[Перевод] Как ввести в заблуждение компьютер: коварная наука обмана искусственного интеллекта

В начале XX века Вильгельм фон Остин, немецкий тренер лошадей и математик, объявил миру, что научил лошадь считать. Годами фон Остин путешествовал по Германии с демонстрацией этого феномена. Он просил свою лошадь по кличке Умный Ганс (породы орловский рысак), подсчитывать результаты простых уравнений. Ганс давал ответ, топая копытом. Два плюс два? Четыре удара.
Но учёные не верили в то, что Ганс был таким умным, как заявлял фон Остин. Психолог Карл Штумпф провёл тщательное расследование, которое окрестили «Гансовским комитетом». Он обнаружил, что Умный Ганс не решает уравнения, а реагирует на визуальные сигналы. Ганс выстукивал копытом, пока не добирался до правильного ответа, после чего его тренер и восторженная толпа разражались криками. А затем он просто останавливался. Когда он не видел этих реакций, он так и продолжал стучать.
Информатика может многому научиться у Ганса. Ускоряющийся темп разработки в этой области говорит о том, что большая часть созданного нами ИИ обучилась достаточно для того, чтобы выдавать правильные ответы, но при этом не понимает информацию по-настоящему. И его легко обмануть.
Алгоритмы машинного обучения быстро превратились во всевидящих пастухов людского стада. ПО соединяет нас с интернетом, отслеживает в нашей почте спам и вредоносный контент, а вскоре будет водить наши машины. Их обман сдвигает тектонический фундамент интернета, и угрожает нашей безопасности в будущем.
Небольшие исследовательские группы — из Пенсильванского государственного университета, из Google, из военного ведомства США — разрабатывают планы защиты от потенциальных атак на ИИ. Теории, выдвинутые в исследовании, говорят, что атакующий может изменить то, что «видит» робомобиль. Или активировать распознавание голоса на телефоне и заставить его зайти на вредоносный сайт при помощи звуков, которые будут для человека только шумом. Или позволить вирусу просочиться через сетевой файервол.

Слева — изображение здания, справа — изменённое изображение, которое глубинная нейросеть относит к страусам. В середине показаны все изменения, применённые к первичному изображению.
Вместо перехвата контроля над управлением робомобилем, этот метод демонстрирует ему что-то вроде галлюцинации — изображение, которого на самом деле нет.
Такие атаки используют изображения с подвохом [adversarial examples — устоявшегося русского термина нет, дословно получается нечто вроде «примеры с противопоставлением» или «соперничающие примеры» — прим. перев.]: изображения, звуки, текст, выглядящие нормальными для людей, но воспринимаемые совершенно по-другому машинами. Небольшие изменения, сделанные атакующими, могут заставить глубинную нейросеть сделать неправильные выводы о том, что её демонстрируют.
«Любая система, использующая машинное обучение для вынесения решений, критичных для безопасности, потенциально уязвима для такого рода атак», — говорит Алекс Канчельян, исследователь из Университета Беркли, изучающий атаки на машинное обучение при помощи обманных изображений.
Знание этих нюансов на ранних этапах разработки ИИ даёт исследователям инструмент к пониманию методов исправления этих недостатков. Некоторые уже занялись этим, и говорят, что их алгоритмы из-за этого стали ещё и эффективнее работать.
Большая часть основного потока исследований ИИ зиждется на глубинных нейросетях, в свою очередь основывающихся на более обширной области машинного обучения. Технологии МО используют дифференциальное и интегральное исчисление и статистику для создания используемого большинством из нас софта, вроде спам-фильтров в почте или поиска в интернете. За последние 20 лет исследователи начали применять эти техники к новой идее, нейросетям — программным структурам, имитирующим работу мозга. Идея в том, чтобы децентрализовать вычисления по тысячам небольших уравнений («нейронов»), принимающих данные, обрабатывающих и передающих их далее, на следующий слой из тысяч небольших уравнений.
Эти ИИ-алгоритмы обучаются так же, как и в случае с МО, которое, в свою очередь, копирует процесс обучения человека. Им демонстрируют примеры разных вещей и связанные с ними метки. Покажите компьютеру (или ребёнку) изображение кота, скажите, что кот выглядит вот так, и алгоритм научится распознавать котов. Но для этого компьютеру придётся просмотреть тысячи и миллионы изображений котов и кошек.
Исследователи обнаружили, что эти системы можно атаковать при помощи особым образом подобранных обманных данных, которые они назвали «adversarial examples».
