[Перевод] Как мы автоматизируем тестирование с помощью управления выпусками — Часть 1
В ноябре 2015 г. мы открыли доступ к версии службы Release Management для публичного тестирования в Visual Studio Team Services. Материалы этого блога помогут Вам быстро начать использовать весь комплекс возможностей RM. Документация MSDN, доступная здесь, позволит Вам глубоко разобраться в сценариях и концепциях RM.
Вы можете использовать службу RM в двух сценариях: для внедрения кода на нескольких используемых средах и для выполнения тестов при разработке продукта. В этой публикации я расскажу о втором сценарии, а именно о том, как мы (группа разработчиков службы RM корпорации Microsoft) автоматизируем тестирование с помощью RM. Уже в течение семи месяцев мы используем RM для тестирования, за что я благодарю мою коллегу Лову (Lova).
Я разделил эту статью на две части. Первая часть представляет собой общее описание нашего опыта процесса комплексной автоматизации тестирования. Во второй части речь пойдет о некоторых проектных решениях, проблемах, с которыми мы столкнулись в процессе автоматизации тестирования, и способах решения этих проблем.
Обзор и общее описание
VSTS состоит из нескольких единиц масштабирования (scale units, SU), обеспечивающих такие службы, как управление версиями, сборка, управление выпусками, отслеживание рабочих элементов и др. Все группы, участвующие в разработке и применяющие инструменты VSTS, используют SU0 в своей повседневной работе. Таким образом, SU0 является «рабочим вариантом». Как правило, группы сначала развертывают новый код в SU0 и передают его в другие единицы масштабирования лишь после того, как поэкспериментируют с ним в течение некоторого времени.
Аналогичным образом группа RM использует службы SU0 в своей повседневной работе. Мы ведем разработку (дополняем код и вносим исправления) в функциональной ветви TF Git под названием features/rmmaster, собираем код с помощью службы Build и тестируем его с помощью службы RM.
Общее предназначение нашей технической системы — одновременное тестирование каждой проверки на множестве конфигураций для того, чтобы как можно раньше обнаруживать регрессии в цикле разработки. На текущий момент существует три этапа отладки разрабатываемого кода:
- Этап предварительной проверки или запросы на включение внесенных изменений: На этом этапе мы выполняем главным образом модульные и некоторые комплексные тесты для того, чтобы гарантировать корректность работы базовых функций в ветви features/rmmaster.
- Обратите внимание на то, что этот этап не выполняется, если в ветви git разрешены проверки.
- Этап непрерывной интеграции (Continuous Integration, CI): На этом этапе CI-сборка запускается в работу непосредственно после проверки. Для этой сборки мы еще раз выполняем модульные тесты и убеждаемся, что параллельно проводимые проверки не привели к ошибкам, а затем публикуем артефакты, которые использовались группой RM при автоматизации тестирования.
- Этап автоматизации тестирования: Он начинается в момент окончания сборки и включает в себя набор параллельно запускаемых определений выпуска (Release Definitions, RD). Каждое определение выпуска тестирует определённый сценарий; определения выпуска в совокупности охватывают весь продукт. Этому этапу в настоящей публикации я уделю больше всего внимания.
Настройка «непрерывного конвейера автоматизации»
Имя нашей CI-сборки непрерывной интеграции — VSO.RM.CI. Сборка публикует единственный артефакт под названием «drop», который содержит в себе все двоичные файлы, созданные в результате ее выполнения.
Мы связываем это определение сборки с набором определений выпуска с помощью свойства триггера определения выпуска. Другими словами, каждое определение выпуска, выделенное ниже, активизируется автоматически по окончании сборки VSO.RM.CI.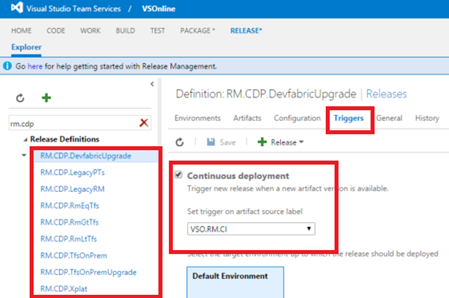
(Обратите внимание на то, что каждое определение выпуска имеет единственную среду. Мы были вынуждены использовать девять определений выпуска, поскольку RM не поддерживает параллельное выполнение сред. Такая функция появится в ближайшее время. Когда это произойдёт, мы объединим девять определений выпуска в одно определение выпуска с девятью параллельно выполняющимися средами, что улучшит отслеживаемость сборок).
