[Перевод] Как избежать «подводных камней» машинного обучения: руководство для академических исследователей
Введение
Этот лонг-рид является сильно переработанным и расширенным переводом статьи How to avoid machine learning pitfalls: a guide for academic researchers (Lones, 2021). Статья является кратким описанием ряда распространенных ошибок, возникающих при использовании методов машинного обучения, и руководством к тому, как их избежать. Материал предназначен в первую очередь для студентов-исследователей и касается вопросов, регулярно возникающих в академических исследованиях, например, необходимости проводить строгие сравнения и делать обоснованные выводы. Однако материал применим к использованию ML и в других областях.
Прежде чем приступить к созданию моделей
Подумайте. Это нормально, что вам хочется сразу же начать обучение и оценку моделей. Но начинать надо не с этого — оцените цели проекта; полностью поймите данные, которые будут использоваться; рассмотрите любые ограничения данных, которые необходимо устранить; и поймите, что в вашей области уже было сделано. Если действовать иначе, есть риск получить результаты, которые сложно будет опубликовать, и/или модели, которые не подходят для решения поставленной задачи.
Разберитесь с тем, какую задачу вы хотите решить
При оценке того, является ли задача решаемой, стоит спросить себя:, а нужно ли ее решать? Если да, нужно ли ее решать с помощью машинного обучения?
Изучите литературу
Важно понимать, что было сделано и что не было сделано ранее. Другие люди работали над той же задачей — и это хорошо; академический прогресс обычно представляет собой итерационный процесс, в котором каждое последующее исследование опирается на предыдущее. Можно обнаружить, что кто-то уже исследовал вашу замечательную идею, но, скорее всего, они уж задали ряд направлений для дальнейших исследований.
Игнорировать предыдущие исследования — потенциально упустить ценную информацию. Возможно, кто-то уже пробовал предложенный вами подход и нашел фундаментальные причины, по которым он не сработает (и тем самым избавил вас от нескольких лет разочарования), или же частично решил проблему таким образом, что вы сможете от этого решения оттолкнуться.
Важно провести обзор литературы ДО начала работы. Если вы сделаете это слишком поздно — возможно, придется объяснять, почему вы повторяете те же самые исследований и не опираетесь на существующие знания.
Как искать статьи
Выделите ключевые слова (на английском) по которым вы будете искать похожие исследования
Вбейте их в Google Scholar
Изучите релевантные статьи
Внимательно почитайте вводную часть, возможно там есть ссылки на похожие исследования
Выпишите ключевые идеи и достижения, добавьте ссылки на статьи в свои личные архивы. Они вам еще понадобятся для своего собственного введения.
Так же существует множество агрегаторов, которые мониторят свежевыходящие статьи и каждый день публикуют обзоры на самое интересное (Twitter @ak92501, YouTube Yannic Kilcher и многие другие).
 Примеры ресурсов, на которых можно поискать исследования
Примеры ресурсов, на которых можно поискать исследования
Как искать готовые модели
Для поиска готовых моделей с опубликованным кодом существует отличный ресурс — Papers With Code. Отличительной особенностью ресурса является то, что все модели сравниваются между собой на бэнчмарках (сразу видно какая модель работает лучше всего на каком-то конкретном датасете).
На Papers With Code можно искать по типам задач (например Object Detection или Visual Reasoning). Реализован поиск по методам (например Attention или Graph Embeddings) и по датасетам (например CelebA или PubMed).
 Пример работы с Papers With Code
Пример работы с Papers With Code
Потратьте время на понимание своих данных
В конечном итоге вы захотите опубликовать свою работу. Значительно проще публиковать работы, основанные на данных из надежного источника (собранных с использованием надежной методологии).
Если вы используете данные, скачанные с интернет-ресурса, убедитесь, что вы знаете, откуда они взяты. Описаны ли они в статье? Если да, посмотрите на документ; убедитесь, что он был опубликован в авторитетном месте, и проверьте, упоминают ли авторы какие-либо ограничения используемых датасетов.
Не предполагайте, что если набор данных использовался в ряде работ, то он хорошего качества — иногда данные используются только потому, что их легко достать, а некоторые широко используемые наборы данных имеют свои особенности и существенные ограничения (Paullada et al., 2020). Например, при исследовании категории faces в ImageNet (Deng et al., 2009, Crawford & Paglen, 2019) обнаружили миллионы изображений людей, которые были помечены оскорбительными категориями, включая расистские и унизительные фразы. В ответ на эту работу, большая часть набора данных ImageNet была удалена (Yang et al., 2020).
Если вы обучаете свою модель на плохих данных, то, скорее всего, у вас получится плохая модель. Существует соответствующий термин garbage in garbage out (чушь на входе — чушь на выходе). Всегда начинайте с проверки, что ваши данные осмысленны.
Проведите эксплораторный анализ данных (Cox, 2017). Ищите недостающие или непоследовательные записи. Гораздо проще сделать это сейчас, до обучения модели, чем потом, когда вы будете пытаться объяснить рецензентам, почему вы использовали плохие данные.
Анализ важно провести независимо от того, используете ли вы существующие наборы данных или генерируете новые данные в рамках своего исследования (в этом случае учитывайте, что исследовательский анализ может быть ценен сам по себе, а результаты этого анализа могут стать важной частью вашей статьи).
Отдельным пунктом необходимо отметить, что помимо «содержания», важна и «форма» данных. Формат хранения ваших данных повлияет на скорость, с которой вы сможете завершить свое исследование. Например, у вас есть массив, который называется ID и в нем хранятся следующие данные [1,30,111,221,234] в формате float64. Проверьте, а точно ли тут нужен float64, возможно, ваши данные представлены целыми положительными числами, и для их хранения будет достаточно формата uint32 или даже uint16 (подробный обзор форматов данных в Understanding Data Types).
