[Перевод] Как написать генератор изображений, который вас понимает
Автор статьи рассказывает, как за неделю создал Text2Art.com — генератор изображений на основе VQGAN+CLIP, способный рисовать пиксель-арт и живопись, а также изображать то, что вы напишите в текстовом поле.
Для интерфейса используется Gradio, модель работает на сервере FastAPI, а системой очереди сообщений служит Firebase. Подробностями делимся к старту курса по ML и DL.
 Галерея Text2Art
Галерея Text2Art
Если вам понравился проект, вы можете проголосовать за него здесь.
Введение
Не так давно генеративные картины и NFT штурмом захватили мир. Это стало возможным после значительного прогресса OpenAI в генерации изображения из текста. Ранее в этом году OpenAI анонсировал DALL-E, мощный генератор изображений из текстов.
Чтобы проиллюстрировать, насколько хорошо работает DALL-E, посмотрите рисунки, сгенерированные DALL-E по запросу «a professional high quality illustration of a giraffe dragon chimera, «a giraffe imitating a dragon», «a giraffe made of dragon».
Изображения по запросу «a professional high quality illustration of a giraffe dragon chimera, «a giraffe imitating a dragon», «a giraffe made of dragon».
К сожалению, DALL-E не был выпущен в массы. Вместо него была опубликована модель, которая творит магию DALL-E, — CLIP. CLIP или Contrastive Image-Language Pretraining — это мультимодальная сеть, объединяющая текст и изображения.
Одним словом, CLIP способен оценить, насколько хорошо изображение соответствует надписи или наоборот.
Это крайне полезно в управлении генератором, чтобы создать изображение, точно соответствующее введённому тексту. В фильме «DALL-E» CLIP используется, чтобы ранжировать сгенерированные изображения и входные изображения с наивысшим баллом (самые похожие на тектовый запрос).
Через несколько месяцев после анонса фильма DALL-E был опубликован новый генератор изображений-трансформеров под названием VQGAN (Vector Quantized GAN). Сочетание VQGAN с CLIP даёт качество, аналогичное DALL-E. С момента обнародования предварительно обученной модели VQGAN сообщество создало множество удивительных картин.
Вот примеры:
Я был поражён результатами и захотел поделиться ими со своими друзьями. Но, поскольку не так много людей готовы погрузиться в код ради генерации картин, я решил сделать Text2Art.com — сайт, где любой может просто ввести подсказку и сгенерировать нужное изображение, не сталкиваясь с кодом воочию.
Как это работает
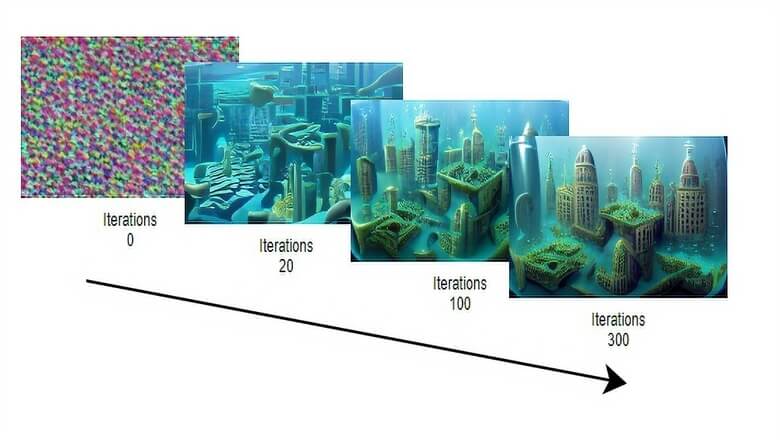
Итак, как работает VQGAN+CLIP? VQGAN генерирует изображение, а CLIP измеряет, насколько оно соответствует запросу. Затем генератор использует обратную связь от модели CLIP, чтобы сгенерировать более точные изображения. Процедура повторяется, пока оценка CLIP не станет достаточно высокой.
VQGAN генерирует изображения, пока CLIP направляет процесс. Чем больше итераций, тем точнее изображение [источник: иллюстрированный VQGAN от LJ Miranda]
Я не буду рассказывать о внутренней работе VQGAN или CLIP. Но, если вы хотите получить более глубокие объяснения VQGAN, CLIP или DALL-E, обратитесь к этим удивительным ресурсам, которые я нашёл:
X + CLIP
VQGAN+CLIP — это только пример того, на что способно объединение генератора изображений с CLIP. Однако вы можете заменить VQGAN на любой генератор. Появилось много вариантов X + CLIP, таких как StyleCLIP (StyleGAN + CLIP), CLIPDraw (векторный генератор), BigGAN + CLIP и многие другие, даже AudioCLIP, который работает со звуком, а не изображениями.
