[Перевод] Глобальная теплокарта Strava: теперь в 6 раз горячее
Рад объявить о первом крупном обновлении глобальной тепловой карты в Strava Labs c 2015 года. Это обновление включает в себя в шесть раз больше данных, чем раньше — в сумме 1 миллиард активностей со всей базы Strava по сентябрь 2017 года.
Наша глобальная теплокарта — самая крупная и подробная, и это самый прекрасный в мире набор данных такого рода. Это прямая визуализация активностей глобальной сети атлетов Strava. Чтобы дать представление о масштабе, то новая теплокарта включает в себя:
- 1 миллиард активностей
- 3 триллиона точек долготы/широты
- 13 триллионов пикселей после растрирования
- 10 терабайт исходных данных
- Общая дистанция маршрутов: 27 миллиардов километров
- Запись общего времени активности: 200 тысяч лет
- 5% земной суши покрыто тайлами

Тепловая карта Москвы демонстрирует функцию поворота/наклона в Mapbox GL
Кроме простого увеличения объёма данных, мы полностью переписали код теплокарты. Это позволило значительно улучшить качество рендеринга. На выделенных участках (highlights) разрешение увеличено вдвое. Растрирование данных по активности осуществляется по маршрутам, а не по точкам. Также улучшена техника нормализации, что даёт более подробные и красивые визуализации.
Теплокарты уже доступны на Strava Labs и Strava Route Builder. Остальная часть статьи посвящена более подробному техническому описанию этого обновления.
Предыстория
Обновлению теплокарты препятствовали две технические проблемы:
- Предыдущая версия теплокарты написана на низкоуровневом C и спроектирована для работы только на одной машине. С учётом этого ограничения обновление теплокарт заняло бы месяцы.
- Для доступа к данным потоков требуется по одному запросу S3 на каждую активность, поэтому чтение входных данных для миллиарда активностей стоило бы тысячи долларов и им было бы сложно управлять.
Код генерации теплокарты полностью переписали с помощью Apache Spark и Scala. Новый код задействует новую инфраструктуру с массовым доступом к потоку активности и поддерживает параллелизацию на каждом этапе от начала до конца. После этих изменений мы полностью решили все проблемы масштабирования. Полная глобальная теплокарта построена на нескольких сотнях машинах всего за несколько часов, с общей стоимостью вычислительной операции всего в несколько сотен долларов. В будущем сделанные изменения позволят обновлять теплокарту на регулярной основе.
В других частях этой статьи детально описывается, как работает каждый этап задачи Spark по созданию теплокарты, а также описываются конкретные улучшения рендеринга.
Входные данные и фильтрация
Входные потоки с исходными данными об активностях поступает с хранилища данных Spark/S3/Parquet. Эти данные включают в себя каждую из 3 триллионов GPS-точек, когда-либо загруженных на Strava. Несколько алгоритмов чистят и фильтруют эти данные.
На платформе действуют многочисленные ограничения для защиты приватности, которые нужно соблюдать:
- Приватные активности сразу исключаются из обработки
- Площади активностей обрезаются в соответствии с установленными пользователем зонами приватности
- Из обработки полностью исключаются данные атлетов, которые отключили функцию Metro/теплокарты в настройках приватности
Дополнительные фильтры устраняют ошибочные данные. Из теплового слоя бегунов исключаются активности со скоростью бега выше разумной, потому что они с большой вероятностью были помечены ошибочно как «бег». Есть такие же верхние лимиты максимальной скорости для велосипедистов, чтобы отделить их от автомобилей и самолётов.
Данные о неподвижных объектах имеют нежелательный побочный эффект — они показывают адреса, где люди живут или работают. Новый алгоритм намного лучше выявляет точки остановки атлетов. Если величина усреднённой по времени скорости потока активности становится слишком малой в любой момент, то соответствующие точки этой активности отфильтровываются до тех пор, пока активность не выйдет за определённый радиус от первоначальной точки остановки.