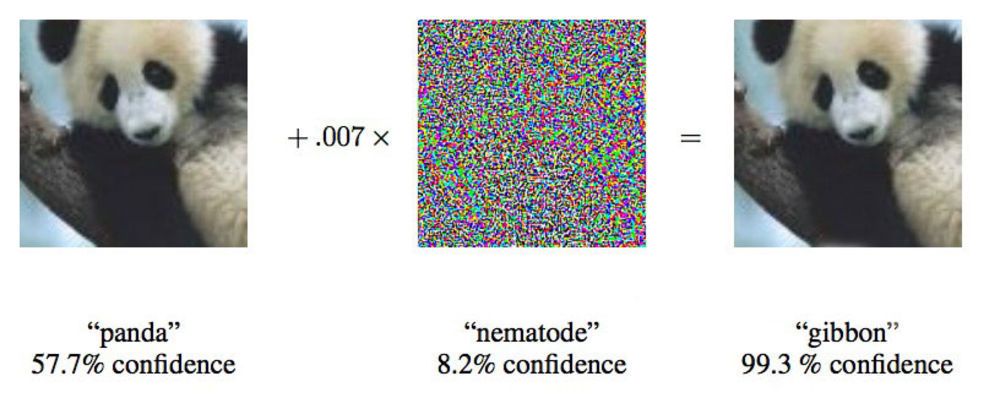
В работе от 2015 года исследователи из Google показали, что глубинные нейросети можно заставить отнести это изображение панды к гиббонам.
«Мы показываем вам фото, на котором явно видно школьный автобус, и заставляем думать, что это страус», — говорит Йэн Гудфелло [Ian Goodfellow], исследователь из Google, активно работающий в области подобных атак на нейросети.
Изменяя предоставляемые нейросетям изображения всего на 4%, исследователи смогли обмануть их, заставив ошибиться с классификацией, в 97% случаев. Даже если им не было известно, как именно нейросеть обрабатывает изображения, они могли обмануть её в 85% случаев. Последний вариант обмана без данных об архитектуре сети называется «атакой на чёрный ящик». Это первый документированный случай функциональной атаки подобного рода на глубинную нейросеть, и его важность заключается в том, что примерно по такому сценарию и могут проходить атаки в реальном мире.
В работе исследователи из Пенсильванского государственного университета, компании Google и Исследовательской лаборатории при ВМФ США провели атаку на нейросеть, классифицирующую изображения, поддерживаемую проектом MetaMind и служащую онлайн-инструментом для разработчиков. Команда построила и натренировала атакуемую сеть, но их алгоритм атаки работал независимо от архитектуры. С таким алгоритмом они смогли обмануть нейросеть-«чёрный ящик» с точностью до 84,24%.

Верхний ряд фото и знаков — правильное распознавание знаков.
Нижний ряд — сеть заставили распознавать знаки совершенно неправильно.
Скармливание машинам некорректных данных — идея не новая, но Даг Тайгар [Doug Tygar], профессор из Университета в Беркли, изучавший машинное обучение с противопоставлением в течение 10 лет, говорит, что эта технология атак превратилась из простого МО в сложные глубинные нейросети. Злонамеренные хакеры применяли эту технику на спам-фильтрах годами.
Исследование Тайгера берёт начало из работы 2006 года по атакам подобного рода на сети с МО, которую в 2011 году он расширил при помощи исследователей из Калифорнийского университета в Беркли и Microsoft Research. Команда Google, первой начавшая применять глубинные нейросети, опубликовала свою первую работу в 2014 году, через два года после обнаружения возможности таких атак. Они хотели убедиться в том, что это не какая-то аномалия, а реальная возможность. В 2015 они опубликовали ещё одну работу, в которой описали способ защиты сетей и повышения их эффективности, и Йэн Гудфелло с тех пор давал консультации и по другим научным работам в этой области, включая и атаку на чёрный ящик.
Исследователи называют более общую идею о ненадёжной информацией «византийскими данными», и благодаря ходу исследований они пришли к глубинному обучению. Термин происходит от известной «задачи византийских генералов», мысленном эксперименте из области информатики, в котором группа генералов должна координировать свои действия при помощи посыльных, не обладая при этом уверенностью в том, кто из них — предатель. Они не могут доверять информации, полученной от своих коллег.
«Эти алгоритмы разработаны так, чтобы справляться со случайным шумом, но не с византийскими данными», — говорит Тайгар. Чтобы понять, как такие атаки работают, Гудфелло предлагает представить себе нейросеть в виде диаграммы рассеивания.
