организации, использующие инструменты Carl Data Flow Works, прибегают к услугам консультантов, которые вручную проверяют данные со всех датчиков и изменяют значения, представляющиеся ошибочными, для устранения таких неточностей.
Выборка суточных показаний счетчика с маркированными аномалиями
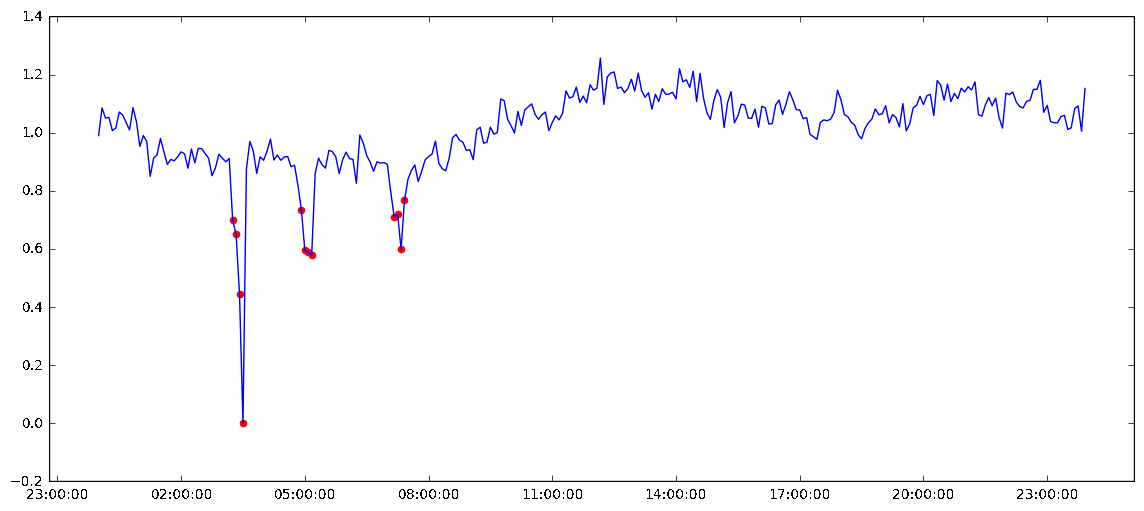
Чтобы избежать дополнительных временных и финансовых затрат, компания Carl Data решила создать модель выявления аномалий, которая позволила бы автоматизировать обнаружение таких ошибок.
Проблема
Поскольку ошибки в работе датчиков случаются нечасто, обучающие множества, которые сформированы на основе журналов, отобранных Carl Data, содержали гораздо больше «точных» значений, чем «неточных». В случае неравномерного распределения обучающих образцов традиционные двоичные классификаторы в отдельных случаях могут не выявлять ошибки датчиков ввиду большого количества положительных примеров. Зачастую для выявления нерегулярного потока используются неконтролируемые алгоритмы обнаружения отклонений динамических рядов.
Однако такие неконтролируемые системы выявления отклонений, как Twitter Anomaly Detection Package или Microsoft Anomaly Detection API, хотя и справляются с задачей обнаружения нерегулярных потоков, все равно не могут отличить ожидаемые отклонения в поведении (например, пиковые значения в случае наводнений) от ошибок датчика. Кроме того, эти API выполняют только пакетную классификацию, которая отнимает слишком много времени, чтобы эффективно работать в режиме реального времени.
Взаимодействие
Microsoft помогает компании Carl Data в разработке модели обнаружения аномалий, способной идентифицировать различные типы отклонений от нормы, и передаче ее в производственную среду посредством концентраторов событий и PowerBI.
Методика обнаружения аномалий методом машинного обучения
Модель 1. Обнаружение отклонений (неконтролируемый алгоритм)
- Считайте необработанные статистические данные, полученные от датчика скорости.
- Считайте маркированные аномалии из отобранных данных для датчика скорости.
- Отправьте необработанные данные в Microsoft Anomaly Detection API, чтобы маркировать отклонения.
- Оцените модель отклонения на основе результатов Anomaly Detection API, сопоставив полученные с ее помощью результаты с «аномалиями, маркированными вручную».
Модель 2. Двоичный классификатор (контролируемый)
- Считайте необработанные статистические данные, полученные от датчика скорости.
- Выполните считывание и объединение маркированных аномалий из отобранных данных для датчика скорости.
- Создайте окно истории для предыдущих четырех значений показаний на основе данных от датчика скорости на каждый момент времени.
- Создайте обучающее и тестовое множество путем произвольного разделения данных в окнах истории.
- Обучите классификатор случайного леса, используя обучающие данные.
- Измерьте производительность случайного леса на основе тестовых данных.
Модель 3. Гибридный классификатор (дифференциация аномалий и отклонений)
- Считайте необработанные статистические данные, полученные от датчика скорости.
- Считайте маркированные аномалии из отобранных данных для датчика скорости.
- Отправьте необработанные данные в Microsoft Anomaly Detection API, чтобы маркировать отклонения.
- Создайте окно истории для четырех предыдущих значений показаний, полученных от датчика скорости, на каждый момент времени, используя только значения, помеченные как отклонения.
- Создайте обучающее и тестовое множество путем произвольного разделения данных в окнах истории.
- Обучите классификатор случайного леса, используя обучающие данные.
- Измерьте производительность случайного леса на основе тестовых данных.
- Измерьте производительность случайного леса для всего динамического ряда скорости за исключением обучающего множества.
Методика интеграции

- Передайте данные из канала в концентратор событий Anomaly Detection, установив размер окна равным n.
- Маркируйте новые события как «аномалия» или «не аномалия», используя модель, построение которой описано в последнем разделе.
- Передайте маркированные данные канала в концентратор событий визуализации.
- Используйте потоковую аналитику для обработки данных из концентратора событий визуализации.
- Импортируйте данные потоковой аналитики в PowerBI, чтобы визуализировать маркированные аномалии.
Результаты
В процессе взаимодействия мы создали три модели, скомбинировав Microsoft Anomaly Detection API с набором случайных лесов и логистической регрессией, чтобы выявить ошибку датчика.
Хотя Anomaly Detection API позволяет выявить отклонения идентификатора в целях классификации аномалий, в наборе данных Carl Data разница между аномалиями и регулярным потоком была линейно дифференцируемой достаточно, чтобы получать сопоставимо качественный результат как при использовании двоичного классификатора случайного леса, так и в комбинации с Anomaly Detection API.
В отдельных случаях аналитики могут вручную помечать как аномальные значения в границах аномального пика датчика. Anomaly Detection API не может корректно маркировать такие значения. Тем не менее, если ошибка датчика представлена более наглядно и аномалии не являются линейно дифференцируемыми в достаточной степени, гибридный метод дает более обобщенные результаты, чем при использовании только двоичного классификатора.
Выбранная модель имеет следующие характеристики производительности с высокой степенью точности (99%) и полноты возврата (100%):
Измерение производительности модели с использованием обучаемого модуля теста производительности SciKit

Код
Исходный код и заметки по использованию описанного метода см. на GitHub.
Варианты использования
Методика, изложенная в этом примере кода, важна с точки зрения применения машинного обучения динамических рядов в таких мало охваченных областях, как контроль сточных вод.
Кроме того, по мере развития Интернета вещей и перехода от агрегирования данных к прогнозной аналитике все большее значение приобретает возможность различать аномалии, вызванные ошибками датчика, от аномалий, представляющих собой ожидаемые отклонения. Подход, изложенный в этом примере кода, рекомендуется использовать как раз в этих случаях.
