[Перевод] Как устроено распределение памяти

Один из общих для всех программ на вашем компьютере аспектов — это потребность в памяти. Прежде чем запуститься, программы должны быть загружены с жёсткого диска в память. При работе программ подавляющее большинство их действий заключается в загрузке значений из памяти, выполнении вычислений с ними, а затем сохранении результата обратно в память.
В этом посте я познакомлю вас с основами распределения памяти (memory allocation). Распределители памяти существуют, потому что иметь доступную память недостаточно, необходимо ещё и эффективно её использовать. Мы наглядно изучим, как работают простые распределители. Мы рассмотрим некоторые из задач, которые им необходимо решать, а также некоторые из методик, которыми они их решают. Прочитав этот пост, вы узнаете всё, что необходимо для написания собственного распределителя.
malloc и free
Чтобы понять работу распределителя памяти, необходимо разобраться, как программы запрашивают и возвращают память. malloc и free — это функции, впервые появившиеся в своём узнаваемом виде в в UNIX v7 в 1979 (!) году. Давайте рассмотрим короткую программу на C, демонстрирующую их использование.
Постойте-ка. Я никогда не писал код на C. Я вообще пойму, что написано в статье?
Если у вас есть начальные знания по любому другому языку программирования, например, JavaScript, Python или C#, то с пониманием проблем возникнуть не должно. Необязательно понимать каждое слово, если вы понимаете смысл в целом. Обещаю, что это единственный код на C в этой статье.
#include
int main() {
void *ptr = malloc(4);
free(ptr);
return 0;
}
В приведённой выше программе мы, вызвав malloc(4), запрашиваем 4 байта памяти, сохраняем возвращённое значение в переменной ptr, а затем показываем, что завершили работу с памятью, вызвав free(ptr).
При помощи этих двух функций сегодня управляют используемой памятью почти все программы. Даже если вы не пишете на C, то код, исполняющий вашу программу на Java, Python, Ruby, JavaScript и так далее, использует malloc и free.
Что такое память?
Наименьшая единица памяти, с которой работают распределители, называется «байт». Байт может хранить любое число от 0 до 255. Можно представить память в виде длинной последовательности байтов. Мы визуализируем эту последовательность в виде сетки квадратов, где каждый квадрат представляет собой байт памяти.

В показанном выше коде на C malloc(4) распределяет 4 байта памяти. Мы обозначим распределённую память как квадраты более тёмного цвета.

Затем free(ptr) сообщает распределителю, что мы закончили работу с этой памятью. Она снова возвращается в пул доступной памяти.
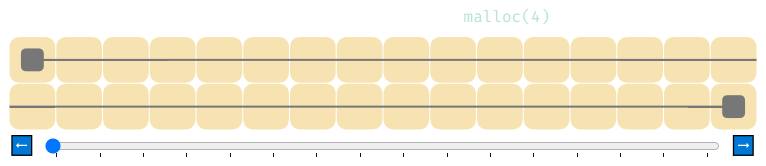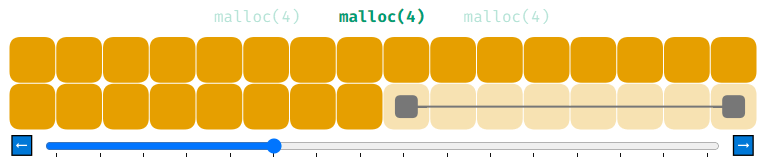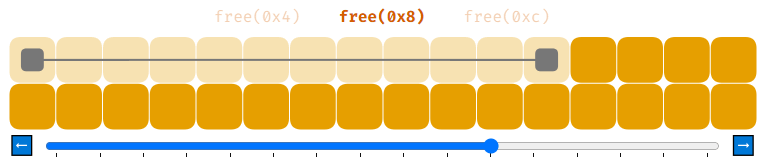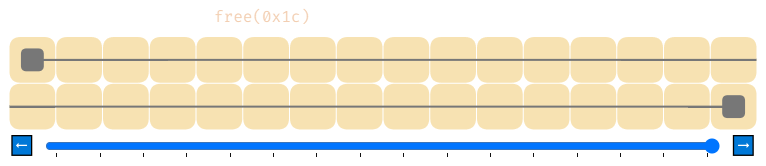
Вот как выглядят 4 вызова malloc, за которыми следуют 4 вызова free.

