[Перевод] Как я нашел баг в Google Meet

Это отладочное приключение Брюса Доусона, разработчика Chrome и блогера, позволило снизить загрузку процессора при работе с веб-камерой примерно на 3% — настоящая помощь для тех, кто полагается на видеозвонки.
В 2020 году роль видеоконференций значительно возросла. Я не в команде Google Meet, но работаю над Chrome, поэтому я запустил свой любимый профилировщик во время одного из своих совещаний, чтобы посмотреть, смогу ли я найти с его помощью полезную информацию.
Во время видеоконференции задействовано много различных процессов. При десятке открытых вкладок было 37 процессов Chrome, шесть из которых активно участвовали в работе видеосвязи. Кроме того, было запущено более 200 других процессов (например, 87 копий svchost.exe), четыре из которых также участвовали в работе видеосвязи. Вы можете задаться вопросом, почему для соединения двух людей требуется 10 процессов, поэтому вот список процессов и их ролей:
audiodg.exe — Windows Audio Device Graph Isolation, вывод звука
dwm.exe — Windows Desktop Window Manager, показ видео
svchost.exe — Windows Camera Frame Server (захват веб-камеры)
System — системный процесс Windows, выполняет разные задачи от имени процессов
chrome.exe — браузерный процесс, главная управляющая программа
chrome.exe — процесс рендеринга, вкладка Meet
chrome.exe — процесс GPU, отвечает за рендеринг страниц
chrome.exe — служебный процесс NetworkService, общается с сетью
chrome.exe — VideoCaptureService, общается с Windows Camera Frame Server
chrome.exe — AudioService, управляет вводом и выводом звука
Эти задачи распределены по разным процессам для обеспечения безопасности и стабильности. Если один из них выйдет из строя, его можно перезапустить, не отключая остальные. Если работа одного из них нарушена из-за ошибки безопасности, он будет изолирован от остальной системы, чтобы снизить ущерб.
Все это имеет смысл, но наличие такого большого количества процессов затрудняет профилирование производительности. Непростой задачей будет просмотреть все эти процессы, чтобы найти места для потенциальных улучшений. Также это усложняется тем, что я мало знаю об архитектуре Meet.
Анализ профиля
Видеосвязь требует интенсивной работы ЦП — нужно записывать, сжимать, передавать, получать, распаковывать и отображать как аудио, так и видео. В приведенных ниже данных показаны сэмплы ЦП, записанные службой Microsoft«s Event Tracing for Windows (ETW). Этот профилировщик выборки прерывает каждый запущенный поток примерно 1000 раз в секунду и записывает стек вызовов. Для отображения результатов я использовал Windows Performance Analyzer (WPA). На скриншоте ниже я просматривал 10-секундный период. Видно более 16000 сэмплов (что составляет около 16 секунд процессорного времени), которые были записаны для 10 процессов, участвующих в работе видеосвязи:
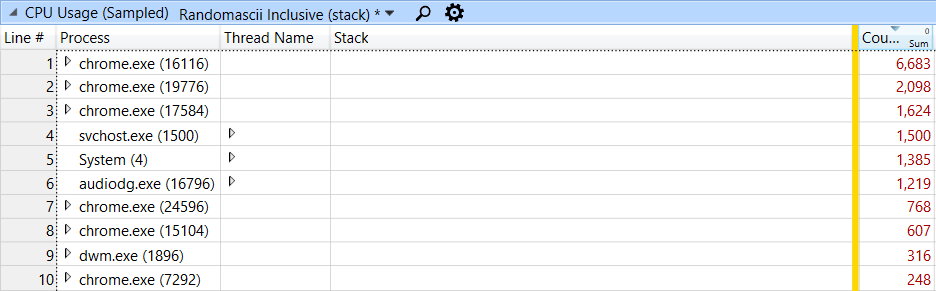
Нужно посмотреть слишком много сэмплов, но стеки вызовов упорядочены, так что можно детализировать только самые загруженные. Я ничего не нашел в первом процессе Chrome, но во втором кое-что обнаружилось:
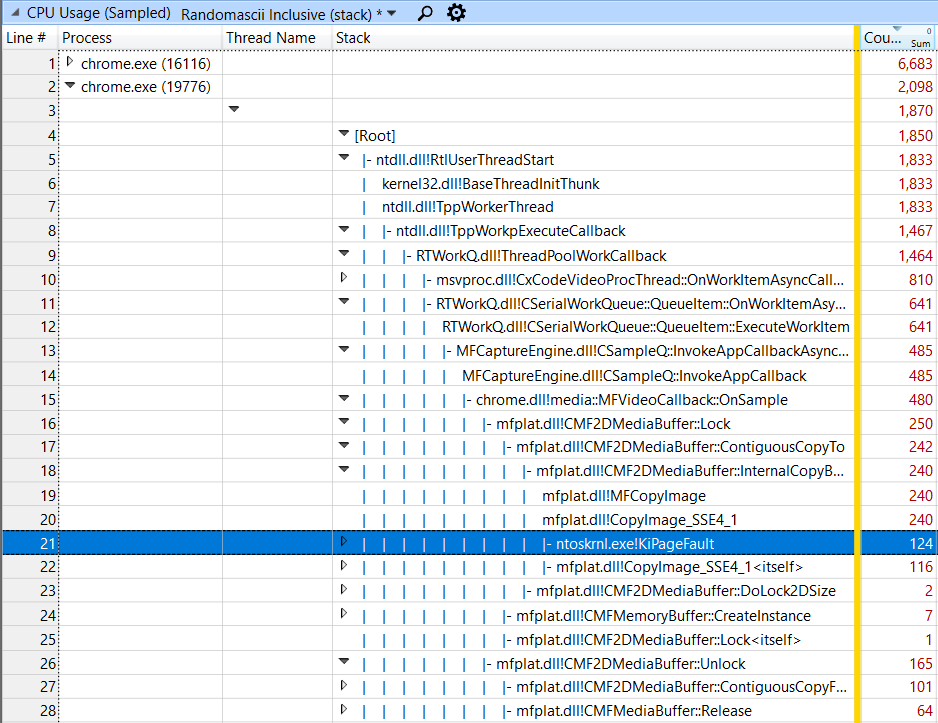
