[Перевод] Как создать игровой ИИ: гайд для начинающих

Наткнулся на интересный материал об искусственном интеллекте в играх. С объяснением базовых вещей про ИИ на простых примерах, а еще внутри много полезных инструментов и методов для его удобной разработки и проектирования. Как, где и когда их использовать — тоже есть.
Большинство примеров написаны в псевдокоде, поэтому глубокие знания программирования не потребуются. Под катом 35 листов текста с картинками и гифками, так что приготовьтесь.
Что такое ИИ?
Игровой ИИ сосредоточен на том, какие действия должен выполнять объект, исходя из условий, в которых находится. Обычно это называют управлением «умными агентами», где агент является игровым персонажем, транспортным средством, ботом, а иногда и чем-то более абстрактным: целой группой сущностей или даже цивилизацией. В каждом случае это вещь, которая должна видеть свое окружение, принимать на его основе решения и действовать в соответствии с ними. Это называется циклом Sense/Think/Act (Чувствовать/Мыслить/Действовать):
- Sense: агент находит или получает информацию о вещах в своей среде, которые могут повлиять на его поведение (угрозы поблизости, предметы для сбора, интересные места для исследования).
- Think: агент решает, как реагировать (рассматривает, достаточно ли безопасно собирать предметы или сначала он должен сражаться/скрываться).
- Act: агент выполняет действия для реализации предыдущего решения (начинает движение к противнику или предмету).
- …теперь ситуация изменилась из-за действий персонажей, поэтому цикл повторяется с новыми данными.
ИИ, как правило, концентрируется на Sense-части цикла. Например, автономные автомобили делают снимки дороги, объединяют их с данными радара и лидара, и интерпретируют. Обычно это делает машинное обучение, которое обрабатывает входящие данные и придает им смысл, извлекая семантическую информацию по типу «есть еще один автомобиль в 20 ярдах впереди вас». Это так называемые classification problems.
Играм не нужна сложная система для извлечения информации, так как большая часть данных уже является ее неотъемлемой частью. Нет необходимости запускать алгоритмы распознавания изображений, чтобы определить, есть ли враг впереди — игра уже знает и передает сведения прямо в процессе принятия решений. Поэтому часть цикла Sense часто намного проще, чем Think и Act.
Ограничения игрового ИИ
У ИИ есть ряд ограничений, которые необходимо соблюдать:
- ИИ не нужно заранее тренировать, будто это алгоритм машинного обучения. Бессмысленно писать нейросеть во время разработки, чтобы наблюдать за десятками тысяч игроков и изучать лучший способ игры против них. Почему? Потому что игра не выпущена, а игроков нет.
- Игра должна развлекать и бросать вызов, поэтому агенты не должны находить лучший подход против людей.
- Агентам нужно выглядеть реалистичными, чтобы игроки чувствовали будто играют против настоящих людей. Программа AlphaGo превзошла человека, но выбранные шаги были сильно далеки от традиционного понимания игры. Если игра имитирует противника-человека, такого чувства не должно быть. Алгоритм нужно изменить, чтобы он принимал правдоподобные решения, а не идеальные.
- ИИ должен работать в реальном времени. Это значит, что алгоритм не может монополизировать использование процессора в течение длительного времени для принятия решений. Даже 10 миллисекунд на это — слишком долго, потому что большинству игр достаточно от 16 до 33 миллисекунд, чтобы выполнить всю обработку и перейти к следующему кадру графики.
- Идеально, если хотя бы часть системы управляется данными, чтобы «некодеры» могли вносить изменения, и чтобы корректировки происходили быстрее.
Рассмотрим подходы ИИ, которые охватывают весь цикл Sense/Think/Act.
Принятие базовых решений
Начнем с простейшей игры — Pong. Цель: переместить платформу (paddle) так, чтобы мяч отскакивал от нее, а не пролетал мимо. Это как теннис, в котором вы проигрываете, если не отбиваете мяч. Здесь у ИИ относительно легкая задача — решить, в каком направлении перемещать платформу.

Условные операторы
Для ИИ в Pong есть самое очевидное решение — всегда стараться расположить платформу под мячом.
Простой алгоритм для этого, написанный в псевдокоде:
every frame/update while the game is running:
if the ball is to the left of the paddle:
move paddle left
else if the ball is to the right of the paddle:
move paddle right
Если платформа двигается со скоростью мяча, то это идеальный алгоритм для ИИ в Pong. Не нужно ничего усложнять, если данных и возможных действий для агента не так уж и много.
Этот подход настолько прост, что весь цикл Sense/Think/Act едва заметен. Но он есть:
- Часть Sense находится в двух операторах if. Игра знает где мяч и где платформа, поэтому ИИ обращается к ней за этой информацией.
- Часть Think тоже входит в два оператора if. Они воплощают в себе два решения, которые в данном случае являются взаимоисключающими. В результате выбирается одно из трех действий — переместить платформу влево, переместить вправо, или ничего не делать, если она уже правильно расположена.
- Часть Act находится в операторах Move Paddle Left и Move Paddle Right. В зависимости от дизайна игры, они могут перемещать платформу мгновенно или с определенной скоростью.
Такие подходы называют реагирующими — есть простой набор правил (в данном случае операторы if в коде), которые реагируют на текущее состояние мира и действуют.
Дерево решений
Пример с игрой Pong фактически равен формальной концепции ИИ, называемой деревом решений. Алгоритм проходит его, чтобы достичь «листа» — решения о том, какое действие предпринять.
Сделаем блок-схему дерева решений для алгоритма нашей платформы:
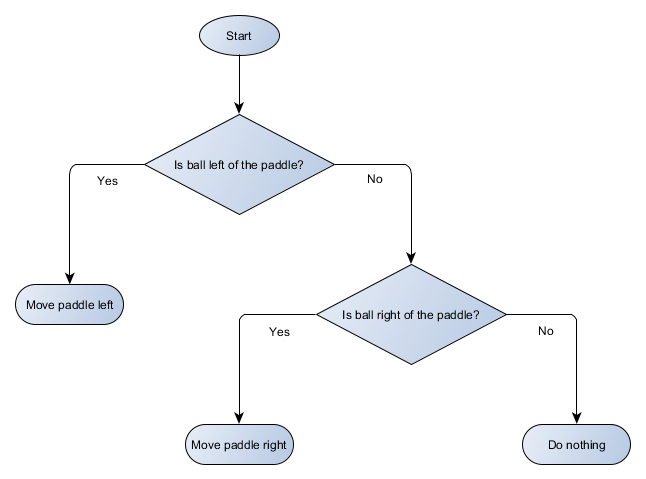
Каждая часть дерева называется node (узел) — ИИ использует теорию графов для описания подобных структур. Есть два типа узлов:
- Узлы принятия решений: выбор между двумя альтернативами на основе проверки некоторого условия, где каждая альтернатива представлена в виде отдельного узла.
