[Перевод] Экстремальная настройка производительности HTTP: 1,2M API RPS на инстансе EC2 с 4 виртуальными процессорами (vCPU)
Прим. перев.: автор данного исследования — Marc Richards, Solutions Architect и DevOps-инженер — продемонстрировал потрясающую настойчивость и тщательность в тотальной оптимизации производительности веб-приложения. Получившийся материал — кладезь полезных знаний для расширения своего кругозора в области оптимизации, особенностей сетевого стека в Linux и не только, даже вне зависимости от практической заинтересованности в конечном результате автора. Приготовьтесь к по-настоящему длинному техническому путешествию с обилием терминологии, увлекательных графиков и полезных ссылок.
В этой статье будут рассмотрены шаги, позволяющие увеличить производительность сервера до 1,2 млн JSON API-запросов в секунду на базе инстанса AWS EC2 с 4 vCPU. За рамками этого уникального квеста останется большинство спорных решений, которые мне довелось опробовать для получения нужного результата. Вместо этого мы пойдем преимущественно проторенной дорогой, неуклонно продвигаясь от 224 тыс. RPS на старте (конфигурация по умолчанию) до умопомрачительных 1,2 млн RPS на финише.

По правде говоря, превысить планку в 1 млн RPS не было изначальной целью. Все началось с написания одной статьи, совершенно не связанной с текущей темой. Именно она подстегнула мою одержимость всеобщей оптимизацией. Глобальная пандемия обеспечила некоторую передышку в работе, и я решил по-максимуму использовать свободное время. В таблице ниже перечислены девять рассматриваемых категорий оптимизации со ссылками на соответствующие Flame-графики. Отдельные столбцы показывают выигрыш от каждой оптимизации в процентах и совокупную пропускную способность в запросах в секунду. Это довольно убедительная иллюстрация того, насколько эффективно комбинирование различных подходов при работе над оптимизацией.
Оптимизация | Flame-графики | Прирост | RPS |
Отправная точка | initial.svg | - | 224k |
1. Оптимизация приложения | app.svg | 55% | 347k |
2. Ограничение спекулятивного выполнения | spec-exec.svg | 28% | 446k |
3. Аудит / блокировка системных вызовов | syscall.svg | 11% | 495k |
4. Отключение iptables / netfilter | iptables.svg | 22% | 603k |
5. Идеальная локальность | perfect-locality.svg | 38% | 834k |
6. Оптимизация обработки прерываний | interrupt.svg | 28% | 1.06M |
7. Любопытные соседи | nosy-neighbor.svg | 6% | 1.12M |
8. Борьба со спинлоками | spin-lock.svg | 2% | 1.15M |
9. Всё близится к завершению | final.svg | 4% | 1.20M |
Главная задача этой статьи — помочь вам в выборе и оценке инструментов и методов для профилирования/повышения производительность систем. При этом не стоит ожидать похожего увеличения производительности веб-приложения в 5 раз за счет бездумного изменения конфигураций. Многие из перечисленных оптимизаций принесут пользу только тем, кто уже превысил планку в 50 тыс. RPS. С другой стороны, применение методов профилирования к любому приложению позволяет разобраться в его поведении и выявить узкие места.
Была идея разбить статью на несколько частей, но она не прижилась из-за страха запутать все еще сильнее (кроме того, логично всю информацию держать в одном месте). Тем, кто желает углубиться и попробовать все самостоятельно, рекомендую воспользоваться шаблоном CloudFormation для настройки тестового окружения.
Базовая конфигурация бенчмарка
Это краткий обзор конфигурации бенчмарка на AWS. Для подробностей обратитесь к разделу «Подробное описание конфигурации бенчмарка». В качестве эталонного бенчмарка для эксперимента использовался тест JSON-сериализации Techempower. Для реализации использовался простой API-сервер на основе libreactor — event-driven-фреймворка, написанного на Си. API-сервер использует примитивы Linux, такие как epoll, send и recv, с минимальным потреблением ресурсов. За HTTP-парсинг отвечает picohttpparser, а за создание JSON — libclo. Он настолько быстр, насколько это возможно (во всяком случае, до появления io_uring), и выступает идеальной основой для эксперимента по оптимизации.
