[Перевод] Как проверить причинную связь без эксперимента?

Сегодня поговорим об установлении причинных связей между явлениями, когда невозможно провести эксперимент и А/В-тесты.
Это довольно простая статья, которая будет полезна начинающим в статистике и машинном обучении или тем, кто раньше над такими вопросами не задумывался.
Действительно ли пациентам, тестирующим новое лекарство, становится лучше из-за лекарства, или они все все равно бы выздоровели? Ваши продавцы действительно эффективны или же они говорят с теми клиентами, которые и так готовы совершить покупку? Действительно ли Сойлент (или рекламная кампания, которая обойдётся фирме в миллион долларов) стоит вашего времени?
Установление причинных связей
Причинная связь невероятно важна, но иногда ее очень сложно установить.
К вашему столу подходит коллега. Он замешивает себе Сойлент — растворимый заменитель еды, и предлагает вам попробовать. Сойлент выглядит отвратительно, и вы интересуетесь, чем же он полезен. Коллега отвечает, что его друзья, которые употребляли этот напиток в течение нескольких месяцев, недавно пробежали марафон. А до этого они не бегали? — Бегали, в прошлом году они тоже пробежали марафон.
В идеальном мире мы могли бы в любое время провести эксперимент — золотой стандарт в установлении причинных связей. В реальности это не всегда возможно. Есть сомнения в этичности применения плацебо или опасных непроверенных лекарств. Руководство может не захотеть пытаться продавать товар случайному набору покупателей с целью получения возможного кратковременного подъема прибыли, да и команда, получающая бонусы с продаж, может взбунтоваться против этой идеи.
Как же установить причинные связи, не применяя A/B тестирование? Здесь-то и вступают в игру Propensity Modeling и другие методы установления причинных связей.
Propensity Modeling
Итак, предположим, что мы хотим смоделировать эффект от употребления Сойлента, используя метод Propensity Modeling (метод подбора контрольных групп по индексу соответствия). Чтобы объяснить его идею, проведём мысленный эксперимент.
Представим, что у Брэда Питта есть брат-близнец — точная его копия. Брэд 1 и Брэд 2 просыпаются в одно и то же время, одинаково питаются, получают одинаковые физические нагрузки. Однажды Брэду 1 удаётся купить последнюю пачку Сойлента у уличного торговца, а Брэд 2 не успевает, поэтому только Брэд 1 начинает включать Сойлент в свою диету. При таком сценарии любое дальнейшее различие в самочувствии близнецов — совершенно определенно следствие употребления Сойлента.
Переводя вышеописанный сценарий в реальную жизнь, один из способов оценить влияние Сойлента на здоровье был бы таким:
Для каждого индивида, употребляющего Сойлент, мы находим не употребляющего, сопоставимого по наблюдаемым характеристикам с первым. Например, мы могли бы поставить в соответствие пьющему Сойлент Jay-Z непьющего Канье Уэста, употребляющей Натали Портмэн — не употребляющую Киру Найтли, а любительнице Сойлента Дж. К. Роулинг — нелюбительницу Стефани Мейер.
Мы измеряем эффект Сойлента как различия между каждой парой «близнецов».
Тем не менее, на практике найти максимально схожих людей невероятно сложно. Действительно ли Jay-Z соответствует Канье, если Jay-Z спит в среднем на час больше Канье? А можем ли мы сопоставить Jonas Brothers и One Direction?
Propensity Modeling — это упрощение вышеизложенного метода подбора контрольных групп. Вместо нахождения похожих индивидов на основании многочисленных характеристик, мы устанавливаем соответствие на основании одного единственного индекса, характеризующего вероятность того, что индивид будет пить Сойлент («propensity», «склонность»).
Более детально, метод подбора контрольных групп на основании индекса соответствия состоит в следующем:
- Для начала определим, какие из характеристик индивида будут служить критериями отбора (например, как человек питается, когда спит, где живёт, и т.д.)
- Затем построим вероятностную модель (скажем, логистические регрессию) на основании отобранных переменных, чтобы предсказать, будет ли пользователь пить Сойлент. Например, наша обучающая выборка может состоять из множества людей, некоторые из которых заказали напиток в первую неделю марта 2016 года, и обучим классификатор определять, кто из пользователей станет пользователем Сойлента.
- Вероятностная оценка того, что индивид станет пользователем нашего продукта, называется индексом соответствия.
