[Перевод] Графика для эдвенчуры с DALL-E 2
Недавно я получил доступ к OpenAI DALL-E 2. Конечно, очень весело создавать с его помощью котиков на аватарки, но ведь модель можно использовать и в других видах творческой работы.
О сильных и слабых сторонах DALL-E рассказано неоднократно, поэтому я не буду на этом останавливаться. Отмечу только, что эта нейросеть не станет угрозой высокому искусству. Модель имеет представление о том, как выглядят вещи и как они могут визуально сочетаться друг с другом, но она очень расплывчато представляет, как они работают (она не разбирается в анатомии, архитектуре, тонкостях обеденного этикета викторианской эпохи, художественной критике). Так что отрисовка объектов не достигает уровня реализма, поэтому я бы не слишком беспокоился на тему создания фальшивых новостей.
Тем не менее, под руководством человека и с тщательно выбранной сферой работы DALL-E все же может делать очень впечатляющие вещи. Я подозреваю, что графика игр жанра Adventure в духе «укажи и кликни» (Point-and-click) может быть одной из таких сфер. Я изучил потенциал DALL-E в данной области и написал этот кейс.
Источник вдохновения
Игры Adventure «укажи и кликни» представляют собой довольно широкий жанр с множеством различных художественных стилей. Я сосредоточился на поджанре, близком к стилю эдвенчур от Sierra и LucasArts начала 1990-х. Обычно они работают с разрешением экрана 320 × 200 и выглядят пикселизированными, особенно на современном дисплее:
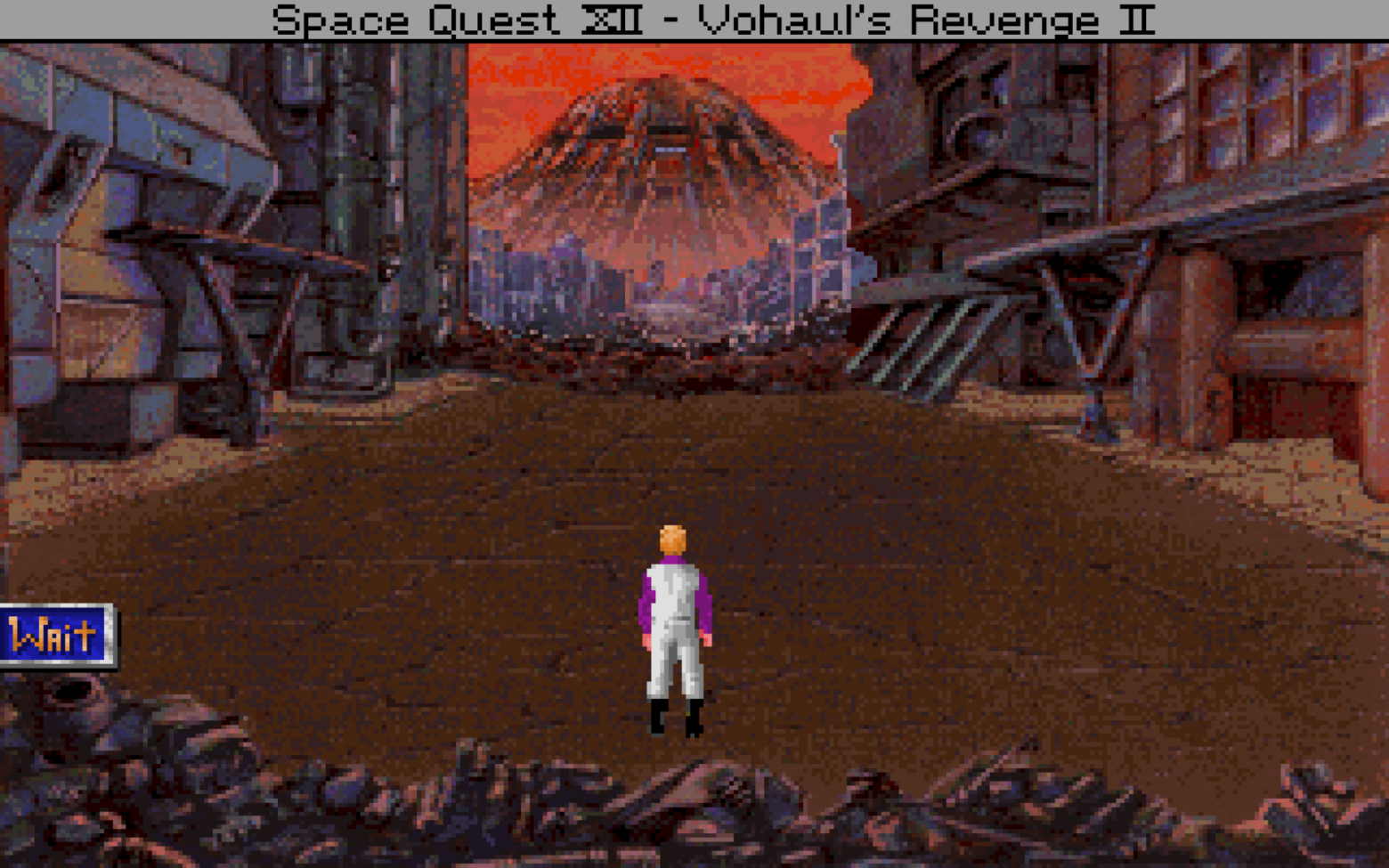 Space Quest IV (Sierra On-Line 1991)
Space Quest IV (Sierra On-Line 1991) Индиана Джонс и судьба Атлантиды (LucasArts, 1992)
Индиана Джонс и судьба Атлантиды (LucasArts, 1992)
Современные разработчики игр иногда работают с низким разрешением, что приводит к аналогичному эффекту:
 Последняя дверь (The Game Kitchen, 2013–2017)
Последняя дверь (The Game Kitchen, 2013–2017) Кэти Рейн (Clifftop Games, 2016)
Кэти Рейн (Clifftop Games, 2016) Доярка Млечного Пути (Machineboy, 2017)
Доярка Млечного Пути (Machineboy, 2017)