Разберем на конкретном примере
Скачаем датасет: «Когда и где кого-то покусала собака в NYC» и загрузим его в pandas
# Download dataset
!wget https://data.cityofnewyork.us/api/views/rsgh-akpg/rows.csv?accessType=DOWNLOAD -O dogs.csv
# Load into pandas and display a sample
import pandas as pd
dataset = pd.read_csv('dogs.csv')Проверим, есть ли дубликаты:
if len(dataset) == len(dataset.drop_duplicates()):
print('Очевидных дупликатов нет')
else:
print('%.2f процентов данных являются дубликатами' % len(dataset.drop_duplicates())/len(dataset) * 100)
>>>> Очевидных дупликатов нетУ нас есть колонки: UniqueID, DateOfBite, Species, Breed, Age, Gender, SpayNeuter, Borough, ZipCode. Давайте проверим все ли с ними в порядке. Начнем с определения того, в каком виде хранятся наши данные в памяти.
Object — это далеко не самая эффективная форма хранения информации в Pandas-DataFrame и, как правило, отличный индикатор того, что с данными, что-то не так. Давайте разберемся с каждой колонкой по отдельности.
UniqueID
Мы ожидаем, что в этой колонке каждому объявлению был присвоен уникальный ID. Судя по сэмплу, это просто порядковый номер начинающийся с 1. Можем визуализировать эту колонку, что бы убедиться что там никаких сюрпризов.
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(len(dataset))
plt.xlabel('Index')
plt.ylabel('UniqueID')
plt.scatter(x, dataset['UniqueID'], s=0.1)
Можно заметить, что уникальных идентификаторов меньше чем строк в датафрейме. Давайте убедимся:
dataset['UniqueID'].max(), len(dataset['UniqueID'])
>>>> (12383, 22663)То есть ID повторяются? Судя по всему, в какой-то момент времени нумерация была запущена заново. А значит ID совсем даже не unique => использовать эту колонку как уникальный идентификатор мы не можем.
В каком формате хранятся данные в этой колонке?
dataset['UniqueID'].dtype
>>>> dtype('int64')В int64 можно записывать целые числа в диапазоне от -9223372036854775808 до 9223372036854775807. Мы уже по графику видим, что знак нам не нужен, и что наше максимальное значение явно меньше. Определим какой у нас максимум.
dataset['UniqueID'].min(), dataset['UniqueID'].max()
>>>> (1, 12383)Значит, нам подойдет uint16 целое число без знака в диапазоне от 0 до 65535.
dataset_filtered = dataset.copy()
dataset_filtered['UniqueID'] = dataset['UniqueID'].astype('uint16')Сколько памяти мы выиграли?
def resources_gain(column = 'UniqueID', orig_dataset=dataset, filtered_dataset=dataset_filtered):
original_memory = orig_dataset[column].memory_usage(deep=True)
memory_after_conversion = filtered_dataset[column].memory_usage(deep=True)
gain = original_memory/memory_after_conversion
print(f'Gain: {round(gain, 2)}')
resources_gain(column='UniqueID', orig_dataset=dataset, filtered_dataset=dataset_filtered)
>>>> Gain: 3.99Теперь колонка UniqueID занимает в 4 раза меньше места (а значит, и обрабатывается быстрее).
DateOfBite
В DateOfBite, судя по всему, записано время укуса, но в формате str. Нам было бы удобнее работать с timestamps.
dataset_filtered['DateOfBite'] = pd.to_datetime(dataset['DateOfBite'])Оценим выигрыш в ресурсах
resources_gain(column='DateOfBite', orig_dataset=dataset, filtered_dataset=dataset_filtered)
>>>> Gain: 8.87Теперь проверим нет ли каких-то странных дат.
dataset_filtered['DateOfBite'].hist()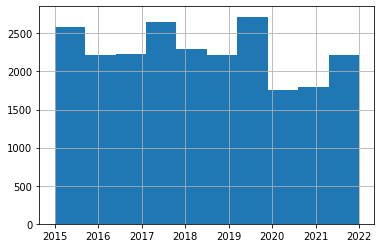
С датами все в порядке, кстати можно заметить, что во время Ковида собакам было меньше кого кусать =)
Species
Мы ожидаем, что в этом отчете сообщается только об укусах собак.
dataset['Species'].unique()Если у нас целая колонка в которой исключительно значение DOG, то зачем нам эта колонка? Правильно. Удаляем ее.
del dataset_filtered['Species']Breed
Посмотрим на то, какие значения есть в этой колонке.
dataset['Breed'].unique()
>>>> array(['UNKNOWN', 'Pit Bull', 'Mixed/Other', ..., 'SHIH TZU',
'CHIWEENIE MIX', 'DUNKER'], dtype=object)Можно заметить, что тип нашего массива — object. Обычно так бывает, когда в массиве есть несколько разных типов данных (например float и str). Давайте найдем все значения, которые не являются строками.
dataset['Breed'][dataset['Breed'].apply(lambda x: type(x) != str)].unique()
>>>> array([nan], dtype=object)Ага — NaN. А выше мы уже видели что есть категория UNKOWN. Давайте поправим
dataset_filtered['Breed'][dataset['Breed'].apply(lambda x: type(x) != str)] = 'UNKNOWN'Теперь посмотрим на поправленный список.
np.sort(dataset_filtered['Breed'].unique()).tolist()[:15]
>>>> ['/SHIH TZU MIX',
'2 BULL TERRIER DOGS',
'2 DOGS: TERR X & DOBERMAN',
'2 PITBULLS',
'AFRICAN BOERBOEL',
'AIREDALE TERRIER',
'AKITA / SHEPHERD MIX',
'AKITA/CHOW CHOW',
'ALAPAHA BULLDOG',
'ALASKA HUSKY',
'ALASKAN HUSKY',
'ALASKAN HUSKY MIX',
'ALASKAN HUSKY/LABRADOR RETR',
'ALASKAN KLEE KAI',
'ALASKAN MALAMUTE']Часто бывает, что категории повторяются с опечатками. Править это придется в ручную (чем мы заниматься сейчас, конечно, не будем). Но, для примера, поправим опечатку в ALASKAN MALMUTE (заменим на ALASKAN MALAMUTE).