- Сформируем несколько групп, например, пусть будет всего 10 групп: в первую входят пользователи с вероятностью начала употребления Сойлент равной 0–0.1, во вторую — с вероятностью 0.1–0.2, и т.д.
- И наконец, сравним адептов и не-адептов Сойлента в каждой группе (например, сравним их физическую активность, вес или любой другой показатель здоровья), чтобы оценить эффект от напитка.
Например, вот гипотетическое распределение пьющих и непьющих Сойлент по возрасту. Мы можем заметить, что те, кто употребляет напиток, в основном, старше, и этот вмешивающийся фактор — одна из причин, по которой мы не можем просто провести корреляционный анализ.

После обучения модели оценивать индекс соответствия и распределения пользователей по группам в зависимости от данного индекса вот так может выглядеть график, характеризующий влияние напитка на расстояние, которое потребитель пробегает в неделю.

На этом гипотетическом графике каждая из частей соответствует группе по индексу соответствия, а неделя начала воздействия — первая неделя марта, когда групп испытуемых получила первые порции Сойлента. Мы видим, что до этой недели все испытуемые пробегали неплохие расстояние. Тем не менее, после того как группа, получающая препарат, начинает «лечение», они начинают бегать больше, так что мы можем оценить эффект от употребления напитка.
Другие методы установления причинных связей
Без сомнения, существует много других методов установления причинных связей между наблюдаемыми явлениями. Я вкратце расскажу о двух своих любимых (я изначально написал этот пост в ответ на вопрос с Quora, поэтому и примеры взял оттуда).
Построение модели разрывной регрессии
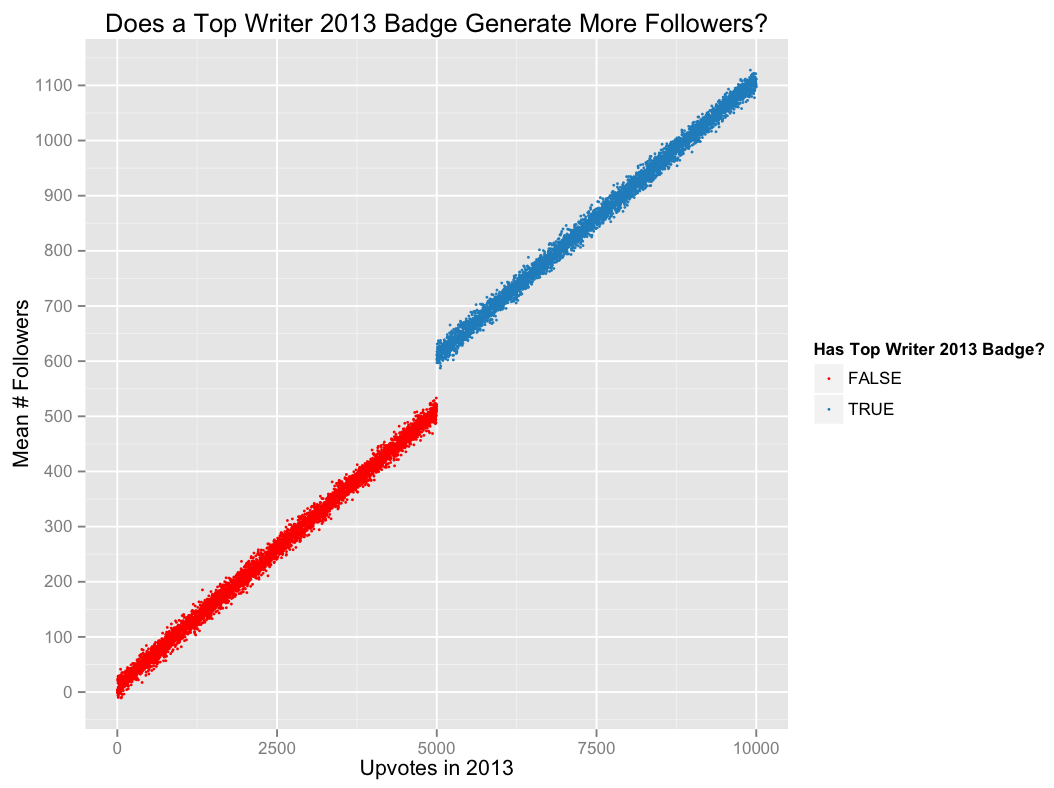
На ресурсе Quora не так давно начали отображать значки статусов (бейджи) на страницах профилей наиболее активных пользователей. Предположим, мы хотим оценить эффект от этого нововведения (допустим, что раз функциональность уже добавлена, провести А/В тестирование невозможно). В частности, нас интересует, поможет ли пользователю бейдж Топ-Автора приобрести больше подписчиков.