Редактирование изображений при помощи StyleCLIP [работа о StyleCLIP]
Код
Я воспользуюсь кодом из репозитория clipit от dribnet, этот код генерирует изображения при помощи VQGAN+CLIP в несколько простых строк (обновление: clipit мигрировал на pixray). Его рекомендуется запускать на Google Colab: VQGAN+CLIP требует много памяти GPU. Вот блокнот Colab.
Прежде всего, если вы работаете на Colab, убедитесь, что вы изменили тип рантайма на GPU, вот так:
Установим кодовую базу и зависимости:
from IPython.utils import io
with io.capture_output() as captured:
!git clone https://github.com/openai/CLIP
# !pip install taming-transformers
!git clone https://github.com/CompVis/taming-transformers.git
!rm -Rf clipit
!git clone https://github.com/mfrashad/clipit.git
!pip install ftfy regex tqdm omegaconf pytorch-lightning
!pip install kornia
!pip install imageio-ffmpeg
!pip install einops
!pip install torch-optimizer
!pip install easydict
!pip install braceexpand
!pip install git+https://github.com/pvigier/perlin-numpy
# ClipDraw deps
!pip install svgwrite
!pip install svgpathtools
!pip install cssutils
!pip install numba
!pip install torch-tools
!pip install visdom
!pip install gradio
!git clone https://github.com/BachiLi/diffvg
%cd diffvg
# !ls
!git submodule update --init --recursive
!python setup.py install
%cd ..
!mkdir -p steps
!mkdir -p models»!» — это специальная команда в Google Colab, которая означает, что команда будет запущена в bash, а не в python.
После установки библиотек мы можем просто импортировать clipit и запустить эти несколько строк кода для генерации картины с помощью VQGAN+CLIP.
Просто замените текстовую подсказку на любую другую. Кроме того, вы можете задать clipit такие параметры, как количество итераций, ширина, высота, модель генератора, хотите ли вы генерировать видео или нет, и многие другие. Чтобы больше узнать об опциях, вы можете посмотреть исходный код.
Вот код генерации:
import sys
sys.path.append("clipit")
import clipit
# To reset settings to default
clipit.reset_settings()
# You can use "|" to separate multiple prompts
prompts = "underwater city"
# You can trade off speed for quality: draft, normal, better, best
quality = "normal"
# Aspect ratio: widescreen, square
aspect = "widescreen"
# Add settings
clipit.add_settings(prompts=prompts, quality=quality, aspect=aspect)
# Apply these settings and run
settings = clipit.apply_settings()
clipit.do_init(settings)
cliptit.do_run(settings)Когда вы запустите код, он сгенерирует изображение. На каждой итерации сгенерированное изображение будет приближаться к тексту, который вы ввели.
Итерации по заросу «underwater city»
Количество итераций
Вот так можно установить количество итераций, им управляет iterations:
clipit.add_settings(iterations=500)Генерация видео
В любом случае нужно генерировать изображение для каждой итерации, поэтому можно сохранить эти изображения и создать анимацию самой генерации. Для этого добавьте make_video=True перед применением настроек.
clipit.add_settings(make_video=True)Получится этот ролик:
Сгенерированный подводный город, запрос «Underwater City»
Управление размером изображений
Размер изображения устанавливается опцией size=(width, height). Сенерируем баннерное изображение с разрешением 800×200. Обратите внимание, что более высокое разрешение требует большего объёма памяти GPU.
clipit.add_settings(size=(800, 200))Баннер 800×200 по запросу «Fantasy Kingdom #artstation»
Генерация пиксель-арта
Можно генерировать и пиксель-арт. Для этого используется рендерер CLIPDraw за сценой с некоторыми инженерными решениями, такими как ограничение цветов палитры, пикселизация и т.д. Просто включите опцию use_pixeldraw=True.
clipit.add_settings(use_pixeldraw=True)Изображение по запросу «Knight in armor #pixelart»Изображение по запросу «A world of chinese fantasy video game #pixelart»
VQGAN+CLIP модификатор ключевых слов
Из-за смещения в CLIP добавление определённых ключевых слов к подсказке может придать определённый эффект генерируемому изображению. Например, добавление слова «unreal engine» к текстовой подсказке, как правило, создаёт реалистичное изображение или HD стиль. Добавление определённых названий сайтов, таких как «deviantart», «artstation» или «flickr», обычно делает результаты более эстетичными. Мне больше всего нравится использовать ключевое слово «artstation», так как я считаю, что помогает создать лучшие картины.