Общая идея заключается в том, что каждое определение выпуска загружает двоичные файлы, необходимые для его тестирования, настраивает тестовую среду, удаляя старые и развертывая новые двоичные файлы (зависимые службы и тестовые библиотеки DLL), выполняет тесты с помощью задачи VsTest (которая также публикует результаты, что упрощает подготовку отчетов и последующий анализ) и еще раз очищает среду. Позже я подробнее рассмотрю устройство определения выпуска в этом блоге.
Процесс обработки кода и публикации теста схематически выглядит следующим образом: 
Настройка пула агентов
Для того чтобы приступить к выполнению задач, необходимо сначала настроить агент сборки/выпуска для нашей CI-сборки непрерывной интеграции и определений выпуска. Обычно на одних серверах сначала запускаются задачи в пуле агента сборки/выпуска для развертывания служб RM/SPS/TFS, а на других серверах выполняются тесты для этих задач. В данном случае мы решили развернуть службы на агентском компьютере, чтобы одновременно использовать несколько экземпляров одного теста.
Каждый тест имел свои собственные требования, что не позволяло использовать размещаемый пул агентов. По этой причине мы создали единственный пул агентов с названием RMAgentPool. Мы подготовили отдельные компьютеры для каждого определения выпуска RM.CDP.*, установили агент сборки/выпуска на каждый из них и добавили эти компьютеры в пул RMAgentPool.
(Для этого мы скачали агента на каждый тестовый компьютер с помощью ссылки «Download agent» («Скачать агент»), выделенной на приведенном ниже рисунке). Мы распаковали zip-файл агента и настроили его, указав нашу учетную запись в параметре «URL for Team Foundation Server» («URL-адрес для Team Foundation Server»), например: https://OurAccount.visualstudio.com).
Каждому компьютеру была предоставлена новая возможность пользователя с названием «RmCdpCapability». Значение этого параметра определяло предназначение компьютера: например, на компьютерах, подготовленных для сборок непрерывной интеграции, использовался параметр RmCdpCapability=CI.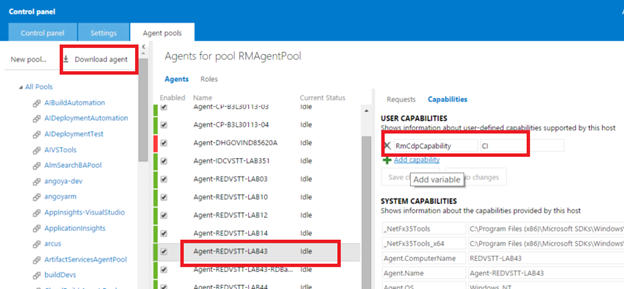
Еще один пример: Для агента, на котором выполнялось определение выпуска RM.CDP.TfsOnPrem, использовался параметр «RmCdpCapability=TfsOnPrem».

Затем определения выпуска использовали параметр RmCdpCapability как требование для того, чтобы тесты выполнялись на подходящих агентах.
Обзор определений выпуска RM.CDP.*
Примечание о терминологии: RM на основе веб-клиента также называется Team Web Access (TWA)
- Служба RM TWA в VSTS называется RM Online (или RMO)
- Служба RM TWA в локальной системе управления версиями TFS называется RM on-prem (эта служба еще не выпущена, но мы делаем все возможное, чтобы выпуск состоялся как можно раньше)
Обратите внимание на то, что VSTS — это набор из нескольких микрослужб, которые разработаны с помощью единой модели Sprint (все группы работают в одном и том же трехнедельном цикле), но каждая группа развернута независимо друг от друга. RM является одной из таких микрослужб и зависит от других микрослужб, в том числе SPS и TFS.
Краткое описание тестов, которые мы выполняем для RM TWA:
- Тесты для RMO:
- RM.CDP.RmEqTfs: Выполняет комплексные тесты (e2e) на основе API для RMO, когда версии выпуска спринта RM и зависимых служб (SPS, TFS) совпадают. Например, RM, SPS и FTS находятся в спринте S92.
