[Перевод] Эти новые уловки пока ещё способны перехитрить видеоролики от Deepfake
Несколько недель специалист по информатике Сывей Люй [Siwei Lyu] наблюдал за роликами deepfake, созданными его командой, с терзающим беспокойством. Эти поддельные фильмы, созданные при помощи алгоритма машинного обучения, показывали знаменитостей, занимающихся такими вещами, которыми бы они не стали заниматься. Они казались ему странно пугающими, и не только потому, что он знал, что они поддельные. «Они неправильно выглядят, — вспоминает он свои мысли, —, но очень сложно точно определить, из-за чего складывается такое впечатление».
Но однажды в его мозгу возникло детское воспоминание. Как и многие другие дети, он играл с детьми в «гляделки». «Я всегда проигрывал такие состязания, — говорит он, — потому что, когда я смотрел на их немигающие лица, мне становилось очень не по себе».
Он понял, что эти поддельные фильмы вызывали у него схожий дискомфорт: он проигрывал гляделки этим звёздам кино, поскольку те не открывали и не закрывали глаза с такой частотой, как это делают реальные люди.
Чтобы узнать, почему, Люй, профессор Университета Олбани, и его команда изучили каждый шаг ПО DeepFake, создающего эти ролики.
Программы Deepfake берут на входе множество изображений конкретного человека — вас, вашей бывшей девушки, Ким Чен Ына — чтобы их было видно с разных углов, с разным выражением лица, говорящими разные слова. Алгоритмы учатся тому, как выглядит этот персонаж, а затем синтезируют полученное знание в видео, показывающем, как этот человек делает то, чего он никогда не делал. Порнография. Стивен Колберт, говорящий слова Джона Оливера. Президент, предупреждающий об опасности поддельных видеороликов.
Эти ролики выглядят убедительно в течение нескольких секунд на экране телефона, но они (пока) ещё не идеальны. В них можно разглядеть признаки подделки, например, странным образом постоянно открытые глаза, происходящие от недостатков процесса их создания. Заглянув в потроха DeepFake, Люй понял, что среди изображений, по которым училась программа, было не так уж много фотографий с закрытыми глазами (вы ведь не сохраните у себя селфи, на котором вы моргаете?). «Это становится искажением», — говорит он. Нейросеть не понимает моргания. Программы также могут упустить и другие «физиологические сигналы, присущие людям», — сказано в работе Люя, описывающей это явление — дыхание с нормальной скоростью, или наличие пульса. И хотя это исследование концентрировалось на роликах, созданных при помощи конкретного ПО, общепризнано, что даже большой набор фотографий может не суметь адекватно описать физическое восприятие человека, поэтому любое ПО, натренированное на этих изображениях, будет неидеальным.
Откровение насчёт моргания вскрыло множество поддельных видео. Но через несколько недель после того, как Люй с командой выложили черновик работы в онлайн, они получили анонимное письмо, где содержались ссылки на очередные поддельные видео, выложенные на YouTube, где звёзды открывали и закрывали глаза в более нормальном режиме. Создатели подделок развивались.
И это естественно. Как отметил Люй в интервью The Conversation, «моргание можно добавить в ролики deepfake, включив в базу изображения с закрытыми глазами, или используя для тренировки видеоролики». Зная, каков признак подделки, можно его избежать — это «всего лишь» техническая проблема. Что означает, что поддельные ролики ввяжутся в гонку вооружений между создателями и распознавателями. Исследования, подобные работе Люя, могут лишь усложнить жизнь изготовителей подделок. «Мы пытаемся поднять планку, — говорит он. — Мы хотим усложнить этот процесс, сделать его более затратным по времени».
Потому что сейчас это очень просто. Скачиваете программу, гуглите фото знаменитости, скармливаете их на вход программе. Она их переваривает, учится на них. И хотя она ещё не полностью самостоятельна, с небольшой помощью она вынашивает и рожает нечто новое и достаточно реально выглядящее.
«Она очень размыта, — говорит Люй. И он не имеет в виду изображения. — Эта линия между правдой и подделкой», — уточняет он.
Это одновременно напрягает и не удивляет любого, кто в последнее время был жив, и сидел в интернете. Но особенно это беспокоит военные и разведывательные управления. В частности, поэтому исследования Люя, как и некоторые другие работы, финансируются программой от DARPA под названием MediFor — Media Forensics [судебная экспертиза СМИ].
Проект MediFor запустили в 2016, когда агентство заметило повышение активности производителей подделок. Проект пытается создать автоматизированную систему, изучающую три уровня признаков подделки, и выдающую «оценку реальности» изображения или видео. На первом уровне ищутся грязные цифровые следы — шум от камеры определённой модели или артефакты сжатия. Второй уровень физический: не то освещение на лице, отражение выглядит не так, как должно выглядеть при таком расположении лампы. Последний — семантический: сравнение данных с подтверждённой реальной информацией. Если, допустим, утверждается, что видео, на котором запечатлели игру в футбол, было снято в Центральном парке в 14 часов во вторник, 9 октября 2018 года, совпадает ли состояние неба с погодным архивом? Соберите все уровни вместе, и получите оценку реальности данных. DARPA надеется, что к концу MediFor появятся прототипы систем, которым можно будет устроить крупномасштабные проверки.
Однако часики тикают (или это просто повторяющийся звук, созданный ИИ, натренированным на данных, относящихся к отслеживанию времени?) «Через несколько лет вы сможете столкнуться с такой вещью, как фабрикация событий», — говорит управляющий программой в DARPA Мэт Турек. «Не просто одно изображение или отредактированное видео, но несколько изображений или роликов, пытающихся передать убедительное сообщение».
