[Перевод] Хаос-инжиниринг, часть 3: Методы и инструменты

Мы становимся тем, что мы лицезреем. Сначала мы формируем инструменты, потом инструменты формируют нас.—Маршал Маклюэн
Хотелось бы искренне поблагодарить и выразить признательность моему хорошему другу Рикардо Суэйрасу за его обзор, вклад и за то, что не давал мне бросить эту статью недописанной. Рикардо, ты просто легенда!
Важно помнить, что хаос-инжиниринг — это не когда выпускаешь на свободу мартышек и без разбору вводишь отказы. Хаос-инжиниринг — это четко определенная, формализованная методика экспериментирования.
«Хаос-инжиниринг включает тщательное наблюдение, суровый скептицизм по отношению к объекту наблюдения, поскольку когнитивные предположения искажают интерпретации результатов. Эта методика подразумевает формулировку гипотез через индукцию, основанную на подобных наблюдениях; экспериментальное и основанное на измерениях тестирование выводов, сделанных из подобных гипотез; корректировку или отказ от гипотез, основанных на результатах экспериментов»—Wikipedia
Хаос-инжиниринг начинается с понимания стабильного состояния системы, с которой вы имеете дело, последующую формулировку гипотезы и, наконец, эксперимент, который подтверждает ее, помогая увеличить запас прочности системы.
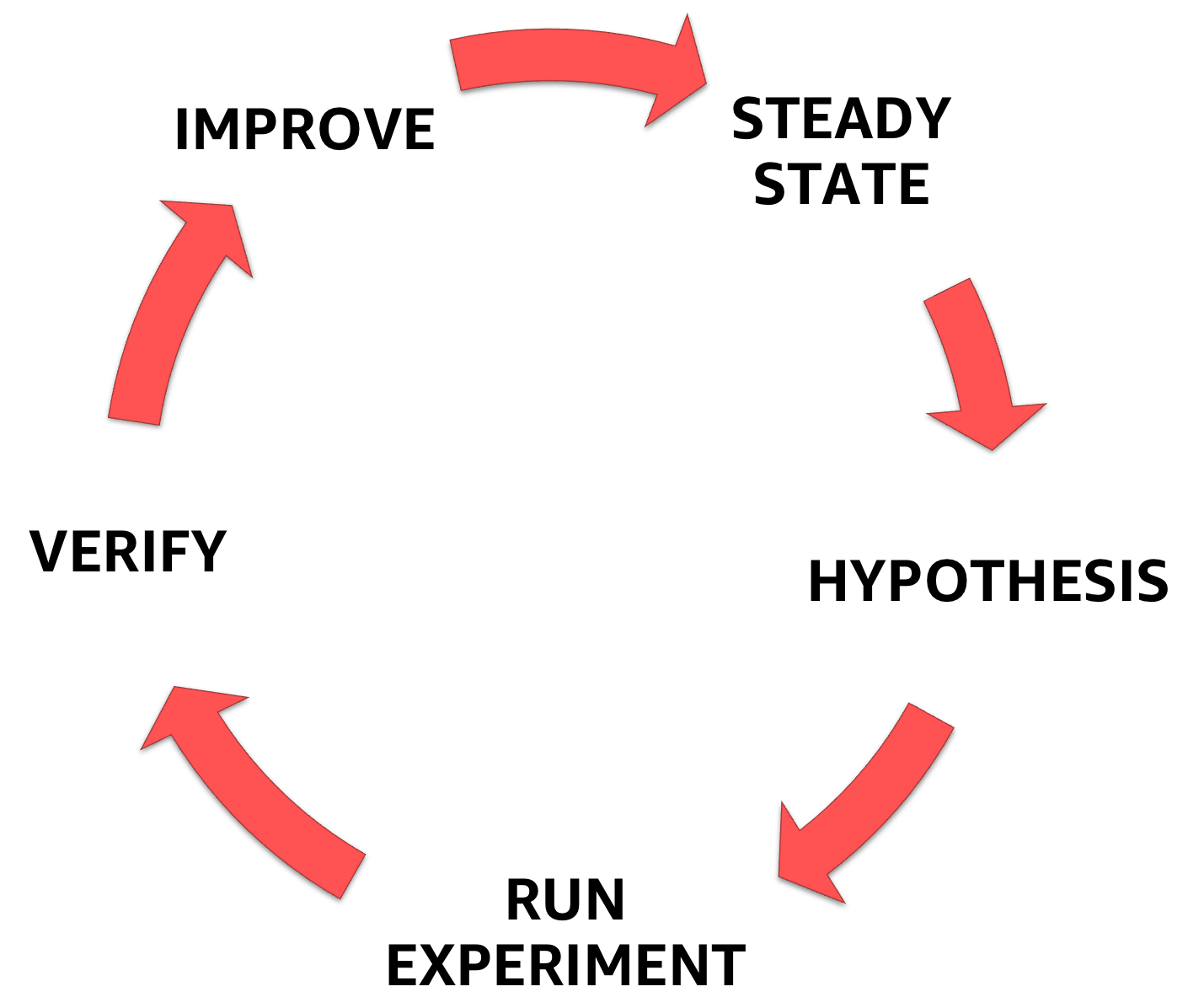
Фазы хаос-инжиниринга
В первой части серии статей я представил хаос-инжиниринг и обсудил каждый шаг описанной выше методики.
Во второй части — разобрал сферы, в которые надо инвестировать, когда проектируете эксперименты по хаос-инжинирингу, и как выбирать верные гипотезы.
В этой, третьей части я сосредоточусь на самом эксперименте и представлю подборку инструментов и методов, которые покрывают широкий спектр введения отказов.
Список — не исчерпывающий, но для начала, и чтобы дать пищу для размышлений, его должно хватить.
Введение отказа — что это и для чего нужно?
Введение отказа служит для проверки, соответствует ли ответ системы спецификациям при нормальных условиях нагрузки. Впервые эту технику применили, когда внедряли отказы на уровне «железа» — на уровне контактов, путем изменения электрических сигналов на устройствах.
В программировании введение отказов помогает улучшить устойчивость системы ПО и позволяет исправлять недостатки в устойчивости к потенциальным отказам в системе. Это называется устранением отказов. Также он помогает оценить ущерб от отказа — т.е. радиус поражения, — еще до того, как отказ случится в производственной среде. Это называется прогнозированием неисправностей.
Введение отказов имеет несколько ключевых преимуществ, помогая:
- понимать и практиковать ответы на случайности и инциденты.
- понимать эффекты реальных отказов.
- понимать эффективность и ограничения механизмов отказоустойчивости.
- устранять ошибки проектирования и обнаруживать единые точки отказа.
- понимать и улучшать наблюдаемость системы.
- понимать радиус поражения отказов и сужать его.
- понимать распространение ошибки между компонентами системы.