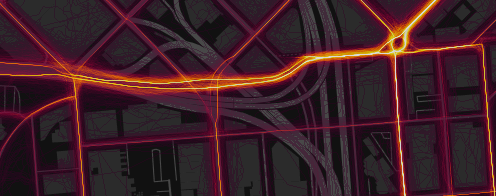
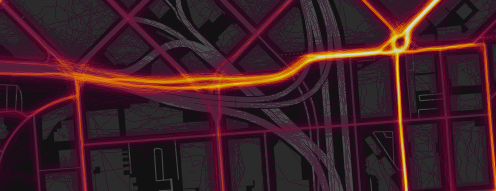
Сравнение рендеринга до (вверху) и после (внизу) добавления искусственного шума для устранения артефактов с устройств, которые корректируют данные GPS в соответствии с координатами ближайшей дороги.
Многие устройства (в первую очередь iPhone) иногда «исправляют» сигнал GPS в жилых районах, привязывая его к известной геометрии дорожной сети, а не к реальным координатам. Это приводит к неприглядному артефакту, когда на некоторых улицах ширина теплового пути составляет всего один пиксель. Сейчас мы исправляем это, добавляя случайное смещение (из нормального распределения шириной два метра) по всем точкам каждой активности. Такой уровень шума достаточен, чтобы подавить артефакт без заметного размытия других данных.
Мы также исключаем любые «виртуальные» активности типа велогонок Zwift, потому что они включают в себя фальшивые данные GPS.
Тепловая растеризация
После фильтрации координаты широты/долготы всех точек передаются в Web Mercator Tile на уровне зума 16. Этот уровень представляет собой мозаику мира из 216×216 тайлов, каждый размером 256×256 пикселей.
Старая теплокарта растрировала каждую точку GPS точно в один пиксель. Такой подход часто был помехой, потому что активности записываются с максимальной скоростью одна точка данных в секунду. Из-за этого часто возникают видимые артефакты в областях с низкой активностью: скорость записи такова, что появляются пробелы между пикселями. Вдобавок появляются отклонения в областях, где движение атлетов замедляется (сравните подъём в гору со спуском). Поскольку на новой теплокарте появился дополнительный более подробный уровень зума (максимальное пространственное разрешение увеличено с 4 до 2 метров), проблема стала ещё более заметной. Вместо старого алгоритма новая карта отображает каждую активность как идеальный пиксельный маршрут, который объединяет непрерывные GPS-точки. В среднем длина сегмента между двумя точками на 16-м уровне зума составляет 4 пикселя, так что изменение очень заметное.
Чтобы добиться этого в параллельных вычислениях, нужно обработать случай, когда соседние точки маршрута относятся к разным тайлам. Каждая такая пара точек обрабатывается повторно, чтобы включить промежуточные точки вдоль линии маршрута на границе каждого тайла, который он пересекает. После такой обработки все отрезки прямой начинаются и заканчиваются на одном и том же тайле или имеют нулевую длину и могут быть пропущены. Таким образом, мы можем представить наши данные как прямые произведения (Tile, Array[TilePixel]), где Array[TilePixel] — это непрерывная серия координат, которая описывает маршрут каждой активности внутри тайла. Набор данных затем группируется по тайлам, так что все данные, необходимые для отрисовки каждого тайла, сопоставляются с одной машиной.
Каждая последовательная пара пикселей в тайле затем растрируется как отрезок прямой при помощи алгоритма Брезенхэма. Этот этап отрисовки отрезка должен быть исключительно быстрым, поскольку он запускается триллионы раз. Сам тайл на данном этапе — просто массив Array[Double](256×256), представляющий собой общее количество отрезков, включающих в себя каждый пиксель.