Каждая точка диаграммы представляет один пиксель изображения, обрабатываемый нейросетью. Обычно сеть пытается провести линию через данные, наилучшим образом соответствующую совокупности всех точек. На практике это немного сложнее, поскольку у разных пикселей разная ценность для сети. В реальности это сложный многомерный график, обрабатываемый компьютером.
Но в нашей простой аналогии диаграммы рассеивания форма линии, проводимой через данные, определяет то, что, как думает сеть, она видит. Для успешной атаки на такие системы исследователям нужно поменять лишь небольшую часть этих точек, и заставить сеть вынести решение, которого на самом деле нет. В примере с автобусом, выглядящим, как страус, фото школьного автобуса испещрено пикселями, расположенными по схеме, связанной с уникальными характеристиками фотографий страусов, знакомыми сети. Это невидимый глазом контур, но когда алгоритм обрабатывает и упрощает данные, экстремальные точки данных для страуса кажутся ей подходящим вариантом классификации. В варианте с чёрным ящиком исследователи проверяли работу с разными входными данными, чтобы определить, как алгоритм видит определённые объекты.
Давая классификатору объектов подложные входные данные и изучая решения, принятые машиной, исследователи смогли восстановить работу алгоритма так, чтобы обмануть систему распознавания изображений. Потенциально такая система в робомобилях в подобном случае может вместо знака «стоп» увидеть знак «уступи дорогу». Когда они поняли, как работает сеть, они смогли заставить машину увидеть всё, что угодно.
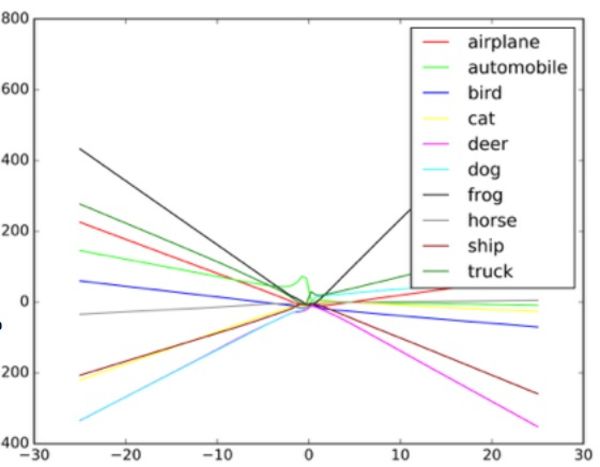
Пример того, как классификатор изображений проводит разные линии в зависимости от различных объектов на изображении. Примеы-обманки можно рассматривать как экстремальные величины на графике.
Исследователи говорят, что такую атаку можно ввести непосредственно в систему обработки изображений, минуя камеру, или эти манипуляции можно провести с реальным знаком.
Но специалист по безопасности из Колумбийского университета Элисон Бишоп говорит, что такой прогноз нереалистичен, и зависит от системы, используемой в робомобиле. Если у атакующих уже есть доступ к потоку данных с камеры, они и так могут выдать её любые входные данные.
«Если они могут добраться до входа камеры, такие сложности не нужны, — говорит она. — Вы можете просто показать ей знак 'стоп'».
Другие методы атаки, кроме обхода камеры — например, нанесение визуальных меток на реальный знак, кажутся Бишоп слабо вероятными. Она сомневается, что камеры с низким разрешением, используемые на робомобилях, вообще смогут различить небольшие изменения на знаке.

Нетронутое изображение слева классифицируется, как школьный автобус. Исправленное справа — как страус. В середине — изменения картинки.
Две группы, одна — в Университете в Беркли, другая — в Университете Джорджтауна, успешно разработали алгоритмы, способные выдавать речевые команды цифровым ассистентам вроде Siri and Google Now, звучащие как неразборчивый шум. Для человека такие команды покажутся случайным шумом, но при этом они могут давать команды устройствам вроде Alexa, непредусмотренные их владельцем.
Николас Карлини, один из исследователей византийских аудио-атак, говорит, что они в своих тестах смогли активировать распознающие аудио программы с открытым кодом, Siri и Google Now, с точностью более 90%.
Шум похож на какие-нибудь переговоры инопланетян из научной фантастики. Это смесь из белого шума и человеческого голоса, но она совсем не похожа на голосовую команду.
