[Перевод] История одного бага: выравнивание данных на x86
Звучит необычно. Кому понадобится делать это в реальной жизни? Обычно такие вычисления встречаются только в задачках из начальной школы или бенчмарках компилятора. Но сейчас это случилось на самом деле.
В реальности стояла задача проверить контрольную сумму заголовков IPv4, которая является суммой обратных кодов (дополнений до единицы) двухбайтных машинных слов. Проще говоря, это означает сложение всех слов и всех битов переноса, которые производятся в процессе. У этой процедуры есть несколько приятных особенностей:
- её можно эффективно выполнить с помощью процессорной инструкции
ADC(к сожалению, эта функция недоступна в C); - её можно выполнить на словах любого размера (можете добавить по желанию восьмибайтные значения, только результат следует уменьшить до двух байт и добавить все биты переполнения);
- она нечувствительна к порядку следования байтов (удивительно, но это так).
Было одно важное требование: исходные данные не были выравнены (IP фреймы такие, какими поступали с оборудования или читались из файла).
Мне не нужно было заботиться о программной переносимости, потому что код должен был работать только на единственной платформе: Intel x64 (Linux и GCC 4.8.3). У Intel нет ограничений на выравнивание целочисленных операндов (доступ к невыровненным данным раньше был медленным, но уже нет), и, поскольку порядок следования байтов неважен, то и порядок байтов от младшего к старшему сойдёт. Так что я по-быстрому написал:
_Bool check_ip_header_sum (const char * p, size_t size)
{
const uint32_t * q = (const uint32_t *) p;
uint64_t sum = 0;
sum += q[0];
sum += q[1];
sum += q[2];
sum += q[3];
sum += q[4];
for (size_t i = 5; i < size / 4; i++) {
sum += q[i];
}
do {
sum = (sum & 0xFFFF) + (sum >> 16);
} while (sum & ~0xFFFFL);
return sum == 0xFFFF;
}Исходный код и выдачу ассемблера можно найти в репозитории.
Наиболее обычный размер IP-заголовка составляет 20 байт (5 двойных слов, которые я буду называть просто словами) — вот почему код выглядит таким образом. Кроме того, размер никогда не может быть меньше — это проверяется перед вызовом данной функции. Поскольку IP-заголовок не может быть больше 15 слов, число итераций цикла составляет от 0 до 10.
Этот код действительно не является программно переносимым — известно, что доступ к произвольной памяти с помощью указателей на 32-битные значения не работает на некоторых процессорах. Например, на большинстве процессоров RISC, если не на всех. Но, как я сказал ранее, никогда не предполагалось, что это создаст проблемы на x86.
И конечно (иначе здесь не было бы о чём рассказывать) реальность доказала обратное, и этот код выпал с ошибкой SIGSEGV.
Упрощение
Сбой происходил только когда выполнялся цикл, то есть заголовки были длиннее 20 байт. В реальной жизни это происходит очень редко, но мне повезло, потому что в моём тестовом наборе данных были такие заголовки. Давайте упростим наш код только до этого цикла. Напишем его на чистом C и разделим на два файла, дабы избежать встроенных функций. Вот наш
sum.c.#include
#include
uint64_t sum (const uint32_t * p, size_t nwords)
{
uint64_t res = 0;
size_t i;
for (i = 0; i < nwords; i++) res += p [i];
return res;
} А вот
main.c.#include
#include
extern uint64_t sum (const uint32_t * p, size_t nwords);
char x [100];
int main (void)
{
size_t i;
for (i = 0; i < sizeof (x); i++) x [i] = (char) i;
for (i = 0; i < 16; i++) {
printf ("Trying %d sum\n", (int) i);
printf ("Done: %d\n", (int) sum ((const uint32_t*) (x + i), 16));
}
return 0;
} Теперь SIGSEGV появлялась на функции
sum, когда i равнялось 1.Расследование
Код функции
sum на удивление большой, так что я покажу только основной цикл..L13:
movdqa (%r8), %xmm2
addq $1, %rdx
addq $16, %r8
cmpq %rdx, %r9
pmovzxdq %xmm2, %xmm1
psrldq $8, %xmm2
paddq %xmm0, %xmm1
pmovzxdq %xmm2, %xmm0
paddq %xmm1, %xmm0
ja .L13Компилятор умён. Слишком умён, как по мне. Он применил набор инструкций SSE (ему было разрешено делать это, потому что я использовал его повсюду и указал
-msse4.2 в командной строке. Этот код одновременно читает четыре значения (movdqa), затем конвертирует их в 64-битный формат в два регистра (две инструкции pmovzxdq и psrldq) и добавляет текущую сумму (%xmm0). После итерации цикла он складывает вместе накопленные значения.Это выглядит как приемлемая оптимизация для случая, когда мы имеем дело с большим количеством слов, но здесь не тот случай. У компилятора не было возможности установить типичное количество итераций цикла, поэтому он оптимизировал код по максимуму, правильно рассудив, что для случая с малым количеством слов и потери от чрезмерной оптимизации тоже будут небольшими. Мы позже проверим, какие тут потери и насколько они большие.