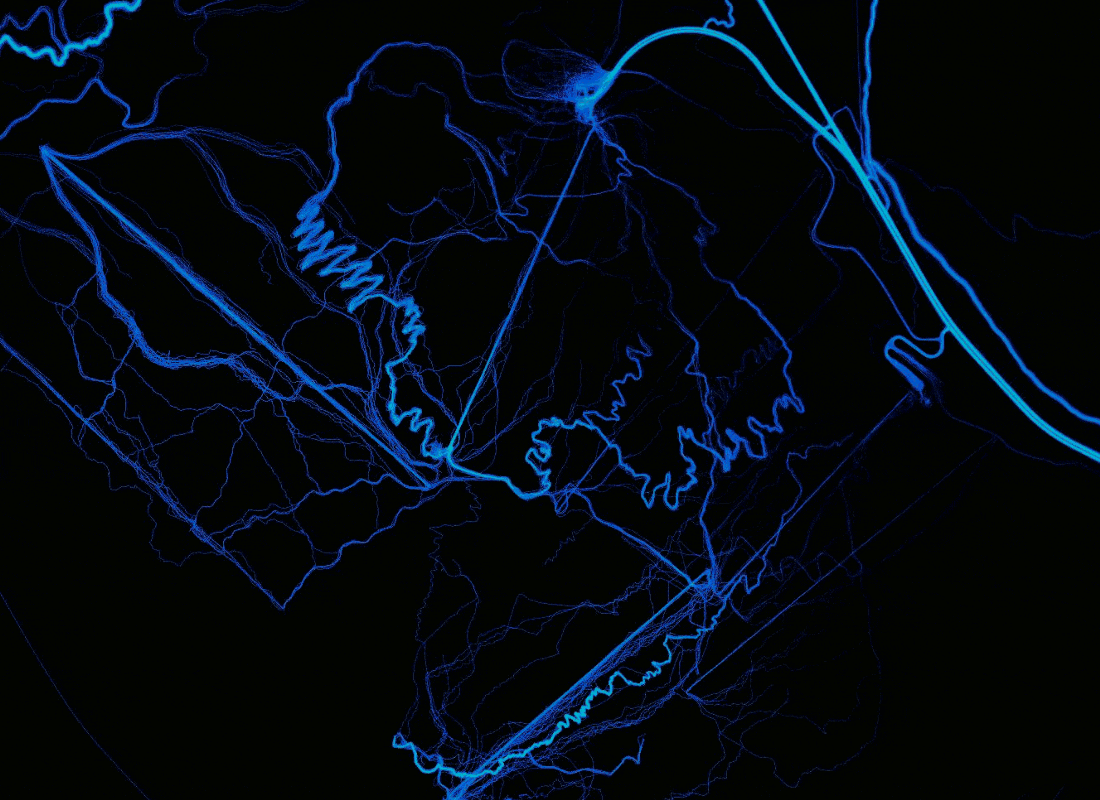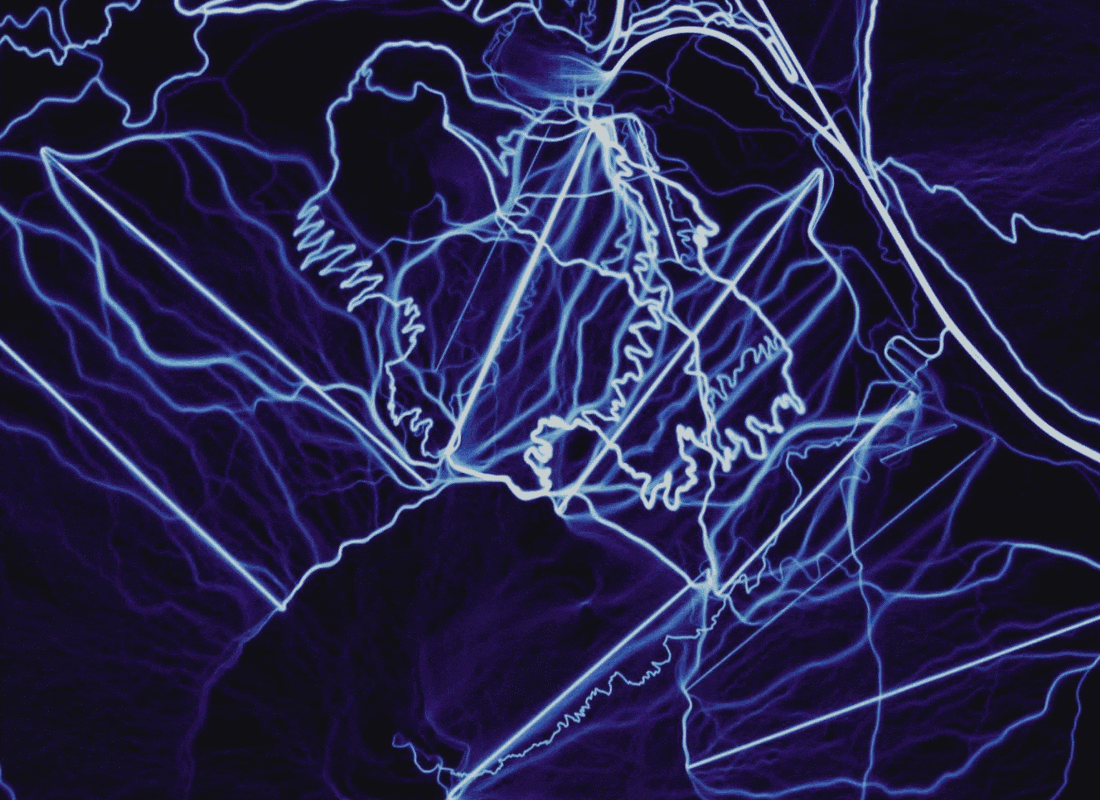
Сравнение рендеринга показывает преимущества растрирования путей поверх точек и добавления дополнительных данных. Место: вулкан Бачелор, Орегон.
На самом крупном зуме мы заполняем более 60 миллионов тайлов. Это представляет проблему, потому что прямое хранение в памяти каждого тайла в виде двойных массивов потребует минимум 60 миллионов × 256 × 256 × 8 байт = ~30 терабайт памяти. Хотя такой объём памяти можно выделить во временном кластере, это будет излишней тратой ресурсов с учётом того, что тайлы обычно допускают сильное сжатие, ведь основная часть значений пикселей равна нулю. По причинам производительности мы решили, что разреженный массив не будет эффективным решением. В Spark можно сильно уменьшить максимально необходимый объём памяти, если организовать на этом этапе параллелизм, который во много раз больше, чем количество активных задач в кластере. Тайлы с завершённой задачи немедленно преобразуются, сжимаются и записываются на диск, так что в каждый данный момент в памяти в несжатом виде хранится только набор тайлов, соответствующий активному набору задач.
Тепловая нормализация
Нормализация — это функция, которая сопоставляет исходное значение тепла для каждого пикселя после растрирования из неограниченной области [0, Inf) с ограниченной областью [0, 1] цветной карты. Выбор способа нормализации в огромной степени влияет на то, как выглядит теплокарта. Эта функция должна быть монотонной, чтобы бóльшие значения соответствовали более сильному «теплу», но существует много способов подойти к данной проблеме. Если применить единую функцию глобализации ко всей карте, то тогда цвет для максимального уровня тепла отобразится лишь в самых популярных районах Strava.
Метод гладкой нормализации (slick normalization) предусматривает вычисление CDF (функции распределения) для исходных значений. Таким образом, нормализованным значением данного пикселя будет процент пикселей с низшим уровнем тепла. Такой метод обеспечивает максимальный контраст, гарантируя одинаковое количество пикселей каждого цвета. В фотообработке эта техника называется выравниванием гистограммы. Мы используем её с небольшими изменениями, чтобы избежать артефактов квантования в малопосещаемых областях.
