[Перевод] Китайский “Спайдермен”, или Как работает движок FineBI

Хабр, привет! Не так давно мы поделились переводом китайской статьи о поиске Банком Даляня инновационных приложений при работе с большими данными. Команде Business Intelligence GlowByte посчастливилось получить от FanRuan ещё одну статью, в которой раскрываются тайны работы движка FineBI Spider. Этот «Спайдермен» — тот ещё герой аналитики. Предлагаем вашему вниманию наш перевод оригинальной статьи и подробности функциональных особенностей китайского «паучка».
РАСКРЫТИЕ ТЕХНИЧЕСКИХ ПРИНЦИПОВ ДВИЖКА FineBI Spider
В процессе анализа данных в системе FineBI важную роль играет движок Spider. Его возможности по обработке данных и проведению вычислений обеспечивают поддержку гибкого и быстрого анализа данных в интерфейсе.

Три режима движка
Spider позволяет извлекать данные онлайн. При этом в зависимости от объёма данных движок может работать в трёх режимах: локальном, распределённом и режиме прямого подключения. Подробнее о каждом — ниже.
Локальный режим
Локальный режим движка Spider позволяет извлекать данные на локальный диск, хранить их в виде двоичных файлов, производить запросы и многопоточные параллельные вычисления, а также полностью использовать доступные ресурсы ЦП. Поэтому в случае небольшого объёма данных эффект отображения получается отличный, особенно при совместном использовании с веб-приложениями.
Распределённый режим
Spider способен гибко поддерживать анализ различных уровней данных. Резкое увеличение массивов данных может вести к масштабированию аппаратных узлов, и в этом случае движок переходит в распределённый режим.
Распределённая модель Spider Engine в сочетании с идеями обработки BigData HADOOP позволяет добиться высокой производительности анализа больших объёмов данных при максимально облегчённой архитектуре. Это решение объединяет ALLUXIO, SPARK, HDFS, ZOOKEEPER и другие компоненты больших данных в сочетании с самостоятельно разработанными высокопроизводительными алгоритмами, столбчатым хранилищем, параллельными вычислениями в памяти, вычислительной локализацией и высокопроизводительными алгоритмами для решения проблемы анализа больших объёмов данных и быстрого представления в FineBI.

Режим прямого подключения (Direct)
Движок Spider может напрямую подключаться к базе данных для анализа больших массивов данных в режиме реального времени. Данный режим может быть использован при достаточно высоких требованиях к получению данных «здесь и сейчас» или к производительности вычислений. При этом все действия пользователя с данными преобразуются в язык запросов в режиме реального времени.
Данные, полученные в указанных режимах, могут быть гибко преобразованы и отображаться на одном дашборде, облегчая тем самым пользователю возможность работы с ними.
Детальное описание технологии
Столбчатое хранение данных и сжатие
Хранение извлечённых данных осуществляется столбцами, накопление данных происходит в одном и том же столбце непрерывно, что значительно сокращает ввод-вывод и повышает эффективность запросов при их выполнении.