Аппаратное обеспечение
Сервер: инстанс 4 vCPU c5n.xlarge.
Клиент: инстанс 16 vCPU c5n.4xlarge (при попытке использовать более простой инстанс клиент становится узким местом).
Сеть: сервер и клиент находятся в одной зоне доступности (use2-az2) и группе размещения кластера.
Программное обеспечение
Операционная система: Amazon Linux 2 (ядро 4.14).
Сервер: реализации libreactor от Techempower (с 18 раунда по 20-й) запускались вручную в Docker-контейнере:
docker run -d --rm --network host --init libreactor.Клиент: было внесено несколько изменений в wrk (популярный инструмент для HTTP-бенчмаркинга) с последующим переименованием его в twrk. Он обеспечивает более стабильные результаты при коротких low-latency-тестах. Стандартная версия wrk должна выдавать аналогичные числа с точки зрения пропускной способности, но twrk лучше отображает задержки p99 и умеет выводить задержки p99.99.
Конфигурация бенчмарка
Бенчмарк запускался трижды; самые высокие и низкие результаты отбрасывались. Twrk запускался с клиента вручную с теми же заголовками, что и в официальном бенчмарке, и следующими параметрами:
без пайплайнов;
256 подключений;
16 потоков, каждый из которых прикреплён к vCPU (по 1 на каждый);
2 секунды на разогрев перед сбором статистики, 10 секунд на сам тест.
twrk -t 16 -c 256 -D 2 -d 10 --latency --pin-cpus "http://server.tfb:8080/json" -H 'Host: server.tfb' -H 'Accept: application/json,text/html;q=0.9,application/xhtml+xml;q=0.9,application/xml;q=0.8,/;q=0.7' -H 'Connection: keep-alive'Пользуясь случаем, хочу выразить свое восхищение современными достижениями в области инженерии и экономики, которые позволяют мне арендовать крошечный кусочек (почти) настоящего «железного» сервера в высокопроизводительной сети с минимальными задержками и платить за это посекундно. Как бы вы ни относились к AWS, возможности и доступность ее инфраструктуры просто впечатляют. Скажем, лет 15 назад было невозможно представить, что нечто подобное данному квесту можно проделать просто для развлечения.
Отправная точка
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 1.14ms 58.95us 1.45ms 0.96ms 61.61%
Req/Sec 14.09k 123.75 14.46k 13.81k 66.35%
Latency Distribution
50.00% 1.14ms
90.00% 1.21ms
99.00% 1.26ms
99.99% 1.32ms
2243551 requests in 10.00s, 331.64MB read
Requests/sec: 224353.73
Transfer/sec: 33.16MBБазовая реализация libreactor способна обслуживать 224 тыс. RPS. Вполне серьезная цифра: большинству приложений такие скорости просто не требуются. Вывод twrk выше показывает статистику для базового сценария.
На гистограмме ниже — сравнение пропускной способности (RPS) базовой реализации libreactor (раунд 18) и текущих реализаций нескольких популярных серверов/фреймворков (раунд 20), работающих на сервере c5n.xlarge с конфигурацией по умолчанию.
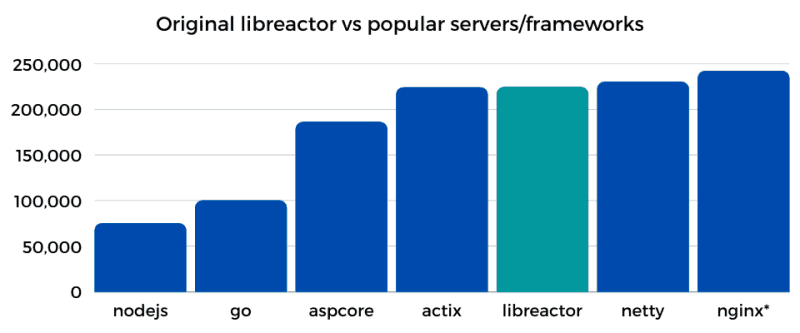 * nginx.conf изменен с тем, чтобы отправлялись за'hardcode’еные JSON-ответы. Это не входит в реализацию Techempower.