dataset_filtered['Breed'][dataset['Breed'] == 'ALASKAN MALMUTE'] = 'ALASKAN MALAMUTE'У нас есть ограниченное (хоть и большое) количество пород. В памяти их выгоднее хранить в качестве категориального признака.
dataset_filtered['Breed'] = dataset_filtered['Breed'].astype('category')Оценим выигрыш в производительности.
resources_gain(column='Breed', orig_dataset=dataset, filtered_dataset=dataset_filtered)
>>>> Gain: 6.35В рамках примера будем считать, что почистили колонку Breed.
Age
Ожидаем, что колонка будет в числовом формате, на деле видим object. Давайте разбираться.
dataset['Age'].unique()[:15]
>>>> array([nan, '4', '4Y', '5Y', '3Y', '7', '6', '5', '8', '11', '3', '13Y',
'2', '10M', '1'], dtype=object)Увы, тут тоже придётся править руками. Необходимо выбрать единую единицу измерения (например месяцы) и все привести к ней. Там, где непонятно — будем писать NaN (хотя, конечно, лучше было бы заполнить более осознанными значениями).
dataset_filtered['Age'][ (dataset['Age'] == '4') |
(dataset['Age'] == '7') |
(dataset['Age'] == '6') |
(dataset['Age'] == '5') |
(dataset['Age'] == '8') |
(dataset['Age'] == '11') |
(dataset['Age'] == '3')] = np.nan #так как нет уверенности, какие именно тут единицы
dataset_filtered['Age'][dataset['Age'] == '4Y'] = 4*12
dataset_filtered['Age'][dataset['Age'] == '5Y'] = 5*12
dataset_filtered['Age'][dataset['Age'] == '3Y'] = 3*12
#и так далееGender
Посмотрим, какие есть варианты пола собаки.
dataset['Gender'].unique()
>>>> array(['U', 'M', 'F'], dtype=object)Тут без сюрпризов, но для увеличения производительности тоже сконвертируем данные в категориальные признаки.
dataset_filtered['Gender'] = dataset['Gender'].astype('category')
resources_gain(column='Gender', orig_dataset=dataset, filtered_dataset=dataset_filtered)
>>>> Gain: 56.97SpayNeuter
Spay/Neutter — была ли собака стерилизована. Мы ожидаем только True и False (хотя удивительно, что нет колонки unknown).
dataset['SpayNeuter'].unique()
array([False, True])Уже используется формат bool, который занимает мало места. Значит, с этой колонкой закончили.
Borough
Boroughs — что-то вроде наших округов (например, ЮЗАО).
dataset['Borough'].unique()
>>>> array(['Brooklyn', 'Manhattan', 'Bronx', 'Other', 'Queens',
'Staten Island'], dtype=object)Также переведем в категориальные признаки.
dataset_filtered['Borough'] = dataset['Borough'].astype('category')
resources_gain(column='Borough', orig_dataset=dataset, filtered_dataset=dataset_filtered)
>>>> Gain: 94.79ZipCode
dataset['ZipCode'].unique()[:15]
>>>> array(['11220', nan, '11224', '11231', '11233', '11235', '11208', '11215',
'11238', '11207', '11205', '11209', '11237', '11217', '11236'],
dtype=object)Видим категории ? и NaN. Их можно объединить.
dataset_filtered['ZipCode'][dataset['ZipCode'] == np.nan] = '?'Остальные значения тоже сделаем категориальными.
dataset_filtered['ZipCode'] = dataset['ZipCode'].astype('category')Напоминим себе какие типы получились в каждой колонке
dataset_filtered.dtypes
>>>> UniqueID uint16
>>>> DateOfBite datetime64[ns]
>>>> Breed category
>>>> Age object
>>>> Gender category
>>>> SpayNeuter bool
>>>> Borough category
>>>> ZipCode category
>>>> dtype: objectОценим, насколько меньше места теперь занимает весь датасет.
gain = dataset.memory_usage(deep=True).sum()/dataset_filtered.memory_usage(deep=True).sum()
print(f'Gain: {round(gain, 2)}')
>>>> Gain: 7.13На этом можем считать нашу чистку завершенной.
Правильно делайте разбиения
Что бы обучить модель, нам понадобиться разбить свои данные на несколько подвыборок (train-val-test).
Рассмотрим пример
Сгенерируем датасет
import numpy as np
dataset_size = 1000
n_features = 2
# Создадим рандомный датасет
X = np.random.normal(size=(dataset_size,n_features))
y = np.random.normal(size=(dataset_size,))
print('Размерность X', X.shape)
print('Размерность y', y.shape)
>>>> Размерность X (1000, 2)
>>>> Размерность y (1000,)Разделим его на train, val и test. Если вы применяете случайное разбиение (как в следующем блоке кода), не забудьте зафиксировать random state, что бы в следующий раз вы получили ровно такую же тестовую выборку.
from sklearn.model_selection import train_test_split
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.15, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.15, random_state=42)
print('Размерность X_train', X_train.shape)
print('Размерность X_val', X_val.shape)
print('Размерность X_test', X_test.shape)
>>>> Размерность X_train (722, 2)
>>>> Размерность X_val (128, 2)
>>>> Размерность X_test (150, 2)plt.scatter(X_train[:,0], X_train[:,1], color='red', alpha=0.5, label='Train')
plt.scatter(X_val[:,0], X_val[:,1], color='green', alpha=0.5, label='Val')
plt.scatter(X_test[:,0], X_test[:,1], color='blue', alpha=0.5, label='Test')
plt.legend()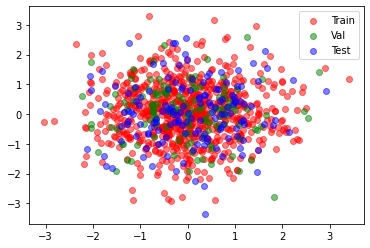
В следующий раз вам предстоит воспользоваться тестом только при проверке обученной модели. А вот валидационный (validation set) нам понадобиться при обучении модели.
