[Перевод] Конференция QCon. Овладение хаосом: руководство Netflix для микросервисов. Часть 4
Джош Эванс рассказывает о хаотичном и ярком мире микросервисов Netflix, начиная с самых основ — анатомии микросервисов, проблем, связанных с распределенными системами и их преимуществ. Опираясь на этот фундамент, он исследует культурные, архитектурные и операционные методы, которые ведут к овладению микросервисами.
Конференция QCon. Овладение хаосом: руководство Netflix для микросервисов. Часть 1
Конференция QCon. Овладение хаосом: руководство Netflix для микросервисов. Часть 2
Конференция QCon. Овладение хаосом: руководство Netflix для микросервисов. Часть 3
В отличии от operational drift, внедрение новых языков для интернационализации сервиса и новых технологий, таких как контейнеры, — это сознательные решения добавить новую сложность в окружающую среду. Моя группа операционистов стандартизировала «асфальтированную дорогу» лучших технологий для Netflix, которые «запекались» в заранее определенных наилучших практиках, основанных на Java и EC2, однако по мере развития бизнеса разработчики стали добавлять новые компоненты, такие как Python, Ruby, Node-JS и Docker.

Я очень горжусь тем, что мы первыми сами выступали за то, чтобы наш продукт отлично работал, не дожидаясь жалоб клиентов. Все начиналось достаточно просто — у нас были операционные программы на Python и несколько бэк-офисных приложений на Ruby, но все стало намного интересней, когда наши веб-разработчики заявили, что намерены отказаться от JVM и собираются перевести веб-приложение на программную платформу Node.js. После внедрения Docker вещи стали намного сложнее. Мы руководствовались логикой, и придуманные нами технологии стали реальностью, когда мы внедрили их для клиентов, потому что они имели большой смысл. Расскажу вам, почему это так.
API-шлюз на самом деле имеет возможность интеграции отличных скриптов, которые могут действовать как endpoints для разработчиков пользовательского интерфейса. Они конвертировали каждый из этих скриптов таким образом, что после внесения изменений могли развернуть их на продакшн и далее на устройства пользователей, и все эти изменения синхронизировались с endpoints, которые запускались в API-шлюзе.
Однако это повторило проблему создания нового монолита, когда служба API была перегружена кодом так, что возникали различные сценарии сбоев. Например, некоторые конечные точки удалялись или же скрипты случайным образом генерировали так много версий чего-либо, что эти версии занимали всю доступную память API-сервиса.
Логично было взять эти endpoints и вытянуть их из API-сервиса. Для этого мы создали компоненты Node.js, которые запускались как небольшие приложения в контейнерах Docker. Это позволило изолировать любые неполадки и сбои, вызванные этими node-приложениями.
Стоимость этих изменений достаточно велика и складывается из следующих факторов:
- Инструменты повышения производительности. Управление новыми технологиями требовало новых инструментов, потому что UI-команда, использующая очень удачные скрипты для создания эффективной модели, не должна была тратить много времени на управление инфраструктурой, она должна была заниматься только написанием скриптов и проверкой их работоспособности.
Инсайт и сортировка возможностей — ключевым примером являются новые инструменты, необходимые для выявления информации о факторах производительности. Нужно было знать, на сколько % занят процессор, как используется память, и сбор этой информации требовал разных инструментов. - Фрагментация базовых образов — простая базовая AMI стала более фрагментированной и специализированной.
- Управление узлами. Не существует доступной готовой архитектуры или технологий, которые позволяют управлять узлами в облаке, поэтому мы создали Titus — платформу управления контейнерами, которая обеспечивает масштабируемое и надежное развертывание контейнеров и облачную интеграцию с Amazon AWS.
- Дублирование библиотеки или платформы. Предоставление новым технологиям одних и тех же основных функций платформы потребовало ее дублирования в облачные инструменты разработчиков Node.js.
- Кривая обучения и производственный опыт. Внедрение новых технологий неизбежно создает новые проблемы, которые необходимо преодолеть и извлечь из них уроки.
Таким образом, мы не могли ограничиться одной «асфальтированной дорогой» и должны были постоянно строить новые пути для продвижения своих технологий. Для снижения стоимости мы ограничивали централизованную поддержку и фокусировались на JVM, новых узлах и Docker. Мы расставляли приоритеты по степени эффективного воздействия, информировали команды о стоимости принятых ими решений и стимулировали их искать возможность многократного использования уже разработанных эффективных решений. Мы использовали этот подход при переводе сервиса на иностранные языки для доставки продукта интернациональным клиентам. Примерам могут служить относительно простые клиентские библиотеки, которые могут генерироваться автоматически, так что достаточно легко создавать Python-версию, Ruby-версию, Java-версию и т.д.
Мы постоянно искали возможность использовать обкатанные технологии, которые отлично зарекомендовали себя в одном месте, и в других похожих ситуациях.
Давайте поговорим о последнем элементе — изменениях, или вариациях. Посмотрите, как неравномерно меняется потребление нашего продукта по дням недели и по часам на протяжение суток. Можно сказать, что в 9 утра для Netflix наступает время тяжелых испытаний, когда нагрузка на систему достигает максимума.