 Сравнение ключевых слов
Сравнение ключевых слов
Кроме того, вы можете использовать ключевые слова, чтобы обусловить художественный стиль: «pencil sketch», «low poly» или даже имя художника — «Thomas Kinkade» или «James Gurney».
 Ключевые слова стиля — сравнение
Ключевые слова стиля — сравнение
Чтобы узнать больше о влиянии различных ключевых слов, вы можете ознакомиться с изображением, которое показывает более 200 слов на 4 темы.
UI на Gradio
Gradio — это библиотека Python, которая упрощает построение демонстраций ML до нескольких строк кода. Демоверсия требует меньше 10 минут работы. Кроме того, вы можете запустить Gradio в Colab, и он сгенерирует ссылку для совместного использования на домене Gradio. Ссылкой можно поделиться.
Gradio имеет некоторые ограничения, но я считаю, что это самая подходящая библиотека, когда вы просто хотите продемонстрировать одну функцию.
Ниже код простого пользовательского интерфейса для приложения Text2Art. Думаю, что он достаточно понятен, но, если вам нужно больше объяснений, смотрите документацию Gradio.
import gradio as gr
import torch
import clipit
# Define the main function
def generate(prompt, quality, style, aspect):
torch.cuda.empty_cache()
clipit.reset_settings()
use_pixeldraw = (style == 'pixel art')
use_clipdraw = (style == 'painting')
clipit.add_settings(prompts=prompt,
aspect=aspect,
quality=quality,
use_pixeldraw=use_pixeldraw,
use_clipdraw=use_clipdraw,
make_video=True)
settings = clipit.apply_settings()
clipit.do_init(settings)
clipit.do_run(settings)
return 'output.png', 'output.mp4'
# Create the UI
prompt = gr.inputs.Textbox(default="Underwater city", label="Text Prompt")
quality = gr.inputs.Radio(choices=['draft', 'normal', 'better'], label="Quality")
style = gr.inputs.Radio(choices=['image', 'painting','pixel art'], label="Type")
aspect = gr.inputs.Radio(choices=['square', 'widescreen','portrait'], label="Size")
# Launch the demo
iface = gr.Interface(generate, inputs=[prompt, quality, style, aspect], outputs=['image', 'video'], enable_queue=True, live=False)
iface.launch(debug=True)Как только вы запустите эту программу в Google Colab или локально, она создаст ссылку, которой можно поделиться, демонстрация будет общедоступной. Не нужно использовать туннелирование SSH вроде ngrok. Кроме того, Gradio также предлагает хостинг за 7 долларов в месяц.
Ссылка в демо, которой можно поделиться.
Однако Gradio хорошо подходит только для демонстрации одной функции. Создание кастомного сайта с дополнительными функциями, такими как галерея, вход в систему или даже просто пользовательский CSS, довольно ограничено или вообще невозможно.
Одно быстрое решение — создать демонстрационный сайт отдельно от пользовательского интерфейса Gradio, затем — встроить интерфейс Gradio через iframe.
Я попробовал этот метод, но осознал один важный недостаток: я не могу персонализировать части, которые должны взаимодействовать с самим приложением ML: валидацию ввода, пользовательский прогресс-бар и т. д., невозможны с iframe. И я решил создать API.
FastAPI для модели
Чтобы сделать API быстрее, вместо Flask я воспользовался FastAPI. Кода меньше, а ещё он автоматически генерирует документацию со Swagger UI, что позволяет тестировать API с помощью простого пользовательского интерфейса.
Кроме того, FastAPI поддерживает асинхронные функции и, как утверждается, он быстрее, чем Flask.
Добавляем /docs/ в URL, чтобы увидеть SwaggerТестируем API в UI Swagger
Вот код, который я написал для выполнения функции ML на сервере FastAPI:
import clipit
import torch
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from fastapi import FastAPI, File, UploadFile, Form, BackgroundTasks
from fastapi.responses import FileResponse
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
@app.get('/')
async def root():
return {'hello': 'world'}
@app.post("/generate")
async def generate(
seed: int = Form(None),
iterations: int = Form(None),
prompts: str = Form("Underwater City"),
quality: str = Form("draft"),
aspect: str = Form("square"),
scale: float = Form(2.5),
style: str = Form('image'),
make_video: bool = Form(False),
):
torch.cuda.empty_cache()
clipit.reset_settings()
use_pixeldraw = (style == 'Pixel Art')
use_clipdraw = (style == 'Painting')
clipit.add_settings(prompts=prompts,
seed=seed,
iterations=iterations,
aspect=aspect,
quality=quality,
scale=scale,
use_pixeldraw=use_pixeldraw,
use_clipdraw=use_clipdraw,
make_video=make_video)
settings = clipit.apply_settings()
clipit.do_init(settings)
clipit.do_run(settings)
return FileResponse('output.png', media_type="image/png")После определения сервера мы можем запустить его с помощью uvicorn. Кроме того, поскольку Google Colab предоставляет доступ к своему серверу только через интерфейс Colab, мы должны использовать Ngrok, чтобы сделать сервер FastAPI публичным.
