[Перевод] Когда «Zoë» !== «Zoë», или почему нужно нормализовывать Unicode-строки
Никогда не слышали о нормализации Unicode? Вы не одиноки. Но об этом надо знать всем. Нормализация способна избавить вас от множества проблем. Рано или поздно нечто подобное тому, что показано на следующем рисунке, случается с любым разработчиком.
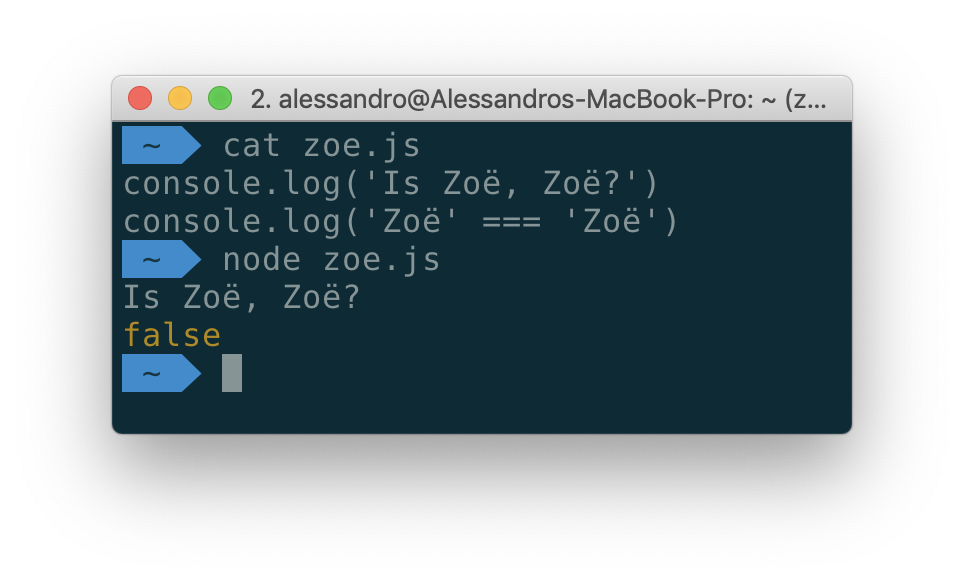
«Zoë» — это не «Zoë»
И это, кстати, не пример очередной странности JavaScript. Автор материала, перевод которого мы сегодня публикуем, говорит, что может показать, как та же проблема проявляется при использовании практически каждого из существующих языков программирования. В частности, речь идёт о Python, Go, и даже о сценариях командной оболочки. Как с этим бороться?
Предыстория
Я впервые столкнулся с проблемой Unicode много лет назад, когда писал приложение (на Objective-C), которое импортировало список контактов из адресной книги пользователя и из его социальных сетей, после чего исключало дубликаты. В определённых ситуациях оказывалось так, что некоторые люди присутствуют в списке дважды. Происходило это из-за того, что их имена, по мнению программы, не являлись одинаковыми строками.
Хотя в вышеприведённом примере две строки выглядят абсолютно одинаково, то, как они представлены в системе, те байты, в виде которых они сохранены на диске, различаются. В первом имени "Zoë" символ ë (e с умлаутом) представляет собой одну кодовую точку Unicode. Во втором случае мы имеем дело с декомпозицией, с подходом к представлению знаков с помощью нескольких символов. Если вы, в своём приложении, работаете с Unicode-строками, вам нужно учитывать то, что одни и те же символы могут быть представлены разными способами.
Как мы пришли к эмодзи: в двух словах о кодировании символов
Компьютеры работают с байтами, которые представляют собой всего лишь числа. Для того чтобы получить возможность обрабатывать на компьютерах тексты, люди договорились о соответствии символов и чисел, и пришли к соглашениям о том, как должно выглядеть визуальное представление символов.
Первое подобное соглашение было представлено кодировкой ASCII (American Standard Code for Information Interchange). Эта кодировка использовала 7 бит и могла представлять 128 символов, в состав которых входили латинский алфавит (прописные и строчные буквы), цифры и основные знаки пунктуации. В ASCII также входило множество «непечатаемых» символов, таких, как символ перевода строки, знак табуляции, символ возврата каретки и другие. Например, в ASCII латинская буква M (прописная m) кодируется в виде числа 77 (4D в шестнадцатеричном представлении).
Проблема ASCII заключается в том, что хотя 128 знаков может быть достаточно для представления всех символов, которыми обычно пользуются люди, работающие с англоязычными текстами, этого количества символов недостаточно для представления текстов на других языках и разных особых символов вроде эмодзи.
Решением этой проблемы стало принятие стандарта Unicode, который был нацелен на возможность представления каждого символа, используемого во всех современных и древних текстах, включая и символы вроде эмодзи. Например, в совсем недавно вышедшем стандарте Unicode 12.0 насчитывается более 137000 символов.
Стандарт Unicode может быть реализован с использованием множества способов кодирования символов. Самые распространённые — это UTF-8 и UTF-16. Надо отметить, что в веб-пространстве сильнее всего распространён стандарт кодирования текстов UTF-8.
Стандарт UTF-8 использует для представления символов от 1 до 4 байт. UTF-8 представляет собой надмножество ASCII, поэтому первые его 128 символов совпадают с символами, представленными в кодовой таблице ASCII. Стандарт UTF-16, с другой стороны, использует для представления 1 символа от 2 до 4 байт.