Как можно достичь высокой скорости внедрения программных инноваций, то есть постоянно вносить новые изменения в систему, не вызывая перерывов в доставке сервиса и не создавая неудобств нашим клиентам? Netflix добились этого благодаря использованию Spinnaker — новой глобальной облачной платформы управления и непрерывной доставки (СD).

Критически важно, что Spinnaker был разработан для интеграции наших лучших практик так, чтобы по мере развертывания компонентов в продакшн мы можем интегрировать их результат непосредственно в технологию доставки медиаконтента.

Нам удалось использовать в конвейере доставки две технологии, которые мы высоко ценим: автоматизированный canary-анализ и поэтапное развертывание. Canary-анализ означает, что мы направляем ручеек трафика в новую версию кода, а остальной продакшн-трафик пропускаем через старую версию. Затем мы проверяем, как справляется с задачей новый код — лучше или хуже существующего.
Поэтапное развертывание означает, что если с развертыванием в одном регионе происходят проблемы, мы переходим к развертыванию в другом регионе. При этом в конвейер продакшена обязательно включается упомянутый выше чеклист. Я немного сэкономлю время и порекомендую вам ознакомится с моим предыдущим выступлением «Инжиниринг глобальных операций Netflix в облачном сервисе», если у вас есть желание поглубже разобраться с этим вопросом. Видеозапись выступления можно посмотреть, пройдя по ссылке внизу слайда.

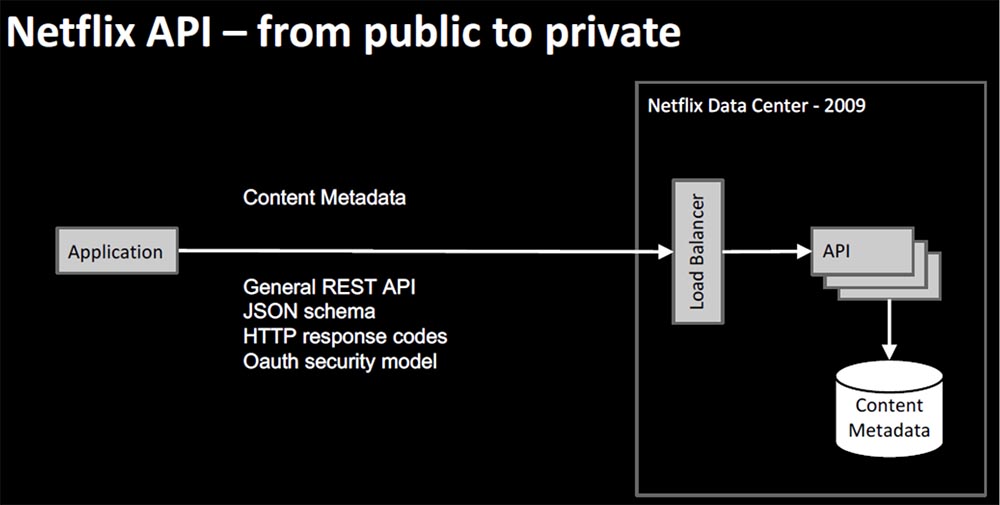
В конце выступления я коротко расскажу об организации и архитектуре Netflix. В самом начале у нас была схема под названием Electronic Delivery — электронная доставка, представлявшая собой первую версию потоковой передачи медиаконтента NRDP 1.x. Здесь можно использовать термин «обратный поток», потому что изначально пользователь мог только скачивать контент для последующего воспроизведения на устройстве. Самая первая платформа электронной доставки Netflix образца 2009 года выглядела примерно так.