Код для запуска и демонстрации сервера:
import nest_asyncio
from pyngrok import ngrok
import uvicorn
ngrok_tunnel = ngrok.connect(8000)
print('Public URL:', ngrok_tunnel.public_url)
print('Doc URL:', ngrok_tunnel.public_url+'/docs')
nest_asyncio.apply()
uvicorn.run(app, port=8000)Запустив сервер, мы можем перейти к Swagger UI (добавив /docs в сгенерированный ngrok URL) и протестировать API.
Генерация подводного замка при помощи FastAPI Swagger UI
При тестировании API я понял, что вывод может занять от 3 до 20 минут в зависимости от качества/итераций. Три минуты само по себе уже считается очень долгим для HTTP-запроса, и пользователи могут не захотеть ждать так долго.
Я решил, что установка вывода в качестве фоновой задачи и отправка пользователю электронного письма после получения результата лучше подходят для этой задачи.
Теперь, когда мы определились с планом, напишем функцию для отправки письма. Сначала я использовал почтовый API SendGrid, но после исчерпания квоты бесплатного использования (100 писем в день) перешёл на API Mailgun, который входит в пакет GitHub Student Developer Pack, разрешая студентам отправлять 20 000 писем в месяц.
Вот код для отправки электронного письма с вложением изображения с помощью API Mailgun:
import requests
def email_results_mailgun(email, prompt):
return requests.post("https://api.mailgun.net/v3/text2art.com/messages",
auth=("api", "YOUR_MAILGUN_API_KEY"),
files=[("attachment",("output.png", open("output.png", "rb").read() )),
("attachment", ("output.mp4", open("output.mp4", "rb").read() ))],
data={"from": "Text2Art ",
"to": email,
"subject": "Your Artwork is ready!",
"text": f'Your generated arts using the prompt "{prompt}".',
"html": f'Your generated arts using the prompt "{prompt}".'}) Далее мы изменим код нашего сервера, чтобы использовать фоновые задачи в FastAPI и отправить результат по электронной почте в фоновом режиме.
Код сервера
#@title API Functions
import clipit
import torch
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from fastapi import FastAPI, File, UploadFile, Form, BackgroundTasks
from fastapi.responses import FileResponse
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
# define function to be run as background tasks
def generate(email, settings):
clipit.do_init(settings)
clipit.do_run(settings)
prompt = " | ".join(settings.prompts)
email_results_mailgun(email, prompt)
@app.get('/')
async def root():
return {'hello': 'world'}
@app.post("/generate")
async def add_task(
email: str,
background_tasks: BackgroundTasks,
seed: int = Form(None),
iterations: int = Form(None),
prompts: str = Form("Underwater City"),
quality: str = Form("draft"),
aspect: str = Form("square"),
scale: float = Form(2.5),
style: str = Form('image'),
make_video: bool = Form(False),
):
torch.cuda.empty_cache()
clipit.reset_settings()
use_pixeldraw = (style == 'Pixel Art')
use_clipdraw = (style == 'Painting')
clipit.add_settings(prompts=prompts,
seed=seed,
iterations=iterations,
aspect=aspect,
quality=quality,
scale=scale,
use_pixeldraw=use_pixeldraw,
use_clipdraw=use_clipdraw,
make_video=make_video)
settings = clipit.apply_settings()
# Run function as background task
background_tasks.add_task(generate, email, settings)
return {"message": "Task is processed in the background"}
С помощью приведённого выше кода сервер быстро ответит на запрос сообщением «Task is processed in the background» вместо того, чтобы ждать завершения генерации и ответа с изображением. Когда генерация завершится, сервер по электронной почте отправит пользователю результат.
Изображение и видеозапись отправляются пользователю по электронной почте
Теперь, когда всё вроде бы заработало, я создал фронтенд и поделился сайтом со своими друзьями. Однако при тестировании с несколькими пользователями я обнаружил, что есть проблема параллелизма.
Когда второй пользователь делает запрос на сервер, в то время как первая задача всё ещё обрабатывается, вторая задача каким-то образом завершает текущий процесс, вместо того чтобы создать параллельный процесс или очередь.