На первый взгляд пиксельная графика кажется излишним ограничением, но у неё есть свои преимущества. Она многое прощает и даёт простор для творчества:
Перспектива не обязательно должна быть реалистичной или даже последовательной. Её часто настраивают чисто по практическим соображениям, например, чтобы устранить визуальный беспорядок, предоставить больше места для действия или для лучшей совместимости с пиксельной сеткой.
Пикселизация помогает обойти неприятную проблему DALL-E, когда она создаёт странные пятна и плохо передаёт детали. Это также помогает при ручной ретуши, поскольку нет очень мелких деталей или текстур, которые нужно точно передать.
Ваши художества выглядят странно? Беспокоитесь об эффекте зловещей долины? Совершите бесплатный тур по жанру Adventure. Почувствуйте, как ваши проблемы уходят, когда он обнимает вас своей рукой. И ещё одной рукой. И ещё одной…
Кхм. Я пытаюсь сказать, что это замечательный, забавный жанр с огромной степенью свободы. И она нам понадобится!
Как перевести в пиксели
Хотя вы можете приказать DALL-E создавать пиксельную графику напрямую, это даже отдалённо не соответствует задаче. Модель просто не знает, как работает пиксельная сетка. Готовое изображение, как правило, будет иметь некоторые характерные особенности пиксельной графики (плоская перспектива, прямые углы, ограниченная цветовая палитра), замешанные в хаотичное нагромождение смазанных прямоугольников всех размеров:
 «Вход в отель в Мексике, стиль пиксель-арт»
«Вход в отель в Мексике, стиль пиксель-арт»
Это, конечно, впечатляет, но скорее в ключе: «пресвятые эникеи, оно, кажется, поняло, что я имел в виду»! Но даже если вы очистите сетку, то вряд ли получите последовательный стиль, и вы не можете контролировать размер сетки.
К счастью, пикселизацию можно легко отделить от основной творческой задачи и передать специализированному инструменту. В своих сценариях я использовал magick:
$ magick -adaptive-resize 25% -scale 400% in.png out.png
Стоит попробовать разные фильтры передискретизации. Оператор ImageMagick -adaptive-resize даёт хороший и четкий вывод, но при таком уменьшении дискретизации можно получить варианты получше.