Пользовательское устройство содержало в себе приложение Netflix, которое состояло из интерфейса UI, модулей безопасности, активации сервиса и воспроизведения, базирующихся на платформе NRDP — Netflix Ready Device Platform.
В то время пользовательский интерфейс был очень прост. Он содержал так называемый Queque Reader, и пользователь заходил на сайт, чтобы добавить что-то в Queque, а затем просматривал добавленный контент на своем устройстве. Положительным было то, что клиентская команда и серверная команда принадлежали одной организации Electronic Delivery и имели тесные рабочие взаимоотношения. Полезная нагрузка была создана на основе XML. Параллельно был создан API Netflix для DVD бизнеса, который стимулировал сторонние приложения направлять трафик в наш сервис.
Однако Netflix API был хорошо подготовлен к тому, чтобы помочь нам с инновационным пользовательским интерфейсом, в нем содержались метаданные всего контента, сведения о том, какие фильмы доступны, что создавало возможность генерировать списки просмотра. У него был общий REST API, базирующийся на схеме JSON, HTTP Response Code, такой же, что используется в современной архитектуре, и модель безопасности OAuth — то, что требовалось в то время для внешнего приложения. Это позволило перейти от публичной модели доставки потокового контента к приватной.
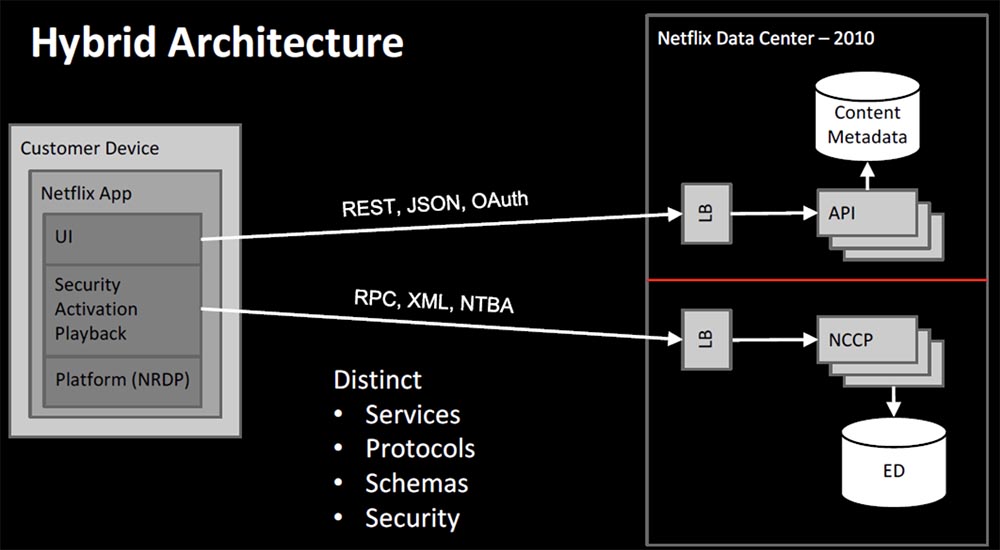
Проблема перехода заключалась во фрагментации, так как теперь в нашей системе функционировали два сервиса, основанные на совершенно разных принципах работы — один на Rest, JSON и OAuth, другой на RPC, XML и механизме безопасности пользователей на основе системы токенов NTBA. Это была первая гибридная архитектура.
По существу между двумя нашими командами существовал файрвол, потому что первоначально API не очень хорошо масштабировался с помощью NCCP, и это приводило к разногласиям между командами. Различия заключались в сервисах, протоколах, схемах, модулях безопасности, и разработчиками часто приходилось переключаться между совершенно разными контекстами.
В связи с этим у меня был разговор с одним из старших инженеров компании, которому я задал вопрос: «Что должна представлять собой правильная долгосрочная архитектура?», и он задал встречный вопрос: «Вероятно, тебя больше волнуют организационные последствия — что произойдет, если мы интегрируем эти вещи, а они сломают то, что мы хорошо научились делать?». Этот подход очень актуален для закона Конвея: «Организации, проектирующие системы, ограничены дизайном, который копирует структуру коммуникации в этой организации». Это очень абстрактное определение, поэтому я предпочитаю более конкретное: «Любая часть программного обеспечения отражает организационную структуру, которая его создала». Приведу вам мое любимое высказывание, принадлежащее Эрику Реймонду: «Если над компилятором работают четыре команды разработчиков, то в итоге вы получите четырехпроходный компилятор». Что же, Netflix имеет четырехпроходный компилятор, и это то, как мы работаем.
Можно сказать, что в этом случае хвост машет собакой. У нас на первом месте не решение, а организация, именно она является драйвером архитектуры, которую мы имеем. Постепенно от мешанины сервисов мы перешли к архитектуре, которую назвали Blade Runner — «Бегущий по лезвию», потому что здесь речь идет о граничных сервисах и возможностях NCCP разделяться и интегрироваться напрямую в Zuul-прокси, API-шлюз, причем соответствующие функциональные «куски» были превращены в новые микросервисы с более продвинутыми функциями безопасности, воспроизведения, сортировки данных и т.д.
Таким образом, можно сказать, что ведомственные структуры и динамика развития компании играют важную роль в формировании дизайна систем и являются фактором, способствующим или препятствующим изменениям. Архитектура микросервисов является комплексной и органичной, а ее здоровье базируется на дисциплине и внедряемом хаосе.
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