Validation set
В процессе обучения модели мы вообще-то хотели бы знать, насколько хорошо она справляется с поставленной задачей. Если для оценки модели на каждой итерации обучения модели мы будем использовать тестовый сет, то просто оптимизируем модель к этому конкретному (тестовому) разбиению и потерям возможность объективно оценивать обобщающую способность модели (тестовое множество станет неявной частью процесса обучения Cawley, 2010). Вместо этого для измерения качества модели (и контроля процесса обучения) следует использовать отдельный (третий) набор для проверки — validation/val set.
Еще одним преимуществом наличия валидационного набора является возможность сделать раннюю остановку (early stopping). Во время обучения модели её качество оценивается по валидационному набору на каждой итерации процесса обучения. Обучение прекращается, когда результат валидации начинает снижаться, так как это указывает на то, что модель начинает переобучаться на train set.
Не смотрите на все ваши данные
Когда вы начнете погружаться в ваши данные, вы, скоре всего, заметите в них какие-то закономерности. Так или иначе, эти закономерности будут направлять вашу дальнейшую работу. Тем не менее, не делайте непроверяемых предположений, которые впоследствии будут использованы в вашей модели. Например, проанализировав датасет с собаками, можно решить что в 2020 и 2021 году собаки стали воспитаннее и перестали так часто кусать прохожих. Но это же не так! На самом деле людей на улицах было меньше, плюс меньше людей хотели и могли обращаться в полицию (из-за ковидных ограничений).
Вообще делать предположения — это нормально, но они должны использоваться только для обучения модели, а не для ее тестирования.
Следует избегать пристального изучения любых тестовых данных на начальном этапе исследовательского анализа. В противном случае вы можете сознательно или неосознанно сделать выводы, которые ограничат обобщающую способность вашей модели не поддающимся тестированию способом. К этой теме мы будем возвращаться еще не раз, поскольку утечка информации из тестового набора в процесс обучения является распространенной причиной плохой обобщаемости ML моделей.
Не допускайте утечки тестовых данных в процесс обучения
Критически важно иметь данные, которые можно использовать для измерения обобщающей способности вашей модели. Распространенная проблема заключается в том, что информация об этих данных просачивается в конфигурацию, обучение или выбор моделей. Когда это происходит, данные перестают быть надежной мерой обобщения, что, в свою очередь, ведет к тому, что опубликованные модели ML регулярно демонстрируют плохие результаты на реальных данных.
Существует несколько вариантов утечки информации из тестового набора. Некоторые из них кажутся вполне безобидными. Например, при подготовке данных используется информация о средних диапазонах переменных во всем наборе данных для масштабирования переменных — чтобы предотвратить утечку информации, такие вещи следует делать только с обучающими данными.
Пример нормализации данных
Создадим искусственный датасет и посмотрим на него
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
dataset = make_moons(n_samples=1000, shuffle=True, noise=0.1, random_state=42)
plt.title('Full dataset')
plt.scatter(dataset[0][:,0], dataset[0][:,1], c=dataset[1])
Данные нужно нормализовать. И очень хочется это сделать сразу со всеми данными, но это приведет к data leakage (утечке данных из тестовой выборки). Давайте все равно это сделаем и временно отложим наш неправильно нормализованный датасет.
import numpy as np
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(dataset[0])
dataset_wrong_data = scaler.transform(dataset[0])
dataset_wrong = (dataset_wrong_data, dataset[1])
plt.title('Неправильно нормализованный датасет')
plt.scatter(dataset_wrong[0][:,0], dataset_wrong[0][:,1], c=dataset_wrong[1])
Теперь разобьем наш исходный датасет на train и test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(dataset[0], dataset[1], test_size=0.2, random_state=42)
plt.scatter(X_train[:,0], X_train[:,1], c=y_train, label='Train', alpha=0.2)
plt.scatter(X_test[:,0], X_test[:,1], c=y_test, marker='x', label='Test')
plt.legend()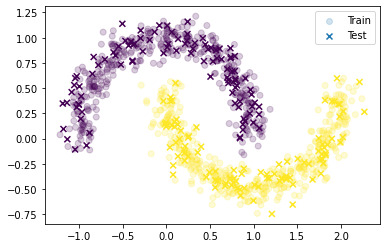
Теперь мы хотим нормализовать данные. Напрашивается идея применить нормализацию к train, и применить нормализацию к test. Так тоже неправильно.
scaler_train = MinMaxScaler()
scaler_test = MinMaxScaler()
scaler_train.fit(X_train)
scaler_test.fit(X_test)
X_train_wrong = scaler_train.transform(X_train)
X_test_wrong = scaler_test.transform(X_test)
plt.scatter(X_train_wrong[:,0], X_train_wrong[:,1], c=y_train, label='Train', alpha=0.2)
plt.scatter(X_test_wrong[:,0], X_test_wrong[:,1], c=y_test, marker='x', label='Test')
plt.title('Еще один не правильно нормализованный датасет')
plt.legend()
Правильно будет использовать тот же скейлер для test, что и для train.