- RM.CDP.RmGtTfs: Выполняет комплексные тесты (e2e) для версии выпуска RMO, когда в единице масштабирования версия выпуска RM опережает зависимые службы (SPS, TFS). Например, RM находится в S92, а SPS/TFS — в S91.
- RM.CDP.RmLtTfs: Выполняет комплексные тесты (e2e) для версии выпуска RMO, когда в единице масштабирования версия выпуска RM отстает от зависимых служб (SPS, TFS). Например, RM находится в S91, а SPS/TFS — в S92.
Приведенная выше матрица тестов позволяет развертывать RMO в единицах масштабирования независимо от того, развернуты ли зависимые службы SPS/TFS (при отсутствии у этих служб зависимости от новой функции; в этом случае набор тестов RmGtTfs завершится неудачно, по крайней мере, мы надеемся на это). - Тесты RM on-prem:
- RM.CDP.TfsOnPrem: выполняет тесты RM on-prem на основе как API, так и пользовательского интерфейса.
- Тесты обновлений
- RM.CDP.DevFabricUpgrade: тестирует сценарий обновления RMO (например, с S91 до S92).
- RM.CDP.OnPremUpgrade: тестирует сценарий обновления RM on-prem.
- Тест x-plat RM, т.е. агент RM выполняется на Linux / iOS:
- RM.CDP.XPlat
Разработка определения выпуска RM.CDP.*
Я подробнее рассмотрю определение выпуска RM.CDP.TfsOnPrem, поскольку оно создает канонический шаблон, используемый другими определениями выпуска.
- Определение выпуска настраивается так, чтобы оно выполнялось на подходящем агенте, как показано на приведенном ниже снимке экрана: RM.CDP.TfsOnPrem –> Edit –> Environment –>… –> Agent Options –> вкладка Options.
- Затем определение выпуска пропускает скачивание артефакта (Skips Artifact Download):

Скачивание артефакта пропускается потому, что наша CI-сборка непрерывной интеграции публикует единственный большой артефакт с названием «drop» размером в несколько ГБ, в то время как всем тестам необходимы различные подмножества файлов.
(на текущий момент RM не позволяет с легкостью скачивать подмножество артефактов, публикуемых сборкой. Как только такая возможность появится, мы сделаем две вещи: (1) вместо одного большого артефакта «drop» начнем публиковать в сборке непрерывной интеграции менее крупные артефакты «TfsDrop», «RmDrop», «SpsDrop» и т. п.; (2) будем скачивать те артефакты, которые необходимы определению выпуска RM.CDP.*). - Каждое из определений выпуска скачивает набор стандартных файлов (в том числе программу vssbinfetch.exe, которая умеет скачивать конкретные фрагменты сборки), выполняя файл downloadArtifacts.ps1, доступный на файловом ресурсе \\). Затем определение выпуска скачивает требуемые двоичные файлы из сборки для своего тестового сценария с помощью созданной нами задачи «vssbinfetch», вызывающей программу vssbinfetch.exe. Например, RM.CDP.RmEqTfs скачивает двоичные файлы для служб SPS, TFS и RMO, а RM.CDP.TfsOnPrem — для TFS on-prem. Эти две задачи выделены ниже. Определение выпуска попутно очищает компьютер и удаляет старые двоичные файлы.
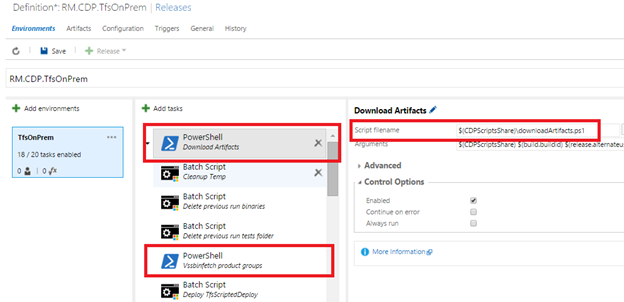
- Затем определение выпуска развертывает необходимые службы и тестовые библиотеки dll на компьютере. Например, «tfat» — это внутренний инструмент, который устанавливает на компьютере службу TFS on-prem.