Вы также можете поэкспериментировать с уменьшением цвета и дизерингом. Изображения, которые я создал для этой статьи, были обработаны следующим образом:
$ magick -adaptive-resize 25% -ordered-dither checks,32,32,32 \
-scale 800% in.png out.png
Пикселизация происходит до соотношения 1:4, ограничивая вывод цветовым кубом с 32 уровнями на канал (т. е. 15-битный цвет) и применяя тонкое —, но не слишком тонкое — сглаживание в шахматном порядке. Изображение также масштабируется в два раза по сравнению с исходным размером для удобного просмотра в браузере.
Подсказки по стилю и отбор изображений
После серии проб и ошибок я остановился на ряде подсказок, связанных с техниками, стилями и авторами изобразительного искусства: холст, масло, высокий ренессанс, модернизм, прецизионизм. Это позволило с высокой вероятностью получить несколько повторяющихся стилей с достаточной, но не слишком высокой детализацией:
 «Фасад мексиканской гасиенды в солнечный день, 2,5d (псевдотрёхмерность) модернистская живопись»
«Фасад мексиканской гасиенды в солнечный день, 2,5d (псевдотрёхмерность) модернистская живопись» «Мексиканская гасиенда в солнечный день, окруженная равнинами, цветная картина Чарльза Шилера»
«Мексиканская гасиенда в солнечный день, окруженная равнинами, цветная картина Чарльза Шилера»
Помимо важных деталей описания, таких как «солнечный день», на освещение, ракурсы камеры и декор могут значительно влиять расплывчатые определения, например, «атмосферный», «драматический», «высокое качество». Они очень ненадёжны, и у меня есть ощущение, что они могут вытеснить более важные части подсказки из крошечного разума модели. Лучше использовать компактные конкретные подсказки, пока вы не приблизитесь к желаемому результату, а потом… можете посмотреть, как всё развалится с добавлением ещё одного определения.
Что подводит нас ко второй части этой задачи, связанной с активным участием человека: отбору. Поскольку OpenAI создаёт четыре варианта для каждой подсказки, этот этап является обязательным. Она также необходима из-за того, что большая часть выходных данных совершенно не соответствует действительности. С правильной подсказкой вы можете получить выборку, в которой примерно 1/20 изображений являются хорошими (с незначительными дефектами) и 5/20 потенциально пригодными для доработки. Остальное будет явно негодным по разным причинам (крупные дефекты, проблемы в стилистике, антропоморфный столб на заднем плане).
Я думаю, такая же история происходит с впечатляющими мэшапами из DALL-E, которыми повсеместно делятся в сети. К тому времени, как вы их видите, они уже были отфильтрованы как минимум дважды. Один раз у источника и один или несколько раз в цепочке носителей, которые донесли картинки до вас. Вы не увидите сотни нелепых изображений, которые сопутствовали созданию пары удачных.
Поскольку для генерации каждого изображения требуется всего одна секунда, а для оценки — несколько секунд, проблема не страшная. Это просто означает, что DALL-E не волшебный и даже не очень умный. Но вы и так это знали, не правда ли?
Выставление сцены
Локация в приключенческой игре чем-то напоминает театральную сцену. Рекомендуется сделать достаточно свободного места рядом с камерой, чтобы игрок мог ходить по нему. Также следует избегать сцен, где игрок может уйти далеко от камеры, так как вам придётся выбирать между комичным несоответствием перспективы и очень крошечной моделькой игрока, за которой трудно следить и сложно контролировать. Очевидно, что настоящая игра не будет строго следовать этим правилам, но у вас должна быть возможность реализовать их при необходимости.
К счастью, это можно сделать, и это не слишком сложно:
 «Вход в здание в мексиканском городе и улица снаружи, в стиле атмосферной живописи высокого ренессанса, холст, масло»
«Вход в здание в мексиканском городе и улица снаружи, в стиле атмосферной живописи высокого ренессанса, холст, масло» «Вход в отель в мексиканском городе и улица снаружи, высокое качество, атмосферная живопись высокого ренессанса, холст, масло»
«Вход в отель в мексиканском городе и улица снаружи, высокое качество, атмосферная живопись высокого ренессанса, холст, масло»
Добиться более плоской перспективы позволяют такие слова, как «фасад». Аналогично помогают слова «диорама» и «миниатюра», хотя они имели тенденцию придавать картине болезненный вид. Также полезно указать типичную деталь на уровне земли, на которой нужно сосредоточиться, например, «вход». Я не уверен, что »2d» и »2.5d» действительно имеют какое-то значение. Собираем всё вместе:
Укажите эпоху, время суток и условия освещения (например, «солнечный день 2000 г»).
