[Перевод] Краткий пересказ вебинара про релиз YDB v23.1

Восемь разработчиков YDB собрались, чтобы поделиться тем, что они сделали для последнего релиза YDB v23.1. Рассмотренные новые возможности можно разделить на две категории: функциональные улучшения и улучшения производительности. Давайте начнем с первой.
Начальное сканирование для механизма Change Data Capture (CDC)
Автор — Ильназ Низаметдинов
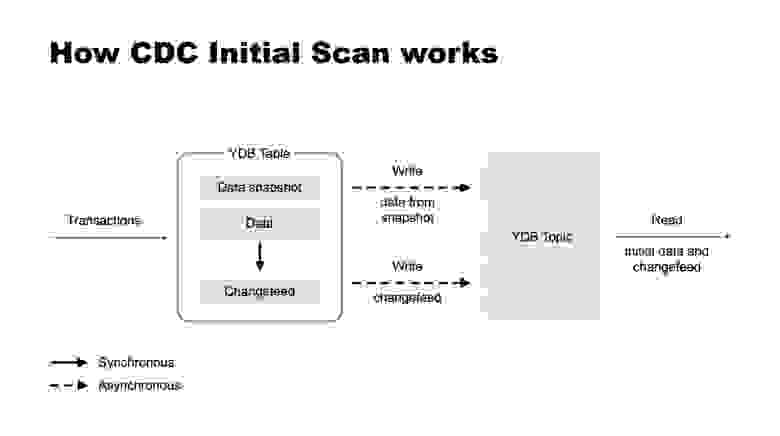
Change Data Capture — это механизм, который позволяет создавать поток изменений данных в таблицах и использовать его в других системах. В YDB он реализован поверх YDB topics, надёжных персистентных очередей, похожих по возможностям на Apache Kafka®. Обычно CDC отправляет только те изменения, которые происходят после его включения и настройки. Но бывают и сценарии, когда в целевой системе нужны все существующие данные, включая записанные ранее. Именно в этом случае пригодится появившаяся в версии v23.1 опция начального сканирования для CDC. С этой опцией CDC передаёт текущее состояние на момент создания в том же формате, что и последующие изменения. Гарантируется, что текущее состояние будет отправлено до начала изменений. Ранее для получения того же результата приходилось вручную разбираться какие данные были в таблице до начала подписки и копировать их отдельно другими средствами.
Улучшения в аудитном логе

Автор — Андрей Рыков
Вторая реализованная возможность, о которой шла речь — это журнал аудита, который часто воспринимается как базовая необходимость любой командой безопасности. Данные в таком логе являются бесценным ресурсом для аудиторов, который они могут использовать, чтобы выявлять несанкционированную деятельность, управлять системными взаимодействиями и расследовать инциденты. В этом релизе добавлена возможность регистрации изменений в объектах схемы YDB: базах данных, каталогах, таблицах и топиках. Кроме того, он регистрирует изменения в количестве партиций, операциях резервного копирования и восстановления, в изменениях настроек доступа и многом другом.
Улучшения производительности
Автоматическая конфигурация пулов акторной системы
Автор — Александр Крюков
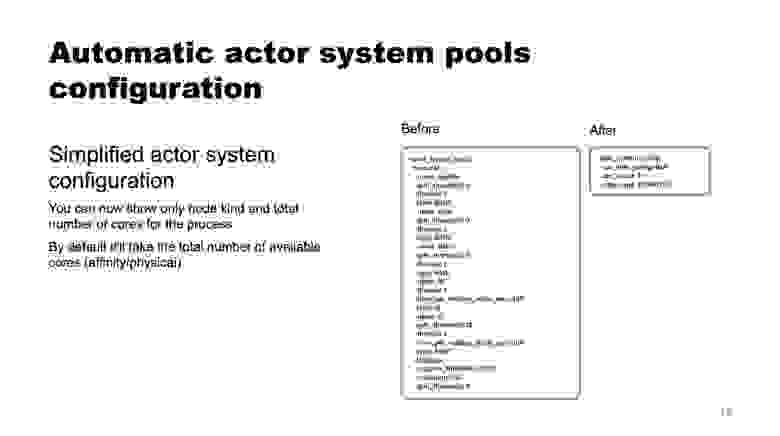
Акторная система YDB — среда для параллельных вычислиений на C++, на основе которой построена YDB. Акторы — это легковесные вычислительные единицы, которые общаются друг с другом посредством передачи сообщений (message passing), как локально, так и через сеть. Узлы YDB выполняют код акторов в нескольких пулах потоков. Конфигурация пулов потоков ранее была довольно сложной, но теперь она имеет автоматический режим с динамическим распределением размера пулов на основе текущей загрузки системы и количества доступных ядер процессора.
Улучшение форматов передачи данных между этапами выполнения запросов
Автор — Виталий Гриднев
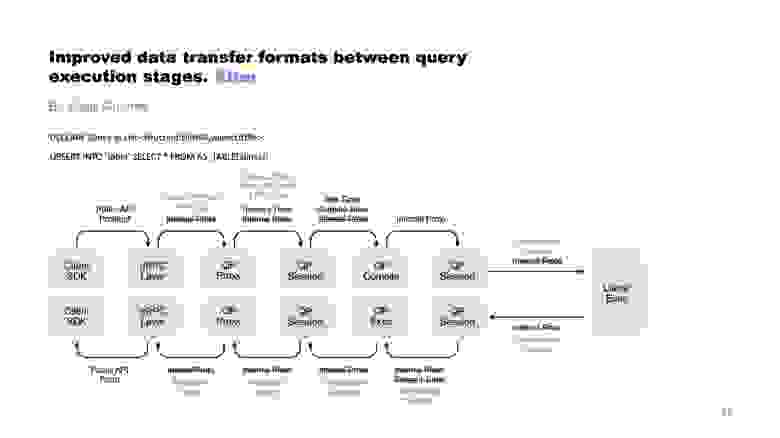
Выполнение запроса YDB состоит из нескольких этапов и каждый из них передаёт текущие данные следующему. Мы заменили часть форматов передачи таким образом, чтобы не перекладывать одни и те же данные из одного формата в другой, если это возможно. Кроме того, мы избавились от избыточных таймеров. Эти изменения позволили сэкономить до 30% вычислительных ресурсов при релизе на наши высоконагруженные кластера.
Кэш шаблонов вычислительного графа
Автор — Владислав Кузнецов
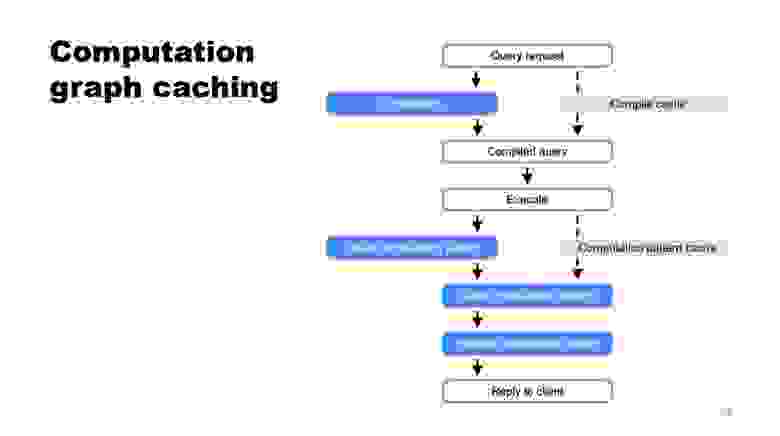
Если мы более детально рассмотрим сам процесс вычисления результата запроса, то можно выделить три основных шага:
Компиляция запроса
Построение шаблона вычислительного графа
Выполнение вычислительного графа
В сценарии транзакционной нагрузки (OLTP) первые два этапа могут быть гораздо более затратными, чем третий. Очевидным решением является кэширование их результатов. В YDB уже давно был кэш компиляции запросов, а в версии 23.1 появился новый кэш для второго этапа — шаблонов вычислительного графа. При обнаружении подходящего шаблона в кэше он клонируется, обогащается временными значениями и в результате становится готовым к выполнению вычислений.
Улучшение вторичных индексов
Вторичные индексы являются ещё одной важной функцией для производительности системы управления базами данных. В этом выпуске YDB мы внесли улучшения для двух сценариев, связанных с вторичными индексами.