Категории введения отказов
Существует 5 категорий введения отказа: на уровне (1) ресурса; (2) сети и зависимостей; (3) приложения, процесса и сервиса; (4) инфраструктуры; и (5) человеческом уровне**.
Далее я рассмотрю каждую из категорий и приведу пример введения отказов для каждой из них. Еще я рассмотрю пример введения отказов и инструментов оркестрации типа «все в одном».
**Важно! В этом посте я не затрагиваю введение отказов на человеческом уровне, но рассмотрю его в следующем.
1 — Введение отказа на уровне ресурса, aka нехватка ресурсов.
Да, облачные технологии приучили нас к тому, что ресурсы практически неограничены, но спешу разочаровать вас: они все же не бесконечны. Экземпляр, контейнер, функция и проч. — вне зависимости от абстракции, ресурсы в конце концов заканчиваются. Выход за грани допустимого, максимальное исчерпание ресурсов называется истощением.

Нехватка ресурсов имитирует атаку типа «отказ в обслуживании», только не обычную, чтобы внедриться в намеченный сервер. Это введение отказов, возможно распространено, потому, наверное, что в применении не сложно.
Истощая ресурсы ЦПУ, памяти и ввода/вывода
Один из моих любимых инструментов — stress-ng, переписка оригинального инструмента нагрузочного тестирования, за авторством Амоса Уотерленда.
Со stress-ng можно вводить отказы, нагружая различные физические подсистемы компьютера, также как и управляя интерфейсами ядра системы, используя стресс-тесты. Доступны следующие стресс-тесты: ЦПУ, кэш ЦПУ, устройство, ввод/вывод, прерывание, файловая система, память, сеть, ОС, конвейер, планировщик и ВМ. Man-страницы включают полное описание всех доступных стресс-тестов, а таких всего 220!
Ниже — несколько практических примеров, как использовать stress-ng:
Нагрузка на ЦПУ matrixprod дает нужный микс операций с памятью, кэшем и плавающей запятой. Это, пожалуй. лучший способ хорошенько разогреть ЦПУ.
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60sНагрузка iomix-bytes пишет N-байты для каждого процесса-обработчика iomix; по умолчанию задан 1 Гб, и он идеален для выполнения стресс-теста вводы/вывода. В этом примере я задам 80% свободного места файловой системы.
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60svm-bytes отлично подходит для стресс-тестов памяти. В этом примере stress-ng запускает 9 стресс-тестов виртуальной памяти, которые в час совокупно потребляют 90% доступной памяти. Т.о., каждый тресс-тест потребляет 10% доступной памяти.
❯ stress-ng --vm 9 --vm-bytes 90% -t 60sНехватка дискового пространства на жестких дисках
dd — это утилита командной строки, собранная для того, что конвертировать и копировать файлы. Однако dd умеет читать и/или писать из файлов особых устройств типа /dev/zero и /dev/random для таких задач, как резервное копирование загрузочного сектора жесткого диска и получение фиксированного объема случайных данных. Т.о., ее можно использовать для введения отказов на сервере и имитации переполнения диска. У вас файлы журнала переполняли сервер и роняли приложение? Так вот, dd поможет — и сделает больно!
Используйте dd очень осторожно. Введете не ту команду — и данные на харде сотрутся, уничтожаться или перепишутся!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &Подтормаживание API приложений
Производительность, устойчивость и масштабируемость API имеют большое значение. API вообще жизненно необходимы для сборки приложений и роста бизнеса.
Нагрузочное тестирование — отличный способ проверить приложение, прежде чем оно попадет в производственную среду. Также это классный метод стрессовой нагрузки, поскольку зачастую вскрывает исключения и ограничения, которые при иных обстоятельствах остались бы невидимы до встречи с реальным трафиком.
wrk — это инструмент для сбора контрольных показателей HTTP, создающий значительную нагрузку на системы. Особенно люблю влупить проверки доступности API, особенно если речь идет о проверке работоспособности, потому что они вскрывают много чего относительно проектировочных решений на уровне кода разработчика: как настроен кэш? как реализовано ограничение скорости? отдает ли система приоритет проверкам работоспособности относительно балансировщиков нагрузки?
Вот с чего можно начать:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/healthЭта команда запускает 12 потоков и держит открытыми 400 соединений по HTTP в течение 20 секунд.
2 — Введение отказов на уровне сети и зависимостей
Книга Питера Дойча »8 заблуждений распределенных вычислений» (The Eight Fallacies of Distributed Computing) — это свод предположений, которые разработчики допускают, проектируя распределенные системы. А потом прилетает ответочка в виде недоступности, и приходится все переделывать. Эти ошибочные предположения звучат так:
- Сеть надежна.
- Задержка равна 0.
- Пропускная способность бесконечна.
- Сеть безопасна.
- Топология не меняется.
- Администратор всего один.
- Стоимость передачи 0.
- Сеть однородна.
Этот список — хорошая отправная точка для выбора введения отказов, если проверяете, выдержит ли ваша распределенная система отказ сети.
Введение задержки, потери и обрыва сети
Введение задержки, потери или обрыва сети
tc (контроль трафика) — инструмент командной строки Linux, используемый для конфигурации пакетного планировщика ядра Linux. Он определяет, как пакеты выстраиваются в очередь на передачу и принятие в сетевом интерфейсе. Операции включают постановку в очередь, определение политики, классификацию, планировку, формирование и потери.
tc можно использовать для имитации задержки и потери пакета для приложений UDP или TCP или ограничения использования ширины полосы определенного сервиса — чтобы имитировать условия интернет-трафика.
— введение задержки в 100 мс
#Start
❯ tc qdisc add dev etho root netem delay 100ms
#Stop
❯ tc qdisc del dev etho root netem delay 100ms— введение задержки в 100 мс с дельтой в 50 мс
#Start
❯ tc qdisc add dev eth0 root netem delay 100ms 50ms
#Stop
❯ tc qdisc del dev eth0 root netem delay 100ms 50ms— повреждение 5% сетевых пакетов
#Start
❯ tc qdisc add dev eth0 root netem corrupt 5%
#Stop
❯ tc qdisc del dev eth0 root netem corrupt 5%— потеря 7% пакетов с 25-процентной корреляцией
#Start
❯ tc qdisc add dev eth0 root netem loss 7% 25%
#Stop
❯ tc qdisc del dev eth0 root netem loss 7% 25%Важно! 7% достаточно, чтобы не упало приложение TCP.