- В конце определение выпуска настраивает файл тестовой среды и вызывает задачу Visual Studio Test (или задачу VsTest, которой мы предпочитаем пользоваться :)). Это приводит к публикации результатов теста под названием «TfsOnPrem».
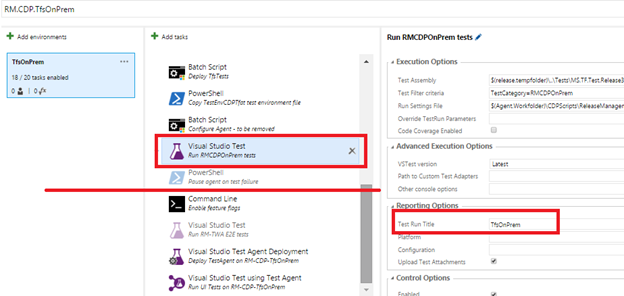
- Как правило, определение выпуска завершается после выполнения задачи «Pause agent on test failure» («Приостановить агент при неудачном тестировании») и очистки, если она требуется. Как правило, задача «Pause» отключена, и я подробнее расскажу об этом в следующей публикации блога.
Анализ результатов тестирования
По мере внесения изменений разработчиками, мы можем легко определить, чьи изменения стали причиной сбоев. Например, на представленном ниже снимке экрана тестирование стало завершаться неудачно после сборки VSO.RM.CI_rmmaster_20151231.5. Дважды щелкнув по выделенному выпуску, мы открываем страницу Release Summary (Сводка выпуска): 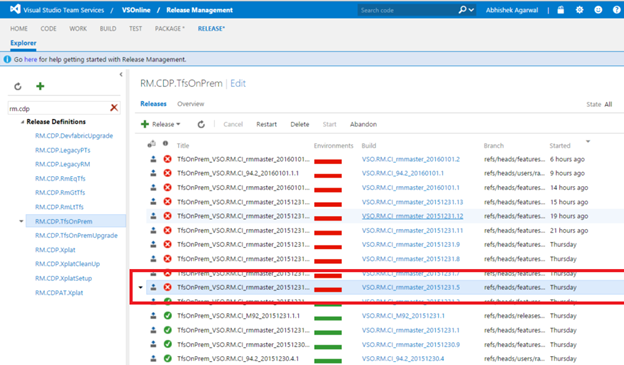
Затем мы переходим в раздел Test Results (Результаты тестирования) страницы Release Summary (Сводка выпуска) и видим, что после этой проверки два теста пользовательского интерфейса стали завершаться неудачно. Щелкнув по выделенной ниже ссылке на тест, мы попадаем в раздел Test (Тест): 
Вложенная вкладка Test Results (Результаты теста) дает нам ценную исходную информацию для подробного анализа проблем: 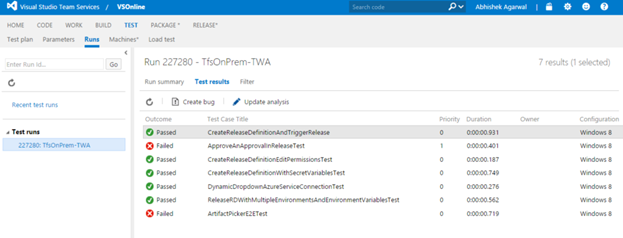
Журналы тестов доступны во вложенной вкладке Run summary (Сводка выполнения).
Мы можем получить более подробную информацию о фиксациях этого выпуска, чтобы определить их возможную связь с регрессом, с помощью вкладки Commits (Фиксации) страницы Release Summary (Сводка выпуска). Например, приведенный ниже снимок экрана показывает, что некоторые изменения пользовательского интерфейса в данной проверке могли стать причиной двух неудачных тестов.
Преимущества тестирования с помощью RM
Тестирование с помощью RM дает нам следующие преимущества:
- Мы быстро проверяем сборку благодаря параллельному выполнению всех тестовых наборов.
- Мы можем обнаруживать самые медленные определения выпуска и добавлять дополнительные агенты для выполнения тестовых наборов, что ускоряет параллельную обработку. Например, у нас есть два компьютера для сборки непрерывной интеграции («RmCdpCapability=CI»), и мы планируем добавить к ним еще один для RM.CDP.RmEqTfs, поскольку его выполнение длится дольше остальных.
