[Перевод] Google обнародовала технические данные и назначение TPU

Для начала немного контекста. TPU — это специализированная ASIC, разработанная инженерами Google для ускорения процессов «вывода» (имеется ввиду получение готового результата — прим. переводчика) нейросетей, ее цель — ускорение продуктивной фазы этих приложений для уже обученных сетей. Например, это работает каждый раз, когда пользователь инициирует голосовой поиск, запрашивает перевод текста или ищет совпадение с изображением. Но на этапе обучения Google использует GPU, так же, как и все компании, использующие технологию «глубокого обучения».
Различие важно, поскольку «вывод» может выполняться по большей части с помощью 8-битных целочисленных операций, в то время как обучение обычно выполняется с помощью 32-разрядных или 16-разрядных операций с плавающей запятой. Как указал Google в своем анализе TPU, при умножении 8-битных целых чисел можно использовать в шесть раз меньше энергии, чем при умножении 16-разрядных чисел с плавающей запятой, а для сложения — в тринадцать раз меньше.
ASIC TPU использует это преимущество путем включения 8-битного матричного умножителя, который может параллельно выполнять 64 К операций умножения. При максимальной производительности он обеспечивает 92 триллиона операций в секунду. Процессор также имеет 24 Мбайт встроенной памяти, что составляет довольно большой объем для чипа такого размера. Однако пропускная способность памяти довольно скромная — 34 Гб/с. Чтобы оптимизировать энергозатраты, TPU работает на довольно скромной частоте 700 МГц и потребляет 40 Вт мощности. ASIC изготавливается по 28-нанометровому техпроцессу и имеет TDP 75 Вт.
Во всем, что касается компьютерного оборудования, Google обращает основное внимание на энергопотребление, поскольку оно составляет немалую часть общей стоимости владения (TCO) оборудованием в дата-центрах. А для крупных дата-центров затраты на электроэнергию могут расти слишком быстро в случае, когда оборудование слишком мощное для выполняемых задач. По словам авторов анализа TPU из Google, «когда закупаешь оборудование тысячами единиц, стоимость производительности важнее самой производительности».
Другим важным аспектом дизайна TPU является время отклика. Поскольку вывод выполняется в ответ на пользовательские запросы, система должна выдать результат как можно быстрее. Поэтому разработчики отдали предпочтение низкой задержке над высокой пропускной способности. Для графических процессоров это соотношение меняется на противоположное, поэтому их используют на требующей большой вычислительной мощности фазе обучения.
Обоснованность разработки компанией специального чипа для «вывода» пришла к Google около шести лет назад, когда начали внедрять технологии «глубокого обучения» в своих поисковых системах. Поскольку эти продукты ежедневно использовались миллионами людей, требующиеся вычислительные мощности начали выглядеть устрашающе. Например, выяснилось, что, если бы люди использовали голосовой поиск с применением нейронной сети всего три минуты в день, компании пришлось бы удвоить количество дата-центров Google при условии, что используется обычное оборудование.
Поскольку TPU специально спроектированы для «вывода», они обеспечивают гораздо лучшую производительность и энергоэффективность, чем процессоры Intel или графические процессоры NVIDIA. Чтобы определить возможности TPU, Google сравнил его с другими процессорами 2015 года, спроектированными для «вывода», а именно с Intel Haswell Xeon и графическим процессором NVIDIA K80. Тесты проводились на шести контрольных показателях для трех наиболее часто используемых типов нейронных сетей: сверточных (CNN), рекуррентных (RNN) и многослойных персептронов (MLP). Соответствующие конфигурации и результаты тестирования показаны в таблице ниже.
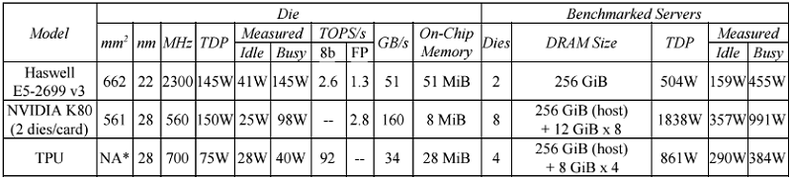
В результате было обнаружено, что TPU работал от 15 до 30 раз быстрее, чем GPU K80 и процессор Haswell. Энергоэффективность была еще более впечатляющей, TPU превосходил конкурентов в 30–80 раз. Google утверждает, что, если бы они использовали в TPU память GDDR5 с более высокой пропускной способностью, то могли бы утроить производительность чипа.
Такие результаты не так уж удивительны, учитывая, что GPU K80 ориентирован на HPC и обучение нейронной сети, но не оптимизирован для вывода. Что касается процессоров Xeon, они не оптимизированы для «глубокого обучения» алгоритмов любого типа, хотя в аналогичных сценариях они лишь немного медленнее, чем K80.
В некоторой степени, все это — старые новости. Новая линейка процессоров NVIDIA 2017-го года из семейства Pascal превосходит K80 с большим отрывом. Что касается вывода, NVIDIA теперь предлагает графические процессоры Tesla P4 и P40, которые, как и TPU, поддерживают 8-разрядные целочисленные операции. Эти процессоры NVIDIA могут быть недостаточно быстрыми, чтобы превзойти специализированный TPU, но разрыв в производительности между ними, вероятно, будет значительно меньше.
В любом случае, TPU не угрожает лидерству NVIDIA в сфере «глубокого обучения». GPU-мейкер по-прежнему доминирует в этой сфере и, очевидно, собирается продавать множество своих ускорителей «вывода» P4 и P40 крупным дата-центрам. Более общая угроза NVIDIA в области разработок для «вывода» — это Intel, которая позиционирует свои Altera FPGA для этого типа работы. Так, Microsoft уже подписала контракт на поставку Altera FPGA, развернув крупнейшее в мире облако ИИ с использованием процессоров Altera/Intel. И другие поставщики услуг ИИ также могут последовать этому примеру.
Почти наверняка Google уже работает над своим TPU второго поколения. Этот чип, вероятно, будет иметь память с более высокой пропускной способностью, либо GDDR5, либо что-то еще более экзотическое. Инженеры Google наверняка будут экспериментировать с логикой и дизайном TPU для увеличения тактовой частоты. Переход на меньший техпроцесс, скажем, 14 нанометров, сделал бы достижение этих целей проще. Конечно, вполне возможно, что эти TPU уже выпущены и используются в какой-то части облака Google –, но об этом мы если и узнаем, то только через пару лет.
