[Перевод] Как мы писали код Netflix

Как именно в Netflix реализован код до этапа работы в облаке? Части этой истории мы рассказывали и прежде, но сейчас настало время добавить в неё больше деталей. В данном посте мы опишем инструменты и методы, позволившие нам пройти путь от исходного кода до развёрнутого сервиса, который позволяет наслаждаться фильмами и сериалами более чем 75 миллионам подписчиков со всего мира.

Схема выше — отсылка к предыдущему посту, представляющему Spinnaker, нашу глобальную непрерывную платформу передачи данных. Но до попадания в Spinnaker строке кода нужно пройти несколько этапов:
- Код должен быть написан и локально испытан плагинами Nebula;
- Изменения перемещаются в центральное хранилище git;
- Jenkins запускает Nebula, которая создаёт, тестирует и подготавливает приложения для облака;
- Билды «выпекаются» в Amazon Machine Image;
- Spinnaker способствует разблокировке и активизации измененного кода.
В остальной части этого поста мы опишем инструменты и методы, использованные на каждом из этих этапов и поговорим об испытаниях, которые повстречались на нашем пути.
Организационная культура, облако и микросервисы
Прежде чем углубиться в описание процесса создания кода Netflix, необходимо обозначить ключевые факторы, которые влияют на принимаемые решения: наша организационная культура, облако и микросервисы.
Культура Netflix расширяет возможности инженеров в плане использования любого, по их мнению, подходящего инструментария ради решения поставленных задач. По нашему опыту, для того, чтобы какое-либо решение получило всеобщее признание, оно должно быть аргументированным, полезным и уменьшать когнитивную нагрузку на большинство инженеров Netflix. Команды свободны в выборе пути решения задач, но за это расплачиваются дополнительной ответственностью поддержкой этих решений. Предложения центральных команд Netflix начинают считаться частью «проторенной дорожки» (paved road). Сейчас именно она находится в центре нашего внимания и поддерживается нашими специалистами.
Кроме того, в 2008 году Netflix начала переносить потоковую передачу данных на AWS и переводить монолитную ЦОД на основе Java-приложений на облачные Java-микросервисы. Их архитектура позволяет командам Netflix не быть сильно связанными друг с другом, что позволяет создавать и продвигать решения задач в комфортном для них темпе.
Разработка
Думаю, никого не удивит то, что перед развёртыванием сервиса, либо приложения, его сначала нужно разработать. Мы создали Nebula — набор плагинов build system для Gradle, чтобы справиться с основными сложностями в ходе разработки. Gradle является первоклассным инструментом для разработки, тестирования и подготовки Java-приложений к развёртыванию, потому что охватывает основные потребности нашего кода. Он был выбран потому как на нём было легко писать поддающиеся тестированию плагины, уменьшая при этом итоговый файл. Таким образом, Nebula, при помощи Gradle с его набором доступных плагинов для управления взаимосвязями, выпуском, развёртыванием и многими другими инструментами, обеспечивает надёжный автоматизированный функционал.