Почему существуют и тот и другой стандарты? Дело в том, что тексты на западных языках обычно эффективнее всего кодируются с использованием стандарта UTF-8 (так как большинство символов в таких текстах могут быть представлены в виде кодов размером в 1 байт). Если же говорить о восточных языках, то можно сказать, что файлы, хранящие тексты, написанные на этих языках, обычно получаются меньше при использовании UTF-16.
Кодовые точки Unicode и кодирование символов
Каждому символу в стандарте Unicode назначен идентификационный номер, который называется кодовой точкой. Например, кодовой точкой эмодзи  является U+1F436.
является U+1F436.
При кодировании этого значка он может быть представлен в виде различных последовательностей байтов:
- UTF-8: 4 байта,
0xF0 0x9F 0x90 0xB6 - UTF-16: 4 байта,
0xD83D 0xDC36
В JavaScript-коде, представленном ниже, все три команды выводят в консоль браузера один и тот же символ.
// Так соответствующая последовательность байтов просто включается в код
console.log('') // =>
// Тут используется кодовая точка Unicode (ES2015+)
console.log('\u{1F436}') // =>
// Тут используется представление этого символа в стандарте UTF-16
// с применением двух кодовых единиц (по 2 байта каждая)
console.log('\uD83D\uDC36') // =>
Во внутренних механизмах большинства JavaScript-интерпретаторов (включая Node.js и современные браузеры) используется UTF-16. Это означает, что рассматриваемый нами значок с собакой хранится с использованием двух кодовых единиц UTF-16 (по 16 бит каждая). Поэтому то, что выводит следующий код, не должно показаться вам непонятным:
console.log(''.length) // => 2
Комбинирование символов
Теперь вернёмся к тому, с чего мы начали, а именно, поговорим о том, почему символы, выглядящие для человека одинаково, имеют различное внутреннее представление.
Некоторые символы в кодировке Unicode предназначены для модификации других символов. Их называют комбинируемыми символами (combining characters). Они применяются к базовым символам (base characters) Например:
n + ˜ = ñu + ¨ = üe + ´ = é
Как видно из предыдущего примера, комбинируемые символы позволяют добавлять к базовым символам диакритические знаки. Но на этом возможности Unicode по трансформации символов не ограничиваются. Например, некоторые последовательности символов могут быть представлены в виде лигатур (так ae может превратиться в æ).
Проблема заключается в том, что особенные символы могут быть представлены различными способами.
Например, букву é можно представить двумя способами:
- С помощью одной кодовой точки U+00E9.
- С помощью комбинации буквы e и знака акута, то есть — с помощью двух кодовых точек — U+0065 и U+0301.
Символы, получившиеся в результате применения любого из этих способов представления буквы é, будут выглядеть одинаково, но при их сравнении окажется, что символы это разные. Строки, содержащие их, будут иметь разную длину. Убедиться в этом можно, выполнив следующий код в консоли браузера.
console.log('\u00e9') // => é
console.log('\u0065\u0301') // => é
console.log('\u00e9' == '\u0065\u0301') // => false
console.log('\u00e9'.length) // => 1
console.log('\u0065\u0301'.length) // => 2
Это может привести к неожиданным ошибкам. Например, они могут выражаться в том, что программа, по непонятным причинам, не способна найти в базе данных некоторые записи, в том, что пользователь, вводя правильный пароль, не может войти в систему.
Нормализация строк
У вышеописанных проблем есть простое решение, которое заключается в нормализации строк, в приведении их к «каноническому представлению».
Существуют четыре стандартных формы (алгоритма) нормализации:
- NFC: Normalization Form Canonical Composition.
- NFD: Normalization Form Canonical Decomposition.
- NFKC: Normalization Form Compatibility Composition.
- NFKD: Normalization Form Compatibility Decomposition.
Чаще всего используется форма нормализации NFC. При использовании этого алгоритма все символы сначала подвергаются декомпозиции, после чего все комбинирующиеся последовательности подвергаются повторной композиции в порядке, определяемом стандартом. Для практического применения можно выбрать любую форму. Главное — применять её последовательно. В результате поступление на вход программы одних и тех же данных всегда будет приводить к одному и тому же результату.
В JavaScript, начиная со стандарта ES2015 (ES6), имеется встроенный метод для нормализации строк — String.prototype.normalize ([form]). Пользоваться им можно в среде Node.js и практически во всех современных браузерах. Аргумент form этого метода представляет собой строковой идентификатор формы нормализации. По умолчанию используется форма NFC.
Вернёмся к ранее рассмотренному примеру, применив на этот раз нормализацию:
const str = '\u0065\u0301'
console.log(str == '\u00e9') // => false
const normalized = str.normalize('NFC')
console.log(normalized == '\u00e9') // => true
console.log(normalized.length) // => 1
Итоги
Если вы разрабатываете веб-приложение и используете в нём то, что вводит пользователь, всегда выполняйте нормализацию полученных текстовых данных. В JavaScript для выполнения нормализации можно воспользоваться стандартным методом строк normalize ().
Уважаемые читатели! Сталкивались ли вы с проблемами, возникающими при работе со строками, решить которых можно с помощью нормализации?