* nginx.conf изменен с тем, чтобы отправлялись за'hardcode’еные JSON-ответы. Это не входит в реализацию Techempower.
Actix, NGINX и Netty — хорошо известные, высокопроизводительные HTTP-серверы, и libreactor ничуть им не уступает. Глядя на гистограмму, можно подумать, что возможностей для улучшения на самом деле не так много, но это заблуждение. Знание о том, какое место занимает libreactor по отношению к другим HTTP-серверам, безусловно, полезно, но останавливаться на достигнутом не стоит.
Flame-графики
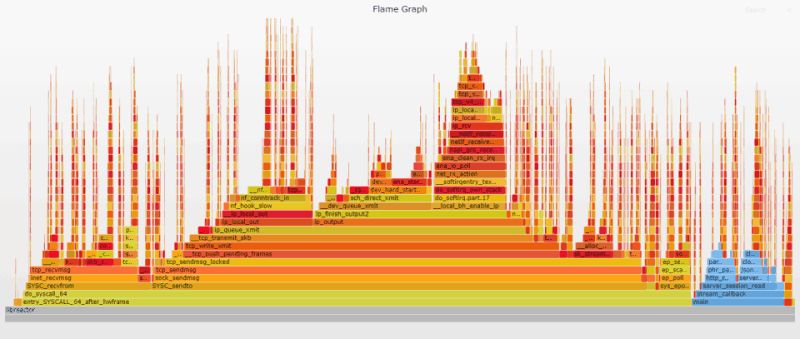
Flame-графики представляют собой уникальный способ визуализировать загрузку CPU и идентифицировать наиболее часто используемые участки кода приложения. Они являются мощным инструментом оптимизации, позволяя быстро выявлять и устранять узкие места. Flame-графики широко используются в этой статье. Они служат своего рода наглядным подтверждением достигнутого прогресса и намекают, на что еще необходимо обратить внимание.
Первый Flame-график дает представление о внутреннем устройстве приложения. Flame-графики настроены таким образом, чтобы пользовательские функции выводились в оттенках синего, а функции ядра играли всеми переливами «пламени». Из графика очевидно, что основная часть процессорного времени тратится на ядро (отправку/получение сообщений по сети). То есть наше приложение уже работает довольно эффективно; основные проблемы возникают при перемещении данных ядром.
Код на стороне пользователя отвечает за парсинг входящего HTTP-запроса и подготовку ответа. Высокие и тонкие «иглы», разбросанные по графику, представляют обработку входящих запросов, связанную с прерываниями. Эти «иглы» распределены случайным образом, поскольку прерывания могут случаться когда угодно.
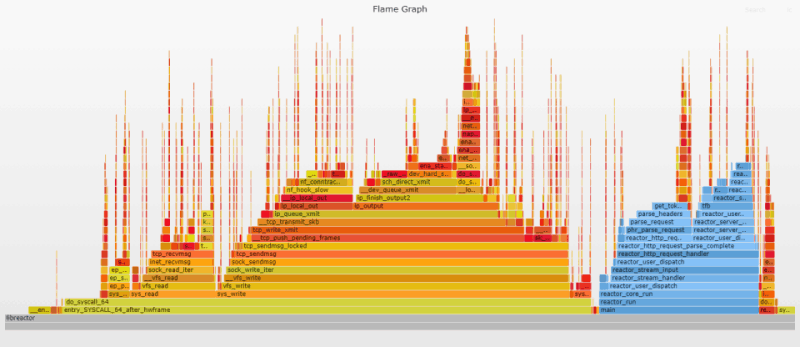
Нажмите на изображение, чтобы открыть исходный SVG-файл, созданный с помощью Flamegraph. SVG-файлы интерактивны. Можно кликнуть по сегменту, чтобы изучить его более подробно, или выполнить поиск (Ctrl + F или нажать на ссылку в правом верхнем углу) по названию функции. При поиске соответствующие участки графика выделяются фиолетовым цветом и отображается их относительная доля. Например, поиск ret_from_intr покажет, сколько времени CPU тратит на прерывания. Подробная информация о генерации Flame-графиков доступна в приложении к статье.