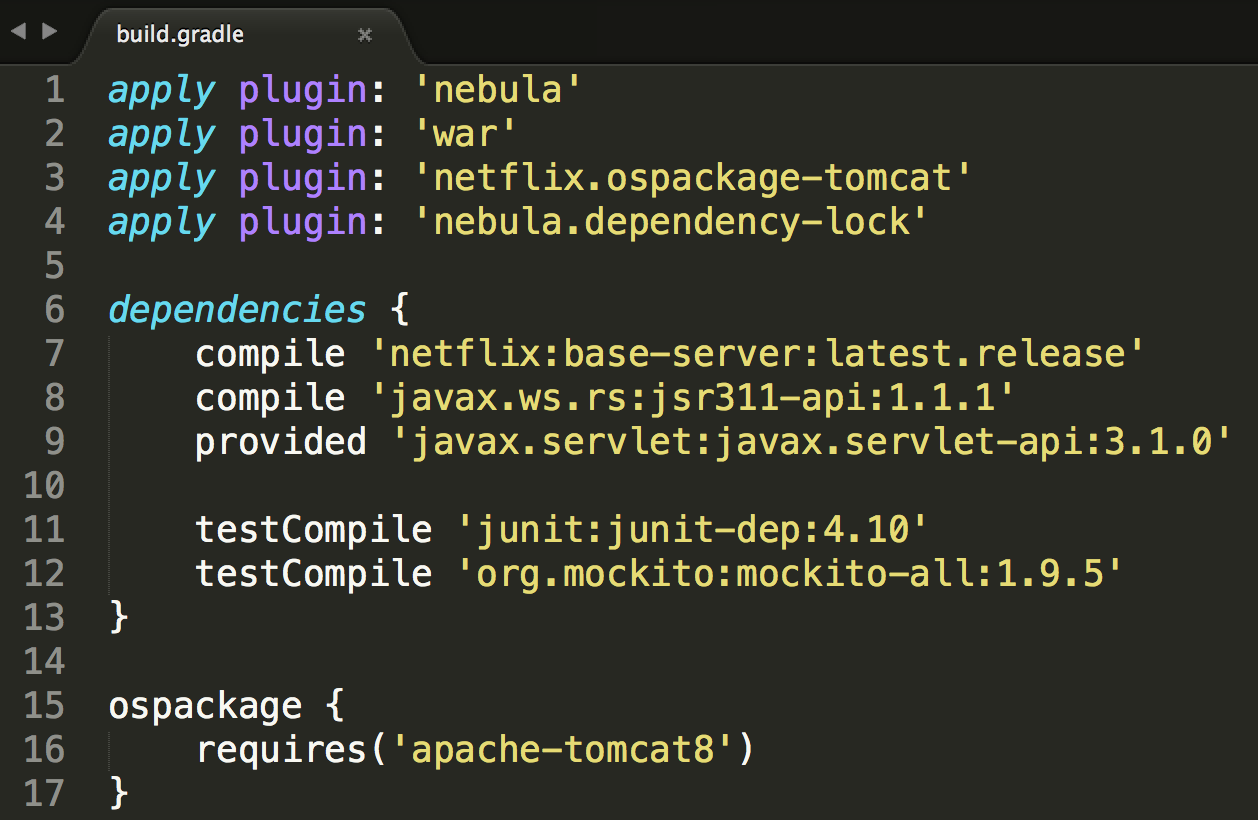
Простое приложение на Java. Файл build.gradle
Представленный выше файл build.gradle является примером сборки обычного Java-приложения в Netflix. В теле этого проекта мы видим команды Java и четыре плагина Gradle, три из которых являются или частью Nebula, или же внутренними настройками, связанными с ее плагинами. Плагин «nebula» — часть Gradle, обеспечивающая связи и настройки, необходимые для интеграции с нашей инфраструктурой. Плагин «nebula.dependency-lock» позволяет проекту создавать файл a.lock, который строит вариативные зависимости с возможностью повторения. Плагин «netflix.ospackage-tomcat» и блок ospackage будут рассмотрены ниже.
При помощи Nebula мы пытаемся обеспечить многократно используемую и совместимую функциональность сборки, преследуя задачу уменьшить шаблонные обороты в каждом файле приложения. В следующем посте мы подробнее обсудим Nebula и её различные функции, код к которым открыт. А пока вы можете зайти на web-сайт Nebula.
Интеграция
После локального испытания кода при помощи Nebula мы можем перейти к интеграции и развёртыванию. Для начала мы должны запустить обновлённый исходный код в хранилище Git, так как при необходимости команды могут свободно найти его рабочий процесс.
После подтверждения изменения срабатывает функция Jenkins. Наше использование Jenkins для непрерывной интеграции развивалось годами. В нашем ЦОД мы начали всего с одного массивного master Jenkins, но это вылилось в использование 25 masters Jenkins в AWS. В Netflix он используется для большого количества автоматизированных задач, которые сложнее простых непрерывных интеграций.
Задача Jenkins — вызвать Nebula для создания, тестирования и подготовки к развёртыванию кода приложения. Если репозиторий становится библиотекой, Nebula опубликует *.jar в нашем репозитории. Если репозиторий является приложением, то Nebula запустит плагин ospackage. Плагин ospackage («operating system package») представит созданный артефакт приложения в виде Debian или RPM пакете, содержание которого определяется при помощи простого DSL, основанного на Gradle. Затем Nebula опубликует Debian-файл в репозиторий пакетов, где он станет доступным для следующего этапа: «выпечки».
«Выпечка»
Примечание: Под «выпечкой» и «пекарней» подразумевается аналогия с процессом выпечки в реальной жизни: рецепт, последовательность, соблюдение необходимых условий. Автору оригинала очень нравится данный оборот и он будет использовать его в дальнейшем достаточно часто. К сожалению, русскоязычного аналога по вкладываемому в эти слова смыслу я не нашел.