Постойте-ка… Что
mallocвозвращает в качестве значения? Что означает «дать» память программе?
То, что возвращает malloc, называется «указатель» или «адрес памяти». Это число, идентифицирующее байт в памяти. Обычно мы записываем адреса в виде, называемом «шестнадцатеричным». Шестнадцатеричные числа записываются с префиксом 0x, чтобы отличать их от десятичных чисел. Ниже показано различие между шестнадцатеричными и десятеричными числами.
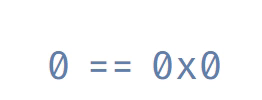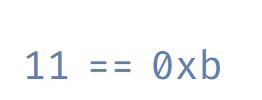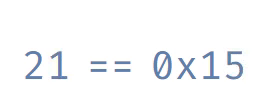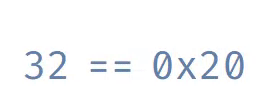
Вот знакомая нам сетка памяти. Каждый байт подписан своим адресом в шестнадцатеричном виде. Чтобы сэкономить место, мы опустили префикс 0x.

В примерах из этой статьи мы условно считаем, что в компьютере очень малый объём памяти, однако в реальной жизни нам приходится работать с миллиардами байтов. Реальные адреса гораздо больше, чем используемые здесь, но принцип остаётся точно таким же. Адреса памяти — это числа, соответствующие конкретному байту в памяти.
Простейшая malloc
«Hello world» реализаций malloc выдаёт блоки памяти, отслеживая, где завершился предыдущий блок, и начиная следующий блок за ним. Ниже серым квадратом показано, где должен начинаться следующий блок.

Можно заметить, что память не освобождается при помощи free. Мы отслеживаем, только где должен начинаться следующий блок, и у нас нет информации, где начинаются или заканчиваются предыдущие блоки; у free недостаточно информации, чтобы что-то сделать. Поэтому она ничего и не делает. Это называется «утечкой памяти» (memory leak), потому что после распределения память больше никогда не удастся использовать снова.
Можете не верить, но это не абсолютно бесполезная реализация. Для программ, использующих известный объём памяти, это может быть очень эффективной стратегией. Она чрезвычайно быстра и проста. Однако в распределителе памяти общего назначения мы не можем обойтись без реализации free.
Простейшая malloc общего назначения
Чтобы иметь возможность освобождать память при помощи free, мы должны лучше отслеживать состояние памяти. Это можно сделать, сохраняя адрес и размер всех распределений и адрес и размер блоков свободной памяти. Мы назовём это «списком распределений» (allocation list) и «списком свободной памяти» (free list).

Мы представим элементы списка свободной памяти в виде двух серых квадратов, соединённых друг с другом линией. Можно представить, что этот элемент задан в коде как address=0 и size=32. При запуске нашей программы вся память помечена как свободная. При вызове malloc мы обходим в цикле весь список свободной памяти, пока не найдём блок достаточно большого размера. После его обнаружения мы сохраняем адрес и размер распределения в список распределений и соответствующим образом уменьшаем элемент списка свободной памяти.

Да, вы меня подловили. Одно из преимуществ распределителя памяти заключается в том, что он отвечает за память. Можно хранить список распределений/свободной памяти в зарезервированной области. Или же можно хранить их линейно, в нескольких байтах, предшествующих каждому распределению. Пока предположим, что зарезервировали некоторый объём невидимой нам памяти для себя и используем её для хранения списков распределений и свободной памяти.
Так что насчёт free? Так как мы сохранили адрес и размер распределения в список распределений, можно выполнить поиск по этому списку и переместить распределение обратно в список свободной памяти. Без информации о размере этого невозможно будет сделать.

Теперь список свободной памяти содержит два элемента. Это может показаться безвредным, однако на самом деле представляет собой серьёзную проблему. Давайте понаблюдаем за ней в действии.