Предостережение
Этот квест затевался преимущественно ради развлечения. Не пытайтесь повторять его дома! Хотя дома можно, главное — не на работе (если, конечно, вы не разбираетесь досконально в том, что происходит)! Любой код на Си, написанный мной, в лучшем случае следует рассматривать как доказательство концепции. Си пришлось изучать почти с нуля — последний раз я писал на нем лет двадцать назад. Знаю, что автор libreactor«а использует его в production, но сам пока не рискую.
1. Оптимизация приложения
За базу был взят код libreactor из раунда 18* серии бенчмарков Techempower. Изменения в бенчмарке загружались непосредственно в репозиторий Techempower и сопровождались соответствующими issues в репозитории libreactor с целью внести правки на уровне фреймворка. Эти изменения были затем учтены в ветке libreactor 2.0. Реализация из раунда 20 содержит все оптимизации на уровне реализации/ фреймворка, описанные в этой статье.
* Перед бенчмаркингом код из 18 раунда получил поддержку Ubuntu 20.04, gcc 10, libdynamic 1.3.0 и libreactor 1.0.1.
Оптимизация реализации
Использование vCPU
На самую первую оптимизацию я наткнулся без какого-либо глубокого анализа. htop на сервере во время выполнения бенчмарка показал, что libreactor использует два из четырех доступных vCPU.

То есть бенчмарк в libreactor по сути использовал лишь половину своих возможностей. После правок пропускная способность возросла более чем на 25%! «А почему не в два раза?» — спросите вы. Дело в том, что:
«простаивающие» логические ядра обрабатывали часть IRQ*;
это гиперпоточные vCPU, у которых 2 физических ядра разделены на 4-х логических. Использование всех 4 логических ядер определенно увеличит скорость, но неизбежно приведет к соперничеству за ресурсы, поэтому не стоит ожидать удвоения производительности.
* Обработку IRQ на «простаивающих» vCPU можно увидеть на этом Flame-графике по итогам начального бенчмарка; он включает все процессы, а не только libreactor.
GCC
Следующая оптимизация: приложение компилировалось с GCC-флагом -O3, однако при компиляции самого фреймворка флаг оптимизации не использовался.
После создания ветки libreactor 2.0 в Makefile фреймворка был добавлен флаг GCC -march-native; его применение в приложении также благоприятно сказалось на производительности. По всей видимости, это связано с тем, что для всех компонентов используется один и тот же набор параметров при сборке с Link Time Optimizations.
Оптимизация фреймворка
send/recv
libreactor 1.0 использует функции read и write Linux для взаимодействия на основе сокетов. Использование read/write при работе с сокетами эквивалентно более специализированным функциям recv и send, при этом работа с recv/send напрямую чуть быстрее. В обычных условиях разница минимальна, но после 50 тыс. RPS она становится ощутимой. Подробности можно почерпнуть из issue на GitHub. Там же приведены Flame-графики «до» и «после». Проблема была устранена в ветке libreactor 2.0.
Потребление ресурсов pthread«ами
Аналогичным образом, хотя pthread«ы в Linux потребляют совсем мало ресурсов, их вклад станет заметным при высокой нагрузке. Оказалось, что libreactor создает пул потоков для облегчения асинхронного разрешения имен. Такой подход оправдан в случае HTTP-клиента, который подключается к множеству разных доменов, и нужно избежать блокировки DNS-запросов. Но он вряд ли подходит для HTTP-сервера, которому нужно только разрешить собственный адрес перед привязкой к сокету. Обычно эта тонкость ускользает от внимания, поскольку пул потоков создается при запуске и никогда больше не используется. Увы, управления потоками и связанной с этим траты ресурсов не избежать. Даже в экстремальных условиях этого теста overhead составляет всего около 3%, но даже 3% — слишком много, чтобы тратить их впустую.