Что вообще в этом коде могло вызвать ошибку? Мы быстро поняли, что это та инструкция movdqa. Как большинство инструкций SSE с доступом к памяти, она требует 16-байтное выравнивание адреса исходного аргумента. Но мы не можем ожидать такого выравнивания от указателя uint32_t, и как тогда вообще использовать эту инструкцию?
Компилятор на самом деле заботится о выравнивании. Перед запуском цикла он вычисляет, сколько слов может быть обработано перед началом цикла.
testq %rsi, %rsi ; %rsi is n
je .L14
movq %rdi, %rax ; %rdi is p
movq %rsi, %rdx
andl $15, %eax
shrq $2, %rax
negq %rax
andl $3, %eaxИли, в более привычном виде:
if (nwords == 0) return 0;
unsigned start_nwords = (- (((unsigned)p & 0x0F) >> 2)) & 3;Он возвращает 0, если
p заканчивается на 0, 1, 2 или 3 в Hex, возвращает 3, если она заканчивается на 4−7, возвращает 2 для диапазона 8−B и 1 для C−F. После обработки этих первых слов мы можем запускать цикл (при условии, что количество оставшихся слов минимум 4, и заботясь об остатках).Короче говоря, этот код выравнивает указатель по 16 байт, но при условии, что он уже выровнен по 4.
Внезапно наш x86 ведёт себя словно RISC: он вылетает с ошибкой, если указатель на uint32_t не выровнен по 4 байта.
Простые решения не подходят
Никакая простая манипуляция с этой функцией не решает проблему. Мы могли бы, к примеру, объявить параметр
p как char* в наивной попытке «объяснить компилятору произвольную природу указателя»: uint64_t sum0 (const char * p, size_t nwords)
{
const uint32_t * q = (const uint32_t *) p;
uint64_t res = 0;
size_t i;
for (i = 0; i < nwords; i++) res += q [i];
return res;
}Или мы можем заменить индексацию арифметикой указателя.
uint64_t sum01 (const uint32_t * p, size_t n)
{
uint64_t res = 0;
size_t i;
for (i = 0; i < n; i++) res += *p++;
return res;
}Или применить оба способа.
uint64_t sum02 (const char * p, size_t n)
{
uint64_t res = 0;
size_t i;
for (i = 0; i < n; i++, p += sizeof (uint32_t))
res += *(const uint32_t *) p;
return res;
}Ни одна из этих модификаций не помогает. Компилятор достаточно умён, чтобы игнорировать весь синтаксический сахар и редуцировать код до основы. Все эти версии вылетают с ошибкой SIGSEGV.
Что говорят стандарты
Это похоже на довольно грязный трюк компилятора. Выполняемая им трансформация программы противоречит обычным ожиданиям программиста для x86. Действительно ли компилятору позволено делать такое? Чтобы ответить на этот вопрос, придётся глянуть в стандарт.