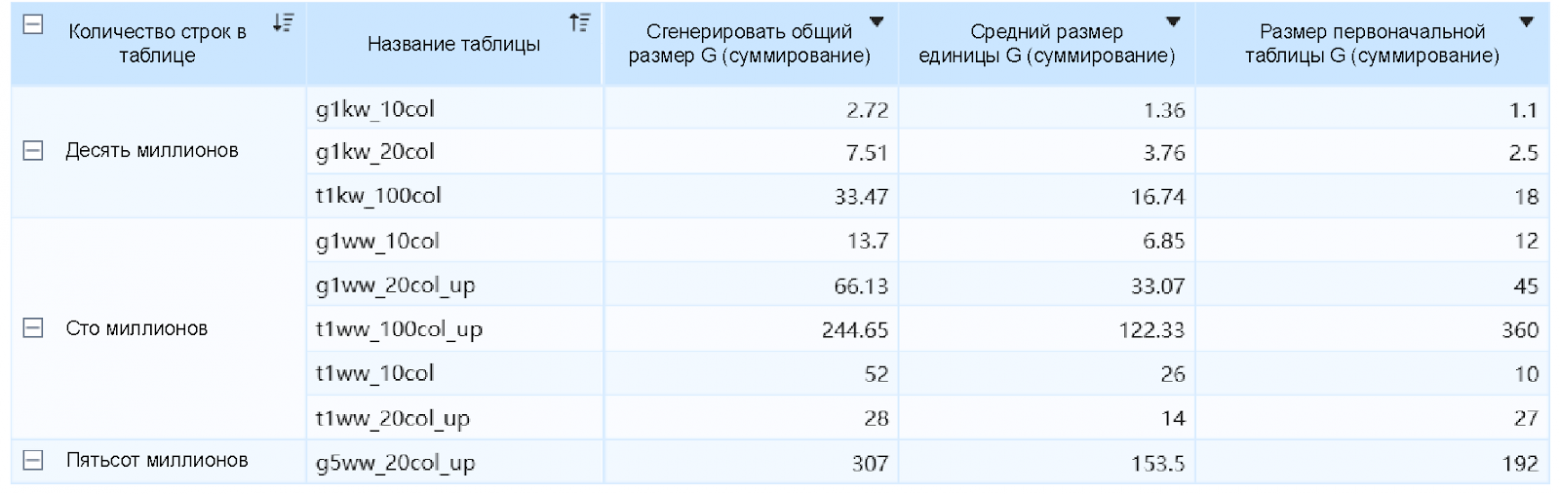
Столбчатое хранение данных основано на использовании данных одного типа с высокой долей одинаковых значений, которые извлекаются в виде словаря, и каждое значение колонки просто хранится непосредственно в индексе, сопоставленном с этим значением, после чего происходит сжатие. Таким образом, коэффициент сжатия данных значительно увеличивается. Ниже приведено сравнение размеров исходных данных и извлечённых данных. Наглядно показано, что в случае небольшого объёма нет никакой разницы в размере данных; при этом чем больше объём данных, тем лучше сжатие после извлечения, и можно достичь эффекта извлечённых данных: исходные данные = 1:1.5.
Интеллектуальное растровое индексирование
Растровое индексирование, или Bitmap-индексирование, является распространённой техникой ускорения фильтрации при работе с большими данными и может использоваться для одновременного вычисления больших объёмов данных.
Предположим, что имеется следующая таблица:

Теперь сделаем запрос:
select Фамилия, имя from table where пол = `М` and образование! = бакалавриат.
При отсутствии индекса мы можем только сканировать строку за строкой, чтобы определить, выполнены ли критерии фильтра, и добавить в набор результатов, если они выполнены.
Теперь мы создаём растровые индексы для значений пола и образования следующим образом:
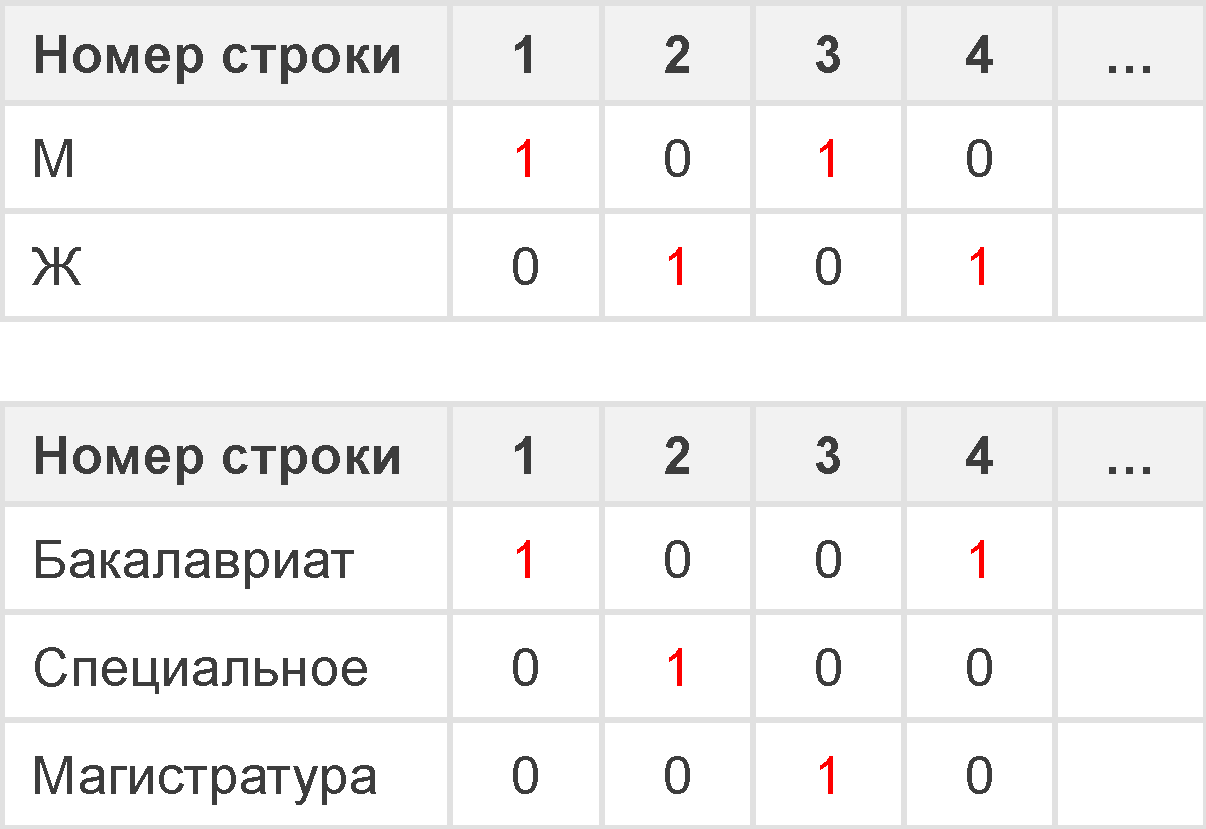
где 1 представляет соответствующее значение в этой строке, в противном случае оно равно 0.
Отсюда:
Для фильтра образование! = Бакалавриат можно быстро получить bitmap «Бакалавриат» 1001, а затем выполнить обратную операцию 0110.