Мы распределили 8 блоков памяти по 4 байта каждый. Затем мы освободили их все при помощи free, получив 8 элементов списка свободной памяти. Проблема заключается в том, что если мы попытаемся теперь выполнить malloc(8), то в списке свободной памяти нет элементов, способных хранить 8 байт и malloc(8) завершится с ошибкой.
Чтобы решить эту проблему, нужно проделать чуть больше работы. Когда мы освобождаем память при помощи free, нужно сделать так, чтобы, если возвращаемый в список свободной памяти блок находится рядом с любыми другими свободными блоками, мы бы соединили их. Это называется «объединением» (coalescing).
Так гораздо лучше.
Фрагментация
Идеально объединённый список свободной памяти не решит всех наших проблем. В примере ниже показана более длинная последовательность распределений. Взгляните на состояние памяти в конце.
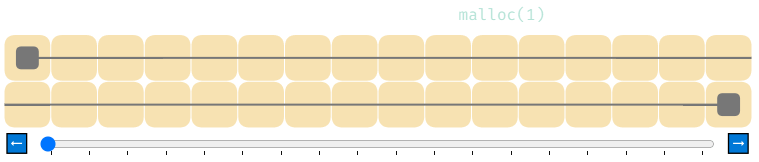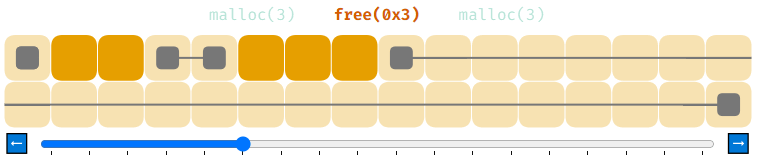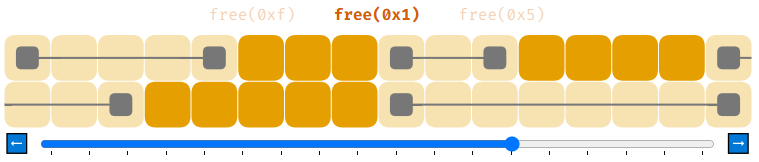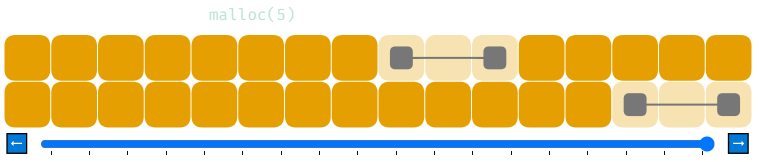
Мы завершаем эту последовательность, когда 6 из наших 32 байтов свободны, но они разделены на два блока по 3 байта. Если бы нам пришлось обработать malloc(6), то несмотря на теоретическое наличие достаточного количества свободной памяти, мы не смогли бы этого сделать. Это называется «фрагментацией».
К сожалению, нет. Помните, выше мы говорили, что возвращаемое malloc значение — это адрес байта в памяти? Перемещение распределений не изменит указатели, которые мы уже вернули из malloc. Мы изменим значение, на которое указывают эти указатели, по сути, повредив их. Это один из недостатков API malloc/free.
Если мы не можем перемещать распределения после их создания, то нужно изначально аккуратнее обращаться с тем, куда их помещать.
Один из способов борьбы с фрагментацией — это, как ни странно, избыточное распределение. Посмотрите, что произойдёт, если мы будем всегда распределять не менее 4 байтов, даже если запрос был на 1 байт. Вот точно такая же последовательность распределений, что и выше.
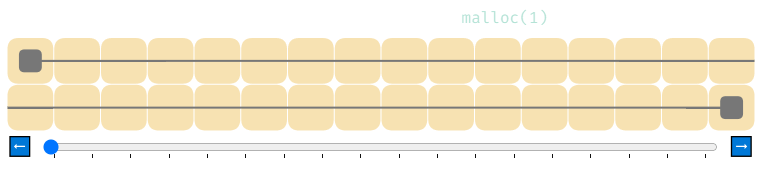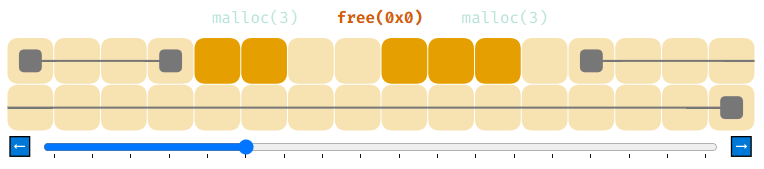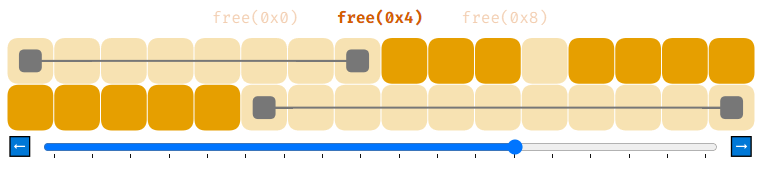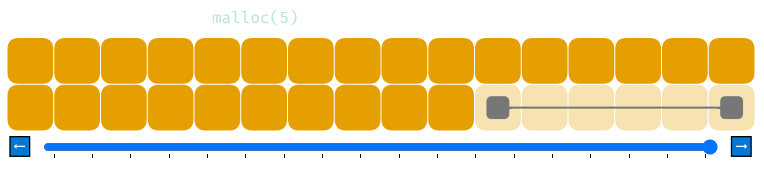