Не было уверенности, что вызвало проблему, возможно, это было использование глобальных переменных в коде clipit, а возможно, нет. Я быстро понял, что мне нужно реализовать систему очереди сообщений.
По результатам поисков в Google большинство рекомендует RabbitMQ или Redis. Однако я не был уверен, можно ли установить RabbitMQ или Redis на Google Colab: для этого, похоже, требуется разрешение sudo.
В конце концов, я решил использовать Google Firebase, потому что хотел закончить проект как можно скорее, а с Firebase я знаком лучше всего.
В основном, когда пользователь пытается сгенерировать рисунок во фронтенде, он добавляет запись в queue, которая описывает задачу (введённый текст, тип изображения, размер и т. д.).
С другой стороны, мы запустим сценарий на Google Colab, который будет постоянно прослушивать новую запись в очереди и обрабатывать задания одно за другим.
Код бэкенда, который обрабатывает задание и постоянно прослушивает очередь
import torch
import clipit
import time
from datetime import datetime
import firebase_admin
from firebase_admin import credentials, firestore, storage
if not firebase_admin._apps:
cred = credentials.Certificate("YOUR_CREDENTIAL_FILE")
firebase_admin.initialize_app(cred, {
'storageBucket': 'YOUR_BUCKET_URL'
})
db = firestore.client()
bucket = storage.bucket()
def generate(doc_id, prompt, quality, style, aspect, email):
torch.cuda.empty_cache()
clipit.reset_settings()
use_pixeldraw = (style == 'pixel art')
use_clipdraw = (style == 'painting')
clipit.add_settings(prompts=prompt,
seed=seed,
aspect=aspect,
quality=quality,
use_pixeldraw=use_pixeldraw,
use_clipdraw=use_clipdraw,
make_video=True)
settings = clipit.apply_settings()
clipit.do_init(settings)
clipit.do_run(settings)
data = {
"seed": seed,
"prompt": prompt,
"quality": quality,
"aspect": aspect,
"type": style,
"user": email,
"created_at": datetime.now()
}
db.collection('generated_images').document(doc_id).set(data)
email_results_mailgun(email, prompt)
transaction = db.transaction()
@firestore.transactional
def claim_task(transaction, queue_objects_ref):
# query firestore
queue_objects = queue_objects_ref.stream(transaction=transaction)
# pull the document from the iterable
next_item = None
for doc in queue_objects:
next_item = doc
# if queue is empty return status code of 2
if not next_item:
return {"status": 2}
# get information from the document
next_item_data = next_item.to_dict()
next_item_data["status"] = 0
next_item_data['id'] = next_item.id
# delete the document and return the information
transaction.delete(next_item.reference)
return next_item_data
# initialize query
queue_objects_ref = (
db.collection("queue")
.order_by("created_at", direction="ASCENDING")
.limit(1)
)
transaction_attempts = 0
while True:
try:
# apply transaction
next_item_data = claim_task(transaction, queue_objects_ref)
if next_item_data['status'] == 0:
generate(next_item_data['id'],
next_item_data['prompt'],
next_item_data['quality'],
next_item_data['type'],
next_item_data['aspect'],
next_item_data['email'])
print(f"Generated {next_item_data['prompt']} for {next_item_data['email']}")
except Exception as e:
print(f"Could not apply transaction. Error: {e}")
time.sleep(5)
transaction_attempts += 1
if transaction_attempts > 20:
db.collection("errors").add({
"exception": f"Could not apply transaction. Error: {e}",
"time": str(datetime.now())
})
exit()На фронте нужно только добавить новую задачу в очередь. Убедитесь, что правильно настроили Firebase на фронтенде:
db.collection("queue").add({
prompt: prompt,
email: email,
quality: quality,
type: type,
aspect: aspect,
created_at: firebase.firestore.FieldValue.serverTimestamp(),
})
Мы сделали это! Теперь, когда пользователь попытается создать рисунок на фронтенде, он добавит новую задачу в очередь. Затем рабочий скрипт на сервере Colab обработает задания в очереди, одно за другим. Вы можете заглянуть в репозиторий GitHub, чтобы увидеть весь код.
Лучше понять нейросети и научиться решать проблемы бизнеса с их помощью вы сможете на наших курсах:
Также вы можете перейти на страницы из католога, чтобы увидеть, как мы готовим специалистов в других направлениях.
Ссылки статьи
[1] DALL-E
[2] CLIP
[3] CLIP-VQGAN
[4] StyleCLIP
[5] Flask против FastAPI
Профессии и курсы
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:
