[Перевод] ИИ DALL E mini склонен генерировать женщин в сари

В ответе на пустой запрос ставшая вирусной DALL У mini часто генерирует фото женщин в сари. Почему? Пытаемся разобраться под катом к старту флагманского курса по Data Science.
Как и большинство людей постоянно в сети, бразильский сценарист Фернандо Марес был очарован изображениями, созданными моделью ИИ DALL·E mini. Эта система ИИ стала вирусной сенсацией, она создаёт изображения на основе, казалось бы, случайных и причудливых запросов пользователей, таких как «Леди Гага в образе Джокера», «Капибара подала иск на Илона Маска» и многих других.
Марес — опытный хактивист — начал использовать DALL·E mini в начале июня. Но вместо того чтобы вводить текст конкретного запроса, он оставил поле пустым. Очарованный результатами, которые кажутся случайными, Марес снова и снова запускал пустой поиск — и заметил нечто странное: почти каждый раз, когда он запускал пустой запрос, DALL·E mini генерировал портреты темнокожих женщин в сари — распространённой в Южной Азии одежде.
Марес тысячи раз опрашивал DALL·E mini, вводя пустую команду, чтобы выяснить, было ли это простым совпадением. Затем он пригласил своих друзей по очереди на его компьютере, чтобы одновременно генерировать изображения на 5 вкладках браузера. Он сказал, что продолжал без перерыва почти 10 часов и создал обширное хранилище из более чем 5000 уникальных изображений и поделился 1,4 ГБ необработанных мини-данных DALL·E.
На большинстве этих изображений — темнокожие женщины в сари. DALL-E mini, кажется, одержим этим очень специфическим типом изображения, но почему? По мнению исследователей ИИ, ответ может быть связан с некачественной маркировкой и неполными наборами данных.
DALL·E mini разработан артистом по искусственному интеллекту Борисом Даймой и вдохновлён DALL·E 2 — программой OpenAI, которая по тексту генерирует гиперреалистичные рисунки и изображения. От медитирующих кошек до роботов-динозавров, которые сражаются с грузовиками-монстрами в Колизее. Эти изображения взорвали мозги, а некоторые люди назвали её угрозой для иллюстраторов-людей. Признавая возможность неправомерного использования DALL-E, OpenAI ограничил доступ к своей модели до отобранной группы в 400 исследователей.
Дайма был очарован созданным DALL·E 2 арт-объектами и «хотел иметь версию с открытым исходным кодом, доступную и улучшаемую всеми», как рассказал он Rest of World. Итак, он пошёл дальше, создал урезанную версию модели с открытым исходным кодом и назвал её DALL·E mini. Он запустил её в июле 2021 года, с тех пор модель обучается и совершенствует результаты.
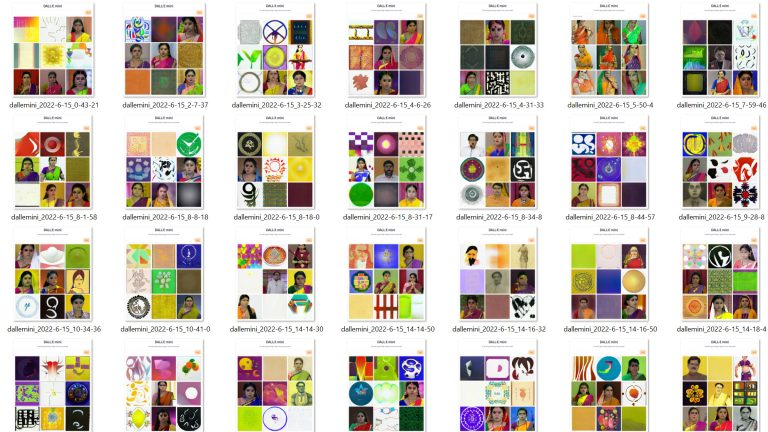 DALL.E 2 mini создаёт мини-изображения для пустых запросов
DALL.E 2 mini создаёт мини-изображения для пустых запросов
DALL·E mini стала вирусным интернет-феноменом. Её изображения не такие чёткие, как изображения из DALL·E 2, заметно искажены и размыты, но система производит свободную визуализацию. Он вдохновил карикатуру в журнале New Yorker. У дескриптора Weird Dall-E Creations в Твиттере более 730 000 подписчиков.
Дайма сообщил, что модель генерирует около 5 миллионов запросов в день и сегодня работает над тем, чтобы не отставать от экстремально растущего интереса пользователей. DALL.E mini не имеет никакого отношения к OpenAI и с 20 июня по настоянию OpenAI переименована в модель с открытым исходным кодом Craiyon.
Дайма признаёт, что озадачен причиной генерации изображения темнокожих женщин в сари на пустых запросах, но подозревает, что она связана с набором данных. «Это довольно интересно, и я не понимаю, почему это происходит», — сказал Дайма после просмотра изображений. — Также возможно, что этот тип изображения широко представлен в наборе данных, возможно, также с короткими подписями». Rest of World также обратился к OpenAI — создателю DALL·E 2, чтобы узнать, есть ли у них информация, но пока мы не получили ответа.