Для простоты предположим, что бейдж выдаётся каждому пользователю, который за предыдущий год получил 5000 и более голосов. Идея, которая лежит в основе разрывной регрессии, состоит том, что различие между пользователями, находящихся вблизи порога, определяющего получение или неполучение бейджа (например, теми, кто заработал 4999 голосов и не получил бейдж, и теми, кто заработал 5000 голосов и получил бейдж) можно считать более-менее случайным событием. Это значит, что мы можем использовать выборку, взятую в непосредственной близости от указанного порога, для установления причинных связей.
Например, на воображаемом графике ниже разрыв в районе 5000 подписчиков позволяет сделать вывод, что бейдж Топ-Автора в среднем приводит к увеличению числа подписчиков на 100.
Естественный эксперимент
Тем не менее, выяснение влияния бейджей на количество подписчиков — не слишком интересный вопрос (это лишь простой пример). Можно было бы задать более глубокий вопрос: что происходит, когда пользователь находит своего любимого автора? Вдохновлят ли автор читателя на создание собственных материалов, дальнейшие исследования, тем самым поощряя дальнейшее взаимодействие с сайтом? Насколько важен контакт с лучшими авторами по сравнению с чтением случайной подборки лучших статей?
Я изучал аналогичный случай, когда работал в Google, поэтому, вместо воображаемого примера с Quora, расскажу лучше о работе, который занимался там.
Предположим, мы хотим понять, что произошло бы, если бы мы могли поставить в соответствие каждому пользователю идеальный канал на YouTube.
- Приводит ли увлечение одним каналом к увеличению вовлечённости пользователя вне рамок этого канала, например, потому что пользователь заходит на YouTube, чтобы посмотреть свой любимый канал, а потом остаётся посмотреть что-нибудь ещё? Такое явление называется мультипликативный эффект. Пример из мира телевидения: телезритель остаётся дома воскресным вечером специально, чтобы посмотреть очередной эпизод «Отчаянных домохозяек», а когда серия заканчивается, переключает каналы в поисках чего-нибудь ещё интересного.
- Приводит ли увлечение одним каналом к увеличению активности на этом канале (так называемый аддитивный эффект)?
- Замещает ли любимый канал другие каналы в списке предпочтений пользователя? В конце концов, время, которое пользователь может проводить на сайте, ограничено. Это называется нейтральный эффект.
- Наоборот, не уменьшается ли время, которое пользователь проводит на сайте, с появлением идеального канала, так как он тратит меньше времени на пролистывание и поиск интересных видео? Тогда мы наблюдали бы негативный эффект.
Как всегда, идеально было бы провести A/B тестирование, но в данном случае это невозможно: мы не можем заставить пользователя полюбить определённый канал (мы можем рекомендовать каналы пользователям, но они совсем не обязательно им понравятся), мы также не можем и запретить им смотреть другие каналы.
Один из подходов к исследованию этого эффекта — естественный эксперимент — сценарий, когда Вселенная сама генерирует для нас выборку, близкую к случайной. Вот в чем его идея.
Рассмотрим пользователя, который загружает новое видео каждую среду. Однажды он сообщает подписчикам, что не будет размещать новых видео в течение нескольких недель, пока он в отпуске.
Как отреагируют подписчики? Перестанут ли они смотреть YouTube по средам, потому что обычно они посещают сайт только ради этого канала? Или их активность не изменится, так как они смотрят упомянутый канал только когда он появляется на главной странице?
Теперь наоборот, давайте представим, что канал начал загружать новые видеозаписи по пятницам. Начнут ли подписчики посещать сайт также и по пятницам? И будут ли они, раз уж зашли на YouTube, смотреть только новое видео, или это породит водопад поисковых запросов и связанного контента?
Оказывается, все эти сценарии могут иметь место. Вот, например, календарь загрузки видео одним популярным YouTube каналом. Как видно, в 2011 году они обычно публиковали видео по вторникам и пятницам, но в конце года сдвинули дни публикации на среду и субботу.