В Лос-Аламосской национальной лаборатории специалист по информатике Джастон Мур более ярко представляет себе потенциальное будущее. Допустим: сообщаем алгоритму, что нам нужно видео, на котором Мур грабит аптеку; внедряем его в видеозаписи системы безопасности этого заведения; отправляем его за решётку. Иначе говоря, его беспокоит, что если стандарты проверки доказательств не будут (или не смогут) развиваться параллельно изготовлению подделок, людей подставлять будет просто. А если суды не смогут полагаться на визуальные данные, может получиться так, что будут проигнорированы и настоящие доказательства.
Мы приходим к логическому заключению, что один раз увидеть будет не лучше, чем сто раз услышать. «Может так получиться, что мы не будем доверять никаким фотографическим свидетельствам, — говорит он, —, а мне в таком мире жить не хочется».
Такой мир не так уж невероятен. И проблема, по словам Мура, простирается гораздо дальше замены лиц. «Алгоритмы могут создавать изображения лиц, не принадлежащих реальным людям, они могут странным образом переделывать изображения, превращая лошадь в зебру», — говорит Мур. Они могут удалять части изображений и удалять из видео объекты, находящиеся на переднем плане.
Может, у нас не получится бороться с подделками быстрее, чем их будут делать. Но, может, и получится — и эта возможность даёт мотивацию для команды Мура по исследованию цифровых методов изучения доказательств. Программа Лос-Аламоса, комбинирующая знания по киберсистемам, информационным системам, теоретической биологии и биофизики, примерно на год моложе агентства DARPA. Один из подходов концентрируется на «сжимаемости», на случаях, когда в изображении содержится не столько информации, сколько кажется. «По сути, мы отталкиваемся от идеи о том, что у всех ИИ-генераторов изображений есть ограниченный набор вещей, которые они способны создать, — говорит Мур. — Так что даже если изображение кажется мне или вам довольно сложным, в нём можно найти повторяющуюся структуру». При повторной переработке пикселей там остаётся не так уж много всего.
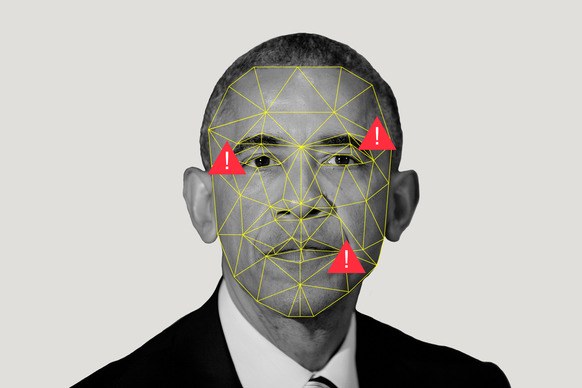
Они также используют алгоритмы разреженного кодирования, чтобы играть в игру с совпадениями. Допустим, у нас есть две коллекции: куча реальных изображений, и куча искусственно созданных ИИ картинок. Алгоритм изучает их, создавая то, что Мур называет «словарём визуальных элементов», отмечая, что общего есть у искусственных картинок, и что общего есть у реальных изображений. Если друг Мура ретвитнет изображение Обамы, а Мур посчитает, что изображение сделано при помощи ИИ, он сможет прогнать его через программу и узнать, к какому из словарей оно будет ближе.
Лос-Аламос, где находится один из мощнейших суперкомпьютеров мира, закачивает в эту программу ресурсы не только потому, что кто-то может подставить Мура через поддельное ограбление. Миссия лаборатории — «решать проблемы национальной безопасности при помощи научного превосходства». Их центральная задача — ядерная безопасность, обеспечение гарантий того, что бомбы не взорвутся тогда, когда не должны, и взорвутся, когда должны (пожалуйста, не надо), а также помощь в нераспространении. Всё это требует общих знаний по машинному обучению, поскольку помогает, как говорит Мур, «делать большие выводы из малых наборов данных».
Но кроме всего этого такие предприятия, как Лос-Аламос, должны иметь возможность верить своим глазам — или знать, когда им не нужно доверять. Поскольку, что, если вы увидите спутниковые изображения того, как страна мобилизует или испытывает ядерное оружие? Что, если кто-то подделает показания датчиков?
Это пугающее будущее, которого работы Мура и Люя должны в идеале избежать. Но в мире, где всё пропало, увидеть — не значит поверить, а кажущиеся стопроцентными измерения могут быть поддельными. Всё цифровое подвергается сомнениям.
Но, может, «сомнения» — неправильное слово. Многие люди примут подделки за чистую монету (помните фото акулы в Хьюстоне?), особенно если содержимое совпадёт с их убеждениями. «Люди будут верить в то, во что склонны верить», — говорит Мур.
Вероятность этого выше для обычной публики, смотрящей новости, чем в области национальной безопасности. И чтобы помешать распространению дезинформации среди нас, простаков, DARPA предлагает сотрудничество соцсетям, в попытке помочь пользователям определить, что достоверность того видео, где Ким Чен Ын танцует макарену, довольно низкая. Турек указывает на то, что соцсети могут распространить историю, опровергающую видео, так же быстро, как само видео.
Но будут ли они это делать? Разоблачение — процесс хлопотный (хотя и не такой неэффективный, как гласит молва). А людям необходимо по-настоящему показать факты до того, как они смогут поменять своё мнение насчёт выдумок.
Но даже если никто не сможет поменять мнение масс по поводу правдивости видео, важно, что люди, принимающие политические и юридические решения — по поводу того, кто перевозит ракеты или убивает людей — пытаются использовать машины для того, чтобы отделить явную реальность от сна ИИ.