Я понял, что 124 сэмплов в KiPageFault заслуживают изучения. Большая часть работы с интенсивным использованием ЦП в этой трассировке была важной и неизбежной, но у меня было подозрение, что эти сэмплы представляют собой работу, которой можно избежать — что-то, что я могу исправить. И хотя они составляли всего 0,75% сэмплов, я подозревал, что они указывают на несколько большие затраты.
Я сразу осознал их важность, потому что нечто подобное видел ранее. KiPageFault означает, что процессор обратился к памяти, которая была выделена, но в данный момент не принадлежит процессу. Возможно, страницы были удалены из процесса для экономии памяти, но в активном процессе на машине с большим объемом памяти это бессмысленно. Более вероятно, что это недавно выделенная память.
Когда программа выделяет небольшой объем памяти, диспетчер локальной памяти (иногда называемый «кучей») обычно имеет некоторый доступный объем, который он может передать программе. Но если у него нет подходящего блока памяти, он запросит некоторую часть у операционной системы (ОС). Если программа выделяет большой объем памяти (больше 1 МБ или около того), то куча обязательно запросит больше памяти. Сама по себе это относительно дешевая операция. Куча запрашивает у ОС некоторую память, ОС говорит «конечно», затем ОС отмечает тот факт, что она обещала память, и все. В это время ОС фактически не предоставляет программе никакой памяти. Так устроен мир в Windows, Linux, Android, и это хорошо, но может сбивать с толку и удивлять. Если процесс никогда не обращается к памяти, тогда память никогда не добавляется к процессу, но если процесс действительно обращается к памяти, то в ему предоставляются отдельные страницы обнуленной памяти. Они называются demand zero page fault, потому что обнуленные страницы «вставляются» в процесс по запросу.
Другими словами, выделение большого блока памяти довольно дешево, но на самом деле оно не предоставляет обещанную память. Затем, когда программа пытается использовать память и ЦП обнаруживает, что по этому адресу ничего нет, он запускает исключение, которое пробуждает ОС. ОС проверяет свои записи и понимает, что на самом деле она обещала разместить память по этому адресу, поэтому она помещает туда часть памяти и перезапускает программу. Такое поведение легко не заметить, так как оно происходит очень быстро, но при профилировании это проявляется как сэмплы, попадающие в KiPageFault.
Этот причудливый «танец» повторяется снова для каждого выделенного блока размером 4 КБ (4 КБ — это размер страниц, над которыми работают ЦП и ОС).
Затраты небольшие. За 10-секундный период только 124 сэмпла, что составляет около 124 мс или 0,124 секунды, попали в KiPageFault. Общая стоимость внешней функции CopyImage_SSE4_1 составляла около 240 мс, поэтому на ошибки страниц приходилось более половины этой функции, но едва ли четверть стоимости функции OnSample в строке 15.
Общие затраты на эти ошибки страниц скромны, но они намекают на многие другие затраты:
Если эта память выделяется повторно (предположительно каждый кадр), то она также должна освобождаться каждый кадр. В строке 26 мы видим, что функция Release, которая освобождает память, использует еще 64 сэмпла.