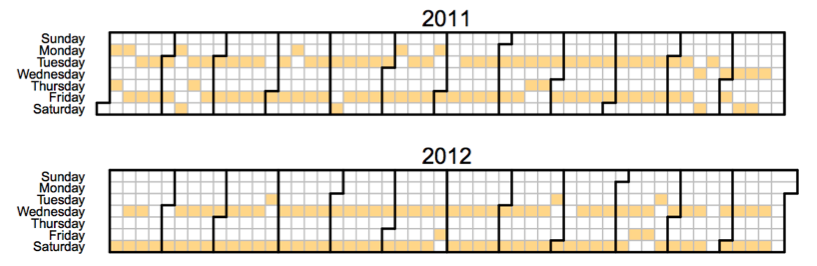
Используя это изменение в расписании в качестве естественного эксперимента, который псевдослучайно отменяет просмотр любимого канала по определённым дням и вводит его по другим, можем попытаться понять эффект от удачной рекомендации идеального канала.
Этот пример естественного эксперимента может показаться несколько запутанным. Следующий пример, возможно, может служить более наглядной иллюстрацией идеи. Допустим, мы хотим исследовать влияние величины дохода на душевное здоровье. Вот эта статья в Нью-Йорк Таймс описывает естественный эксперимент, в рамках которого индейцы чероки распределяли доходы от казино между членами племени, таким образом «случайно» выводя некоторых из них из состояния бедности.
Определение факторов роста
Вернёмся к Propensity Modeling.
Представим, что мы сотрудники группы развития нашей компании, и перед нами стоит задача найти способ превращать случайных посетителей сайта в пользователей, которые возвращаются на него каждый день. Что же нам делать?
Если бы мы использовали Propensity Modeling, подход был бы следующим. Мы могли бы взять список событий (установка мобильного приложения, авторизация, подписка на новостную рассылку или на определённого пользователя и т.д.) и построить модель на основе индекса соответствия для каждого из них. Затем мы могли бы ранжировать каждое из событий в зависимости от эффекта, который оно имеет на вовлечённость пользователя, и использовать наш упорядоченный список в следующей итерации (или с помощью этих цифр убедить руководство, что нам нужно больше ресурсов). Это слегка усложнённая идея построения регрессионной модели вовлечённости (или регрессионной модели оттока) клиентов и оценки веса каждой функциональности.
Несмотря на то что я пишу этот пост, я не большой поклонник использования Propensity Modeling для многих приложений в сфере техники (я не работал в сфере медицины, поэтому у меня нет определённого мнения о его полезности в этой области, хотя, думаю, здесь оно более необходимо). Я приберегу все мои доводы для следующего раза, скажу лишь, что анализ причинных связей — невероятно сложная штука, и мы никогда не сможем учесть все скрытые факторы, влияющие на отношение пользователя. К тому же, просто тот факт, что нам приходится выбирать, какие из событий включать в нашу модель, означает, что мы изначально верим в пользу каждой из них, в то время как на самом деле мы хотели бы обнаружить скрытые факторы, влияющие на вовлечённость, о которых мы никогда бы и не подумали.
Заключение
Подытожим: Propensity Modeling — это мощная техника выявления причинных зависимостей в отсутствие возможности проведения случайного эксперимента.
Чистый корреляционный анализ на основе наблюдений, в конце концов, может быть крайне опасен. Приведу свой любимый пример: если мы обнаружим, что в городах с наибольшим штатом полиции обычно выше уровень преступности, значит ли это, что мы должны сократить количество полицейских, чтобы сократить преступность в стране?
В качестве ещё одного примера — статья о заместительной гормональной терапи в рамках исследования здоровья медицинских сестёр (Nurses» Health Study).
И помните, что модель обычно настолько хороша, насколько хороши данные, которые вы подаёте на вход. Учесть все скрытые переменные, которые могут иметь значение, — очень сложная задача, и в причинно-следственной модели, которая кажется вам хорошо продуманной, на самом деле может не хватать некоторых факторов (я где-то слышал, что Propensity Modeling в случае с медсёстрами привело к ложным заключениям). Поэтому всегда стоит рассмотреть альтернативные подходы к решению вашей задачи, нет ли методов установления причинных связей попроще, а может быть стоит просто спросить пользователей. И даже если случайный эксперимент кажется вам сейчас неподъемной задачей, попытка может помочь избежать многих проблем в дальнейшем.
О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io