Играя с »/etc/hosts» — статической таблицей поиска для имен узлов
/etc/hosts — простой текстовый файл, который связывает IP-адреса с именами узлов, по строчке на адрес. Каждому узлу требуется одна строка, содержащая следующую информацию:
IP_address canonical_hostname [aliases...]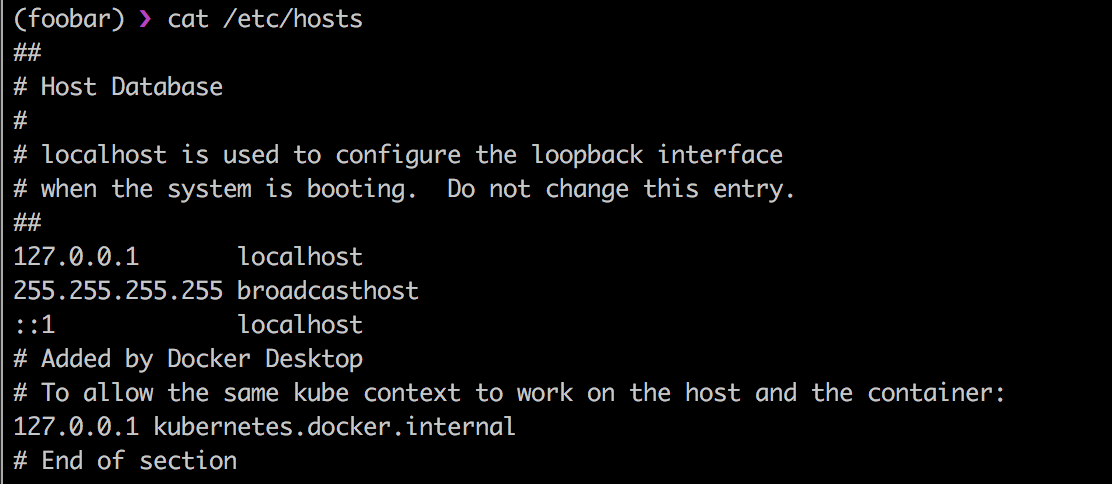
Файл hosts — одна из нескольких систем, которые обращаются к сетевым узлам в компьютерной сети и переводят понятные людям имена узлов в IP-адреса. И да, вы угадали: благодаря ему удобно обманывать компьютеры. Вот несколько примеров:
— Заблокировать доступ к API DynamoDB для инстанса ЕС2
#Start
# make copy of /etc/hosts to /etc/host.back
❯ cp /etc/hosts /etc/hosts.back
❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts
#Stop
# copy back the old version /etc/hosts
❯ cp /etc/hosts.back /etc/hosts— Заблокировать доступ к API EC2 из инстанса ЕС2
#Start
# make copy of /etc/hosts to /etc/host.back
❯ cp /etc/hosts /etc/hosts.back
❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts
#Stop
# copy back the old version /etc/hosts
❯ cp /etc/hosts.back /etc/hostsСмотрите вживую: сначала API ЕС2 доступен и ec2 describe-instances успешно возвращается.
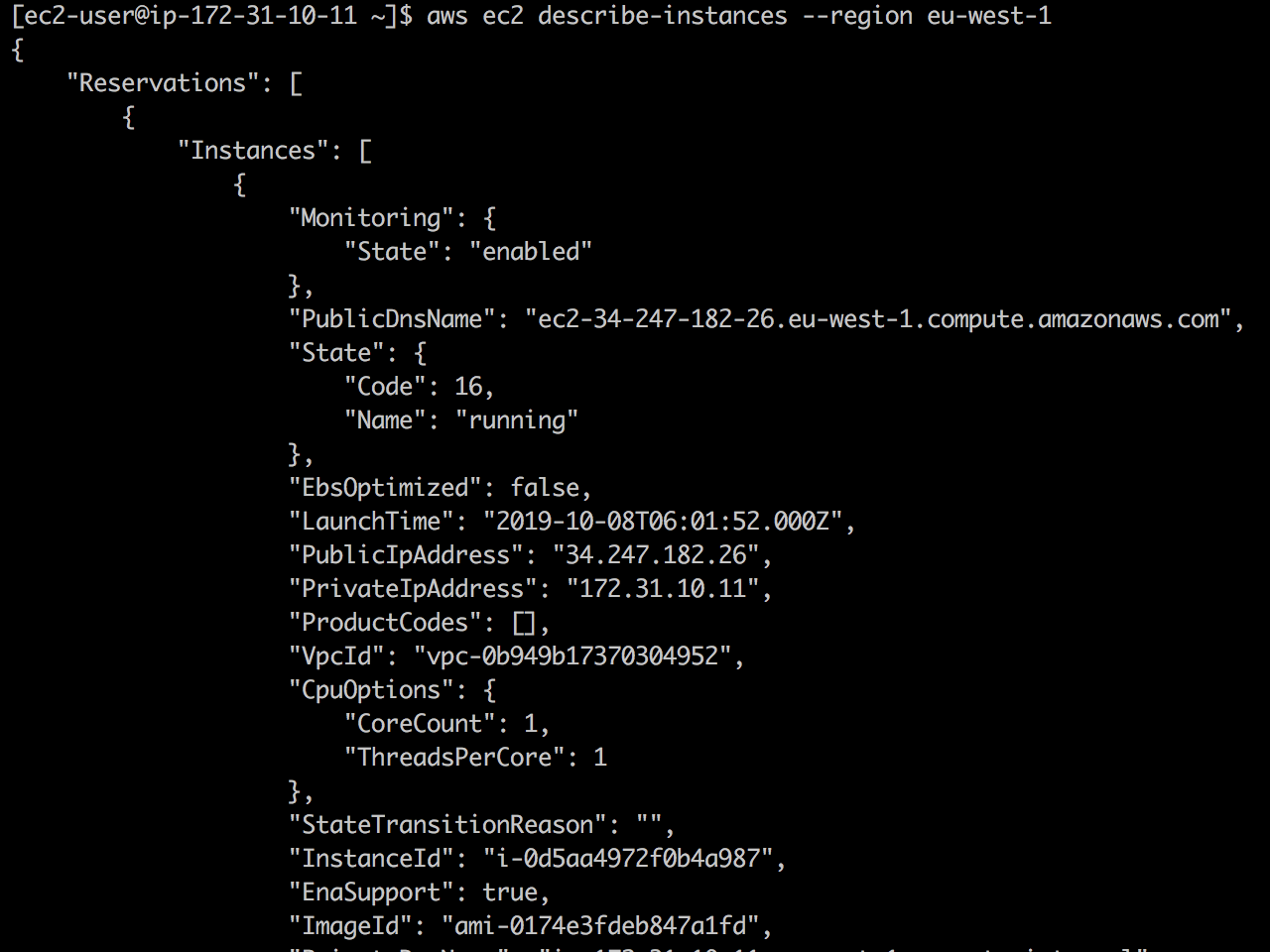
Как только я добавил 127.0.01 ec2.eu-west-1.amazonaws.com к /etc/hosts, и вызов API ЕС2 падает.

Разумеется, это работает для всех API AWS.