- Конечные узлы: действие для выполнения, представляющее окончательное решение.
Алгоритм начинается с первого узла («корня» дерева). Он либо принимает решение о том, к какому дочернему узлу перейти, либо выполняет действие, хранящееся в узле, и завершается.
В чем же преимущество, если дерево решений, выполняет ту же работу, что и if-операторы в предыдущем разделе? Здесь есть общая система, где каждое решение имеет только одно условие и два возможных результата. Это позволяет разработчику создавать ИИ из данных, представляющих решения в дереве, избежав его хардкодинга. Представим в виде таблицы:
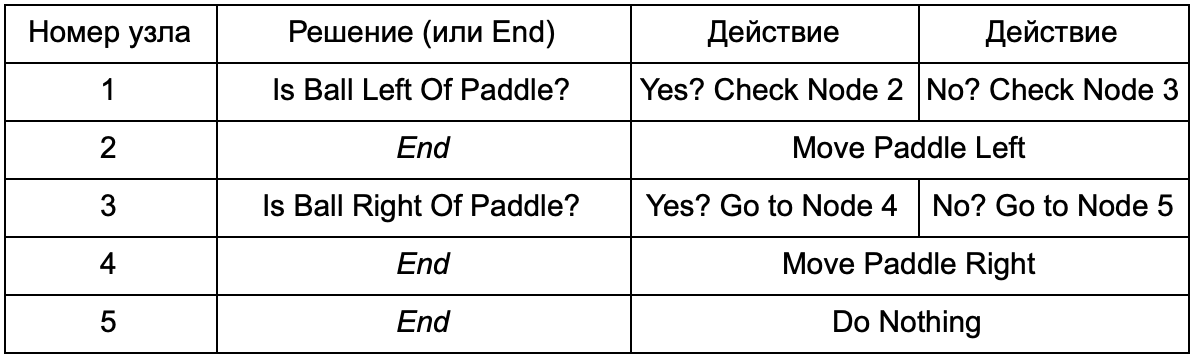
На стороне кода вы получите систему для чтения строк. Создайте узел для каждой из них, подключите логику принятия решений на основе второго столбца и дочерние узлы на основе третьего и четвертого столбцов. Вам все еще нужно запрограммировать условия и действия, но теперь структура игры будет сложнее. В ней вы добавляете дополнительные решения и действия, а затем настраиваете весь ИИ, просто отредактировав текстовый файл с определением дерева. Далее передаете файл геймдизайнеру, который сможет изменить поведение без перекомпилирования игры и изменения кода.
Деревья решений весьма полезны, когда они строятся автоматически на основе большого набора примеров (например, с использованием алгоритма ID3). Это делает их эффективным и высокопроизводительным инструментом для классификации ситуаций на основе получаемых данных. Однако мы выходим за рамки простой системы для выбора действий агентами.
Сценарии
Мы разобрали систему дерева решений, которая использовала заранее созданные условия и действия. Человек, проектирующий ИИ, может организовать дерево так, как хочет, но он все еще должен полагаться на кодера, который это все запрограммировал. Что если мы могли бы дать дизайнеру инструменты для создания собственных условий или действий?
Чтобы программисту не писать код для условий Is Ball Left Of Paddle и Is Ball Right Of Paddle, он может сделать систему, в которой дизайнер будет записывать условия для проверки этих значений. Тогда данные дерева решений будут выглядеть так:
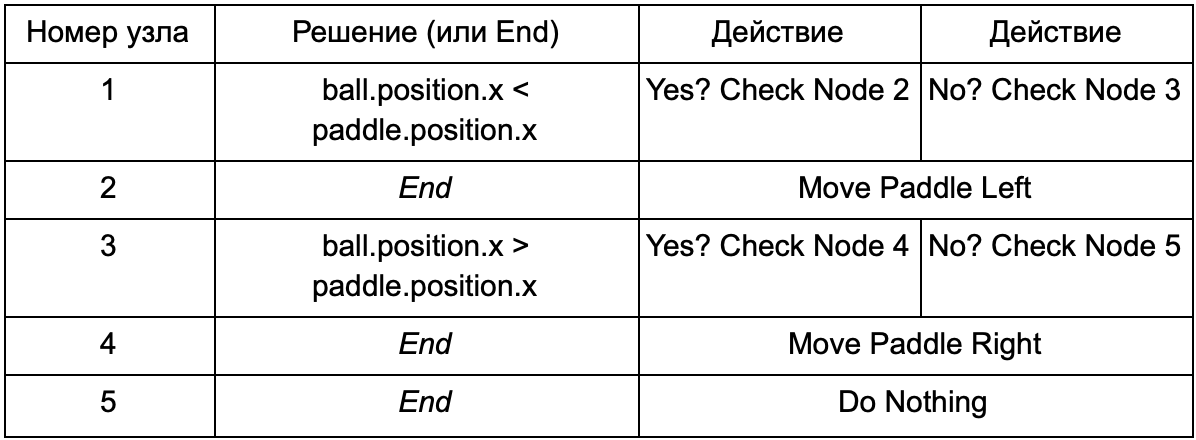
По сути это то же самое, что и в первой таблице, но решения внутри себя имеют свой собственный код, немного похожий на условную часть if-оператора. На стороне кода это считывалось бы во втором столбце для узлов принятия решений, но вместо поиска конкретного условия для выполнения (Is Ball Left Of Paddle), оно оценивает условное выражение и возвращает true или false соответственно. Это делается с помощью скриптового языка Lua или Angelscript. С помощью них разработчик может принимать объекты в своей игре (ball и paddle) и создавать переменные, которые будут доступны в сценарии (ball.position). Кроме того, язык сценариев проще, чем C++. Он не требует полной стадии компиляции, поэтому идеально подходит для быстрой корректировки игровой логики и позволяет «некодерам» самим создавать нужные функции.
В приведенном примере язык сценариев используется только для оценки условного выражения, но его также можно использовать и для действий. Например, данные Move Paddle Right, могут стать оператором сценария (ball.position.x += 10). Так, чтобы действие также определялось в скрипте, без необходимости программирования Move Paddle Right.