scaler_train = MinMaxScaler()
scaler_train.fit(X_train)
scaler_train.fit(X_test)
X_train_norm = scaler_train.transform(X_train)
X_test_norm = scaler_train.transform(X_test)
plt.scatter(X_train_norm[:,0], X_train_norm[:,1], c=y_train, label='Train', alpha=0.2)
plt.scatter(X_test_norm[:,0], X_test_norm[:,1], c=y_test, marker='x', label='Test')
plt.title('Правильно нормализованный датасет')
plt.legend()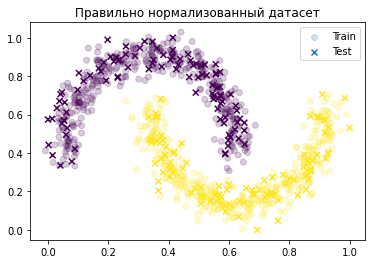
Сравним все вместе.
plt.scatter(dataset_wrong[0][:,0], dataset_wrong[0][:,1], color='blue', alpha=0.1, label='Full wrong')
plt.scatter(X_train_wrong[:,0], X_train_wrong[:,1], color='red', alpha=0.1, label='Train-test wrong')
plt.scatter(X_test_wrong[:,0], X_test_wrong[:,1], color='red', alpha=0.1, marker='x')
plt.scatter(X_train_norm[:,0], X_train_norm[:,1], color='green', alpha=0.2, label='Train-test correct')
plt.scatter(X_test_norm[:,0], X_test_norm[:,1], color='green', alpha=0.2, marker='x')
plt.legend()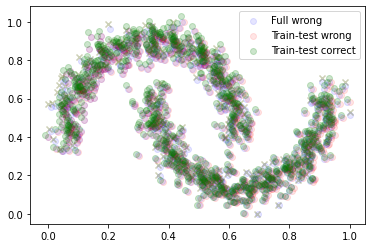
Другий распространенным примером утечки информации является выбор признаков (feature selection, см. Cai et al., 2018) до разбиения данных на подвыборки. Обычно при наличии большого количества признаков проводится их фильтрация тем или иным образом (корреляция с целевой переменной, жадное добавление признаков и пр.).
Например, в геномике это означает отфильтровывание генов, которые являются в каком-то смысле «низкокачественными». Так, мы можем захотеть отфильтровать гены с высокой разреженностью, т.е. имеющие значение 0 для большого числа пациентов. Поскольку критерии для отсеивания таких генов определяются на основе данных, важно, чтобы рассматривался только train set, а не весь набор данных, чтобы определить, нужно ли отсеивать функцию или нет. Поэтому следует вычислять разреженность каждого гена среди обучающих выборок, а не среди всех выборок. В противном случае для отбора признаков будет использована информация, полученная из тестового набора.
Лучшее, что вы можете сделать для предотвращения таких проблем, это разделить подмножество ваших данных в самом начале проекта, и использовать независимый тестовый набор только один раз для измерения генерализации модели в конце проекта (Cawley, 2010 и Kaufman et al., 2012 для более обширного обсуждения этого вопроса. А так же можно обратится к блог-посту Brownlee, в котором детально разбираются часто встречающиеся ошибки).
Убедитесь, что у вас достаточно данных
Если у вас недостаточно данных, то обучение хорошей обобщающей модели может оказаться невозможным. Понять, ваш ли это случай не получится до тех пор, пока вы не начнете строить модели: все зависит от количества шума и ошибок в наборе данных. Если данные «чистые», то можно обойтись меньшим количеством примеров; если много шума — потребуется больше.
Перекрестная валидация (cross-validation)
Если вы не можете получить больше данных — то вы можете более эффективно использовать уже имеющиеся, используя перекрестную валидацию (cross validation. CV).
Вообще говоря, кросс-валидация используется для более точной оценки качества модели. Однократное вычисление качества может быть ненадежно и привести либо к недооценке, либо к переоценке модели. По этой причине обычно проводится серия вычислений метрик. Существует несколько способов провести множественную оценку модели, и большинство из них предполагает многократное обучение модели с использованием различных подмножеств обучающих данных. Перекрестная валидация широко изучена и имеет множество разновидностей построения (Arlot et al., 2010).
Перекерстная валидация в машинном обучении подразумевает, что вместо разбиения набора данных на обучение (train) и тестирование (test), данные разбиваются на множество частей и процесс «обучение-тестирование» производится многократно. Обучение происходит на одних подмножествах, тестирование — на оставшихся, затем выбираются новые подмножества для обучения и тестирования и модель обучается заново. Процедура гарантирует, что модель обучается и тестируется на новых данных на каждом новом шаге.
Часто используют десятикратную прекрестную валидацию.
Разберем на примере
Создадим датасет
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.3, random_state=42)
plt.scatter(X[:,0], X[:,1], c=y)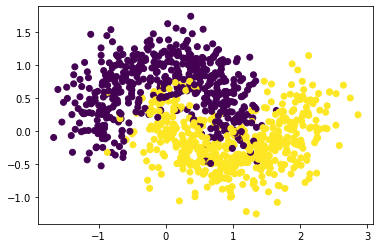
И разделим его на 10 (K) складок (folds). Для каждой складки посчитаем точность классификации
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.ensemble import RandomForestClassifier
#Split data intto 10 folds
kf = KFold(n_splits=10)
kf.get_n_splits(X)
#Define scaler and classifier
scaler = MinMaxScaler()
clf = RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1)
#Define figure space
fig,ax = plt.subplots(nrows=2, ncols=5, figsize=(10,4))
row = 0
scores = []
#Itterate over folds
for col, (train_index, test_index) in enumerate(kf.split(X)):
#Split
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
#Normalize
scaler.fit(X_train)
scaler.fit(X_test)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
#Classify
clf.fit(X_train, y_train)
#Gauge performance
score = clf.score(X_test, y_test)
scores.append(score)
#Plot figure
if col > 4:
col-=5
row=1
ax[row, col].scatter(X_train[:,0], X_train[:,1], c=y_train, alpha=0.05)
ax[row, col].scatter(X_test[:,0], X_test[:,1], c=y_test, marker='x')
ax[row, col].set_title(score)
ax[row, col].axis('off')
Результирующую точность модели мы определим как среднее от всех оценок.
print('Финальная точность = %.2f ± %.2f' % (np.mean(scores), np.std(scores)))
>>>> Финальная точность = 0.91 ± 0.03Для большей надежности можно использовать метод вложенной перекрестной валидации (также известный как двойная кросс-валидация, (см. Cawley, 2010 и Wainer et al., 2021).