Рассказал бы я вам анекдот про DNS…

… но, боюсь, до вас дойдет только на вторые сутки. В смысле, через 24 часа.
21 октября 2016 года из-за DDoS атаки Dyn приличное число платформ и сервисов в Европе и Северной Америке оказались недоступными. Согласно докладу ThousandEyes о производительности DNS по всему миру за 2018 год, 60% предприятий и SaaS-провайдеров все еще полагаются на единичный источник DNS-провайдера и, т.о., становятся уязвимыми перед сбоями DNS. А поскольку без DNS интернета не будет, здорово будет симулировать отказ DNS, чтобы оценить вашу устойчивость к ближайшему отказу DNS.
Blackholing — это метод, при помощи которого традиционно снижают ущерб DDoS атаки. Плохой сетевой трафик направляется в «черную дыру» и сбрасывается в void. Версия /dev/null для работы в сети :-) Можно использовать его для имитации потери сетевого трафика или протокола, того же DNS, скажем.
Для этой задачи нужен инструмент iptables, который используется для настройки, поддержания и проверки IP-пакета в ядре Linux.
Чтобы прогнать DNS-трафик через blackhole, попробуйте вот что:
#Start
❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP
❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP
#Stop
❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP
❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROPВведение отказов с использованием Toxiproxy.
Есть у инструментов Linux вроде tc и iptables одна —, но не единственная — серьезная проблема. Они требуют разрешение root для исполнения, а это создает проблемы для некоторых организаций и сред. Прошу любить и жаловать — Toxiproxy!
Toxiproxy — это ТСР-прокси с открытым исходным кодом, разработанный командой инженеров Shopify. Он помогает имитировать хаотичные сетевые и системные условия или реальные системы. Поместите его между различными компонентами архитектуры, как показано ниже.
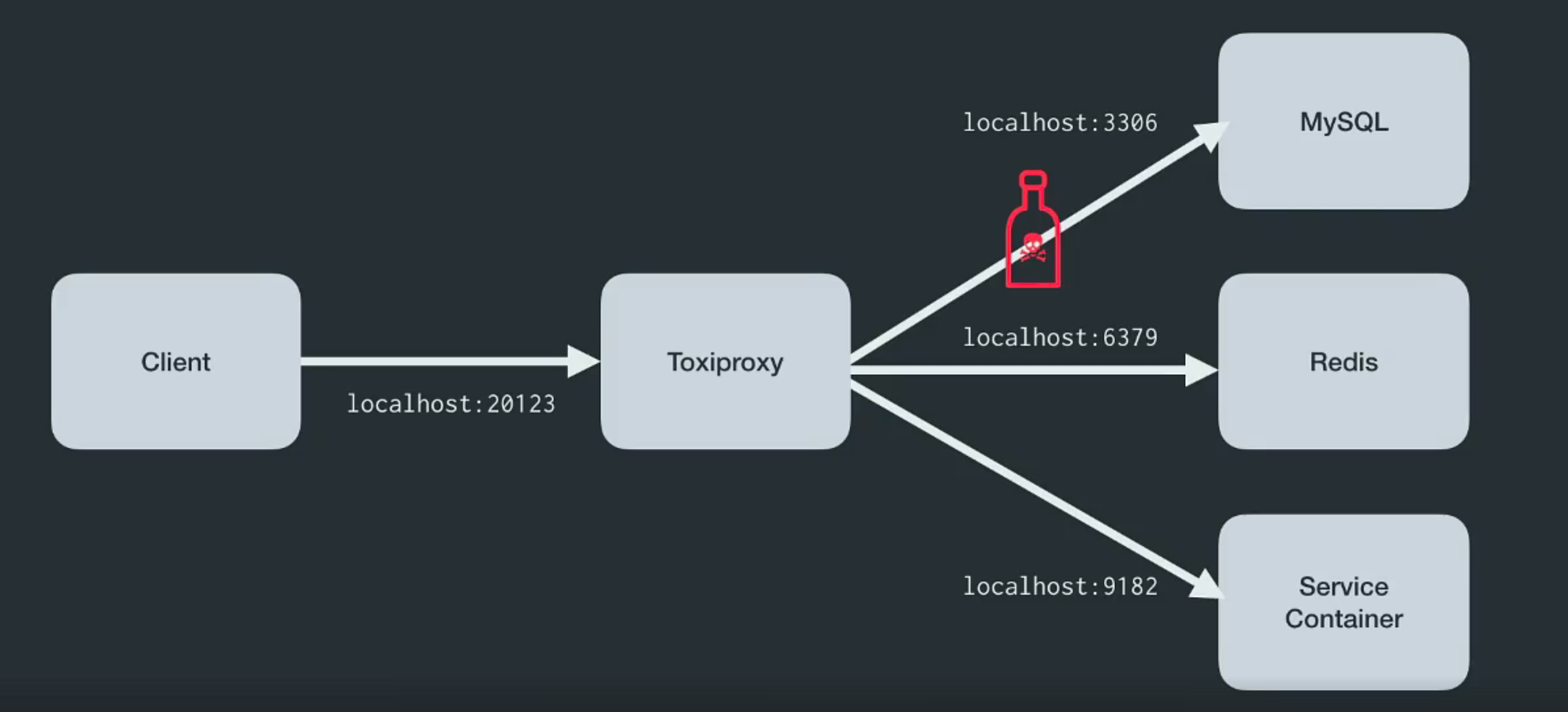
Он создан специально для тестирования, CI и сред разработки, и вносит предопределенную или случайную путаницу, которая управляется через настройки. Toxiproxy использует toxics для манипуляции связями между клиентом и кодом разработчика, и его можно конфигурировать через API HTTP. А еще к нему в комплекте идет достаточное для начала работы количество toxics.
Нижеприведенный пример показывает, как Toxiproxy работает с клиентским кодом toxics, вводя задержку в 1000 мс в связь между моим клиентом Redis, redis-cli и самим Redis.