Я не собираюсь глубоко копать различные стандарты C и C++. Посмотрим только один из них, а именно C99, а конкретнее — последнюю публично доступную версию стандарта C99 (2007).
В нём представлена концепция выравнивания:
3.2
выравнивание
требование для объектов определённого типа располагаться на границах элементов памяти с адресами, кратными адресу байта
Эта концепция используется при определении преобразования указателя.
6.3.2.3
Указатель на объект или неполный тип может быть преобразован в указатель на другой объект или неполный тип. Если результирующий указатель неправильно выровнен для указываемого типа, то поведение не определено. В ином случае, при обратном преобразовании результат должен быть равным оригинальному указателю. Когда указатель на объект преобразуется в указатель на символьный тип данных, то результат указывает на младший адресованный байт объекта. Успешное приращение результата, вплоть до размера объекта, даёт указатели на оставшиеся байты объекта.
А также она используется в разыменования указателя.
6.5.3.2 Адрес и операция разыменования
Если указателю было присвоено недопустимое значение, поведение унарного оператора * не определено. 87)87) Среди недопустимых значений для разыменования оператора унарным оператором *: пустой указатель; ненадлежащим образом выровненный адрес для типа указываемого объекта; адрес объекта по окончании его использования.
Если я правильно понимаю эти пункты, преобразование указателей (кроме преобразования чего-либо в
char *) вообще опасное дело. Программа может вывалиться прямо здесь, во время преобразования. Как вариант, конвертация может пройти успешно, но произвести недопустимое значение, которое вызовет сбой программы (или чушь на выходе) во время разыменования. В нашем случае может случиться и то, и другое, если требование выравнивания для uint32_t, исполняемое этим компилятором, отличается от единицы (выравнивание для char*). Поскольку наиболее естественным выравниванием для uint32_t является 4, то компилятор был совершенно прав.Версия sum0, хотя не решает проблему, всё равно лучше первоначальной sum, ведь та требовала, чтобы указатель был уже типа uint32_t*, что требовало преобразования указателя в коде вызова. Это преобразование может вызвать сбой немедленно или произвести недопустимое значение указателя. Давайте отдадим выравнивание под ответственность функции суммы и поэтому заменим sum на sum0.
Эти пункты стандарта объясняют, почему провалились наши попытки решить проблему, играясь с типами указателей и способами их вычисления. Неважно, что мы делаем с указателем, в итоге он преобразуется в uint32_t*, что немедленно сигнализирует компилятору, что указатель выровнен по границе четырёх байтов.
Есть только два подходящих решения.
Отключить SSE
Первое это не столько решение — скорее, уловка. Проблемы с выравниванием на x86 появляются только при использовании SSE, так давайте его отключим. Мы можем сделать это для всего файла, в котором декларируется
sum, а если это неудобно, только для этой конкретной функции.__attribute__ ((target("no-sse")))
uint64_t sum1 (const char * p, size_t nwords)
{
const uint32_t * q = (const uint32_t *) p;
uint64_t res = 0;
size_t i;
for (i = 0; i < nwords; i++) res += q [i];
return res;
}Такой код ещё хуже переносим, чем первоначальный, поскольку в нём используются атрибуты, специфические для GCC и специфические для Intel. Его можно очистить соответствующей условной компиляцией.
#if defined (__GNUC__) && (defined (__x86_64__) || defined (__i386__))
__attribute__ ((target ("no-sse")))
#endifОднако от такого способа на самом деле мало толку, поскольку он всего лишь даёт программе компилироваться на других компьютерах и других архитектурах, но она не обязательно будет там работать. Программа по прежнему может сбоить, если там процессор RISC или если в компиляторе используется другой синтаксис для отключения SSE.
Даже если мы остаёмся в рамках GCC и Intel, кто может дать гарантию, что через десять лет не появится ещё одна архитектура, отличная от SSE? В конце концов, мой первоначальный код мог быть написан 20 лет назад, когда SSE не существовало (первый MMX появился в 1997 году).