Наконец, эти два bitmap«а объединяются по битам, чтобы получить окончательный bitmap 0010, в котором только третья строка равна 1, поэтому третья строка является результатом нашей фильтрации.
Движок постраничной подкачки
В дополнение к упомянутым выше интеллектуальным растровым индексам достаточно часто можно встретить супербольшие группировки (свыше миллиона строк результирующих наборов). В бизнес-анализе всегда найдётся пользователь, который захочет увидеть некоторый обобщённый контент, чтобы затем принять решение о проведении следующей операции анализа. Поэтому инструменты анализа данных для различных категорий бизнес-аналитиков должны быть в состоянии поддерживать этот вид сценария.
До появления движков постраничной подкачки обработка больших групп базы данных потоковым движком всегда была проблемой. Для запроса select A, B, C, sum (V) group by A, B, C (возврат более миллиона строк результатов):
С одной стороны, при вычислении группировки на основе HashMap эффективность доступа к HashMap будет снижаться, в то время как группировка будет постепенно увеличиваться.
С другой стороны, данные, возвращаемые после агрегации, довольно велики, что увеличивает расход на сериализацию и уменьшение, а слишком большой результирующий набор данных также может увеличить нагрузку на память.
После введения постраничной подкачки, основанной на древовидной структуре движка, связь между родительским и дочерним узлами может быть быстро рассчитана, а после успешного построения взаимосвязей каждый узел имеет свой соответствующий растровый индекс, который может быть вычислен отдельно для получения результатов. Вычисления больших групп перестаёт быть проблемой.