Если сервер собран без Link Time Optimization (-flto), overhead проявляется на Flame-графиках как __pthread_enable_asynccancel и __pthread_disable_asynccancel. В этой статье он не виден, поскольку все Flame-графики генерируются на сборке со включенным -flto. Подробности доступны в соответствующем issue на GitHub; там же имеется Flame-график, на котором видны __pthread_enable_asynccancel и pthread_disable asynccancel. Проблема была устранена в ветке libreactor 2.0.
Собираем всё вместе
Вот примерный перечень всех изменений в приложении и их вклада в повышение производительности. Имейте в виду, что цифры приблизительные и призваны дать представление об их относительном вкладе.
Задействование всех vCPU — 25–27%.
Компиляция с флагом -O3 при сборке фреймворка — 5–10%.
Использование
march=nativeпри сборке приложения — 5–10%.Использование send/recv вместо
write/read— 5–10%.Устранение overhead’а pthread«ов — 2–3%.
Цифры приблизительны по следующим причинам:
Не все изменения произошли в указанном выше порядке, но были сгруппированы ради связности изложения.
Оптимизации обладают не только кумулятивным эффектом, но и дополняют друг друга. Одна оптимизация устраняет некое «узкое место», и это благоприятно сказывается на другой, повышая ее эффективность.
Например, переход от двух vCPU к четырем увеличивает пропускную способность чуть более чем на 25%, когда эта оптимизация выполняется первой, и на 40+%, когда она следует за всеми другими оптимизациями (повышается эффективность использования «простаивающих» vCPU).
Следует также отметить, что libreactor подвергся значительному рефакторингу при переходе от версии 1.0 к версии 2.0. Возможно, это также способствовало повышению производительности, однако специальных исследований на этот счет не проводилось.
Эти изменения делают нашу реализацию libreactor почти идентичной коду в 20 раунде. Единственный недостающий элемент — SO_ATTACH_REUSEPORT_CBPF (его включение будет рассмотрено позже).
Результат
Все оптимизации дают прирост производительности примерно на 55%. Пропускная способность увеличивается с 224 тыс. RPS до 347 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 735.43us 99.55us 4.26ms 449.00us 62.05%
Req/Sec 21.80k 727.56 23.42k 20.32k 62.06%
Latency Distribution
50.00% 723.00us
90.00% 0.88ms
99.00% 0.94ms
99.99% 1.08ms
3470892 requests in 10.00s, 483.27MB read
Requests/sec: 347087.15
Transfer/sec: 48.33MBАнализ Flame-графика
Наиболее очевидным изменением по сравнению с исходным Flame-графиком является уменьшение ширины и высоты фреймов, представляющих код на стороне пользователя (показаны синим цветом), благодаря флагу оптимизации gcc -O3. Также отчетливо виден результат переключения с read/write на recv/send. Наконец, повышение пропускной способности приводит к увеличению частоты прерываний (пиков ret_from intr на графике теперь гораздо больше). Поиск по ret_from_intr показывает, что его вклад вырос с 15% на исходном графике до 27% на текущем.