Тем не менее, такая программа компилируется в очень аккуратный код:
sum0:
testq %rsi, %rsi
je .L34
leaq (%rdi,%rsi,4), %rcx
xorl %eax, %eax
.L33:
movl (%rdi), %edx
addq $4, %rdi
addq %rdx, %rax
cmpq %rcx, %rdi
jne .L33
ret
.L34:
xorl %eax, %eax
retЭто именно тот код, о котором я думал, когда писал функцию. Думаю, этот код будет работать быстрее, чем код на основе SSE для маленьких размеров вектора, что является нашим случаем с заголовками IP. Позже проведём измерения.
Использование memcpy
Другой вариант — использование функции
memcpy. Эта функция может копировать байты, представляющие число, в переменную соответствующего типа, независимо от выравнивания. И она делает это в полном соответствии со стандартом. Может показаться, что это неэффективно, и 20 лет назад так оно и было. В наше время, однако, совсем необязательно реализовать функцию как вызов процедуры; компилятор может расценить её как собственную функцию языка и заменить на перенос из памяти в регистр (memory-to-register). GCC определённо так делает. Он компилирует следующий код: uint64_t sum2 (const char * p, size_t nwords)
{
uint64_t res = 0;
size_t i;
uint32_t temp;
for (i = 0; i < nwords; i++) {
memcpy (&temp, p + i * sizeof (uint32_t), sizeof (temp));
res += temp;
}
return res;
}в код, похожий на оригинальный SSE, но только использует
movdqu вместо movdqa. Эта инструкция допускает невыровненные данные;, но действует с разной производительностью. На некоторых процессорах она гораздо медленнее movdqa, даже если данные на самом деле выровнены. На других работает практически с такой же скоростью.Другое отличие в сгенерированном коде то, что он даже не пытается выравнивать указатель. Он использует movdqu на оригинальном указателе даже если мог бы выровнять его и затем использовать movdqa. Это означает, что такой код, будучи более универсальным, в итоге может оказаться медленнее оригинального кода на некоторых входных данных.
Такое решение полностью переносимо, его можно использовать где угодно, даже на архитектурах RISC.
Комбинированное решение
Первое решение кажется более быстрым на наших данных (хотя мы ещё не измеряли его), в то время как второе более портативно. Мы можем скомбинировать их вместе:
#if defined (__GNUC__) && (defined (__x86_64__) || defined (__i386__))
__attribute__ ((target ("no-sse")))
#endif
uint64_t sum3 (const char * p, size_t nwords)
{
uint64_t res = 0;
size_t i;
uint32_t temp;
for (i = 0; i < nwords; i++) {
memcpy (&temp, p + i * sizeof (uint32_t), sizeof (temp));
res += temp;
}
return res;
}Этот код скомпилируется в хороший не-SSE цикл на GCC/Intel, но будет по-прежнему выдавать рабочий (и достаточно хороший) код на других архитектурах. Это та версия, которую я собираюсь использовать в моём проекте.
Производимый код для x86 идентичен тому, который получался из sum1.
Измерение скорости
Мы видели, что компилятор имеет полное право сгенерировать код с
movdqa. Насколько хорошо такое решение с точки зрения производительности? Измерим производительность всех наших решений. Сначала сделаем это на полностью выровненных данных (указатель выравнен по границе 16). Значения в таблице приведены в наносекундах на добавляемое слово.| Размер, слов | sum0 (movdga) | sum1 (loop) | sum2 (movdqu) | sum3 (loop, memcpy) |
|---|---|---|---|---|
| 1 | 2,91 | 1,95 | 2,90 | 1,94 |
| 5 | 0,84 | 0,79 | 0,77 | 0,79 |
| 16 | 0,46 | 0,45 | 0,41 | 0,46 |
| 1024 | 0,24 | 0,46 | 0,26 | 0,48 |
| 65536 | 0,24 | 0,45 | 0,24 | 0,45 |
Эта таблица подтверждает, что на очень маленьком количестве слов (1) обычные циклы работают быстрее, чем версии на базе SSE, хотя разница не такая большая (1 наносекунда на слово, а ведь здесь только одно слово).