Укажите конкретное местоположение («город», «деревня» или точное географическое место), центральную часть («фасад», «вход в гостиницу») и ближайшее окружение («дома», «улицы», «равнины»).
Вы можете явно указать открытое пространство, например,»…и улица впереди» или «площадь, окруженная…».
Иногда необходимо попросить, чтобы пространство было пустым, иначе DALL-E может дорисовать объекты и людей, которые вы хотели добавить позднее в качестве наложений.
Вы также можете указать расположение камеры, например, «вид с балкона второго этажа», но есть риск, что детали на уровне земли получатся слишком мелкими.
Некоторые комбинации модель не сможет отрисовать, что приведёт к игнорированию большей части вашей подсказки или добавлению странных макроснимков травинок и тому подобного. Будьте готовы перефразировать или пойти на компромисс. Подумайте о том, что может быть хорошо изображено моделью в тестовом доступе.
Ни при каких обстоятельствах не упоминайте слово «видеоигра», если не хотите, чтобы всё было подсвечено синим неоновым светом.
Ретушь и редактирование
Это легко сделать с помощью пользовательского интерфейса в браузере. Просто сотрите часть изображения, при желании отредактируйте подсказку и вперёд. Такая опция очень пригодится, если у вас получилась годная картинка, за исключением сосны, растущей из церковной башни, или импровизированного нашествия морских свиней. Добавление объектов тоже работает. Вот вполне правдоподобный (хотя и неуместный) излюбленный способ передвижения злодея, получившийся с первой попытки:
 «деревенский мексиканский особняк с зеленой территорией, спортивная машина, припаркованная впереди, в окружении небольших домиков в солнечный день, высокое качество, атмосферный высокий ренессанс, холст, масло»
«деревенский мексиканский особняк с зеленой территорией, спортивная машина, припаркованная впереди, в окружении небольших домиков в солнечный день, высокое качество, атмосферный высокий ренессанс, холст, масло»
Вы также можете загружать изображения в формате PNG с альфа-каналом, хотя мне пришлось кое-где щёлкнуть ластиком, прежде чем модель поняла, что на изображении действительно есть прозрачные области. Я думаю, данный метод можно также использовать для заполнения изображений цветными пятнами, чтобы получить более последовательную палитру.
Расширение изображений
DALL-E генерирует картинки размером 1024×1024 пикселей. Чтобы заполнить современный дисплей, вам нужно что-то приближенное к соотношению 19:10. Здесь пригодятся правки прозрачности. Нужно разделить исходное изображение на левую и правую половины и использовать их для заполнения двух новых изображений с прозрачными участками:

Это легко скриптуется. Обратите внимание, что вам нужно стереть подпись DALL-E с правой половины, чтобы она не просочилась в готовую картинку. Что-то типа такого должно сработать:
$ magick in.png -background none -extent 512x0 -splice 512x0 left.png
$ magick in.png \( +clone -fill white -colorize 100 -size 80x16 xc:black \
-gravity southeast -composite \) -alpha off -compose copy_opacity \
-composite -compose copy -background none -gravity east -extent 512x0 \
-splice 512x0 right.pngЗагрузите left.png и right.png повторно, введите подсказку и создайте пару вариантов для каждой половинки. Поскольку контекста много, результаты обычно получаются хорошими. Затем сшейте половинки вместе следующим образом:
$ magick +append left.png right.png out.png
Еще немного дописав скрипт, вы сможете сгенерировать все возможные варианты и оценить их, например:


Вы также можете настроить подсказки для боковых изображений. Добавить бассейн или что-то еще:


Я не удивлюсь, если когда-нибудь такое расширение изображений войдет в стандартный набор инструментов.