Теперь мы можем обработать malloc(6). Стоит помнить, что это лишь один пример. Программы вызывают malloc и free во всевозможных паттернах в зависимости от своих задач, поэтому сложно спроектировать распределитель, всегда работающий оптимально.
mallocначало списка свободной памяти рассинхронизируется с распределённой памятью. Это баг визуализации?
Нет, это побочный эффект избыточного распределения. Визуализация показывает «истинное» использование памяти, при котором список свободной памяти обновляется с точки зрения распределителя. Поэтому когда происходит первая malloc, распределяется 1 байт памяти, однако элемент списка свободной памяти смещается вперёд на 4 байта. В обмен на впустую растрачиваемое пространство мы получаем снижение фрагментации.
Стоит заметить, что это неиспользуемое пространство, получаемое в результате избыточного распределения — ещё одна разновидность фрагментации. Это память, которую нельзя использовать, пока созданное распределение не будет освобождено. Поэтому избыточное распределение не должно быть слишком большим. Например, если наша программа всегда бы распределяла по 1 байту за раз, то мы впустую потратили бы 75% всей памяти.
Другой способ борьбы с фрагментацией — сегментация памяти на пространство для маленьких распределений и пространство для больших. В следующей визуализации мы начинаем с двумя списками свободной памяти. Светло-серый предназначен для распределений по 3 байта и меньше, а тёмно-серый — для распределений по 4 байта и больше. Здесь используется та же последовательность распределений, что и выше.
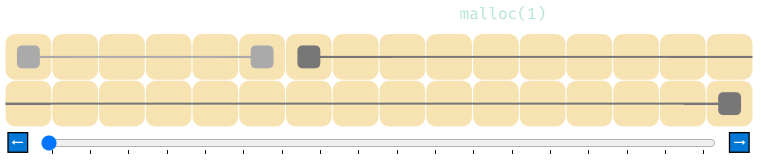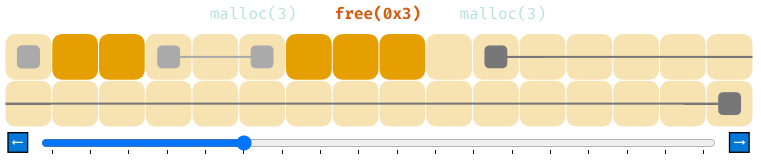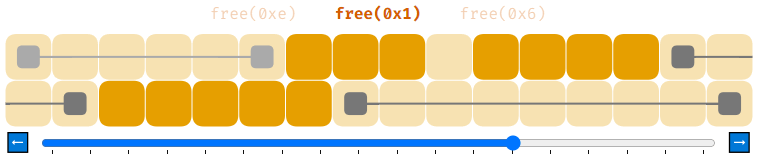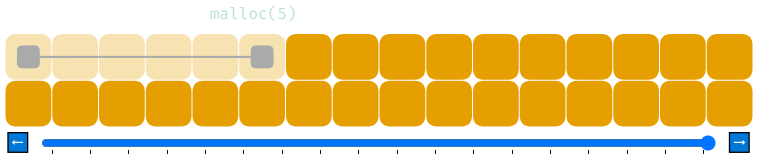
Отлично! Это тоже снижает фрагментацию. Однако если мы позволяем размещать в первом сегменте строго распределения по 3 байта и менее, то не сможем обработать malloc(6). Недостаток здесь заключается в том, что резервирование сегмента памяти под маленькие распределения оставляет меньше памяти для работы с более крупными.
Постойте-ка, первое распределение в тёмно-сером списке свободной памяти составляет 3 байта! А вы сказали, что он предназначен для распределений по 4 байта и выше. Как это понимать?