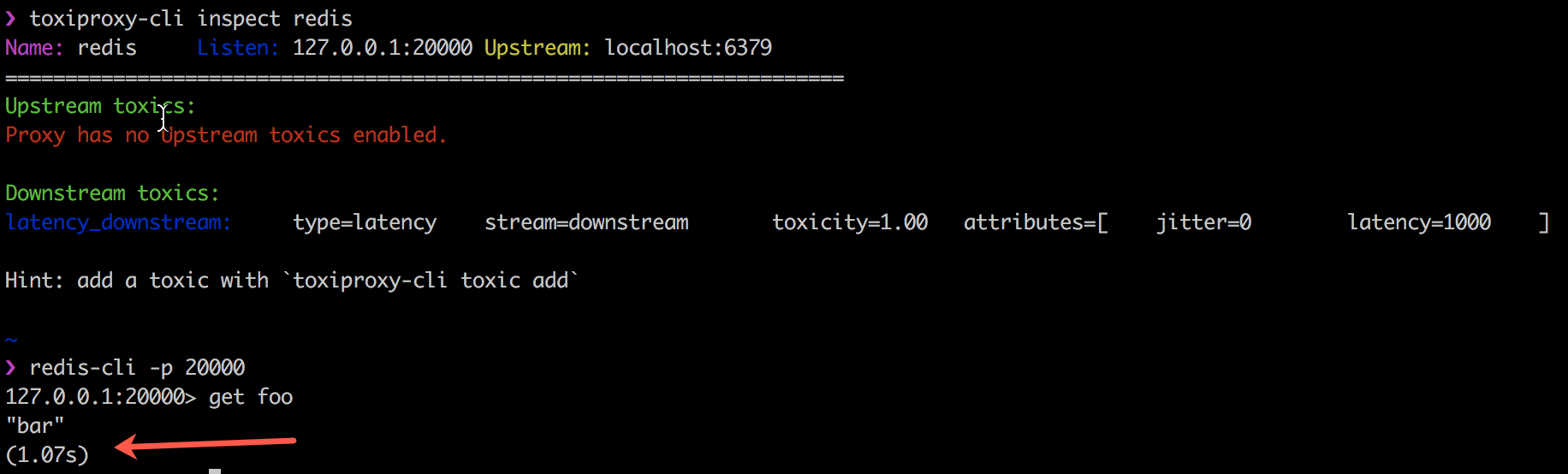
Toxiproxy успешно используется Shopify во всех производственных средах и средах разработки с октября 2014 года. Больше информации — у них в блоге.
3 — Введение отказов на уровне приложения, процесса и сервиса
ПО падает. Это факт. И как вы поступаете? Следует ли логиниться через SSH на сервере и перезапускать давший сбой процесс? Системы контроля за процессом обеспечивают функции контроля состояния или изменения состояния типа start, stop, restart. Системы контроля обычно применяются для того, чтобы обеспечить стабильный контроль процесса. systemd — как раз такой инструмент, обеспечивающий базовые кирпичики управления процессом для Linux. Supervisord предлагает контроль нескольких процессов на операционных системах типа UNIX.
Когда разворачиваете приложение, следует использовать эти инструменты. Это, безусловно, хорошая практика — тестировать ущерб от убийства критически важных процессов. Убедитесь, что вам приходят оповещения и что процесс перезапускается автоматически.
— убить процессы Java
❯ pkill -KILL -f java
#Alternative
❯ pkill -f 'java -jar'— убить процессы Python
❯ pkill -KILL -f pythonКонечно же, можно использовать команду pkill, чтобы убить довольно много других процессов, запущенных в системе.
Введение отказов базы данных
Если есть извещения об отказе, которые не любят получать операторы, то это те, которые относятся к отказам базы данных. Данные — на вес золота, и потому всякий раз, как падает БД, растет риск потерять данные клиента.

Будет просто легкая и безопасная поддержка. И-и-и-и… все упало
Порой способность восстановить данные и как можно быстрее привести БД в рабочее состояние решает будущее компании. К несчастью, также не всегда легко подготовиться к различным режимам отказа БД — и многие из них всплывут только в производственной среде.
Однако если вы используете Amazon Aurora, можно проверить устойчивость к отказам кластера БД Amazon Aurora, используя запросы введения отказа.
Введение отказа Amazon Aurora
Запросы на введение отказа выпускаются как команды SQL к инстансу Amazon Aurora и позволяют планировать имитацию одного из следующих событий:
- Отказ пишущего ли читающего инстанса БД.
- Отказ Aurora Replica.
- Отказ диска.
- Перегрузка диска.
Посылая запрос на введение отказа, надо также указать количество времени, в течение которого будет имитироваться событие отказа.
— вызвать отказ инстанса Amazon Aurora:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];— имитировать отказ Aurora Replica:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE
[ TO ALL | TO "replica name" ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };— имитировать отказ диска для кластера БД Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE
[ IN DISK index | NODE index ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };— имитировать отказ диска для кластера БД Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION
BETWEEN minimum AND maximum MILLISECONDS
[ IN DISK index | NODE index ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };Отказы в мире бессерверных приложений
Введение отказа может стать настоящим вызовом, если вы используете бессерверные компоненты, поскольку бессерверно управляемые сервисы типа WAS Lambda нативно не поддерживают введение отказов.
Введение отказов в функции Lambda
Чтобы разобраться в этой проблеме, я написал небольшую библиотеку python и прослойку lambda — для введения отказов в AWS Lambda. В настоящий момент и то, и то поддерживает задержку, ошибки, исключения и введение кода ошибки НТТР. Введение отказа достигается путем настройки AWS SSM Parameter Store следующим образом:
{
"isEnabled": true,
"delay": 400,
"error_code": 404,
"exception_msg": "I really failed seriously",
"rate": 1
}Можно добавить декоратор python в функцию handler, чтобы ввести отказ.
— сгенерировать исключение:
@inject_exception
def handler_with_exception(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}
>>> handler_with_exception('foo', 'bar')
Injecting exception_type with message I really failed seriously a rate of 1
corrupting now
Traceback (most recent call last):
File "", line 1, in
File "/.../chaos_lambda.py", line 316, in wrapper
raise _exception_type(_exception_msg)
Exception: I really failed seriously — ввести код ошибки «неверный НТТР»:
@inject_statuscode
def handler_with_statuscode(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}
>>> handler_with_statuscode('foo', 'bar')
Injecting Error 404 at a rate of 1
corrupting now
{'statusCode': 404, 'body': 'Hello from Lambda!'}— ввести задержку:
@inject_delay
def handler_with_delay(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}
>>> handler_with_delay('foo', 'bar')
Injecting 400 of delay with a rate of 1
Added 402.20ms to handler_with_delay
{'statusCode': 200, 'body': 'Hello from Lambda!'}Жмакните здесь, чтобы узнать больше об этой библиотеке питон.
Введение отказа в исполнение Lambda через ограничение параллелизма
Lambda по умолчанию использует в целях безопасности регулировку параллельных исполнений всех функций в определеннном регионе, на аккаунт. Параллельные исполнения относятся к нескольким исполнениям кода функции, происходящих в любой отдельно взятый момент времени. Они используются для масштабирования вызов функции к входящему запросу. Но оно может служить и для обратной цели: остановки исполнения Lambda.
❯ aws lambda put-function-concurrency --function-name --reserved-concurrent-executions 0 Эта команда снизит параллелизм до нуля, провоцируя отказы запросов с ошибкой типа «торможение» — код неисправности 429.