Модели с искусственным интеллектом, такие как DALL-E mini, учатся рисовать, анализируя миллионы изображений из интернета с соответствующими подписями. Мини-модель DALL·E разработана на трёх основных наборах данных: Conceptual Captions, который содержит 3 миллиона пар изображений и подписей; Conceptual 12M, который содержит 12 миллионов пар изображений и подписей, и корпус OpenAI, содержащий около 15 миллионов изображений.
Соавтор DALL·E mini Педро Куэнка отметил, что их модель также обучалась с использованием нефильтрованных данных из интернета, что открывает неизвестные и необъяснимые отклонения в наборах данных, которые могут просачиваться в модели генерации изображений.
Дайма не единственный, кто подозревает базовый набор данных и модель обучения. В поисках ответов Марес обратился к популярному дискуссионному форуму по машинному обучению Hugging Face, где размещён DALL·E mini. Сообщество специалистов по компьютерным наукам высказало своё мнение, а некоторые люди неоднократно предлагали правдоподобные объяснения: ИИ мог быть обучен на миллионах изображений людей из Южной и Юго-Восточной Азии, которые «не размечены» в корпусе обучающих данных. Дайма оспаривает эту теорию, поскольку, по его словам, ни одно изображение из набора данных не имеет подписи.
«Обычно у систем машинного обучения есть обратная проблема — они на самом деле не включают достаточно фотографий небелых людей».
Майкл Кук, который в настоящее время исследует пересечение искусственного интеллекта, творчества и игрового дизайна в Университете королевы Марии в Лондоне, поставил под сомнение теорию, что набор данных включает слишком много фотографий людей из Южной Азии. «Обычно у систем машинного обучения есть обратная проблема — они на самом деле не включают достаточно фотографий небелых людей», — сказал он.
У Кука есть собственная теория о противоречивых результатах DALL·E mini. «Одна мысль, которая пришла мне в голову во время чтения, заключается в том, что многие из этих наборов данных удаляют неанглийский текст, а также информацию о конкретных людях, то есть имена собственные», — рассказал Кук.
«То, что мы наблюдаем, — странный побочный эффект некоторой фильтрации или предварительной обработки, когда изображения, например, индийских женщин фильтруются запрещающим списком с меньшей вероятностью, или текст с описанием изображения удаляется и они добавляются в набор данных без прикреплённых меток». Например, если подписи были на хинди или другом языке, вполне возможно, что при обработке данных текст мог быть загрязнён, в результате у изображения нет подписи. «Я не могу сказать это точно — это просто теория, которая пришла мне в голову при изучении данных».
Предубеждения в системах ИИ универсальны, и даже хорошо финансируемые инициативы крупных технологий, такие как чат-бот Tay от Microsoft и инструмент рекрутинга от Amazon, уступили этой проблеме. На самом деле, модель преобразования текста в изображение Google, Imagen, и DALL.E 2 от OpenAI явно показывают, что могут воссоздавать вредные предубеждения и стереотипы, как и DALL.E. mini.
Кук был ярым критиком того, что он считает взращиваемой грубостью и механическими разоблачениями, которые игнорируют предубеждения как неизбежную часть новых моделей ИИ. Вот что он сказал: «Хотя то, что новая технология позволяет людям получать массу удовольствия, похвально, я думаю, что с этой технологией, которую мы используем, возникают серьёзные культурные и социальные проблемы, которые мы не очень понимаем».
Дайма, создатель DALL·E mini, признаёт, что модель всё ещё находится в стадии разработки и степень её предвзятости ещё предстоит полностью задокументировать. «Модель вызвала гораздо больший интерес, чем я ожидал», — делится Дайма.
Дайма хочет, чтобы код модели оставался открытым и его команда могла быстрее изучить её ограничения и погрешности: «Я думаю, что общественности интересно знать о том, что возможно, чтобы люди могли критически относиться к медиа, которые они получают в виде изображений, в той же степени, в какой медиа воспринимаются в виде новостей».
Между тем загадка продолжает оставаться без ответа. «Я многому учусь, просто наблюдая за тем, как люди используют эту модель, — подметил Дайма. — Когда она пуста, это серая зона, поэтому всё ещё нужно исследовать более детально».
Марес сказал, что людям важно узнать о возможном вреде, казалось бы, забавных систем искусственного интеллекта, таких как DALL-E mini. Тот факт, что даже Дайма не может понять, почему система выдаёт эти изображения, усиливает его опасения. «Это то, о чем пресса и критики говорили годами: эти вещи непредсказуемы, их не контролируют».
А пока авторы новой нейросети разбираются с её заблуждениями, мы поможем вам прокачать навыки или с самого начала освоить актуальную в любое время профессию:
Выбрать другую востребованную профессию.