Другие вещи, которые DALL-E может делать, и некоторые, которые не может
С интерьерами у меня тоже были успехи. «Вырезка» (cutaway) оказалась удобной подсказкой, которая позволяет убрать стены и избежать клаустрофобного размещения камеры. Модель хорошо справлялась с декором и мебелью (например, «роскошная гостиная со столом и двумя стульями»). Она также могла генерировать иконки для предметов в инвентаре («почтовый конверт на черном фоне»). Впрочем, я не очень глубоко в это вникал.
Вы, наверное, заметили, что все сгенерированные изображения содержат дефекты. Некоторые можно исправить, удалив их и заполнив пробелы, но другие слишком многочисленны, неподатливы или малы. Это означает, что вам придется просматривать каждое изображение вручную до пикселизации (для грубого редактирования) и после (для внесения финальных штрихов). Вам также потребуется настроить цвета и уровни для единообразия.
DALL-E не может писать. На самом деле он едва ли способен расположить более трёх букв в правильной последовательности, поэтому, если вам нужны слова и обозначения, придётся вносить их самостоятельно. Карты и другие элементы, которые передают конкретную информацию, скорее всего тоже придётся исключить. Хотя вам может повезти, если вы будете использовать в основном прозрачный эскиз реплики.
Модель также вряд ли поможет с анимацией, особенно сложной многокадровой, такой как циклы ходьбы.
Если вы хотите преобразовать существующую дневную сцену в ночную, лучше всего это сделать вручную или с помощью модели переноса стиля.
Я понимаю, что затронул вопрос очень поверхностно и, вероятно, многое не учёл.
Экономика OpenAI
OpenAI контролирует использование модели через систему кредитов. В настоящее время один кредит позволяет создавать четыре изображения из одной подсказки или три правки/варианта из одного изображения и подсказки. Я получил несколько бесплатных приветственных кредитов и мне обещают ещё 15 каждый месяц. Когда вы тратите кредит, для получения результатов требуется 4–5 секунд, то есть на одно изображение уходит около секунды. Вы можете купить 115 кредитов за 15 долларов + налог, что в моем случае составляет 18,75 долларов. Это 0,163 доллара за кредит или максимум 0,0543 доллара за изображение (партия из трёх штук).
Допустим, вы используете DALL-E для создания локаций игры типа «укажи и кликни». Сколько их вам понадобится? Что ж, одна очень успешная такая игра, The Blackwell Epiphany (созданная исключительно замечательными людьми из Wadjet Eye Games), имеет около 70 локаций. Если для своей игры вы собираетесь использовать изображения, сгенерированные ИИ, значит вы вряд ли пытаетесь конкурировать с одним из самых опытных разработчиков в отрасли, поэтому давайте снизим этот показатель до 50.
50 локаций — это все ещё много, и, как я уже упоминал ранее, только 1/20 изображений получаются адекватными. Для каждого местоположения вы, вероятно, можете обойтись 10 подходящими вариантами на выбор. Это означает, что вы создадите 200 изображений для каждого местоположения или всего 10 000 изображений. Давайте удвоим это, чтобы учесть дополнительную проверку, правки, горизонтальные расширения, поздние изменения в сценарии и старые добрые ошибки. Тогда 20 000×0,0543 доллара = 1087 долларов. Поскольку большинство изображений будут генерироваться партиями по четыре, а не по три, будет справедливо округлить эту сумму до 1000 долларов. В любом случае, это, вероятно, не самые большие ваши расходы.
Как насчёт временных затрат? Я имею в виду, что оценка такого количества изображений кажется безумием, но давайте посчитаем и посмотрим. Если для создания изображения требуется около 1 с, а вы тратите около 5 с, решая, следует ли его сохранить (помним, что 95% изображений моментально идентифицируются, как хлам, и вы будете рассматривать партии из четырёх), это 20 000×6 с = 120 000 с или около 33 часов. Даже если вы можете заниматься этим только два часа в день, вам потребуется всего три-четыре недели.
На протяжении всего этого времени вы должны иметь возможность генерировать 10 вариантов и 10 правок для каждого местоположения. Дальнейшее ручное редактирование, скорее всего, займёт гораздо больше трёх недель, но у меня нет такого опыта, так что не могу сказать точно. Это также предполагает, что вы начинаете работу с составления подробного списка локаций.