Thundra — трассировка бессерверных передач
Thundra — это инструмент наблюдения за бессерверными приложениями, имеющий встроенную способность вводить отказы в бессерверные приложения. Он делает обработчики-обертки для введения отказов типа «отсутствие обработчика ошибок» — для операций с DynamoDB, «отсутствие нейтрализации ошибок» — для источника данных, или «отсутствие тайм-аута в исходящих НТТР-запросах». Я сам его не пробовал, но в этом посте за авторством Янь Чуи и в этом великолепном видео Марши Вильяльба процесс неплохо описывается. Выглядит многообещающе.
И в заключении раздела о бессерверных приложениях скажу, что о трудностях хаос-инжиниринга применительно к бессерверным приложениям у Янь Чуи есть отличная статья. Всем рекомендую к прочтению.
4 — Введение отказов на уровне инфраструктуры
С введения отказов на уровне инфраструктуры все и началось — как для Amazon, так и для Netflix. Введение отказов на уровне инфраструктуры — от отключения целого дата-центра до остановки инстансов в случайном порядке — осуществить, наверное, проще всего.
И, естественно, первым на ум приходит пример с «обезьяной хаоса».
Остановка инстансов EC2, выбранных случайно в некоторой зоне доступности.
В пору становления Netflix хотел ввести жесткие архитектурные правила. Он развернул свою «обезьяну хаоса» как одно из первых приложений на AWS, чтобы установить автомасштабируемые stateless-микросервисы — в том смысле, что любой инстанс можно уничтожить или заменить автоматически, не вызывая потерь состояния совсем. «Обезьяна хаоса» позаботилась, чтобы никто это правило не нарушил.
Следующий сценарий — аналогичный «обезьяне хаоса» — это остановка любого инстанса в случайном порядке, в конкретной зоне доступности в пределах одного региона.
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")import boto3
import random
REGION = 'eu-west-1'
def stop_random_instance(az, tag_name, tag_value, region=REGION):
'''
>>> stop_random_instance(az="eu-west-1a", tag_name='chaos', tag_value="chaos-ready", region='eu-west-1')
['i-0ddce3c81bc836560']
'''
ec2 = boto3.client("ec2", region_name=region)
paginator = ec2.get_paginator('describe_instances')
pages = paginator.paginate(
Filters=[
{
"Name": "availability-zone",
"Values": [
az
]
},
{
"Name": "tag:" + tag_name,
"Values": [
tag_value
]
}
]
)
instance_list = []
for page in pages:
for reservation in page['Reservations']:
for instance in reservation['Instances']:
instance_list.append(instance['InstanceId'])
print("Going to stop any of these instances", instance_list)
selected_instance = random.choice(instance_list)
print("Randomly selected", selected_instance)
response = ec2.stop_instances(InstanceIds=[selected_instance])
return responseЗаметили фильтры tag_name и tag_value? Такие вот мелочи предотвратят отказ не тех инстансов. #lessonlearned

И да… перезапустишь базу данных — молодец [упс, не тот инстанс]
5 — Введение отказов и инструменты оркестрации типа «все в одном»
Вполне вероятно, что вы потерялись в таком множестве инструментов. К счастью, есть парочка введений отказа и инструментов оркестрации, которые включают в себя большую их часть и ими легко пользоваться.
Chaos Toolkit
Один из моих любимых инструментов — Chaos Toolkit, платформа с открытым исходным кодом для хаос-инжиниринга, которую коммерчески поддерживает замечательная команда ChaosIQ. Вот лишь некоторые из них: Расс Майлз, Силвейн Хеллегуарх и Марк Паррьен.
Chaos Toolkit определяет декларативный и расширяемый API для удобного проведения эксперимента по хаос-инжинирингу. Он включает драйверы для AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humino, Prometheus и Gremlin.
Расширения — это набор проверок и действий, используемых для экспериментов так: останавливаем случайно выбранный инстанс в конкретной зоне доступности, если tag-key содержит значение chaos-ready.
{
"version": "1.0.0",
"title": "What is the impact of randomly terminating an instance in an AZ",
"description": "terminating EC2 instance at random should not impact my app from running",
"tags": ["ec2"],
"configuration": {
"aws_region": "eu-west-1"
},
"steady-state-hypothesis": {
"title": "more than 0 instance in region",
"probes": [
{
"provider": {
"module": "chaosaws.ec2.probes",
"type": "python",
"func": "count_instances",
"arguments": {
"filters": [
{
"Name": "availability-zone",
"Values": ["eu-west-1c"]
}
]
}
},
"type": "probe",
"name": "count-instances",
"tolerance": [0, 1]
}
]
},
"method": [
{
"type": "action",
"name": "stop-random-instance",
"provider": {
"type": "python",
"module": "chaosaws.ec2.actions",
"func": "stop_instance",
"arguments": {
"az": "eu-west-1c"
},
"filters": [
{
"Name": "tag-key",
"Values": ["chaos-ready"]
}
]
},
"pauses": {
"after": 60
}
}
],
"rollbacks": [
{
"type": "action",
"name": "start-all-instances",
"provider": {
"type": "python",
"module": "chaosaws.ec2.actions",
"func": "start_instances",
"arguments": {
"az": "eu-west-1c"
},
"filters": [
{
"Name": "tag-key",
"Values": ["chaos-ready"]
}
]
}
}
]
}Провести вышеупомянутый эксперимент просто:
❯ chaos run experiment_aws_random_instance.json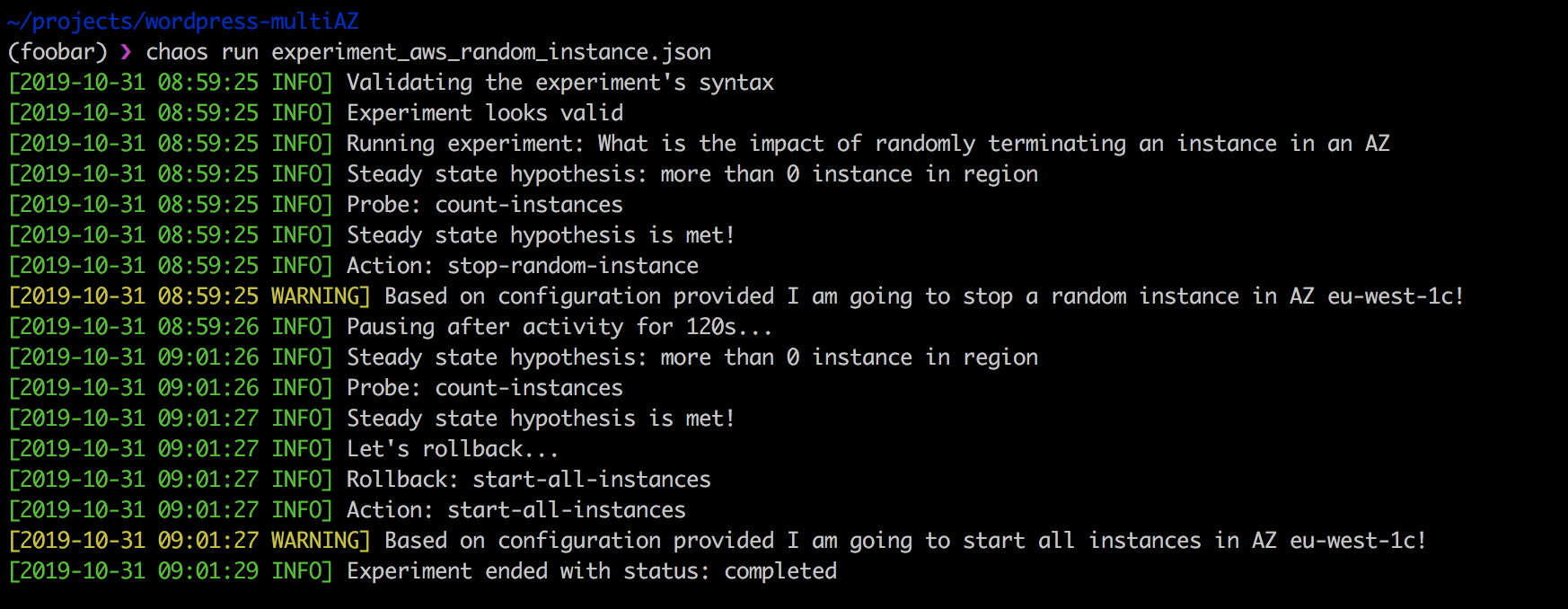
Сила Chaos Toolkit в том, что, во-первых, он с открытым исходным кодом и его можно подстроить под ваши нужды. Во-вторых, он прекрасно вписывается в конвейер CI/CD и поддерживает непрерывный хаос-тестинг.