SSE намного быстрее на большом количестве слов (1024 и больше), и здесь общий итог в выигрыше может быть весьма значительным.
На входных данных среднего размера (вроде 16) скорости практически одинаковые, с небольшим преимуществом SSE (movdqu).
Запустим тест на всех значениях между 1 и 16 и проверим, где находится точка равновесия. Версии sum1 (не-SSE цикл) и sum3 показывают очень похожий результат (что ожидаемо, поскольку код одинаковый; разница в результатах показывает погрешность измерений в районе 0,02 нс). Вот почему на графике представлена только окончательная версия (sum3).
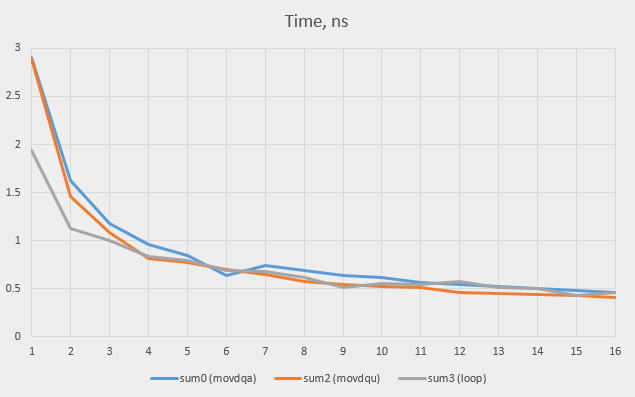
Мы видим, что простые циклы выигрывают у версий SSE при количестве слов до 3, после чего версии SSE начинают брать верх (версия movdqu, как правило, быстрее оригинальной movdqf).
Думаю, что в отсутствие какой-либо дополнительной информации компилятор прав в предположении, что произвольный цикл будет исполняться более трёх раз, так что решение использовать SSE было полностью правильным. Но почему он сразу не перешёл к опции movdqu? Есть ли вообще какая-то причина использовать movdqa?
Мы видели, что когда данные выровнены, версия movdqu работает на той же скорости, что и movdqa, на большом количестве слов, и работает быстрее на малом количестве слов. Последнее можно объяснить меньшим количеством инструкций, которые предваряют цикл (нет необходимости в проверке на выравнивание). Что произойдёт, если мы запустим тест на невыровненных данных? Вот результаты для некоторых вариантов:
| Размер, слов | Смещение 0 | Смещение 1 | Смещение 4 | |||||
|---|---|---|---|---|---|---|---|---|
| movdqa | movdqu | loop | movdqu | loop | movdqa | movdqu | loop | |
| 1 | 2,91 | 2,90 | 1,94 | 2,93 | 1,94 | 2,90 | 2,90 | 1,94 |
| 5 | 0,84 | 0,77 | 0,79 | 0,77 | 0,79 | 0,84 | 0,79 | 0,78 |
| 16 | 0,46 | 0,41 | 0,46 | 0,42 | 0,46 | 0,52 | 0,40 | 0,46 |
| 1024 | 0,24 | 0,26 | 0,48 | 0,26 | 0,51 | 0,25 | 0,25 | 0,47 |
| 65536 | 0,24 | 0,24 | 0,45 | 0,25 | 0,50 | 0,24 | 0,24 | 0,46 |
Как видим, выравнивание даёт только незначительные изменения в скорости, за исключением одного: версия
movdqa начинает немного замедляться (0,52 нс вместо 0,46 нс) при смещении на 4 с количеством 16 слов. Прямой цикл по-прежнему остаётся лучшим решением на малом количестве слов; movdqu — лучшее решение на большом количестве. Компилятор был не прав, используя movdqa. Возможное объяснение в том, что он оптимизирован для старой модели процессора Intel. Инструкция movdqu работала немного медленнее movdqa на процессорах Xeon, даже на полностью выровненных данных. Похоже, теперь это больше не наблюдается, так что компилятор можно упростить (и смягчить требования к выравниванию).Оригинальная функция