Юридические соображения
В дополнение к своим политикам API у OpenAI есть общедоступная политика в отношении контента и документы с условиями использования, которые, по-видимому, относятся к DALL-E. У меня нет юридического образования, но суть их, по-видимому, в том, чтобы «не быть недоброжелательными, подлыми или отвратительными». Такие правила легко соблюдать, работая только с пейзажами и архитектурой. Некоторые ограничения кажутся неудачными с точки зрения создания развлекательной фантастики: могу ли я создать окровавленный носовой платок, автомобильную аварию или что-нибудь похуже? Наверное, нет. Что-нибудь с оружием? Конечно, нет. Впрочем, их тоже можно понять.
Больше всего беспокоит и, вероятно, мешает реализации некоторых творческих проектов пункт 6 условий использования. «Право собственности по наследованию». Я интерпретирую этого так: сгенерированные изображения являются собственностью OpenAI. Однако они обещают не отстаивать авторские права, если вы будете соблюдать другие их политики (которые, предположительно, могут измениться). Если вы делаете долгосрочную творческую работу, особенно что-то вроде игры, которая может включать темы для взрослых, это кажется рискованным предложением. Я бы не взялся за такой проект, не обратившись за разъяснениями.
Вопрос этики
Ах да, этика. Много вопросов вызывает неправильное использование, но OpenAI излишне осторожничают. В любом случае наш вариант использования DALL-E нельзя назвать гнусным.
Что более актуально для нас, так это закрытый обучающий набор данных и то, что он может содержать тонны ранее «открытых», но защищённых авторским правом материалов, или просто изображений, автор которых не хотел, чтобы они использовались таким образом. Мы говорим о полумиллиарде изображений, а соответствующие исследования и сообщения в блогах либо ссылаются на парсинг, либо прямо упоминают об этом. Поиски не увенчались особым успехом, но я обнаружил интересный открытый вопрос. Итак, может ли это быть неуважительным или даже оскорбительным?
Общая защита утверждает, что модель учится на тренировочном наборе так же, как и человек. Подразумевается, что человеческие правила (предположительно с исключениями для человека) должны применяться к её выходным данным. На первый взгляд, это может показаться разумным аргументом, но он явно ошибочен и поверхностен, поскольку DALL-E не похож на человека. Он может владеть выходными данными (или передать своё право собственности OpenAI) не больше, чем ими владеет реляционная база данных.
Лучший аргумент в данном случае таков: процесс обучения настолько сильно искажает входные данные, что невозможно восстановить исходное изображение. Вам не нужно глубоко понимать процесс, чтобы понять, что в этом есть смысл: есть терабайты обучающих данных, а на выходе модель выдаёт только гигабайты. Выходит, это трансформирующий ремикс и потенциально добросовестное/этичное использование.
У меня болит голова при мыслях об этом, особенно потому, что подобное происходит и в моей отрасли. Я ещё не пришёл к определённому выводу, но в целом думаю, что важно сосредоточиться на чистой пользе, которую могут принести технологии и совместное использование, а ещё на том, как можно справедливо распределить выгоды (и обязательства).
Нейросети перевернут мир?
Ну, не весь мир. Но что-то точно перевернут. Нейросети развивались очень быстро за последние пару лет, и похоже, DALL-E 2 уже не самая свежая новость. Мой друг пошутил, что нам посчастливилось жить в поистине глобальную эпоху с минимальным количеством белых пятен на карте и постоянным потоком достаточно точной информации. Он имел в виду, что в недалёком прошлом было множество белых пятна, а недалёкое будущее будет переполнено крайне правдоподобной хренью. Мы посмеялись над этим, но здесь есть над чем подумать.
 «Космический корабль с надписью «copyleft» на боку, пилотируемый кошками, реалистичное фото»
«Космический корабль с надписью «copyleft» на боку, пилотируемый кошками, реалистичное фото»
Что ещё интересного есть в блоге Cloud4Y
→ Как открыть сейф с помощью ручки
→ Сделайте Linux похожим на Windows 95
→ Как распечатать цветной механический телевизор на 3D-принтере
→ WD-40: средство, которое может почти всё
→ Изобретатели, о которых забыли
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем только по делу. А ещё напоминаем про второй сезон нашего сериала ITить-колотить. Его можно посмотреть на YouTube и ВКонтакте.