Минус Chaos Toolkit в том, что на его освоение требуется время. Более того, в нем нет готовых экспериментов, так что придется писать их самому. Впрочем, я знаком с командой в ChaosIQ, которая работает не покладая рук, разбираясь с этой задачей.
Gremlin
Еще один мой любимчик — Gremlin. Вмещает в себя исчерпывающий набор режимов введения отказов в несложном инструменте с интуитивным пользовательским интерфейсом. Такая себе «Хаос-как-услуга».
Gremlin поддерживает введение отказов на уровне ресурса, сети и запросов, позволяя быстро экспериментировать со всей системой, в т.ч. с «железом», различными облачными провайдерами, контейнеризированными средами, включая Kubernetes, приложениями и — в некоторой степени — бессерверными приложениями.
Плюс бонус — ребята из Gremlin большие молодцы, пишут отличный контент для блога и всегда готовы помочь! Вот некоторые из них: Мэтью, Колтон, Тэмми, Рич, Ана и HML.
В использовании Gremlin проще некуда:
Сперва войдите в приложение Gremlin и выберите «Create Attack».
Назначьте цель — инстанс.
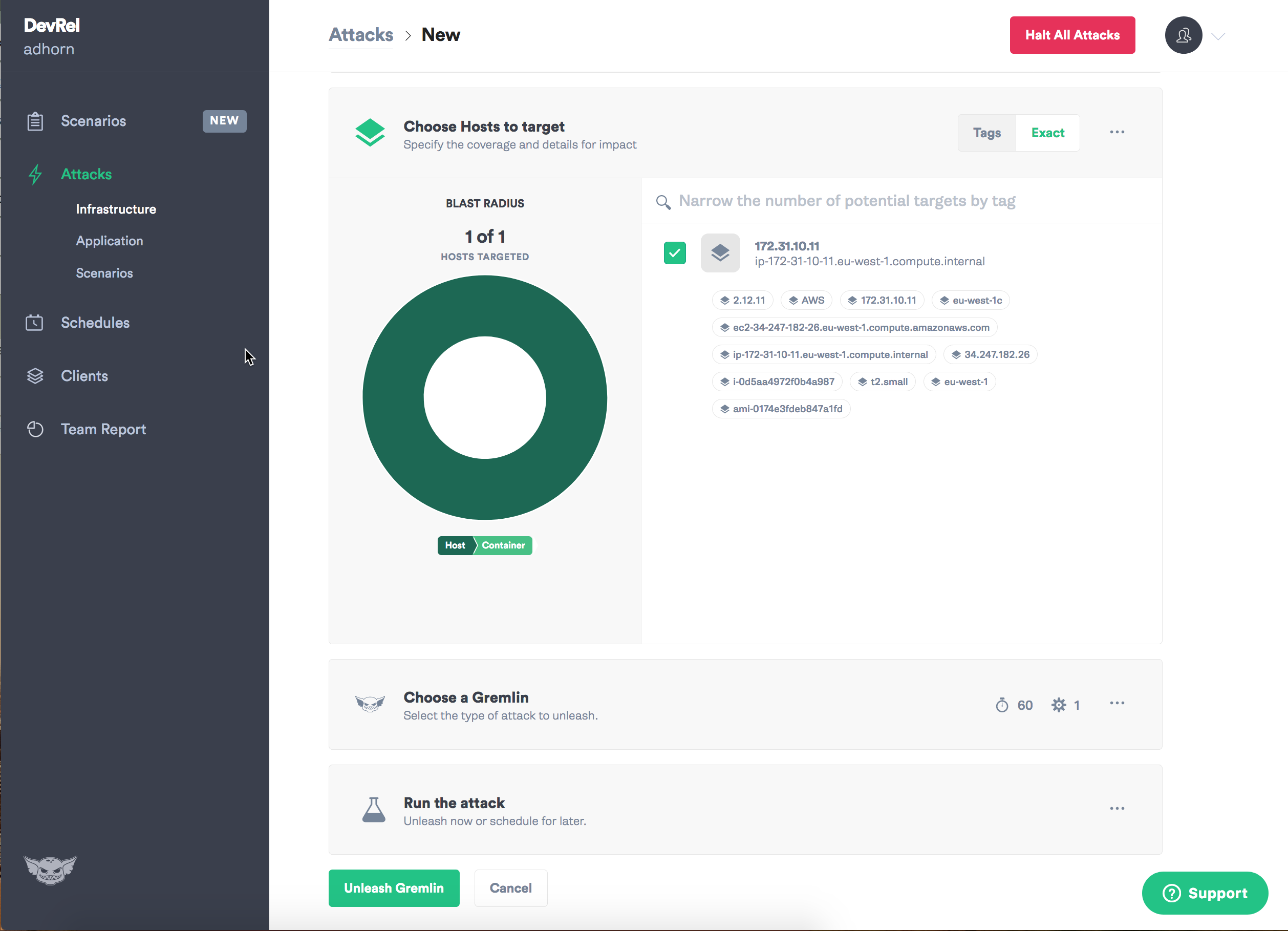
Выберите тип отказа, который хотите ввести, и да начнется хаос!
