[Перевод] Как я пишу конспекты по математике на LaTeX в Vim
Некоторое время назад на Quora я отвечал на вопрос: как успевать записывать за лектором конспект по математике на LaTeX. Там я объяснил свой рабочий процесс по конспектированию в LaTeX с помощью Vim и Inkscape (для рисунков). Но с тех пор многое изменилось, так что я хочу опубликовать несколько постов в блоге с описанием нового процесса. Это первая из статей.
Я начал использовать LaTeX для конспектирования во втором семестре курса математики, и с тех пор написал более 1700 страниц. Вот несколько примеров, как выглядит конспект:



Эти конспекты, включая рисунки, делаются прямо на лекции и не редактируются впоследствии. Чтобы эффективно писать конспекты в LaTeX, должны соблюдаться четыре правила:
- Запись текста и формул в LaTeX должна быть такой же быстрым, как у лектора, пишущего на доске: задержка недопустима.
- Рисование иллюстраций должно быть почти таким же быстрым, как у лектора.
- Управление заметками, то есть добавление заметки, компоновка всех заметок, последних двух лекций, поиск в заметках и т. д., должно проходить легко и быстро.
- Должно быть возможно аннотирование pdf-документов с помощью LaTeX, если я хочу написать заметку вместе с pdf-документом.
Эта статья посвящена первому пункту: конспектирование на LaTeX.
Для записи текста и математических формул на LaTeX я использую Vim. Это мощный текстовый редактор общего назначения, весьма расширяемый. Я использую его для написания кода, LaTeX, текста Markdown… в общего, любых текстов. У него довольно крутая кривая обучения, но если вы освоили базу, уже трудно вернуться к редактору без привычных горячих клавиш. Вот как выглядит мой экран, когда я редактирую документ LaTeX:

Слева Vim, а справа — программа Zathura для просмотра PDF, которая тоже поддерживает сочетания клавиш в стиле Vim. Я работаю в Ubuntu с оконным менеджером bspwm. В качестве плагина LaTeX установлен vimtex. Он обеспечивает подсветку синтаксиса, оглавление, synctex и т. д. С помощью vim-plug я настроил его следующим образом:
Plug 'lervag/vimtex'
let g:tex_flavor='latex'
let g:vimtex_view_method='zathura'
let g:vimtex_quickfix_mode=0
set conceallevel=1
let g:tex_conceal='abdmg'
Последние две строки настраивают маскировку. Это функция, в которой код LaTeX заменяется или становится невидимым, когда курсор находится не в этой строке. Если спрятать \ [, \], $, то они не так бросаются в глаза, что даёт лучший обзор документа. Эта функция также заменяет \bigcap на ∩, \in на ∈ и т. д., как показано на анимации:

С такой настройкой можно добиться поставленной задачи: писать на LaTeX так же быстро, как пишет лектор на доске. Здесь в игру вступают сниппеты.
Что такое сниппет?
Сниппет — это короткий фрагмент текста для многоразового использования, который вызывается другим текстом. Например, при наборе sign и нажатии Tab, слово sign превращается в подпись:

Сниппеты могут быть динамическими: когда я набираю today и нажимаю Tab, слово today заменяется текущей датой, а box-Tab становится полем, которое автоматически увеличивается в размере.


Вы даже можете использовать один сниппет внутри другого:

Создание сниппетов с помощью UltiSnips
Для управления сниппетами я использую плагин UltiSnips. Вот его конфигурация:
Plug 'sirver/ultisnips'
let g:UltiSnipsExpandTrigger = ''
let g:UltiSnipsJumpForwardTrigger = ''
let g:UltiSnipsJumpBackwardTrigger = ''
Код для сниппета sign:
snippet sign "Signature"
Yours sincerely,
Gilles Castel
endsnippet
Для динамических фрагментов можете поместить код между обратными кавычками ``, этот код будет запущен при расширении сниппета. Здесь я использовал bash для форматирования текущей даты: date + %F.
snippet today "Date"
`date +%F`
endsnippet
Внутри блока `!p ... ` можно писать на Питоне. Посмотрите на код для сниппета box:
snippet box "Box"
`!p snip.rv = '┌' + '─' * (len(t[1]) + 2) + '┐'`
│ $1 │
`!p snip.rv = '└' + '─' * (len(t[1]) + 2) + '┘'`
$0
endsnippet
Вместо этого кода в документ будет вставлено значение переменной snip.rv. Внутри блоков у вас есть доступ к текущему состоянию сниппета, например, t[1] соответствует месту первой табуляции, fn текущему имени файла и т. д.
Сниппеты значительно ускоряют работу, особенно некоторые из более сложных сниппетов. Начнём с самых простых.
Окружение
Чтобы вставить окружение, достаточно ввести beg в начале строки. Затем имя окружения, которое отражается в команде \end{}. Нажатие Tab помещает курсор внутрь.