Можно пойти еще дальше и полностью написать дерево решений на языке сценариев. Это будет код в виде жестко запрограммированных (hardcoded) условных операторов, но они будут находится во внешних файлах скрипта, то есть могут быть изменены без перекомпиляции всей программы. Зачастую можно изменить файл сценария прямо во время игры, чтобы быстро протестировать разные реакции ИИ.
Реагирование на события
Примеры выше идеально подходят к Pong. Они непрерывно запускают цикл Sense/Think/Act и действуют на основе последнего состояния мира. Но в более сложных играх нужно реагировать на отдельные события, а не оценивать все и сразу. Pong в таком случае уже неудачный пример. Выберем другой.
Представьте шутер, где враги неподвижны пока не обнаружат игрока, после чего действуют в зависимости от своей «специализации»: кто-то побежит «рашить», кто-то будет атаковать издалека. Это все еще базовая реагирующая система — «если игрок замечен, то сделай что-нибудь», —, но ее можно логически разделить на событие Player Seen (игрок замечен) и реакцию (выберите ответ и выполните его).
Это возвращает нас к циклу Sense/Think/Act. Мы можем накодить Sense-часть, которая каждый кадр будет проверять — видит ли ИИ игрока. Если нет — ничего не происходит, но если видит, то создается событие Player Seen. У кода будет отдельный раздел, в котором говорится: «когда происходит событие Player Seen, сделай », где — ответ, который вам нужен для обращения к частям Think и Act. Таким образом, вы настроите реакции к событию Player Seen: на «рашущего» персонажа — ChargeAndAttack, а на снайпера — HideAndSnipe. Эти связи можно создать в файле данных для быстрого редактирования без необходимости заново компилировать. И здесь тоже можно использовать язык сценариев.
Принятие сложных решений
Хоть простые системы реакций очень действенны, бывает много ситуаций, когда их недостаточно. Иногда нужно принимать различные решения, основанные на том, что агент делает в настоящий момент, но представлять это за условие тяжело. Иногда существует слишком много условий, чтобы эффективно представить их в дереве решений или скрипте. Иногда нужно заранее оценивать, как изменится ситуация, прежде чем принимать решение о следующем шаге. Для решения этих проблем нужны более сложные подходы.
Finite state machine
Finite state machine или FSM (конечный автомат) — это способ сказать, что наш агент в настоящее время находится в одном из нескольких возможных состояний, и что он может переходить из одного состояния в другое. Таких состояний определённое количество — отсюда и название. Лучший пример из жизни — дорожный светофор. В разных местах разные последовательности огней, но принцип тот же — каждое состояние представляет что-то (стой, иди и т.д.). Светофор находится только в одном состоянии в любой момент времени, и переходит от одного к другому на основе простых правил.
С NPC в играх похожая история. Для примера возьмем стража с такими состояниями:
- Патрулирующий (Patrolling).
- Атакующий (Attacking).
- Убегающий (Fleeing).
И такими условиями для изменения его состояния:
- Если страж видит противника, он атакует.
- Если страж атакует, но больше не видит противника, он возвращается к патрулированию.
- Если страж атакует, но сильно ранен, он убегает.
Также можно написать if-операторы с переменной-состоянием стража и различные проверки: есть ли поблизости враг, какой уровень здоровья NPC и т. д. Добавим еще несколько состояний:
- Бездействие (Idling) — между патрулями.
- Поиск (Searching) — когда замеченный враг скрылся.
- Просить о помощи (Finding Help) — когда враг замечен, но слишком силен, чтобы сражаться с ним в одиночку.
Выбор для каждого из них ограничен — например, страж не пойдет искать скрывшегося врага, если у него низкое здоровье.
В итоге все это становится слишком сложным для длинного списка «если
». Упростим. Рассмотрим все состояния и перечислим все переходы в другие состояния вместе с необходимыми для этого условиями.
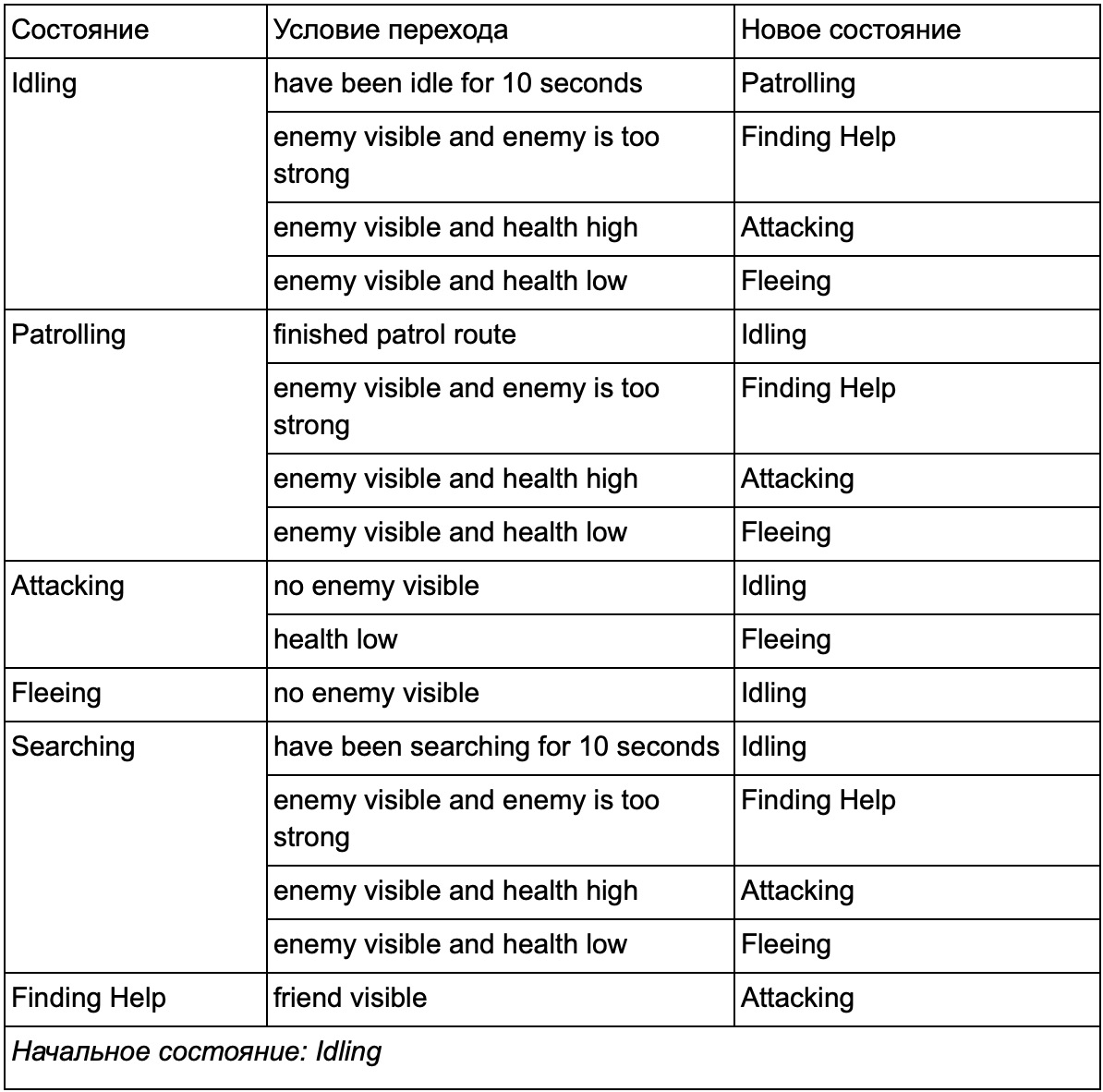
Это таблица переходов состояний — комплексный способ представления FSM. Нарисуем диаграмму и получим полный обзор того, как меняется поведение NPC.