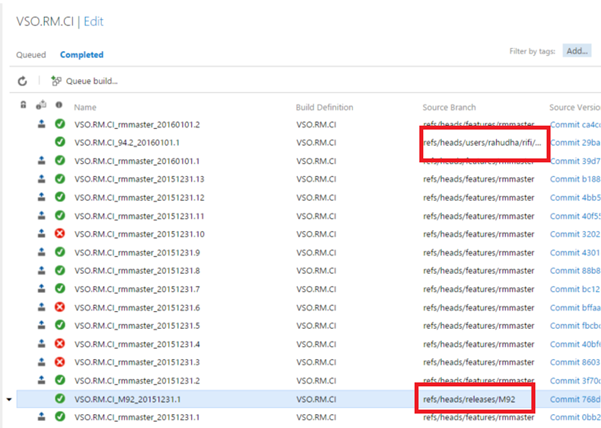
- Такая настройка позволяет легко тестировать различные ветви. Поскольку непрерывная интеграция настроена на ветвь нашей функции (features/rmmaster), мы можем так же легко ставить сборку в очередь из ветви выпуска, например, releases/M92, как показано на снимке экрана ниже. По окончании сборки будут активированы те же определения выпуска RM.CDP.* для обработки двоичного кода из этой ветви выпуска.
- Гибкую работу с ветвями можно расширить в виде следующего сценария: тестирование кода до его проверки может оказываться утомительным для разработчиков (как правило, разработчики выполняют его, когда собираются внести большое количество изменений), например, в выделенной ниже ветви /users/rahudha/rifi. Главная идея заключается в том, что разработчики могут решить ту же задачу путем повторного использования ресурсов группы, не настраивая тестовую инфраструктуру в своих средах разработки.
- Мы можем выполнять в производственной среде те же тесты, что и в среде автоматического тестирования: Поскольку для развертывания в производственную среду мы используем RMO (именно так мы развертываем RMO с помощью RMO), мы можем тестировать развертывание с помощью тех же тестовых задач.
- Поскольку все наборы тестов применяются к одному и тому же набору двоичного кода, мы легко можем ответить на вопрос: «Каково качество сборки?» Как правило, мы хотим знать о качестве сборки до того, как развертываем ее в производственной среде. На приведенном ниже снимке экрана показан простой запрос для определения качества сборки.
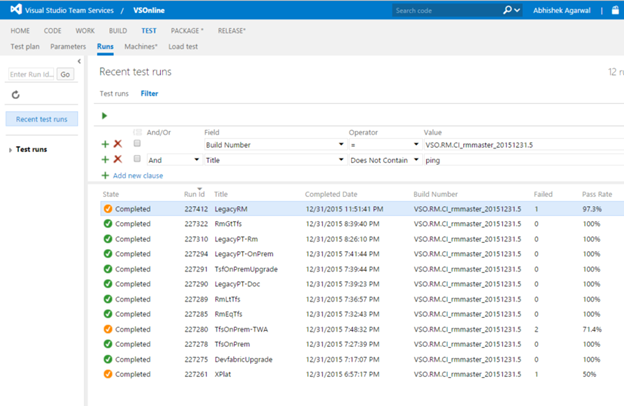
(В ближайшие несколько месяцев эта возможность станет более интегрирована со страницей Release Summary (Сводка выпуска).
Заключение
Вначале мы использовали RMO при тестировании процессов разработки только для того, чтобы понять его возможности. С течением времени мы пришли к выводу, что эффективность RMO существенно выше, чем у тестовой инфраструктуры, которой мы пользовались ранее. Разработчикам нравится, что они могут тестировать крупные изменения без трудоемкой настройки локальной тестовой среды.
Теперь Вы имеете представление о том, как группа разработчиков RM использует RM для автоматизации тестирования. Мы надеемся, что наш опыт подскажет Вам идеи, как автоматизировать процесс тестирования.
Во второй части этого статьи речь пойдет о некоторых проектных решениях, проблемах, с которыми мы столкнулись в процессе организации управления выпусками и способах решения этих проблем.