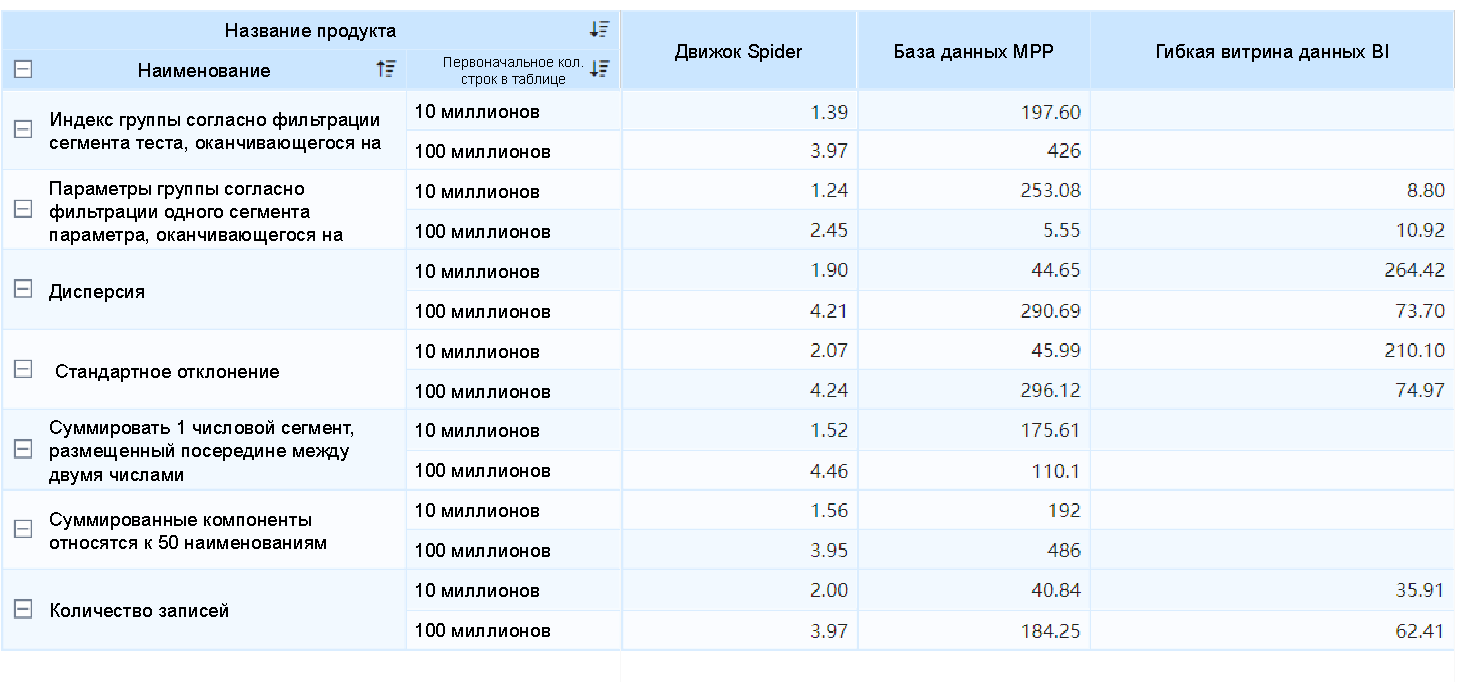
На приведённом ниже рисунке отображена производительность вычисления большой группы данных. Время вычисления движком Spider в основном составляет около 3 секунд.
Асинхронный импорт данных
В процессе извлечения и импорта данных, когда JDBC (Java Database Connectivity) начинает выполнять сжатие и извлечение данных, работа по сжатию не препятствует извлечению. При этом проводимое при сжатии сегментирование данных не требует большого объёма сжатия и расхода ресурсов. В то же время независимые потоки сжатия работают одновременно с извлечением, сокращая время извлечения данных за счёт параллельной обработки. В сочетании с оптимизацией хранения данных это позволяет при импорте массивных данных избежать проблем с производительностью, таких как OOM (Out of memory).