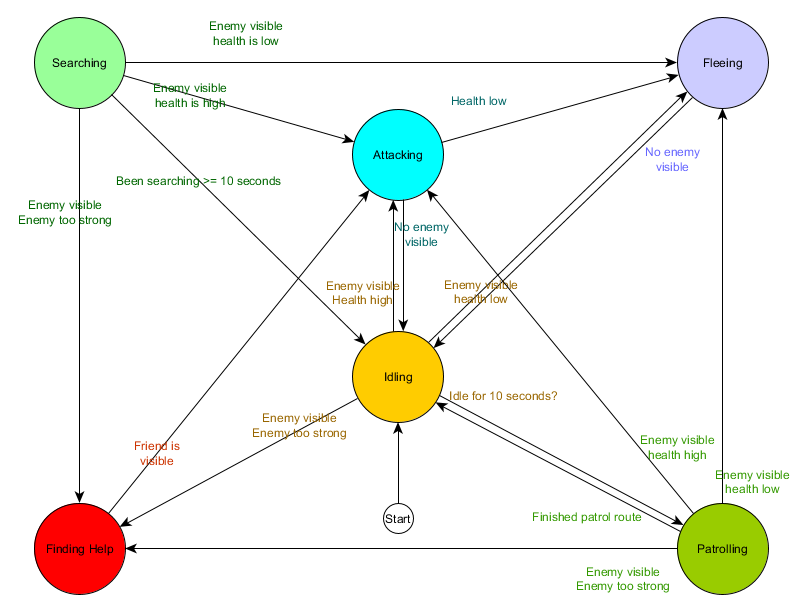
Диаграмма отражает суть принятия решений для этого агента на основе текущей ситуации. Причем каждая стрелка показывает переход между состояниями, если условие рядом с ней истинно.
Каждое обновление мы проверяем текущее состояние агента, просматриваем список переходов, и если условия для перехода выполнены, он принимает новое состояние. Например, каждый кадр проверяется истек ли 10-секундный таймер, и если да, то из состояния Idling страж переходит в Patrolling. Таким же образом, состояние Attacking проверяет здоровье агента — если оно низкое, то он переходит в состояние Fleeing.
Это обработка переходов между состояниями, но как насчет поведения, связанного с самими состояниями? Что касается реализации фактического поведения для конкретного состояния, обычно существует два типа «крюка», где мы присваиваем действия к FSM:
- Действия, которые мы периодически выполняем для текущего состояния.
- Действия, которые мы предпринимаем при переходе из одного состояния в другое.
Примеры для первого типа. Состояние Patrolling каждый кадр будет перемещать агента по маршруту патрулирования. Состояние Attacking каждый кадр будет пытаться начать атаку или перейти в состояние, когда это возможно.
Для второго типа рассмотрим переход «если враг виден и враг слишком силен, то перейти в состояние Finding Help. Агент должен выбрать, куда пойти за помощью, и сохранить эту информацию, чтобы состояние Finding Help знало куда обратиться. Как только помощь найдена, агент переходит обратно в состояние Attacking. В этот момент он захочет рассказать союзнику об угрозе, поэтому может возникнуть действие NotifyFriendOfThreat.
И снова мы можем посмотреть на эту систему через призму цикла Sense/Think/Act. Sense воплощается в данных, используемых логикой перехода. Think — переходами, доступными в каждом состоянии. А Act осуществляется действиями, совершаемыми периодически в пределах состояния или на переходах между состояниями.
Иногда непрерывный опрос условий перехода может быть дорогостоящим. Например, если каждый агент будет выполнять сложные вычисления каждый кадр, чтобы определить видит ли он врагов и понять, можно ли переходить от состояния Patrolling к Attacking — это займет много времени процессора.
Важные изменения в состоянии мира можно рассматривать как события, которые будут обрабатываться по мере их появления. Вместо того, чтобы FSM каждый кадр проверял условие перехода «может ли мой агент видеть игрока?», можно настроить отдельную систему, чтобы выполнять проверки реже (например, 5 раз в секунду). А результатом выдавать Player Seen, когда проверка проходит.
Это передается в FSM, который теперь должен перейти в условие Player Seen event received и соответствующе отреагировать. Итоговое поведение одинаково за исключением почти незаметной задержки перед ответом. Зато производительность стала лучше в результате отделения части Sense в отдельную часть программы.
Hierarchical finite state machine
Однако работать с большими FSM не всегда удобно. Если мы захотим расширить состояние атаки, заменив его отдельными MeleeAttacking (ближний бой) и RangedAttacking (дальний бой), нам придется изменить переходы из всех других состояний, которые ведут в состояние Attacking (текущие и будущие).