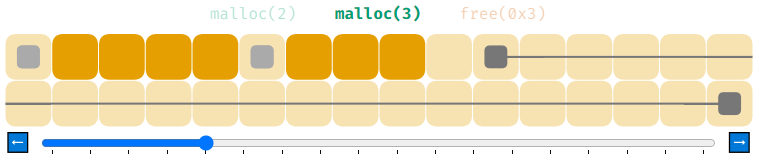
И вы снова меня подловили. Написанная мной реализация помещает мелкие распределения в тёмно-серое пространство, если светло-серое заполнено. При этом она выполняет избыточное распределение, в противном случае в тёмно-сером пространстве из-за мелких распределений образовалась бы фрагментация, которую можно избежать.
Распределители, разделяющие память на основании размера распределения, называются slab allocator. На практике у них есть гораздо больше классов размеров, чем два из нашего примера.
Небольшая загадка про malloc
Что произойдёт, если выполнить malloc(0)? Подумайте об этом, изучая показанную ниже анимацию.
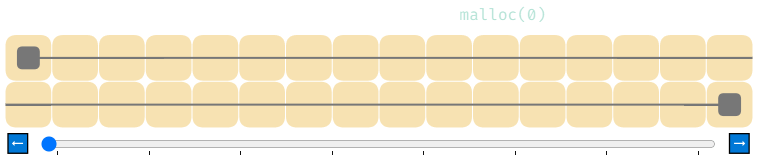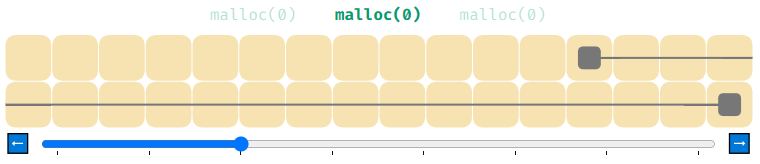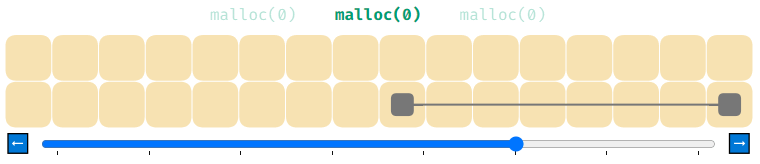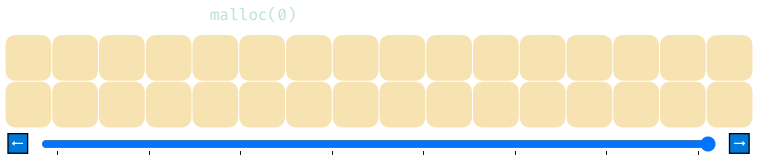
В ней используется реализация списка свободной памяти, требующая для распределений не менее 4 байтов. Вся память распределяется, но на самом деле она никак не используется. Думаете ли вы, что это корректное поведение?
Оказывается, поведение при malloc(0) зависит от конкретной реализации. Некоторые из них ведут себя так, как показано выше, распределяя пространство, хотя, вероятно, этого не стоит делать. Другие возвращают так называемый «нулевой указатель» (null pointer) — специальный указатель, который приводит к вылету программы, если попытаться считать или записать в память, на которую он указывает. Третьи выбирают один конкретный адрес в памяти и возвращают один и тот же адрес для всех вызовов malloc(0), сколько бы раз её ни вызывали.
В чём же мораль этой истории? Не используйте malloc(0).
Линейное хранение
Помните, когда вы задали вопрос о том, где хранится информация списка распределения и списка свободной памяти, я ответил, что она хранится в какой-то другой области памяти, которую мы зарезервировали для себя?
Это не единственный способ решения. Многие распределители хранят информацию прямо рядом с блоками памяти, с которыми они связаны. Взгляните на пример.