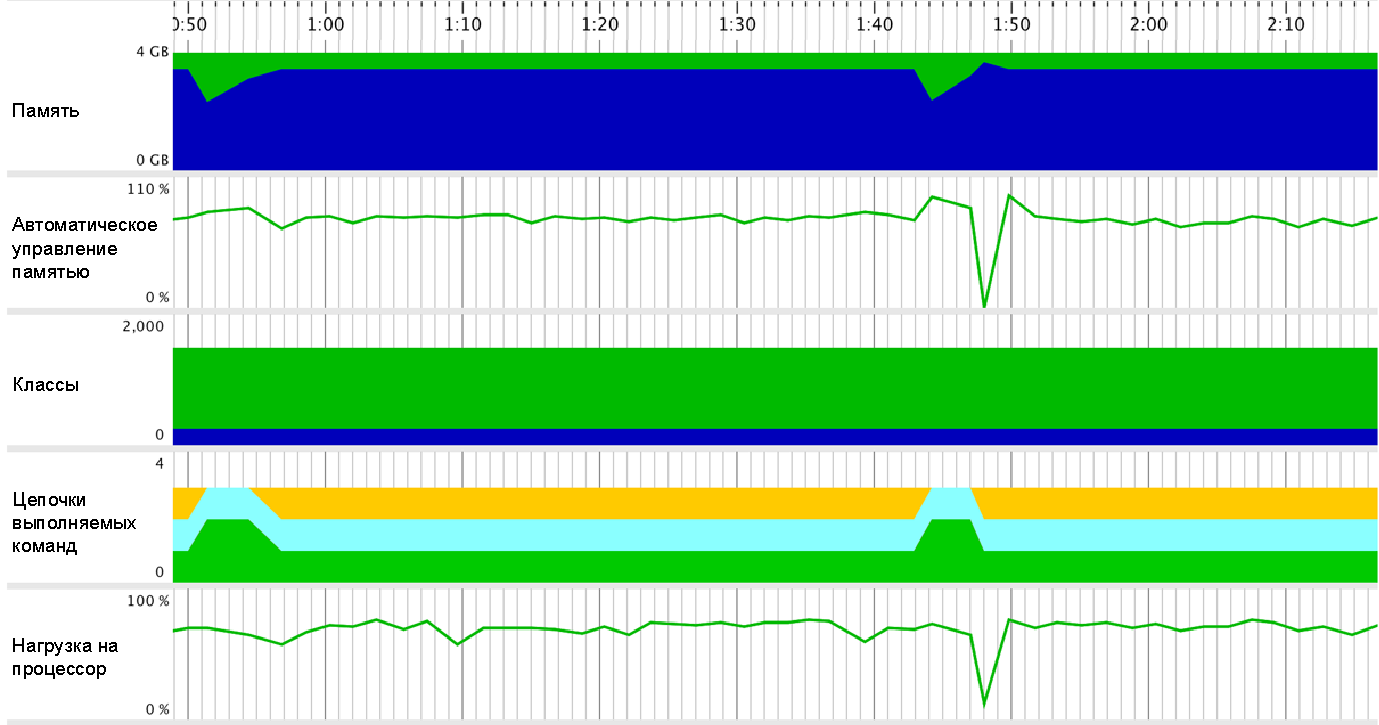
На представленном ниже рисунке показан процесс импорта таблицы данных из 100 столбцов и 1 миллиарда строк (не повторяющийся список строк в таблице составляет более 100 миллионов строк), при этом объём памяти не превышает 4 Гб, что дает замечательные результаты (скриншот использования ресурсов, записанный с помощью Jprofile).
Распределённая система хранения файлов
Хранение больших объёмов данных требует дешёвых способов хранения, которые позволяли бы хранить неструктурированные данные и выполнять распределённые вычисления. Первое, что вспоминается при этом, это распределённая файловая система HDFS из Hadoop, механизм стабильности и отказоустойчивости которой достаточно совершенен, а поддержка, реализованная после версии Hadoop 2.X, обеспечивает доступ к данным хранилища в течение всего времени. Его экосистема в области больших данных также относительно хорошая, поэтому его используют как систему хранения для долгосрочного дублирующего и резервного копирования.
Однако хранилище HDFS по-прежнему является дисковым, и его производительность ввода-вывода не может соответствовать задержкам, требуемым для потоковых вычислений, а частый обмен данными по сети ещё больше замедляет вычислительную обработку. Поэтому мы представили Alluxio в качестве основной системы хранения данных нашей распределённой системы, чьи возможности хранения, ориентированные на память, делают доступ к данным для приложений верхнего уровня на несколько порядков быстрее, чем существующие традиционные решения.
При Alluxio используется комбинация ресурсов памяти, SSD и дискового хранилища. С помощью политик кэширования, таких как LRU и LFU, предоставляемых Alluxio, можно обеспечить, чтобы «горячие» данные оставались в памяти, а «холодные» сохранялись на устройствах хранения второго или даже третьего уровня, при этом HDFS на самом низком уровне выступает в качестве системы долгосрочного хранения файлов.