Наверняка вы заметили, что в нашем примере много дублированных переходов. Большинство переходов в состоянии Idling идентичны переходам в состоянии Patrolling. Хорошо бы не повторяться, особенно если мы добавим больше похожих состояний. Имеет смысл сгруппировать Idling и Patrolling под общим ярлыком «небоевые», где есть только один общий набор переходов в боевые состояния. Если мы представим этот ярлык как состояние, то Idling и Patrolling станут подсостояниями. Пример использования отдельной таблицы переходов для нового небоевого подсостояния:
Основные состояния: 
Состояние вне боя: 
И в форме диаграммы:
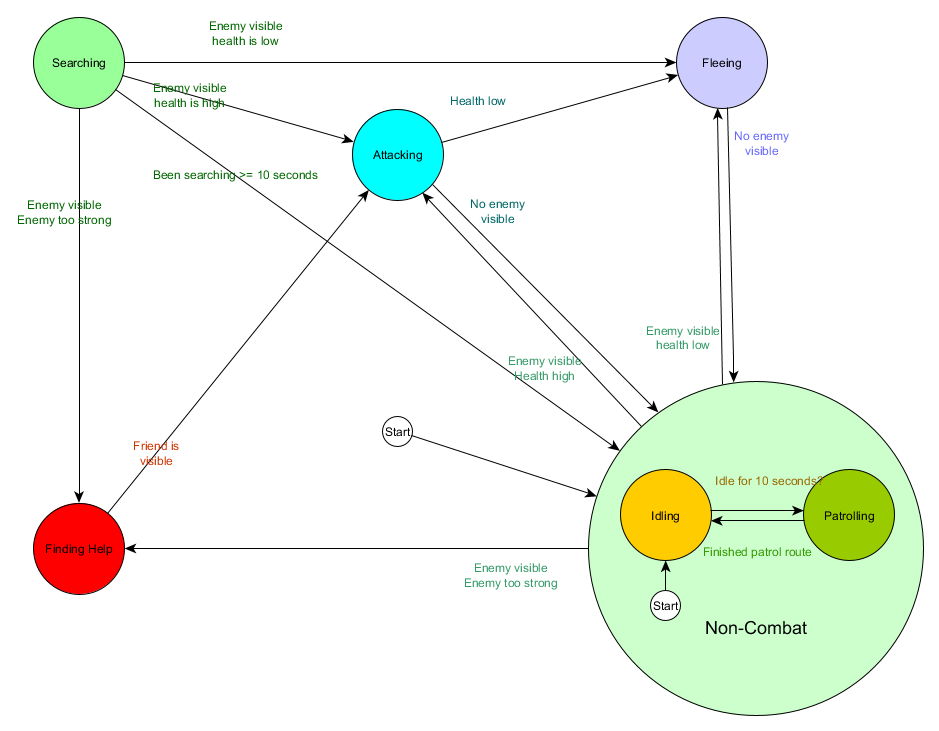
Это та же самая система, но с новым небоевым состоянием, которое включает в себя Idling и Patrolling. С каждым состоянием, содержащим FSM с подсостояниями (а эти подсостояния, в свою очередь, содержат собственные FSM — и так далее сколько вам нужно), мы получаем Hierarchical Finite State Machine или HFSM (иерархический конечный автомат). Сгруппировав небоевое состояние, мы вырезали кучу избыточных переходов. То же самое мы можем сделать для любых новых состояний с общими переходами. Например, если в будущем мы расширим состояние Attacking до состояний MeleeAttacking and MissileAttacking, они будут подсостояниями, переходящими между друг другом на основе расстояния до врага и наличия боеприпасов. В итоге сложные модели поведения и подмодели поведения можно представить с минимумом дублированных переходов.
Дерево поведений
С HFSM создаются сложные комбинации поведений простым способом. Тем не менее, есть небольшая трудность, что принятие решений в виде правил перехода тесно связано с текущим состоянием. И во многих играх это как раз то, что нужно. А тщательное использование иерархии состояний может уменьшить количество повторов при переходе. Но иногда нужны правила, работающие независимо от того, в каком состоянии вы находитесь или которые применяются почти в любых состояниях. Например, если здоровье агента упало до 25%, вы захотите, чтобы он убегал независимо от того, был ли он в бою, бездельничал или разговаривал — вам придется добавлять это условие в каждое состояние. А если ваш дизайнер позже захочет изменить порог низкого здоровья с 25% до 10%, то этим снова придется заниматься.
В идеале для этой ситуации нужна система, в которой решения «в каком состоянии пребывать», находятся за пределами самих состояний, чтобы вносить изменения только в одном месте и не трогать условия перехода. Здесь появляются деревья поведений.
Существует несколько способов их реализации, но суть для всех примерно одинакова и похожа на дерево решений: алгоритм начинается с «корневого» узла, а в дереве находятся узлы, представляющие либо решения, либо действия. Правда есть несколько ключевых отличий:
- Теперь узлы возвращают одно из трех значений: Succeeded (если работа выполнена), Failed (если нельзя запустить) или Running (если она все еще запущена и нет конечного результата).
- Больше нет узлов решений для выбора между двумя альтернативами. Вместо них узлы Decorator, у которых есть один дочерний узел. Если они Succeed, то выполняют свой единственный дочерний узел.
- Узлы, выполняющие действия, возвращают значение Running для представления выполняемых действий.
Этот небольшой набор узлов можно объединить для создания большого количества сложных моделей поведения. Представим HFSM стража из предыдущего примера в виде дерева поведения:
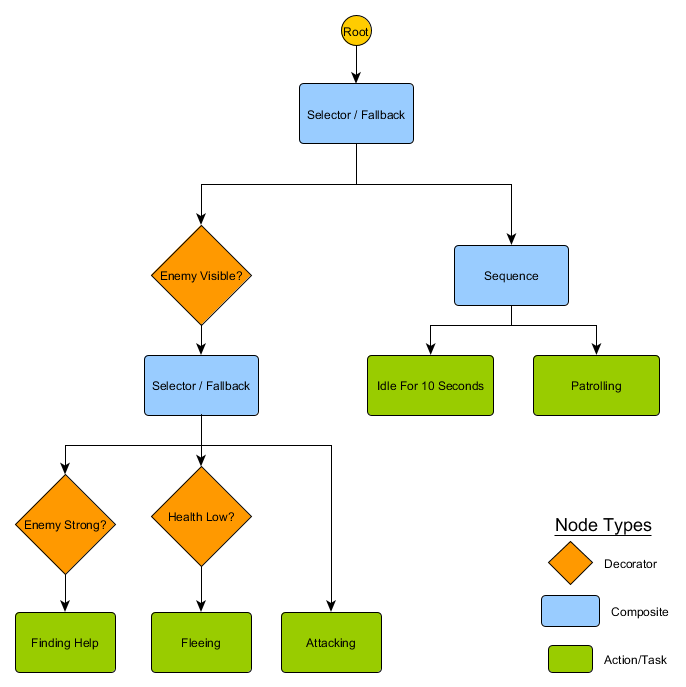
С этой структурой не должно быть явного перехода от состояний Idling/Patrolling к состоянию Attacking или любым другим. Если враг виден, а здоровье персонажа низкое, выполнение остановится на узле Fleeing, независимо от того, какой узел он ранее выполнял — Patrolling, Idling, Attacking или любой другой.