Аугментация данных
Вы можете использовать методы аугментации данных (например, Wong et al., 2016, Shorten et al., 2019). Они могут быть весьма эффективны для «расширения» небольших датасетов.
Разберем на примере
#Download image
!wget https://wallpaperaccess.com/full/3842851.jpg
#Read image
image = cv2.imread("3842851.jpg")
#Display
plt.imshow(image)
plt.axis('off')
Теперь определим аугментации
import albumentations as A
import cv2
import matplotlib.pyplot as plt
#Define augmentations
transform = A.Compose([
A.Resize(width=512, height=512),
A.HorizontalFlip(p=1),
A.CLAHE(clip_limit=4.0, tile_grid_size=(8, 8), always_apply=False, p=0.5)
])И применим их к картинке
#Apply transformation
transformed = transform(image=image)
transformed_image = transformed["image"]
#Display original and transformed
fig,ax = plt.subplots(ncols=2, figsize=(10,5))
ax[0].imshow(image)
ax[1].imshow(transformed_image)
ax[0].set_title('Original')
ax[1].set_title('Augmented')
for a in ax:
a.axis('off')
Несколько аугментаций лучше чем одна
До 2021 года была принято проводить аугментации следующим образом: берем сэмпл, применяем к нему набор аугментаций с некоторой вероятностью (например p=0.5) и отправляем этот сэмпл в модель на обучение. В статье Fort et al., 2021 предлагается способ, который работает лучше: берем сэмпл, дублируем его N раз и к каждому из дублей применяем свою аугментацию.
Казалось бы, в каждом мини-батче становится меньше уникальных примеров, что должно бы негативно сказаться на способности к обобщению. Но нет. Точность на тесте только увеличивается.
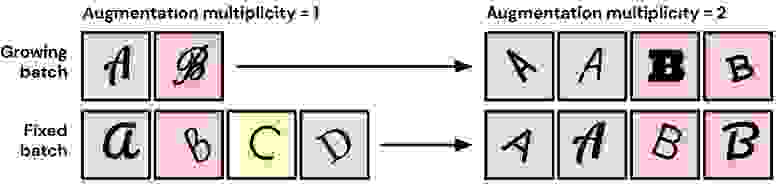 Пример двойной аугментации (Fort el al., 2021)
Пример двойной аугментации (Fort el al., 2021)
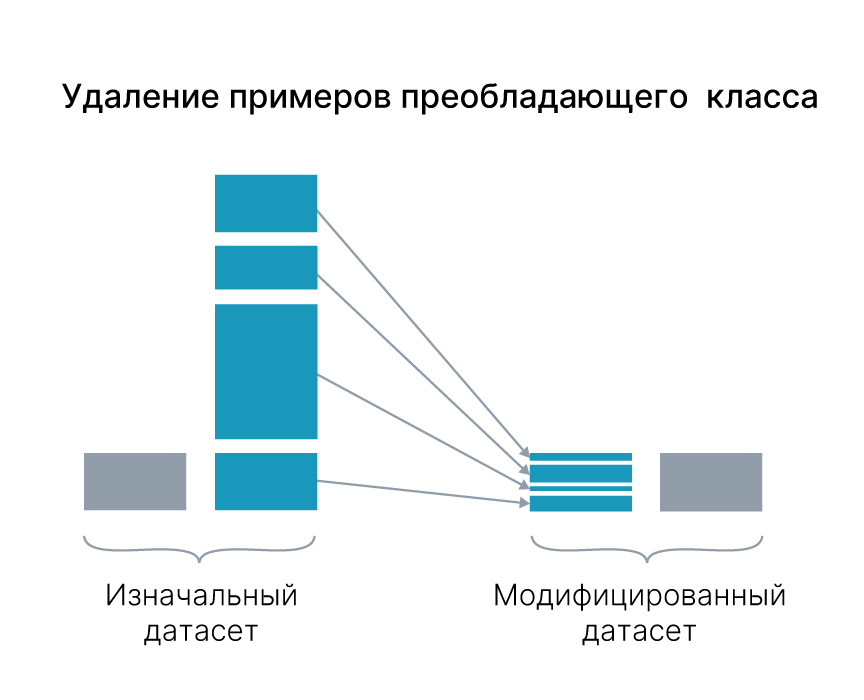
Дисбаланс классов
Увеличение количества данных также полезно в случае дисбаланса классов. Такая ситуация характерна, скажем, для задач классификации, когда в семплов некоторых класса много меньше, чем других. Работа Haixiang et al., 2017 посвящена обзору методов решения данной проблемы.
Transfer-learning
Частично проблема недостаточного количества данных решается при помощи transfer-learning — использования моделей, заранее обученных на данных, близких к вашим.