Когда страницы освобождаются, операционная система должна обнулить их (по соображениям безопасности), чтобы они были готовы к повторному использованию. Это делается в процессе Windows System — почти полностью скрытые затраты. Конечно, когда я заглянул в процесс System, я увидел 138 сэмплов в MiZeroPageThread. Я обнаружил, что 87% сэмплов KiPageFault во всей системе были в вызове CopyImage_SSE4_1, поэтому предположительно 87% из 138 сэмплов в MiZeroPageThread были связаны с сним.
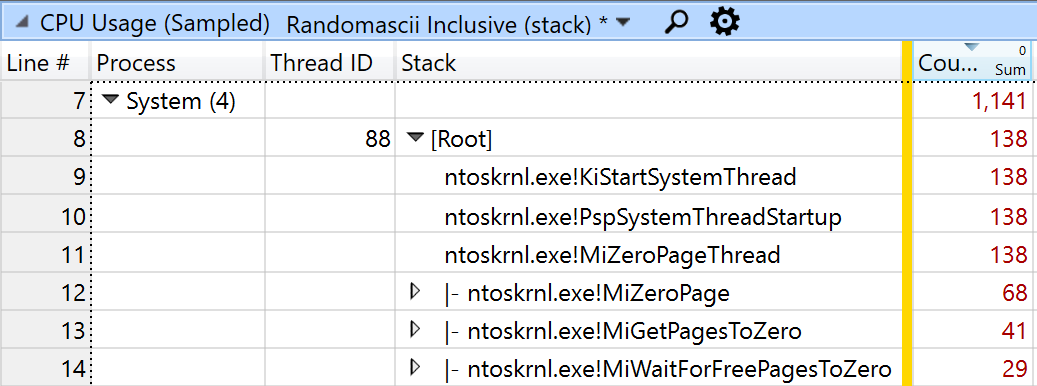
Я проанализировал эти скрытые затраты на выделение памяти в блоге 2014 года. Базовая архитектура памяти Windows с тех пор не изменилась, поэтому скрытые затраты остаются примерно такими же.
В дополнение к сэмплам ЦП моя трассировка ETW содержала стеки вызовов для каждого вызова VirtualAlloc. На этом скриншоте WPA показан 10-секундный период, в течение которого функция OnSample выполняет 298 выделений памяти, каждое по 1,320 МБ, примерно 30 в секунду:
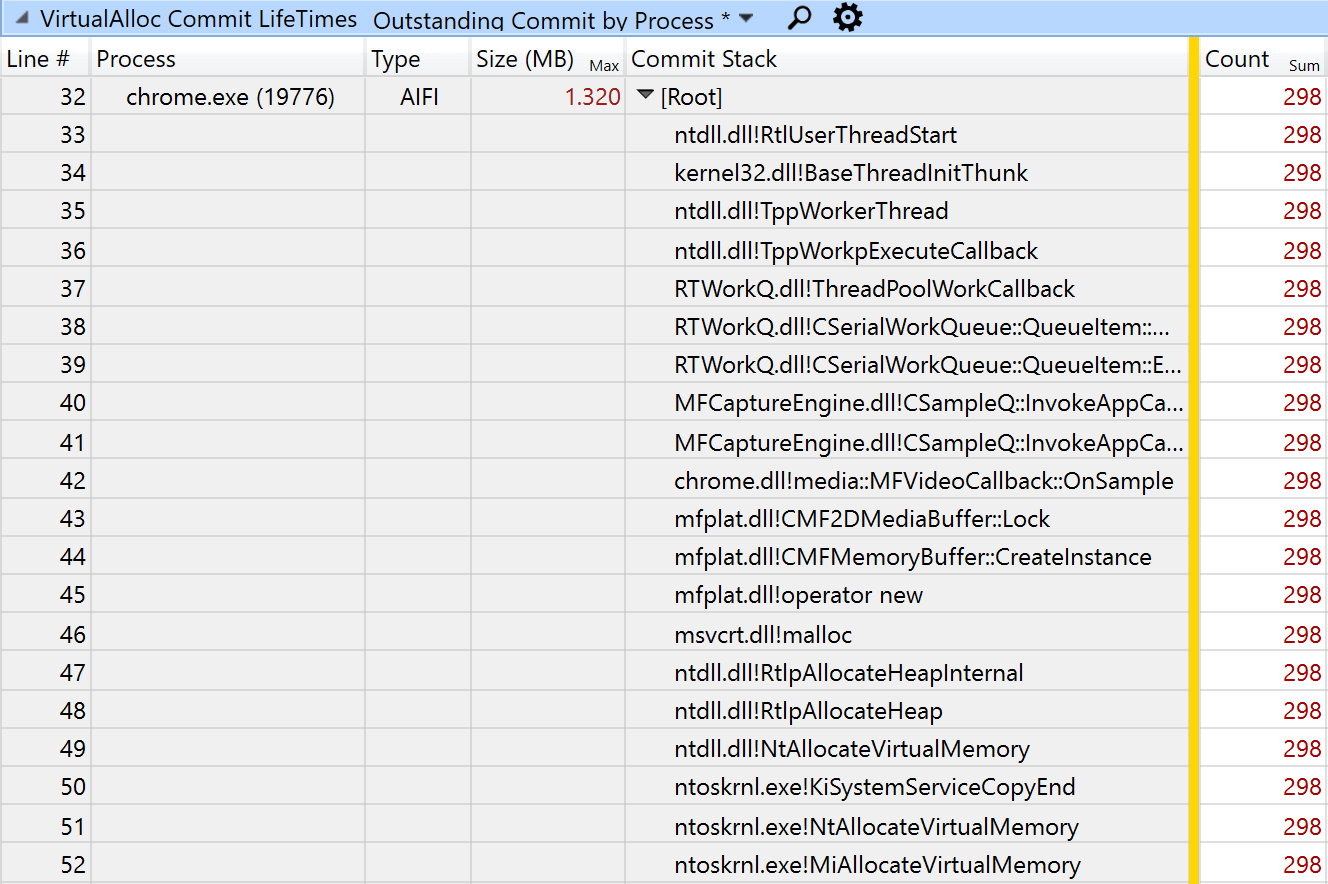
На данный момент мы можем оценить, что стоимость этих повторных выделений памяти составляет 124 (отказ страницы) плюс 64 (освобождение) плюс 124 (87% выборок обнуления), всего 312 сэмплов. Это дает нам до 1,9% от общих затрат процессора на работу видеоконференции. Исправления, конечно, мир не изменят, но стоят того.
Но подождите, это еще не все!
Мы блокируем буфер, чтобы просматривать его содержимое, но оказывается, что мы вообще не хотим, чтобы вызов блокировки копировал буфер. Мы просто хотим, чтобы вызов блокировки описал нам буфер, чтобы мы могли посмотреть на него на месте. Следовательно, вся стоимость вызова MFCopyImage — пустая трата! Это еще 116 сэмплов. Кроме того, в вызове CMF2DMediaBuffer: Unlock в строке 26 есть еще один вызов CMF2DMediaBuffer: ContiguousCopyFrom. Это потому, что вызов Unlock предполагает, что мы могли изменить копию буфера, поэтому он копирует ее обратно. Так что 101 сэмпл — тоже мусор!
Если мы сможем проверять этот буфер без танца из alloc/copy/copy/free, то мы сможем сохранить 312 сэмплов плюс 116 сэмплов (остальная часть стоимости копирования) плюс 101 сэмпл (стоимость обратного копирования) для общей экономии в 3,2%. Становится все лучше и лучше.