Деревья поведений сложны — есть много способов их составить, да и найти правильное сочетание декораторов и составных узлов может быть проблематично. Есть также вопросы о том, как часто проверять дерево — мы хотим проходить его каждую часть или только тогда, когда одно из условий изменилось? Как хранить состояние, относящееся к узлам — как узнать, когда мы были в состоянии Idling в течение 10 секунд или как узнать, какие узлы выполнялись в прошлый раз, чтобы правильно обработать последовательность?
Именно поэтому существует множество реализаций. Например, в некоторых системах узлы декоратора заменили встроенными декораторами. Они повторно оценивают дерево при изменении условий декоратора, помогают присоединиться к узлам и обеспечивают периодические обновления.
Utility-based system
У некоторых игр есть множество различных механик. Желательно, чтобы они получили все преимущества простых и общих правил перехода, но не обязательно в виде полного дерева поведения. Вместо того, чтобы иметь чёткий набор выборов или дерево возможных действий, проще изучить все действия и выбрать самое подходящее в данный момент.
Utility-based system (система, основанная на полезности) как раз в этом поможет. Это система, где у агента есть множество действий, и он сам выбирает какое выполнить, основываясь на относительной полезности каждого. Где полезность — произвольная мера того, насколько важно или желательно выполнение этого действия для агента.
Рассчитанную полезность действия на основе текущего состояния и среды, агент может проверить и выбрать наиболее подходящее другое состояние в любое время. Это похоже на FSM, за исключением того, где переходы определяются оценкой для каждого потенциального состояния, включая текущее. Обратите внимание, что мы выбираем самое полезное действие для перехода (или остаемся, если уже выполнили его). Для большего разнообразия это может быть взвешенный, но случайный выбор из небольшого списка.
Система назначает произвольный диапазон значений полезности — например, от 0 (совершенно нежелательно) до 100 (полностью желательно). У каждого действия есть ряд параметров, влияющих на вычисление этого значения. Возвращаясь к нашему примеру со стражем:

Переходы между действиями неоднозначны — любое состояние может следовать за любым другим. Приоритеты действий находятся в возвращаемых значениях полезности. Если враг виден, и этот враг силен, а здоровье персонажа низкое, то и Fleeing, и FindingHelp вернут высокие ненулевые значения. При этом FindingHelp всегда будет выше. Аналогичным образом, небоевые действия никогда не возвращают больше 50, поэтому они всегда будут ниже боевых. Нужно учитывать это при создании действий и вычислении их полезности.
В нашем примере действия возвращают либо фиксированное постоянное значение, либо одно из двух фиксированных значений. Более реалистичная система предполагает возврат оценки из непрерывного диапазона значений. Например, действие Fleeing возвращает более высокие значения полезности, если здоровье агента низкое, а действие Attacking возвращает более низкие, если враг слишком силен. Из-за этого действие Fleeing имеет приоритет над Attacking в любой ситуации, когда агент чувствует, что у него недостаточно здоровья для победы над противником. Это позволяет изменять приоритеты действий на основе любого числа критериев, что делает такой подход более гибким и вариативным, чем дерево поведения или FSM.
Каждое действие имеет много условий для расчета программы. Их можно написать на языке сценариев или в виде серии математических формул. В The Sims, которая моделирует распорядок дня персонажа, добавляют дополнительный уровень вычислений — агент получает ряд «мотиваций», влияющих на оценки полезности. Если персонаж голоден, то со временем он будет голодать еще сильнее, и результат полезности действия EatFood будет расти до тех пор, пока персонаж не выполнит его, снизив уровень голода, и вернув значение EatFood равным нулю.
Идея выбора действий на основе системы оценок довольно проста, поэтому Utility-based system можно использовать как часть процессов принятия решений ИИ, а не как их полную замену. Дерево решений может запросить оценку полезности двух дочерних узлов и выбрать более высокую. Аналогичным образом, дерево поведения может иметь составной узел Utility для оценки полезности действий, чтобы решить, какой дочерний элемент выполнить.
Движение и навигация
В предыдущих примерах у нас была платформа, которую мы перемещали влево или вправо, и страж, который патрулировал или атаковал. Но как именно мы обрабатываем перемещение агента в течение определенного периода времени? Как мы устанавливаем скорость, как мы избегаем препятствий, и как мы планируем маршрут, если добраться до места назначения сложнее, чем просто двигаться по прямой? Давайте это рассмотрим.
Управление
На начальном этапе будем считать, что каждый агент имеет значение скорости, которое включает в себя, как быстро он двигается и в каком направлении. Она может быть измерена в метрах в секунду, километрах в час, пикселей в секунду и т. д. Вспоминая цикл Sense/Think/Act, мы можем представить, что часть Think выбирает скорость, а часть Act применяет эту скорость к агенту. Обычно в играх есть физическая система, которая выполняет эту задачу за вас, изучая значение скорости каждого объекта и регулируя ее. Поэтому можно оставить ИИ с одной задачей — решить, какую скорость должен иметь агент. Если известно, где агент должен быть, то нужно переместить его в правильном направлении с установленной скоростью. Очень тривиальное уравнение:
desired_travel = destination_position — agent_position
Представьте 2D-мир. Агент находится в точке (-2,-2), пункт назначения где-то на северо-востоке в точке (30, 20), а необходимый путь для агента, чтобы оказаться там — (32, 22). Допустим, эти позиции измеряются в метрах — если принять скорость агента за 5 метров в секунду, то мы будем масштабировать наш вектор перемещения и получим скорость примерно (4.12, 2.83). С этими параметрами агент прибыл бы к месту назначения почти через 8 секунд.
Пересчитать значения можно в любое время. Если агент был на полпути к цели, перемещение было бы половиной длины, но так как максимальная скорость агента 5 м/с (мы это решили выше), скорость будет одинаковой. Это также работает для движущихся целей, позволяя агенту вносить небольшие изменения по мере их перемещения.
Но мы хотим больше вариативности — например, медленно нарастить скорость, чтобы симулировать персонажа, движущегося из стоячего состояния и переходящего к бегу. Тоже самое можно сделать в конце перед остановкой. Эти фичи известны как steering behaviours, каждое из которых имеет конкретные имена: Seek (поиск), Flee (бегство), Arrival (прибытие) и т. д. Идея заключается в том, что силы ускорения могут быть применены к скорости агента, на основе сравнения положения агента и текущей скорости с пунктом назначения, чтобы использовать различные способы перемещения к цели.