Оригинальную функцию для проверки заголовков IP теперь следует переписать следующим образом:
#if defined (__GNUC__) && (defined (__x86_64__) || defined (__i386__))
__attribute__ ((target ("no-sse")))
#endif
_Bool check_ip_header_sum (const char * p, size_t size)
{
const uint32_t * q = (const uint32_t *) p;
uint32_t temp;
uint64_t sum = 0;
memcpy (&temp, &q [0], 4); sum += temp;
memcpy (&temp, &q [1], 4); sum += temp;
memcpy (&temp, &q [2], 4); sum += temp;
memcpy (&temp, &q [3], 4); sum += temp;
memcpy (&temp, &q [4], 4); sum += temp;
for (size_t i = 5; i < size / 4; i++) {
memcpy (&temp, &q [i], 4);
sum += temp;
}
do {
sum = (sum & 0xFFFF) + (sum >> 16);
} while (sum & ~0xFFFFL);
return sum == 0xFFFF;
}Если мы боимся преобразования невыровненного указателя в
uint32_t* (стандарт говорит о неопределённом поведении), то код будет выглядеть следующим образом: #if defined (__GNUC__) && (defined (__x86_64__) || defined (__i386__))
__attribute__ ((target ("no-sse")))
#endif
_Bool check_ip_header_sum (const char * p, size_t size)
{
uint32_t temp;
uint64_t sum = 0;
memcpy (&temp, p, 4); sum += temp;
memcpy (&temp, p + 4, 4); sum += temp;
memcpy (&temp, p + 8, 4); sum += temp;
memcpy (&temp, p + 12, 4); sum += temp;
memcpy (&temp, p + 16, 4); sum += temp;
for (size_t i = 20; i < size; i+= 4) {
memcpy (&temp, p + i, 4);
sum += temp;
}
do {
sum = (sum & 0xFFFF) + (sum >> 16);
} while (sum & ~0xFFFFL);
return sum == 0xFFFF;
}Обе версии выглядят довольно уродливо, особенно вторая. Обе напоминают мне о программировании на чистом ассемблере. Однако именно это правильный способ написания переносимого кода на C.
Интересно, что хотя в наших тестах цикл работал на той же скорости, что и movdqu, на количестве слов 5, но после записи этой функции в один цикл с 0 до size она стала работать медленнее (обычный результат 0,48 нс и 0,83 нс на слово).
Версия C++
C++ позволяет написать ту же функцию в гораздо более читабельном виде, применив некоторые шаблоны. Введём параметризованный тип
const_unaligned_pointer: template class const_unaligned_pointer
{
const char * p;
public:
const_unaligned_pointer () : p (0) {}
const_unaligned_pointer (const void * p) : p ((const char*)p) {}
T operator* () const
{
T tmp;
memcpy (&tmp, p, sizeof (T));
return tmp;
}
const_unaligned_pointer operator+ (ptrdiff_t d) const
{
return const_unaligned_pointer (p + d * sizeof (T));
}
T operator[] (ptrdiff_t d) const { return * (*this + d); }
}; Здесь всего каркас. Настоящее определение должно содержать проверку на равенство, оператор «минус» для двух указателей, оператор «плюс» в другом направлении, некоторые преобразования и, вероятно, другие вещи.