Расчёт локализации данных
Распределённые вычисления — это совместные вычисления нескольких машин, при которых неизбежно возникает проблема передачи данных между узлами. Чтобы снизить потребление сетевой передачи и избежать ненужной перетасовки, для реализации вычислений локализации данных используется механизм планирования Spark. Это означает, что задача назначается на узел, имеющий данные для каждой задачи, что экономит расход на передачу данных и позволяет вычислять большие объёмы данных за секунды.
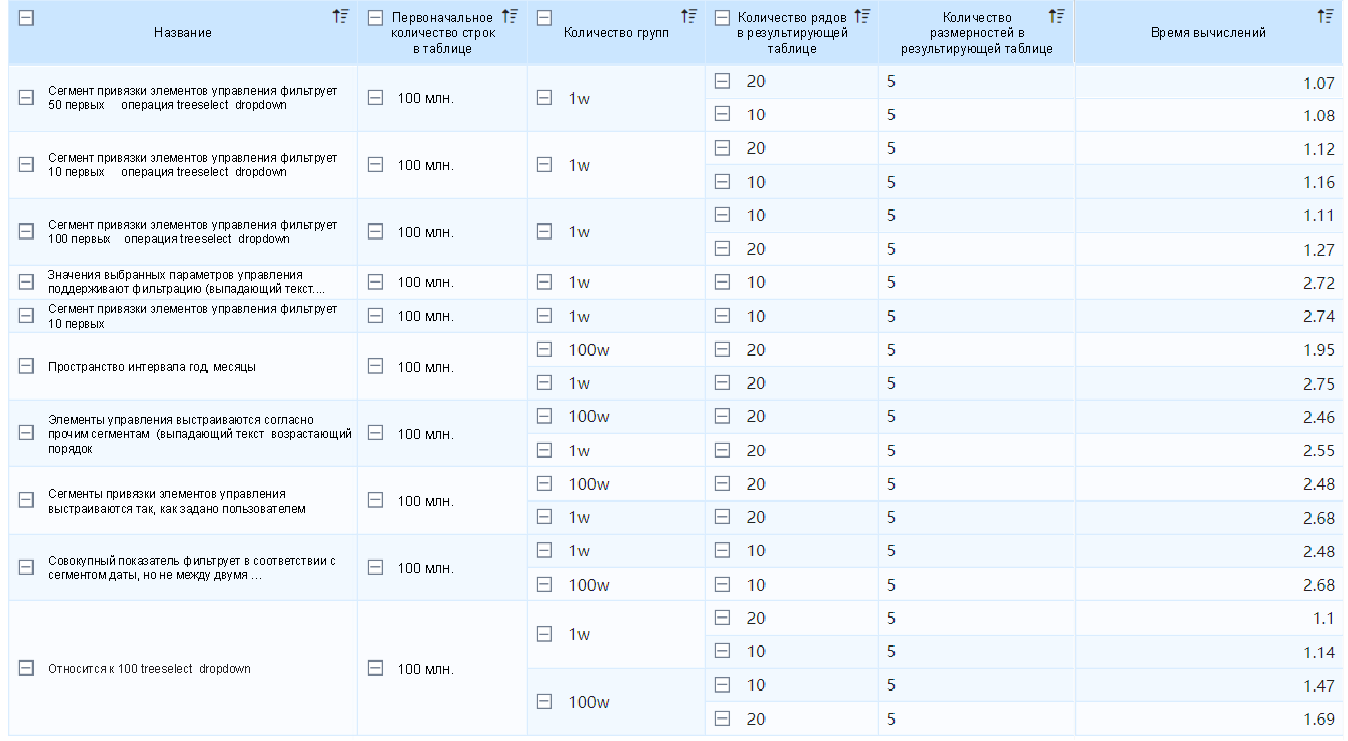
Интеллектуальное кэширование
Интеллектуальное кэширование больше предназначено для поддержки параллельных запросов в режиме прямого подключения (Direct Mode). Из-за прямого подключения к базе данных производительность естественно и неизбежно ограничена базой данных.
В то же время пользовательские запросы будут учитывать запросы аналогичных данных, поэтому для интеллектуального кэширования вводится encache-framework, что с учётом многоуровневого кэширования и интеллектуальных стратегий для операций после возврата данных также позволяет избежать дублирования кэширования, тем самым значительно повышая производительность запросов. Ниже приводится сравнение эффекта от первого и второго запроса.