Вычисление CDF для исходных значений тепла только в одном тайле на практике даст не очень хороший результат, потому что на экран обычно выводится карта размером минимум 5×5 тайлов (каждый по 256×256 пикселей). Поэтому мы вычисляем общий CDF для тайла, используя его значения тепла и значения соседних областей в радиусе пяти тайлов. Это гарантирует, что функция нормализации может изменяться только в масштабе больше, чем размер обычного экрана для просмотра.
В реальных вычислениях ради производительности используется приблизительная CDF: для этого просто сортируются входные данные, откуда берётся некоторое количество образцов. Мы установили, что лучше вычислять смещённую CDF, забирая больше образцов ближе к концу массива. Это потому что в большинстве случаев интересные данные по теплу содержатся лишь в небольшой части пикселей.

Сравнение методов нормализации (слева: старый, справа: новый) на зуме 33%, чтобы лучше рассмотреть эффект. Новый метод гарантирует видимость на одном изображении любого диапазона исходных данных по теплу. Вдобавок, билинейная интерполяция функции нормализации между тайлами предотвращает любые видимые артефакты на границах тайлов. Место: область залива Сан-Франциско.
Преимущество такого подхода в том, что на теплокарте идеально равномерное распределение по цветам. В некотором смысле это приводит к тому, что теплокарта передаёт максимальную информацию об относительных значениях тепла. Мы также субъективно считаем, что выглядит она по-настоящему красиво.
Недостаток этого подхода в том, что теплокарта теперь не соответствует абсолютным количественным значениям. Один и тот же цвет соответствует одному и тому же уровню тепла только на локальном уровне. Поэтому для государственных органов, департаментов планирования, безопасности и транспорта мы предлагаем более сложный продукт Strava Metro с точной количественной версией тепловой карты.
Интерполяция функций нормализации через границы тайлов
До сих пор мы использовали функцию нормализации для каждого тайла, которая представляет собой CDF пикселей в рамках нескольких соседних тайлов. Однако CDF по-прежнему скачкообразно изменяется на границах тайлов так, что выглядит как некрасивый артефакт, особенно в областях с большим градиентом абсолютного тепла.
Для решения этой проблемы мы применили билинейную интерполяцию. Реальное значение каждого пикселя выводится из суммы билинейных коэффициентов четырёх ближайших соседних тайлов: max (0, (1-x)(1-y)), где x, y — это расстояния от центра тайла. Такая интерполяция требует больше вычислительных ресурсов, потому что для каждого пикселя нужно оценить четыре CDF вместо одного.
Рекурсия по уровням зума
До сих пор мы говорили только о генерации тепла на одном уровне зума. При переходе на другие уровни исходные данные просто складываются — четыре тайла сливаются в один с разрешением в четверть от исходного. Затем запускается заново процесс нормализации. Это продолжается до тех пор, пока не достигнут последний уровень зума (один тайл для всего мира).
Очень захватывающе смотреть, как новые этапы процесса Spark захватывают всё меньше данных в геометрической прогрессии, так что вычисление требует экспоненциально всё меньше и меньше времени. Потратив около часа на вычисление первого уровня зума, процесс эффектно финишировал, вычислив последние несколько уровней менее чем за секунду.

Зуммирование с одного тайла в Лондоне (Великобритания) на весь мир
Выдача
В результате нормализованные данные по теплу для каждого пикселя занимают один байт, потому что мы отображаем значение на цветовой карте, и значение тепла входит в массив из 256 цветов. Эти данные хранятся в S3, с группировкой соседних тайлов в один файл для уменьшения общего количества файлов на хостинге. В момент запроса сервер забирает и кэширует соответствующий метатайл с S3, затем на лету генерирует PNG по исходным данным и запрашиваемой цветовой карте. Затем наш CDN (Cloudfront) кэширует все изображения тайлов.
Также сделаны различные обновления фронтенда. Теперь мы перешли на Mapbox GL. Благодаря этому стало возможным плавное зуммирование, а также управление причудливыми поворотами и наклонами. Надеемся, что вам понравится изучать эту обновлённую тепловую карту.