Наша стратегия развертывания сосредоточена вокруг неизменности паттерна сервера. Для снижения вероятности дрейфа конфигурации и для уверенности в том, что повторения развертываний происходят из одного источника, файлы крайне не рекомендуется модифицировать вручную. Каждое развертывание на Netflix начинается с создания нового AMI (Amazon Machine Image). Для формирования файлов AMI прямо из источника мы создали «Пекарню»
«Пекарня» создаёт API, что невероятно облегчает создание AMI. Затем API службы Пекарни по расписанию «готовят» задания для рабочих узлов, которые используют Animator для создания изображений. Для вызова функции «выпекания» пользователь должен объявить установку нужного пакета и базовое изображение, на которое этот пакет и будет установлен. Оно то (базовое AMI) и обеспечивает работу настроенной с общими конвекциями, услугами и инструментами среду Linux, необходимой для полной интеграции с более крупной частью экосистемы Netflix.
Когда Jenkins успешно выполнил свою часть работы, он, как правило, вызывает «Spinnaker pipeline». Они могут быть вызваны действиями «Jenkins» или фиксацией Git. «Spinnaker» прочтёт пакет операционной системы, сгенерированные «Nebula», и обратится к API «Пекарни», чтобы начать работу.
Применение
После завершения «выпекания» Spinnaker способен развернуть полученный в итоге AMI до десятков, сотен и даже тысяч экземпляров. Тот же самый AMI можно использовать в нескольких средах пока в это же время Spinnaker выявляет среду выполнения для конкретного экземпляра, что позволяет приложениям самостоятельно настраивать время своего выполнения. Успешное «выпекание» запустит следующий этап работы «Spinnaker pipeline» — резвертывание в тестовой среде.
Тут команды начинают деплой, используя при этом целую «батарею» автоматизированных тестов интеграции. С этого момента специфика «pipeline» делает процесс развёртки зависимым от людей с возможностью тонкой настройки. Команды используют «Spinnaker» для управления несколькими областями развертываний, красными / черными внедрениями и многим другим. Достаточно будет сказать о том, что «Spinnaker pipelines» обеспечивают команды гибким инструментарием для контроля развёртки кода.
Предстоящий путь
В целом эти инструменты дают высокий уровень производительности и автоматизации. Например, потребуется всего 16 минут для того, чтобы «Janitor Monkey», наш облачный сервис устойчивости и технического обслуживания, прошел путь от окна регистрации до мульти-региональной развертки.
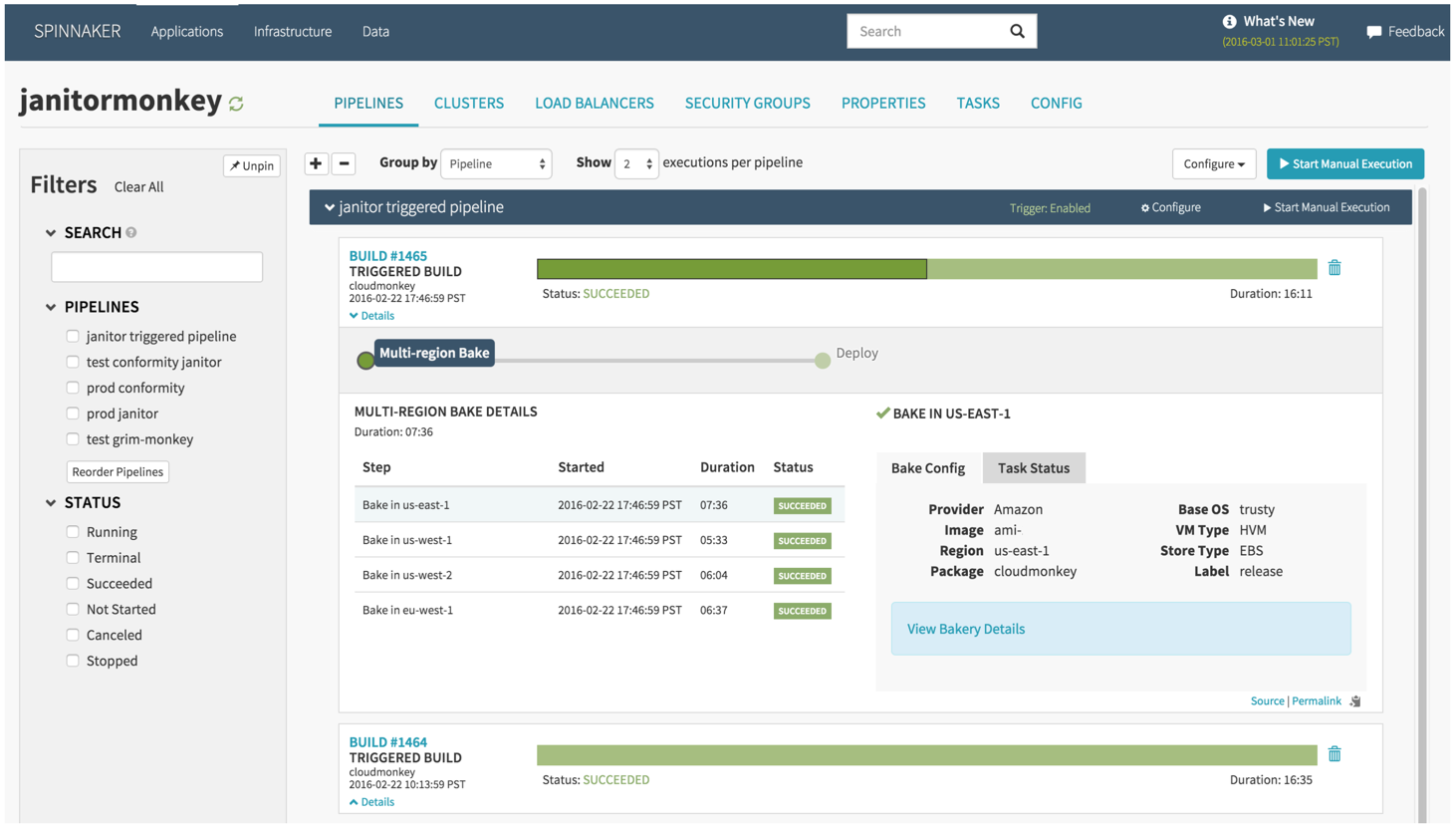
Spinnaker «выпекает» и развёртывает pipeline, вызванную Jenkins.