По словам Карлини, при такой атаке любой услышавший шум телефон (при этом необходимо раздельно планировать атаки на iOS и Android) можно заставить зайти на веб-страницу, также проигрывающую шум, что заразит и находящиеся рядом телефоны. Или же эта страница может по-тихому скачать вредоносную программу. Также есть возможность, что такие шумы проиграют по радио, и они будут запрятаны в белом шуме или параллельно с другой аудиоинформацией.
Такие атаки могут происходить, поскольку машину тренируют на то, что практически в любых данных содержатся важные данные, а также, что один вещи встречаются чаще других, как объясняет Гудфелло.
Обмануть сеть, заставив её поверить в то, что она видит распространённый объект, легче, поскольку она считает, что должна видеть такие объекты чаще всего. Поэтому Гудфелло и ещё одна группа из Университета Вайоминга смогли заставить сеть классифицировать изображения, которых вообще не было — она идентифицировала объекты в белом шуме, случайно созданных чёрных и белых пикселах.
В исследовании Гудфелло случайный белый шум, пропускаемый через сеть, классифицировался ею как лошадь. Это, по совпадению, возвращает нас к истории Умного Ганса, не очень сильно математически одарённой лошади.
Гудфелло говорит, что нейросети, как и Умный Ганс, на самом деле не выучивают какие-то идеи, а лишь учатся узнавать, когда находят нужную идею. Разница небольшая, но важная. Отсутствие фундаментальных знаний облегчает злонамеренные попытки воссоздавать видимость нахождения «правильных» результатов алгоритма, которые на поверку оказываются ложными. Чтобы понимать, чем нечто является, машине нужно также понять, чем оно не является.
Гудфелло, натренировав сортирующие изображения сеть как на естественных изображениях, так и на обработанных (поддельных), обнаружил, что смог не только уменьшить эффективность таких атак на 90%, но и заставить сеть лучше справляться с первоначальной задачей.
«Заставляя объяснять реально необычные поддельные изображения, можно добиться ещё более надёжного объяснения лежащих в основе концепций», — говорит Гудфелло.
Две группы исследователей аудио использовали подход, похожий на подход команды Google, защищая свои нейросети от своих же атак путём перетренировки. Они тоже добились сходных успехов, более чем на 90% уменьшив эффективность атаки.
Неудивительно, что эта область исследований заинтересовала военное ведомство США. Армейская исследовательская лаборатория даже спонсировала две самых новых работы на эту тему, включая атаку на чёрный ящик. И хотя ведомство финансирует исследования, это не означает, что технологию собираются использовать в войне. Согласно представителю ведомства, от исследований до пригодных для использования солдатом технологий может пройти до 10 лет.
Анантрам Свами [Ananthram Swami], исследователь из армейской лаборатории США принимал участие в создании нескольких недавних работ, посвящённых обману ИИ. Армия интересуется вопросом обнаружения и остановки обманных данных в нашем мире, где не все источники информации можно тщательно проверить. Свами указывает на набор данных, полученных с публичных датчиков, расположенных в университетах и работающих в проектах с открытым кодом.
«Мы не всегда контролируем все данные. Нашему противнику довольно легко обмануть нас, — говорит Свами. — В некоторых случаях последствия такого обмана могут быть несерьёзными, в некоторых — наоборот».
Также он говорит, что армия интересуется автономными роботами, танками и другими средствами передвижения, поэтому цель таких исследований очевидна. Изучая эти вопросы, армия сможет выиграть себе фору в разработке систем, неподверженных атакам подобного рода.
Но у любой использующей нейросети группы должны возникать опасения по поводу потенциальной возможности атак с обманом ИИ. Машинное обучение и ИИ находятся в зачаточном состоянии, и в это время промашки с безопасностью могут иметь ужасные последствия. Многие компании доверяют весьма чувствительную информацию системам ИИ, не прошедшим проверку временем. Наши нейросети ещё слишком молоды, чтобы мы могли знать про них всё, что нужно.
Похожий недосмотр привёл к тому, что бот для твиттера от Microsoft, Tay, быстро превратился в расиста со склонностью к геноциду. Поток вредоносных данных и функция «повторяй за мной» привели к тому, что Tay сильно отклонился от намеченного пути. Бот был обманут некачественными входными данными, и это служит удобным примером плохой реализации машинного обучения.
Канчельян говорит, что не считает, будто возможности подобных атак исчерпаны после успешных исследований команды из Google.
«В области компьютерной безопасности атакующие нас всегда опережают, — говорит Канчельян. — Довольно опасно будет заявлять, будто мы решили все проблемы с обманом нейросетей при помощи их повторной тренировки».