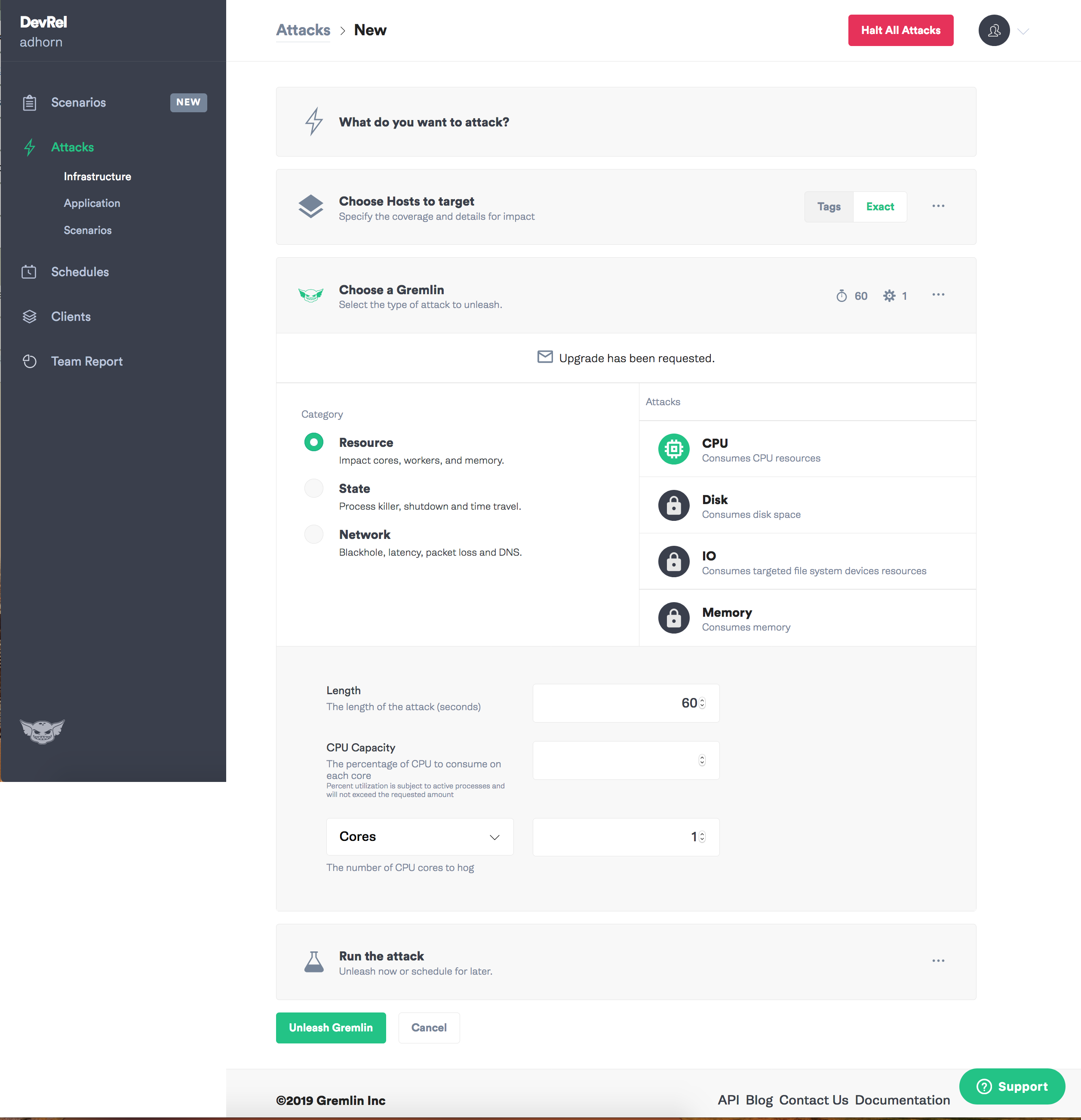
Должен признать, что Gremlin всегда мне нравился: с ним эксперименты по хаос-инжинирингу интуитивно просты.
Минус в ценовой политике — требуется лицензия для работы, что может не подойти для начинающих пользователей или разовых работ. Однако недавно добавили его бесплатную версию. Более того, Gremlin-клиент и daemon нужно устанавливать в инстансы, которые надо атаковать, а это не всем по душе.
Run Command от AWS System Manager
Приложение Run command для работы с EC2, представленное в 2015 году, сделано для простого и безопасного администрирования инстансов. Сегодня оно позволяет удаленно и безопасно управлять конфигурацией ваших инстансов — не только ЕС2, но и конфигурированные в вашей гибридной среде. Это включает локальные серверы и виртуальные машины, и даже ВМ в других облачных средах, используемых с Systems Manager.
Run Command позволяет автоматизировать задачи DevOps или выполнять ad-hoc обновления конфигурации, вне зависимости от размера вашего парка.
В то время, как Run Command по большей части используется для задач типа установки и первоначального развертывания приложений, получения журналов или подключения инстансов к домену Windows, он также хорошо подходит для проведения хаос-экспериментов.
У меня есть статья на тему введения хаоса с использованием AWS System Manager и множества готовых введений отказов с открытым исходным кодом. Попробуйте — прикольно!
Закругляемся!
Прежде чем завершить эту статью, я бы хотел подчеркнуть несколько ключевых моментов относительно введения отказов.
1 — Хаос-инжиниринг — это не про то, чтобы взять и сломать что-нибудь в производственной среде. Это путешествие. В нем вы учитесь на экспериментах в контролируемой среде — да и любой другой, — будь то локальная среда разработчика, бета, стейджинг или производственная среда. Путешествие можно начинать, где бы вы ни находились! Лучше меня скажет Ольга Холл:
«Примите Хаос сейчас. Возьмите его с собой в путь».
—Ольга Холл, старший менеджер в резилиенс-инжиниринг Amazon Prime Video
2 — Прежде чем вводить отказ, помните, что принципиально важно наладить программу мониторинга и оповещений. Без них вы просто не поймете ущерба ваших экспериментов по хаосу или сумеете оценить радиус поражения, а ведь это критично для нормальных практик хаос-инжиниринга.
3 — Некоторые из введений отказа могут причинить реальный ущерб, поэтому будьте аккуратнее и начинайте с тестовых инстансов, чтобы не пострадали клиенты.
4 — И, наконец, тесты, тесты и еще раз тесты. Помните, что хаос-инжиниринг — это про уверенность в вашем приложении и инструментах, которые должны выдерживать неблагоприятные условия.
Ну вот и все, спасибо, народ, что дочитали до конца. Надеюсь, вам понравилась третья часть. Прошу, не стесняйтесь давать обратную связь, делиться мнениями и хлопать в ладоши :-)
— Эдриан