Код следующий:
snippet beg "begin{} / end{}" bA
\begin{$1}
$0
\end{$1}
endsnippet
Символ b означает, что такой сниппет работает только в начале строки, A означает автоматическое расширение, то есть не нужно нажимать Tab. Места табуляции, куда осуществляется переход по нажатию Tab и Shift+Tab, обозначены как $1, $2, … и последнее обозначено $0.
Встроенные и отображаемые формулы
Два самых часто используемых сниппета — mk и dm, которые запускают математический режим. Первый для встроенных формул, второй для отображаемых.

Сниппет для формул «умный»: он знает, когда вставлять пробел после знака доллара. Когда я начинаю вводить слово непосредственно за закрывающим $, он добавляет пробел. Но если я набираю другой символ, то он не добавляет пробел, как в случае '$p$-value'.

Код этого сниппета:
snippet mk "Math" wA
$${1}$`!p
if t[2] and t[2][0] not in [',', '.', '?', '-', ' ']:
snip.rv = ' '
else:
snip.rv = ''
`$2
endsnippet
W в конце первой строки означает, что сниппет расширяется только на границах слов. Поэтому, например, hellomk не сработает, а hello mk сработает.
Сниппет для отображаемых формул более простой, но тоже довольно удобный. Он заставляет всегда заканчивать уравнения точкой.

Подстрочные и надстрочные знаки
Еще один полезный сниппет — для индексов. Он изменяет a1 на a_1 и a_12 на a_{12}.

Код этого сниппета в качестве триггера использует регулярное выражение. Он расширяет фрагмент, когда вы вводите символ, за которым следует цифра, закодированная как [A-Za-z]\d, или символ, за которым следуют _ и две цифры: [A-Za-z]_\d\d.
snippet '([A-Za-z])(\d)' "auto subscript" wrA
`!p snip.rv = match.group(1)`_`!p snip.rv = match.group(2)`
endsnippet
snippet '([A-Za-z])_(\d\d)' "auto subscript2" wrA
`!p snip.rv = match.group(1)`_{`!p snip.rv = match.group(2)`}
endsnippet
Когда вы объединяете части регулярного выражения в группу, используя круглые скобки, например, (\d\d), то можете использовать их в расширении сниппета через match.group(i) в Python.
Для надстрочных символов я использую td, который превращается в ^{}. Хотя для самых распространённых (квадрат, куб и несколько других) предназначены отдельные сниппеты, такие как sr, cb и comp.

snippet sr "^2" iA
^2
endsnippet
snippet cb "^3" iA
^3
endsnippet
snippet compl "complement" iA
^{c}
endsnippet
snippet td "superscript" iA
^{$1}$0
endsnippet
Дроби
Один из самых удобных сниппетов работает с дробями. Он делает следующие замены:
// → \frac{}{}
3/ → \frac{3}{}
4\pi^2/ → \frac{4\pi^2}{}
(1 + 2 + 3)/ → \frac{1 + 2 + 3}{}
(1+(2+3)/) → (1 + \frac{2+3}{})
(1 + (2+3))/ → \frac{1 + (2+3)}{}

Для первого простой код:
snippet // "Fraction" iA
\\frac{$1}{$2}$0
endsnippet
Вторая и третья замены происходят с помощью регулярных выражений, соответствующих выражениям 3/, 4ac/, 6\pi^2/, a_2/ и т. д.
snippet '((\d+)|(\d*)(\\)?([A-Za-z]+)((\^|_)(\{\d+\}|\d))*)/' "Fraction" wrA
\\frac{`!p snip.rv = match.group(1)`}{$1}$0
endsnippet
Как видите, регулярные выражения могут стать весьма длинными, но вот диаграмма, которая должна всё объяснить:

В четвёртом и пятом случаях сниппет пытается найти соответствующую скобку. Поскольку механизм регулярных выражений UltiSnips этого не умеет, пришлось применить Python:
priority 1000
snippet '^.*\)/' "() Fraction" wrA
`!p
stripped = match.string[:-1]
depth = 0
i = len(stripped) - 1
while True:
if stripped[i] == ')': depth += 1
if stripped[i] == '(': depth -= 1
if depth == 0: break;
i -= 1
snip.rv = stripped[0:i] + "\\frac{" + stripped[i+1:-1] + "}"
`{$1}$0
endsnippet
Наконец, хочу поделиться сниппетом, который превращает текущее выделение в дробь. Выделяете текст, нажимаете Tab, набираете / и снова Tab.

Код использует переменную ${VISUAL}, которая отражает ваш выбор.
snippet / "Fraction" iA
\\frac{${VISUAL}}{$1}$0
endsnippet
Sympy и Mathematica
Другой классный, но менее используемый сниппет, запускает sympy для оценки математических выражений. Например: sympy Tab расширяется до sympy | sympy, а sympy 1 + 1 sympy Tab превращается в 2.

snippet sympy "sympy block " w
sympy $1 sympy$0
endsnippet
priority 10000
snippet 'sympy(.*)sympy' "evaluate sympy" wr
`!p
from sympy import *
x, y, z, t = symbols('x y z t')
k, m, n = symbols('k m n', integer=True)
f, g, h = symbols('f g h', cls=Function)
init_printing()
snip.rv = eval('latex(' + match.group(1).replace('\\', '') \
.replace('^', '**') \
.replace('{', '(') \
.replace('}', ')') + ')')
`
endsnippet
Для Mathematica тоже возможно нечто подобное:

priority 1000
snippet math "mathematica block" w
math $1 math$0
endsnippet
priority 10000
snippet 'math(.*)math' "evaluate mathematica" wr
`!p
import subprocess
code = 'ToString[' + match.group(1) + ', TeXForm]'
snip.rv = subprocess.check_output(['wolframscript', '-code', code])
`
endsnippet
Постфикс-сниппеты
Мне кажется, достойны упоминания также постфикс-сниппеты, которые вставляют соответствующий текст псле ввода определённых символов. Например, phat → \hat{p} и zbar → \overline{z}. Аналогичный сниппет вставляет вектор, например, v,. → \vec{v} и v., → \vec{v}. Порядок точки и запятой не имеет значения, так что я могу нажимать их одновременно. Эти сниппеты реально экономят время, потому что вы вводите их с той же скоростью, с какой лектор пишет на доске.

Обратите внимание, что по-прежнему работают префиксы bar и hat, только с более низким приоритетом. Код для этих сниппетов:
priority 10
snippet "bar" "bar" riA
\overline{$1}$0
endsnippet
priority 100
snippet "([a-zA-Z])bar" "bar" riA
\overline{`!p snip.rv=match.group(1)`}
endsnippet
priority 10
snippet "hat" "hat" riA
\hat{$1}$0
endsnippet
priority 100
snippet "([a-zA-Z])hat" "hat" riA
\hat{`!p snip.rv=match.group(1)`}
endsnippet
snippet "(\\?\w+)(,\.|\.,)" "Vector postfix" riA
\vec{`!p snip.rv=match.group(1)`}
endsnippet
Другие сниппеты
У меня ещё около сотни часто используемых сниппетов. Все они доступны здесь. Большинство из них довольно просты. Например, !> превращается в \mapsto, -> становится \to и т. д.

fun трансформируется в f: \R \to \R :, !> → \mapsto, cc → \subset.

lim становится \lim_{n \to \infty}, sum → \sum_{n = 1}^{\infty}, ooo → \infty.