С помощью параметризованного типа наша функция выглядит очень близко к тому, с чего мы начинали:
bool check_ip_header_sum (const char * p, size_t size)
{
const_unaligned_pointer q (p);
uint64_t sum = 0;
sum += q[0];
sum += q[1];
sum += q[2];
sum += q[3];
sum += q[4];
for (size_t i = 5; i < size / 4; i++) {
sum += q[i];
}
do {
sum = (sum & 0xFFFF) + (sum >> 16);
} while (sum & ~0xFFFFL);
return sum == 0xFFFF;
} Из этого получается в точности такой же ассемблерный код, как и в коде с
memcpy и, очевидно, он работает с той же скоростью.Ещё несколько шаблонов
Наш код читает только невыровненные данные, так что класса
const_unaligned_pointer достаточно. Что если бы мы захотели написать его тоже? Мы можем написать класс и для этого, но в данном случае нам нужно два класса: один для указателя, а другой для l-значения, которое получается во время разыменования этого указателя: template class unaligned_ref
{
void * p;
public:
unaligned_ref (void * p) : p (p) {}
T operator= (const T& rvalue)
{
memcpy (p, &rvalue, sizeof (T));
return rvalue;
}
operator T() const
{
T tmp;
memcpy (&tmp, p, sizeof (T));
return tmp;
}
};
template class unaligned_pointer
{
char * p;
public:
unaligned_pointer () : p (0) {}
unaligned_pointer (void * p) : p ((char*)p) {}
unaligned_ref operator* () const { return unaligned_ref (p); }
unaligned_pointer operator+ (ptrdiff_t d) const
{
return unaligned_pointer (p + d * sizeof (T));
}
unaligned_ref operator[] (ptrdiff_t d) const { return *(*this + d); }
}; Опять же, этот код просто демонстрирует идею; требуется многое добавить, чтобы он подходил для использования в продакшне. Попробуем запустить простой тест:
char mem [5];
void dump ()
{
std::cout << (int) mem [0] << " " << (int) mem [1] << " "
<< (int) mem [2] << " " << (int) mem [3] << " "
<< (int) mem [4] << "\n";
}
int main (void)
{
dump ();
unaligned_pointer p (mem + 1);
int r = *p;
r++;
*p = r;
dump ();
return 0;
} Вот его выдача:
0 0 0 0 0
0 1 0 0 0Мы могли бы написать
++ *p;, но это требует определения
operator++ в unaligned_ref.Выводы
- Проблемы с выравниванием относятся не только к процессорам RISC. Из-за SSE они также актуальны на процессорах x86 (как в 32-битном, так и в 64-битном режимах).
- В нашем случае компилятор был прав, используя SSE в сгенерированном коде. Однако он мог задействовать невыровненный доступ — это было бы не только более надёжно, но и быстрее (и скрыло бы проблему, так что сбой программы мог бы произойти когда-нибудь в другой момент).
- Есть преимущество в написании максимально переносимой программы: ваш собственный процессор может внезапно начать вести себя как совершенно другой.
- Существует много кода, написанного двадцать лет и работавшего только под Intel. Этот код может внезапно начать выдавать сбои таким же образом. Есть один практический совет: отключить все возможные расширенные наборы инструкций во время компиляции такого кода — однако, даже это может не помочь.
- Эта история демонстрирует, что в инструментах для покрытия кода есть что-то полезное. Здесь мне повезло, что входные данные заставили весь код исполняться. В следующий раз может быть иначе.
Update
На ветке /r/cpp/ пользователь OldWolf2 заметил, что код проверки контрольной суммы содержит ошибку в последней строчке:
} while (sum & ~0xFFFFL);Он прав: у
0xFFFFL тип unsigned long, который не всегда такой же как uint64_t. Длина long может быть 32 бита, и тогда инверсия битов (обратный код) произойдёт раньше расширения до 64 бит, а реальная константа в тесте будет 0x00000000FFFF0000. Легко подобрать входные данные, где такой тест завершится со сбоем — например, для массива из двух слов: 0xFFFFFFFF и 0x00000001.Мы можем или делать обратный код после перевода в 64 бита:
} while (sum & ~(uint64_t) 0xFFFF);Или, как вариант, произвести сравнение:
} while (sum > 0xFFFF);Интересно, что GCC производит более лаконичный код во втором случае. Вот версия с тестом:
.L15:
movzwl %ax, %edx
shrq $16, %rax
addq %rdx, %rax
movq %rax, %rdx
xorw %dx, %dx
testq %rdx, %rdx
jne .L15А вот версия со сравнением:
.L44:
movzwl %ax, %edx
shrq $16, %rax
addq %rdx, %rax
cmpq $65535, %rax
ja .L44Комментарии приветствуются ниже или на reddit.