Это говорит о том, что мы всегда ищем способы повысить опытность разработчиков и постоянно бросаем сами себе вызовы — делать лучше, быстрее и проще.
Нас часто спрашивают, как мы справляемся с бинарными зависимостями в Netflix. Nebula предоставляет нам инструменты, ориентированные на облегчение зависимостей Java. Для примера возьмём плагин dependency-lock, который помогает приложениям просчитывать всю их графику бинарных зависимостей и создает вариативный файл a.lock. Плагин «resolution rules» для Nebula позволяет создавать правила зависимостей для всего проекта, которые влияют на все его части. Эти инструменты помогают сделать управление двоичными зависимостями проще, но все равно не позволяют снизить показатели до приемлемого уровня.
Также мы работаем над снижением времени «выпекания». Не так давно 16 минут на развертывание казались мечтой, но с повышением быстродействия других частей системы эта мечта превратилась в потенциальное препятствие. Для примера возьмем развёртывание Simian Army: процесс «выпечки» занял 7 минут, что составляет 44% от всего процесса «выпекания» и развертывания. Мы обнаружили, что ведущими (по времени) в процессе выпечки являлись установка пакетов (включая разрешение зависимостей) и сам процесс копирования AWS.
По мере роста и развития Netflix повышается спрос на его сборку и инструментарий развертки, так как нужно обеспечивать первоклассную поддержку JavaScript/Node.js, Python, Ruby и Go без виртуальной машины. Сейчас для данных языков мы можем порекомендовать плагин Nebula ospackage, который позволяет получить Debian-пакет для последующей «выпечки», оставляя сборку и тестирование инженерам и инструментарию используемой платформы. Пока это решение подходит для нас, но мы пытаемся расширять наш инструментарий для снижения зависимости от конкретных языков.
Контейнеры представляют собой интересную возможность решения двух последних задач. Сейчас мы исследуем, каким образом контейнеры могут помочь улучшить наши процессы сборки, «выпекания» и развёртывания. Если мы сможем создать локальную контейнерную среду, которая в точности имитирует наши облачные среды, потенциально мы смогли бы уменьшить время «выпекания», необходимое для циклов разработки и тестирования, тем самым повысив производительность труда разработчиков и ускорив процесс развития продукта в целом. Контейнер, который можно было бы развернуть локально «из коробки», снижает когнитивную нагрузку и позволяет нашим инженерам сфокусироваться на решении поставленных задач и инновациях, вместо того, чтобы проверять, не появилась ли какая-нибудь ошибка из-за различия сред.