Каждое поведение имеет немного другую цель. Seek и Arrival — это способы перемещения агента к точке назначения. Obstacle Avoidance (избегание препятствий) и Separation (разделение) корректируют движение агента, чтобы обходить препятствия на пути к цели. Alignment (согласование) и Cohesion (связь) держат агентов при перемещении вместе. Любое число различных steering behaviours может быть суммировано для получения одного вектора пути с учётом всех факторов. Агент, использующий поведения Arrival, Separation и Obstacle Avoidance, чтобы держаться подальше от стен и других агентов. Этот подход хорошо работает в открытых локациях без лишних деталей.
В более трудных условиях, сложение разных поведений работает хуже — к примеру, агент может застрять в стене из-за конфликта Arrival и Obstacle Avoidance. Поэтому нужно рассматривать варианты, которые сложнее, чем просто сложение всех значений. Способ такой: вместо сложения результатов каждого поведения, можно рассмотреть движение в разных направлениях и выбрать лучший вариант.
Однако в сложной среде с тупиками и выбором, в какую сторону идти, нам понадобится что-то ещё более продвинутое.
Поиск пути
Steering behaviours отлично подходит для простого движения на открытой местности (футбольное поле или арена), где добраться от А до Б — это прямой путь с небольшими отклонениями мимо препятствий. Для сложных маршрутов нам нужен pathfinding (поиск пути), который является способом изучения мира и принятия решения о маршруте через него.
Самый простой — наложить сетку на каждый квадрат рядом с агентом и оценить в каких из них разрешено двигаться. Если какой-то из них является пунктом назначения, то следуйте из него по маршруту от каждого квадрата к предыдущему, пока не дойдете до начала. Это и есть маршрут. В противном случае повторяйте процесс с ближайшими другими квадратами, пока не найдете место назначения или не закончатся квадраты (это означает, что нет никакого возможного маршрута). Это то, что формально известно как Breadth-First Search или BFS (алгоритм поиска в ширину). На каждом шаге он смотрит во всех направлениях (поэтому breadth, «ширина»). Пространство поиска похоже на волновой фронт, который перемещается, пока не достигнет искомое место — область поиска расширяется на каждом шаге до тех пор, пока в нее не попадет конечная точка, после чего можно отследить путь к началу.
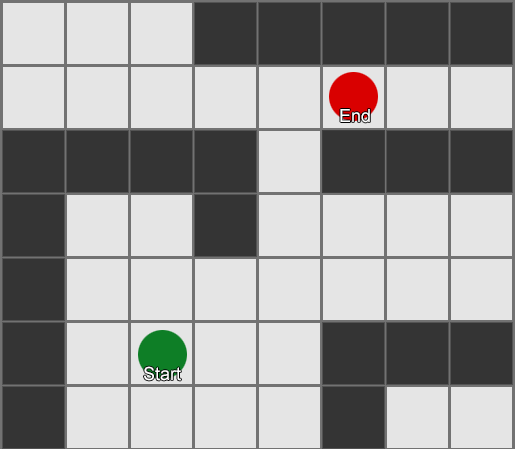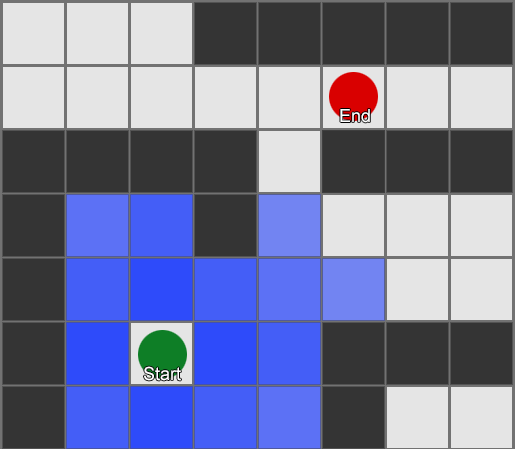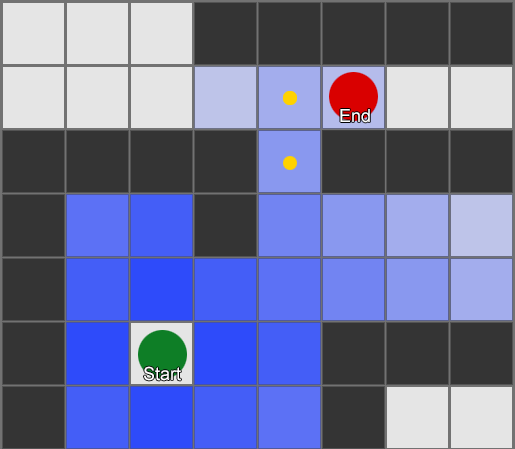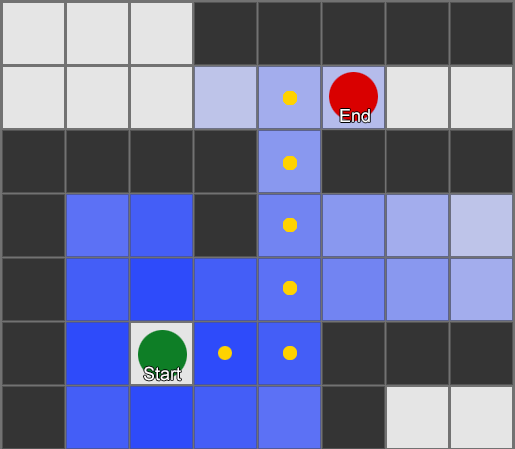
В результате вы получите список квадратов, по которым составляется нужный маршрут. Это и есть путь (отсюда, pathfinding) — список мест, которые агент посетит, следуя к пункту назначения.
Учитывая, что мы знаем положение каждого квадрата в мире, можно использовать steering behaviours, чтобы двигаться по пути — от узла 1 к узлу 2, затем от узла 2 к узлу 3 и так далее. Простейший вариант — направиться к центру следующего квадрата, но еще лучше — остановиться на середине грани между текущим квадратом и следующим. Из-за этого агент сможет срезать углы на крутых поворотах.
У алгоритма BFS есть и минусы — он исследует столько же квадратов в «неправильном» направлении, сколько в «правильном». Здесь появляется более сложный алгоритм под названием A* (A star). Он работает также, но вместо слепого изучения квадратов-соседей (затем соседей соседей, затем соседей соседей соседей и так далее), он собирает узлы в список и сортирует их так, что следующий исследуемый узел всегда тот, который приведет к кратчайшему маршруту. Узлы сортируются на основе эвристики, которая учитывает две вещи — «стоимость» гипотетического маршрута к нужному квадрату (включая любые затраты на перемещение) и оценку того, насколько далеко этот квадрат от места назначения (смещая поиск в правильном направлении).