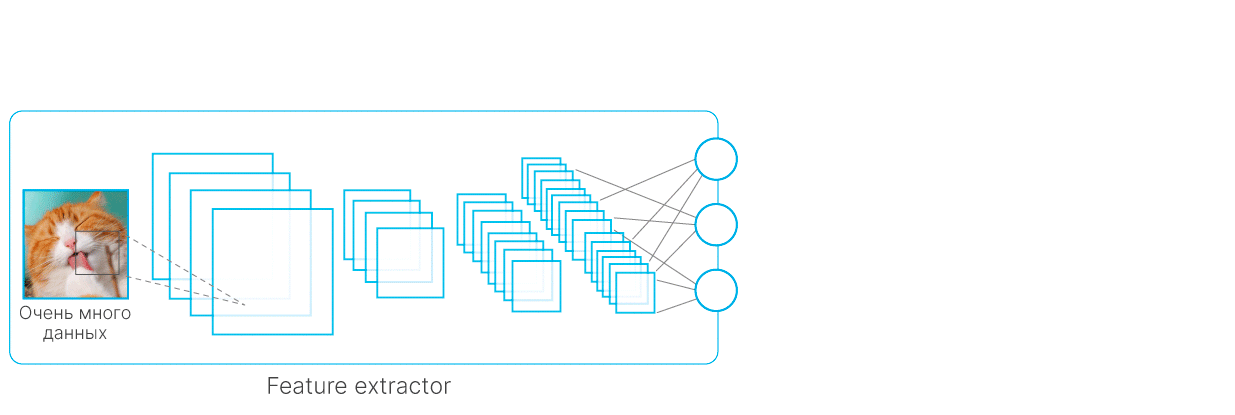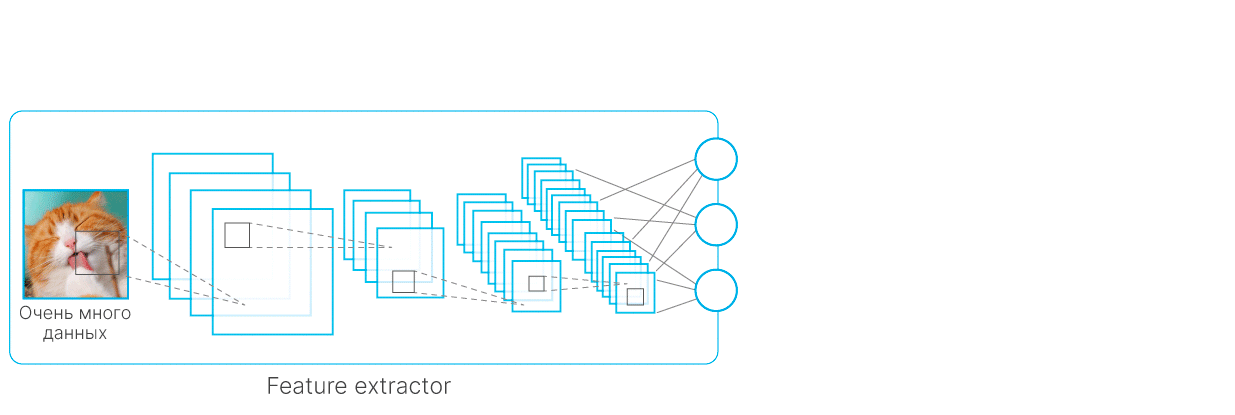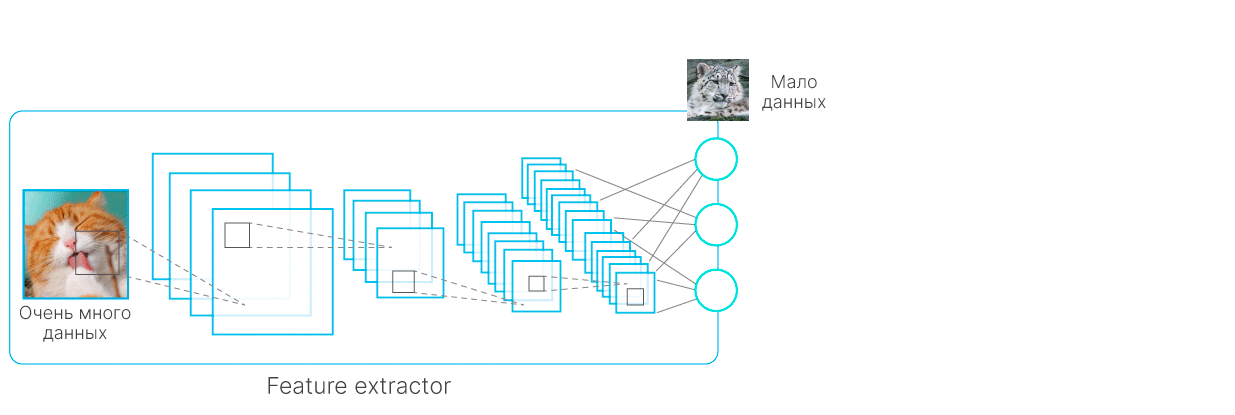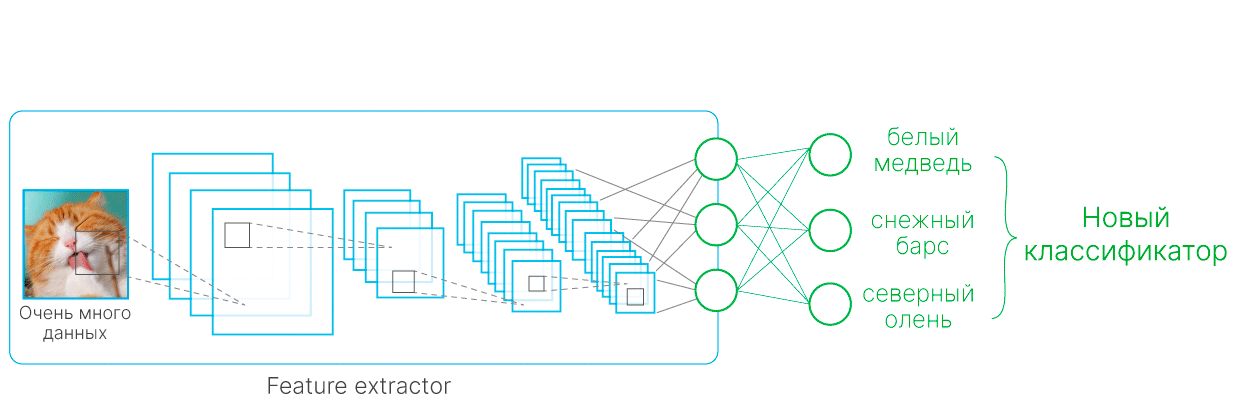 Схематическое объяснение Transfer Learning. Сначала обучается модель на большом датасете, у нее замораживаются все веса, кроме последнего слоя, далее последний слой обучается на интересующем нас маленьком датасете.