Здесь у нас есть память без распределений, однако информация списка свободной памяти хранится линейно в этой памяти. Каждый блок памяти, свободный или занятый, получает 3 дополнительных байта информации об использовании. Если address — адрес первого байта распределения, то структура блока выглядит так:
address + 0— это размер блокаaddress + 1— обозначает, свободен (1) ли блок, или занят (2)address + 2— место, где начинается пригодная к использованию памятьaddress + 2 + размер— снова размер блока
Итак, в приведённом выше примере байт по адресу 0x0 хранит значение 29. Это значит, что блок содержит 29 байт памяти. Значение 1 по адресу 0x1 означает, что этот блок является свободной памятью.
Поначалу это кажется лишним, но это необходимо, если мы хотим организовать coalescing. Давайте взглянем на пример.

Здесь мы распределили 4 байта памяти. Чтобы сделать это, наша реализация malloc начинает с начала памяти и проверяет, используется ли находящийся там блок. Она знает, что по адресу address + 1 она найдёт или 1, или 2. Если она находит 1, то может проверить значение по адресу address, чтобы понять, насколько велик блок. Если он достаточно большой, то можно выполнить распределение в него. Если он недостаточно большой, то реализация знает, что может прибавить найденное в address значение к address, чтобы получить начало следующего блока памяти.
Это привело к созданию занятого блока (обратите внимание, что во втором байте хранится 1) и сместило начало свободного блока вперёд на 7 байт. Давайте повторим это и распределим ещё 4 байта.

Далее давайте освободим при помощи free нашу первую malloc(4). И благодаря реализации free начинают проявляться все достоинства линейного хранения информации. В предыдущих распределителях нам приходилось выполнять поиск по списку распределений, чтобы узнавать размер блока, освобождаемого с помощью free. Теперь мы знаем, что найдём его в address. Ещё лучше, что для этого free нам даже не нужно знать, насколько велико распределение. Мы можем просто присвоить address + 1 значение 1!

Разве это не здорово? Просто и быстро.
А что, если мы захотим освободить второй блок занятой памяти? Мы знаем, что нам нужно стремиться к объединению, чтобы избегать фрагментации, но как это сделать? Именно здесь нам на помощь приходит кажущееся пустой тратой места хранение информации.
В случае объединения мы проверяем состояние блоков непосредственно до и после блока, который мы освобождаем при помощи free. Мы знаем, что можем перейти к следующему блоку, прибавив значение по адресу address к address, но как получить предыдущий блок? Мы берём значение из адреса address - 1 и вычитаем его из address. Без этой дублируемой информации о размере в конце блока было бы невозможно найти предыдущий блок и правильно выполнить coalescing.
Распределители, хранящие подобную информацию об использовании наряду с распределениями, называются boundary tag allocator.
Как ни удивительно, ничто особенно этому не мешает. Вся наша отрасль полагается на корректность кода. Возможно, вы уже слышали о багах «buffer overrun» или «use after free». В таких ситуациях программа изменяет память за пределами конца распределённого блока или случайно использует блок памяти после того, как освободит его при помощи free. Это и в самом деле приводит к катастрофе. В результате этого программа может вылететь немедленно, через несколько минут, часов или даже дней. Хакеры могут использовать этот баг для получения доступа к системам, которые должны быть им недоступны.
Мы наблюдаем рост популярности «безопасных по памяти» языков, например, Rust. Эти языки прилагают большие усилия для того, чтобы совершать подобные ошибки было невозможно в принципе. Конкретный способ реализации этого выходит за рамки нашей статьи, но если вам любопытно, то крайне рекомендую попробовать поработать с Rust.
Возможно, вы также догадались, что вызов free для указателя, находящегося посередине блока памяти, тоже может иметь катастрофические последствия. При определённых значениях в памяти распределитель может ошибочно решить, что он освобождает что-то при помощи free, но на самом деле изменяет память, чего делать не должен.
Чтобы обойти эту проблему, некоторые распределители добавляют в информацию о хранении «магические» значения. Например, они хранят 0x55 по адресу address + 2. При этом на каждое распределение будет тратиться дополнительный байт памяти, но это позволит узнать, была ли совершена ошибка. Чтобы снизить влияние этого, распределители часто по умолчанию отключают это поведение и позволяют включать его только в режиме отладки.
Песочница
Если вы хотите воспользоваться только что приобретёнными знаниями и попытаться написать собственные распределители, то нажмите сюда, чтобы перейти в мою песочницу распределителей. Там вы сможете писать код на JavaScript, реализующий API malloc/free, и визуализировать его работу!
Заключение
В этом посте мы рассмотрели многое, и если вы стремитесь узнать больше, то не будете разочарованы. В частности, я не стал рассматривать темы виртуальной памяти, сравнения brk и mmap, роли кэшей CPU и бесчисленного множества трюков, на которые способны настоящие реализации malloc. О распределителях памяти есть множество информации в Интернете, и если вы дочитали статью, то готовы к дальнейшему изучению.
▍ Благодарности
Выражаю особую благодарность следующим людям:
- Крису Дауну за то, что поделился со мной обширными знаниями о реальных распределителях памяти.
- Антону Веринову за то, что поделился со мной обширными знаниями о вебе, браузерных инструментах разработчика и UX.
- Блейку Бекеру, Мэтту Каспару, Кристе Хорн, Джейсону Педдлу и Джошу Комо за их видение и конструктивные отзывы.