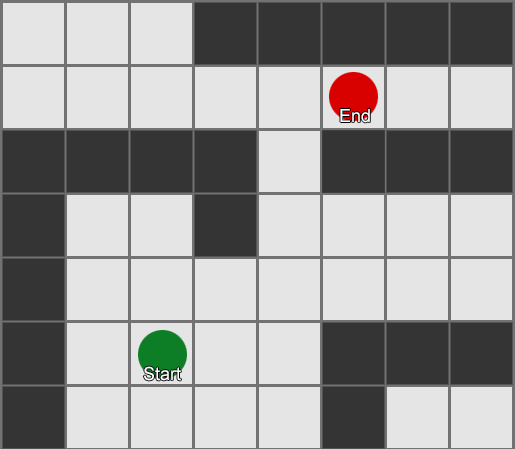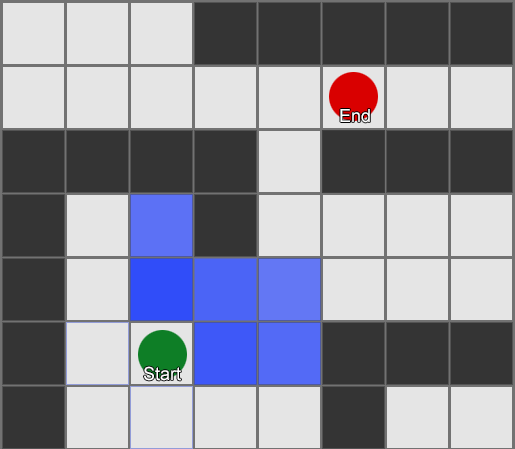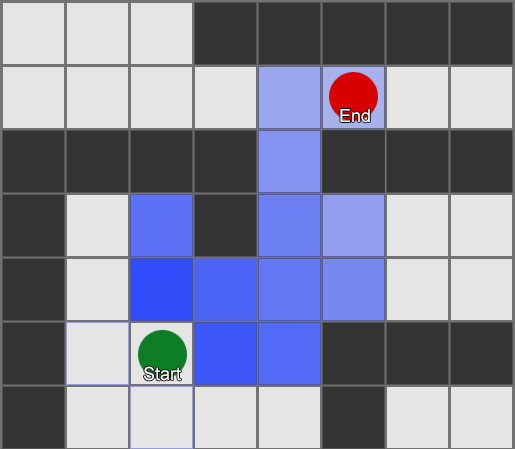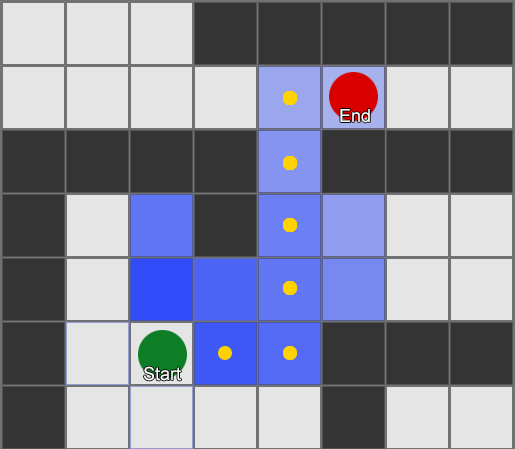
В этом примере показано, что агент исследует по одному квадрату за раз, каждый раз выбирая соседний, который является самым перспективным. Полученный путь такой же, как и при BFS, но в процессе было рассмотрено меньше квадратов —, а это имеет большое значение для производительности игры.
Движение без сетки
Но большинство игр не выложены на сетке, и зачастую ее невозможно сделать без ущерба реалистичности. Нужны компромиссы. Каких размеров должны быть квадраты? Слишком большими — и они не смогут правильно представить небольшие коридоры или повороты, слишком маленькими — будет чрезмерно много квадратов для поиска, который в итоге займет кучу времени.
Первое, что нужно понять — сетка дает нам граф связанных узлов. Алгоритмы A* и BFS фактически работают на графиках и вообще не заботятся о нашей сетке. Мы могли бы поставить узлы в любых местах игрового мира: при наличии связи между любыми двумя соединенными узлами, а также между начальной и конечной точкой и по крайней мере одним из узлов — алгоритм будет работать также хорошо, как и раньше. Часто это называют системой путевых точек (waypoint), так как каждый узел представляет собой значимую позицию в мире, которая может быть частью любого количества гипотетических путей.
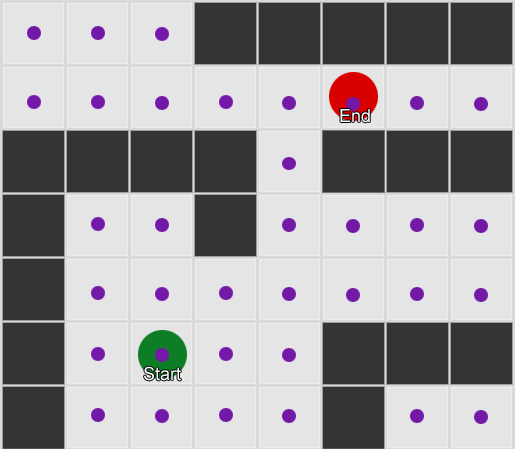
Пример 1: узел в каждом квадрате. Поиск начинается из узла, в котором находится агент, и заканчивается в узле нужного квадрата.
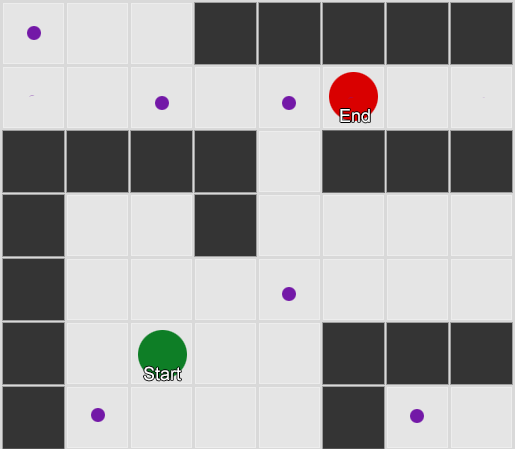
Пример 2: меньший набор узлов (путевых точек). Поиск начинается в квадрате с агентом, проходит через необходимое количество узлов, и затем продолжается до пункта назначения.
Это вполне гибкая и мощная система. Но нужна некоторая осторожность в решениях, где и как поместить waypoint, иначе агенты могут просто не увидеть ближайшую точку