Сниппеты для конкретных курсов
Кроме часто используемых, у меня есть и специфические сниппеты. Они загружаются одной строкой в .vimrc:
set rtp+=~/current_course
Здесь current_course — это символическая ссылка на текущий курс (подробнее об этом в другой статье). В этой папке лежит файл ~/current_course/UltiSnips/tex.snippets, куда я добавляю сниппеты курса. Например, для квантовой механики есть сниппеты для записи квантовых состояний бра и кет.
|q> → \ket{\psi}
Поскольку в квантовой механике часто используется \psi, то я сделал автоматическую замену всех q в braket на \psi.

snippet "\<(.*?)\|" "bra" riA
\bra{`!p snip.rv = match.group(1).replace('q', f'\psi').replace('f', f'\phi')`}
endsnippet
snippet "\|(.*?)\>" "ket" riA
\ket{`!p snip.rv = match.group(1).replace('q', f'\psi').replace('f', f'\phi')`}
endsnippet
snippet "(.*)\\bra{(.*?)}([^\|]*?)\>" "braket" riA
`!p snip.rv = match.group(1)`\braket{`!p snip.rv = match.group(2)`}{`!p snip.rv = match.group(3).replace('q', f'\psi').replace('f', f'\phi')`}
endsnippet
Контекст
При написании этих сниппетов следует учитывать, могут ли они встретиться в обычном тексте. Например, согласно моему словарю, в английском языке около 72 слов, а в голландском — 2000 слов, содержащих sr. Таким образом, когда я набираю слово disregard, sr заменится на ^2, и получится di^2egard.
Решение этой проблемы — в добавлении контекста к сниппетам. С помощью подсветки синтаксиса Vim определяется, должен ли UltiSnips применять сниппет, в зависимости от того, находитесь ли вы в режиме формул или текста. Я придумал такой вариант:
global !p
texMathZones = ['texMathZone'+x for x in ['A', 'AS', 'B', 'BS', 'C',
'CS', 'D', 'DS', 'E', 'ES', 'F', 'FS', 'G', 'GS', 'H', 'HS', 'I', 'IS',
'J', 'JS', 'K', 'KS', 'L', 'LS', 'DS', 'V', 'W', 'X', 'Y', 'Z']]
texIgnoreMathZones = ['texMathText']
texMathZoneIds = vim.eval('map('+str(texMathZones)+", 'hlID(v:val)')")
texIgnoreMathZoneIds = vim.eval('map('+str(texIgnoreMathZones)+", 'hlID(v:val)')")
ignore = texIgnoreMathZoneIds[0]
def math():
synstackids = vim.eval("synstack(line('.'), col('.') - (col('.')>=2 ? 1 : 0))")
try:
first = next(
i for i in reversed(synstackids)
if i in texIgnoreMathZoneIds or i in texMathZoneIds
)
return first != ignore
except StopIteration:
return False
endglobal
Теперь можно добавить context "math()" к тем сниппетам, которые вы хотите применять только в математическом контексте.
context "math()"
snippet sr "^2" iA
^2
endsnippet
Обратите внимание, что математический контекст — тонкая вещь. Иногда в режиме формул мы тоже пишем текст, используя \text{...}. В этом случае мы не хотим применять сниппеты. Однако в следующем случае: \[ \text{$...$} \], они должны применяться. Вот почему код для контекста math не так прост. Следующая анимация иллюстрирует эти тонкости.