Автор — Даниил Чередник
В YDB вторичные индексы имеют имена и, на момент написания, имя индекса необходимо явно указывать при написании SQL запросов. Таким образом, в производственном окружении может быть полезной замена индекса под определенным именем, например, для добавления столбцов, покрытых индексом. Чтобы учесть такой сценарий, YDB теперь поддерживает атомарную замену вторичных индексов.
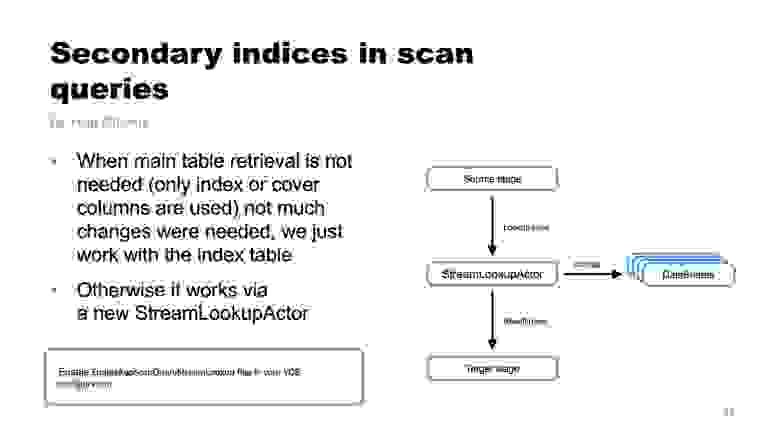
Автор — Юлия Сидорина
YDB позволяет выполнять два типа запросов: запросы данных (data query) для транзакционных (OLTP) нагрузок и сканирующие запросы (scan query) для аналитических (OLAP) нагрузок. Изначально только запросы данных могли использовать вторичные индексы, а теперь сканирующие запросы тоже могут. Однако эта функция ещё не готова для использования в производственных окружениях и не включена по умолчанию в версии 23.1, но вы все равно можете поэкспериментировать с ней, если включите указанную на слайде настройку EnableKqpScanQueryStreamLookup.
Улучшение оптимизации предикатов для чтения таблиц

Автор — Михаил Сурин
На уровне ввода-вывода базы данных как правило стараются считывать с дисков лишь минимальный объём данных, необходимый для получения запрошенного результата. В этом релизе YDB мы устранили ещё один случай, когда выполнялось избыточное полное сканирование таблицы при использовании запроса с оператором OR в условии для чтения нескольких диапазонов таблицы по первичному ключу.
Что дальше?
Если вы хотите узнать больше о упомянутых выше функциях YDB, просмотрите видеоверсию этого вебинара (в её описании также есть таймкоды) или следуйте по ссылкам из релизных заметок.
Если у вас установлена более старая версия YDB, мы рекомендуем обновиться в ближайшее удобное время, скачав последний релиз и следуя инструкциям по обновлению.