Обратите внимание, что выборочные данные достоверны только статистически, а фактические проценты значительно различаются в зависимости от компьютера и конкретной рабочей нагрузки. Но суть остается в том, что это не кардинальное, но заслуживающее внимания изменение.
Несмотря на то, что я провел годы в бизнесе видеоигр, мои знания об API блокировки и разблокировки графического буфера очень слабы. В итоге я полагался на мудрость своих подписчиков в Твиттере, чтобы прийти к выводу, что копирования можно было полностью избежать, и получить приблизительный способ, как это можно исправить. После зарегистрировав излишне подробный отчет об ошибке, я делегировал задачу по ее исправлению. Изменение появилось в М85 и было признано достаточно важным , чтобы бэкпортировать его в М84.
Нужно быть очень внимательны, чтобы увидеть разницу — распределенную между процессом Chrome и системным процессом -, но я надеюсь, что это помогло некоторым компьютерам меньше греться и дольше работать от батарей. И хотя эта неэффективность была обнаружена при профилировании Google Meet, улучшение фактически приносит пользу любому продукту, который использует веб-камеру внутри Chrome (и других браузеров на основе Chromium).
Проверка
После того, как все исправили, я сравнил две 10-секундные ETW трассировки из Chrome Canary до и после изменения, каждая из которых была сделана без других запущенных программ, кроме одной вкладки Chrome, запускающей страницу предварительной встречи Google Meet. В обоих случаях я смотрел на 10-секундный период времени в профилировщике. Это показало:
Процессорное время в OnSample:
До: 458 мс (из которых 432 мс приходились на Lock / Unlock / KiPageFault)
После: 27 мс
Выделения памяти:
До: 30 выделений 1,32 МБ в секунду (по одному на кадр, скорость 30 кадров в секунду — более высокая частота кадров означает больше выделений), всего 396 МБ за 10 секунд
После: 0 выделений
Процессорное время в MiZeroPageThread:
Раньше: 36 мс
Через: 0 мс
Эти измерения показали — тремя разными способами — что проблема с производительностью была решена. Прекращено копирование памяти в OnSample, пропало повторное выделение памяти и системный процесс выполнял меньше работы. Миссия выполнена, ошибка устранена.