Исправление орфографических ошибок на лету
Хотя формулы — важная часть конспекта, основную часть времени я печатаю на английском языке. Примерно 80 слов в минуту, мои навыки набора текста неплохие, но я делаю много опечаток. Вот почему я добавил привязку к Vim, которая исправляет орфографические ошибки, не мешая работе. Когда я во время ввода нажимаю Ctrl+L, исправляется предыдущая орфографическая ошибка. Это выглядит так:
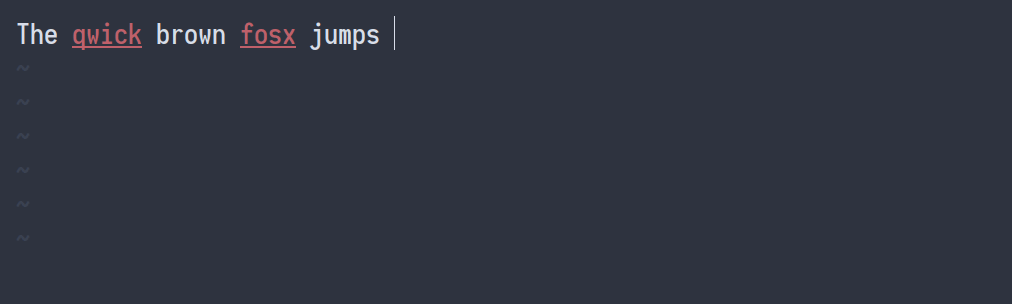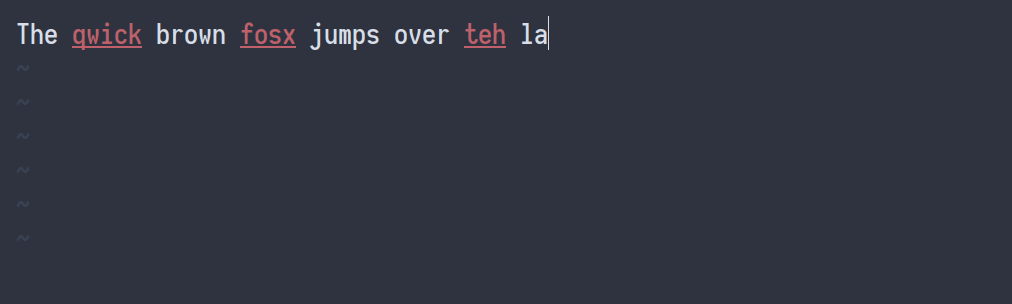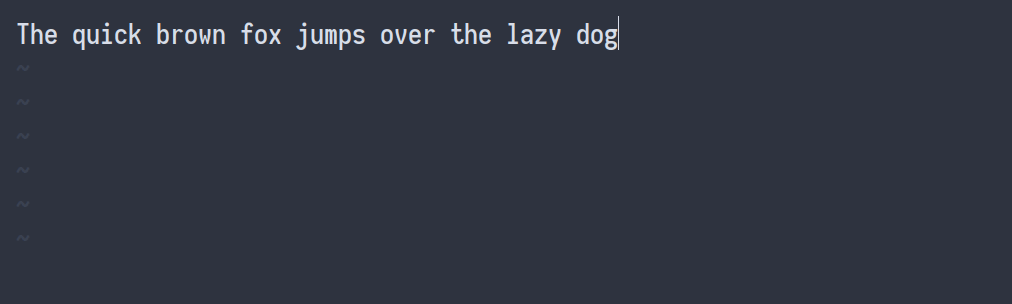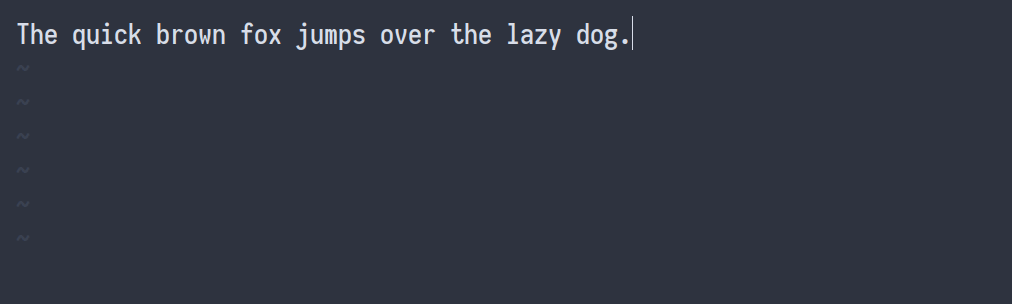
Мои настройки для проверки орфографии:
setlocal spell
set spelllang=nl,en_gb
inoremap u[s1z=`]au
Здесь переход к предыдущей орфографической ошибке [s, затем выбор первого варианта 1z= и возврат `]a. Команды
В заключение
Благодаря сниппетам Vim, написание кода LaTeX больше не вызывает раздражение, а становится скорее удовольствием. В сочетании с проверкой орфографии на лету это позволяет удобно и быстро конспектировать лекции по математике. В следующей статье расскажу об остальных темах, таких как рисование иллюстраций в цифровом виде и встраивание их в документ LaTeX.