Схематическое объяснение Transfer Learning. Сначала обучается модель на большом датасете, у нее замораживаются все веса, кроме последнего слоя, далее последний слой обучается на интересующем нас маленьком датасете.
Следует учитывать, что в случае значительной ограниченности количества данных, скорее всего, вам также придется ограничить сложность используемых моделей ML. Модели с большим количеством параметров, например, глубокие нейронные сети, могут легко переобучаться на небольших датасетах. В любом случае, важно выявить эту проблему на ранней стадии и разработать подходящую (и обоснованную) стратегию для ее решения.
Обращайтесь к экспертам в своей области
Эксперты в области вашего исследования могут быть ценным источником данных, знаний и навыков. Они помогут вам понять, какие проблемы решать полезно и актуально (а какие — нет), как выбрать наиболее подходящий набор данных и модель ML, а также как определить, в каком журнале публиковать статью (аудитория какого журнала будет наиболее подходящей). Если не учитывать мнение экспертов, вы рискуете тем, что ваш проект не будет решать полезные задачи или будет решать неоптимальным или даже вредным способом. К примеру, не лучшей идеей будет использовать неинтерпретирумую ML-модель в областях, где интерпретируемость критически важна. В частности, это относится к принятию медицинских и финансовых решений (Rudin, 2019).
Подумайте о том, как (и где) будет развернута ваша модель
Для чего вам модель ML? Как вы будете ее использовать? Это важные вопросы, и ответ на них должен повлиять на процесс разработки модели. Многие академические исследования по своей сути не подходят для создания моделей, которые будут использоваться в реальном мире (и это не беда, поскольку процесс построения и анализа моделей сам по себе может дать полезное понимание проблемы). Однако у статей, в которых описываются модели, которые можно применять в реальных ситуациях, обычно цитирование значительно выше. Так что стоит заранее подумать о том, как и где ваша модель будет применяться.
Например, если модель будет развернута в среде с ограниченными ресурсами, на датчике или роботе, это следует учесть сразу. На устройстве с маленьким объемом памяти запустить огромный трансформер просто не получится. А в случае, когда классификация сигнала должна быть выполнена в течение миллисекунд, следует обратить особое внимание на потенциальную скорость инференса модели.
 Пример среды с ограниченными ресурсами и требованиями к скорости работы
Пример среды с ограниченными ресурсами и требованиями к скорости работы
Еще одним нюансом может являться контекст того, как ваша модель будет связана с окружением — с программной системой, в которой она будет развернута. Эта процедура зачастую далеко не так проста (Sculley et al., 2015). Однако современнные подходы, такие как ML Ops, направлены на решение подобных трудностей (Tamburri et al., 2020).
Как надежно строить модели
Построение моделей — одна из самых приятных частей ML. С современными ML-фреймворками легко использовать всевозможные подходы к данным и смотреть, какая модель лучше всего решает поставленную задачу. Однако, это может закончиться неорганизованным беспорядком экспериментов, которые потом сложно обосновать и о которых сложно написать статью. Удостоверьтесь, что данные используются правильно, что происходит понятное логирование результатов и что модель подходит для решения задачи.
Попробуйте различные модели
Вообще говоря, не существует такой вещи, как единственная лучшая модель ML. Существует даже доказательство в виде теоремы No Free Lunch, которая показывает, что ни один подход ML не лучше другого, если рассматривать все возможные проблемы (Wolpert, 2002).
Таким образом, ваша задача — найти модель ML, которая хорошо работает для вашей конкретной задачи. Возможно, у вас есть некоторые априорные знания о том, какая модель подойдет лучше всего, например, в виде качественных исследований по схожим темам. Но большую часть времени вам придется работать в темноте. К счастью, современные библиотеки ML позволяют опробовать несколько моделей с небольшими изменениями в коде, поэтому достаточно удобно перебрать несколько моделей и выяснить, какая из них подходит лучше.
Не используйте неподходящие модели
Снижая барьер для имплементации, современные библиотеки ML также облегчают применение неподходящих моделей к вашим данным. В качестве примера можно привести применение моделей, предполагающих категориальные признаки, к набору данных, состоящему из числовых признаков, или попытку применить модель, предполагающую отсутствие зависимостей между переменными к данным временного ряда.
Это особенно важно учитывать в свете публикации, поскольку представление результатов, полученных с помощью несоответствующих моделей, вызовет у рецензентов массу вопросов к вашей работе. Другой крайностью является использование неоправданно сложной модели. Глубокая нейронная сеть — не лучший выбор, если у вас мало данных, а общие знания об области предполагают, что лежащая в основе модель довольно проста.
И, наконец, не используйте «современность» модели в качестве оправдания для ее выбора: старые, проверенные модели часто работают лучше, чем новые.
Какие есть доступные ресурсы для обучения на GPU
GPU — крайне эффективный и ооооочень дорогой способ обучать модели. К счастью для вас вы относитесь к привилегированному классу разработчиков машинного обучения — к классу исследователей, которым за GPU обычно платить не нужно. Если вы можете обосновать зачем вам GPU&nbs