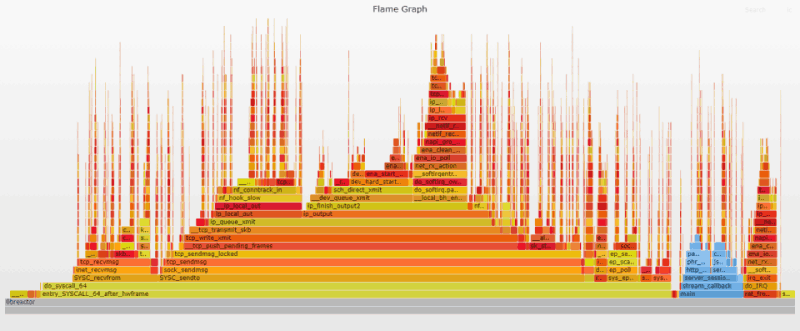
2. Отключение защиты от спекулятивного выполнения
Следующая оптимизация является одновременно существенной и спорной: отключение защиты от спекулятивного выполнения в ядре Linux. Прежде чем бежать за факелами и вилами, прошу, сделайте глубокий вдох и медленно сосчитайте до десяти. Производительность — главное в текущем эксперименте. Как оказалось, эта защита сильно на нее влияет, когда речь заходит о миллионах системных вызовов в секунду.
Но даже если оставить производительность в стороне, существуют сценарии, в которых преимущества от отключения защиты перевешивают риски (хотя в большинстве случаев она действительно имеет смысл). Например, для многопользовательской системы, которая полагается исключительно на пользовательские права и пространства имен Linux при установлении границ безопасности, стоит оставить эти ограничения в силе. С другой стороны, предположим, что API-сервер эксклюзивно занимает весь инстанс EC2. Также предположим, что ненадежный код не запускается, а инстанс использует Nitro Enclaves для дополнительной изоляции. В условиях, когда инстанс выступает естественной границей безопасности, а Nitro Enclave обеспечивает дополнительную защиту, стоит подумать об отключении защиты.
AWS, кажется, довольно уверенно применяет подход «инстансы как граница безопасности». Вот их стандартный ответ на уязвимости класса Spectre/Meltdown:
Инфраструктура AWS защищена от таких атак.
Ни один клиентский инстанс не имеет доступа к памяти инстанса другого клиента, ни один инстанс не имеет доступа к памяти гипервизора AWS.
Для разделения любых ненадежных рабочих нагрузок предлагаем использовать более жесткие меры на уровне инстансов по обеспечению безопасности и изоляции.
Естественно, не обходится без предостережения:
В качестве общей best practice в области безопасности клиентам рекомендуется вносить исправления в операционные системы или программное обеспечение по мере появления соответствующих патчей.
Полагаю, это предостережение здесь для того, чтобы клиенты не отключали бездумно средства защиты, не проанализировав должным образом особенности своего сценария.
Спекулятивное выполнение — это не единичная атака, а целый класс уязвимостей, многие из которых еще предстоит обнаружить. Возможно, если начать с предположения, что защита отключена, и изначально рассматривать инстанс/виртуальную машину как границу безопасности, в долгосрочной перспективе безопасность от этого только выиграет. Больше всего от этого выиграют те, у кого есть время и ресурсы для реализации такого подхода. Было бы крайне любопытно услышать мнения других экспертов по безопасности по этому поводу. Если вы один из них, поделитесь своим мнением на Hacker News или Reddit. Также со мной можно связаться напрямую.
Итак, для целей эксперимента выставляем performance=good, mitigations=off и переходим к подробностям о том, какие именно защитные механизмы были отключены. Вот список задействованных параметров ядра:
nospectre_v1 nospectre_v2 pti=off mds=off tsx_async_abort=offОтключенные защитные механизмы
Spectre v1 + SWAPGS
Защиту от атак Spectre variant 1 нельзя отключить, однако защиту от SWAPGS получилось отключить с помощью параметра ядра nospectre_v1. Это привело к незначительному (1–2%) увеличению производительности.
Spectre v2
Защиту от атак Spectre v2 можно отключить с помощью параметра ядра nospectre_v2. Это значительно повлияло на производительность, повысив ее на 15–20%.
Spectre v3/Meltdown
KPTI был отключен с помощью параметра pti=off. В результате производительность выросла примерно на 6%.
MDS/Zombieload и асинхронное прерывание TSX
MDS был отключен с помощью mds=off, TAA — tsx_async_abort=off. Для обеих уязвимостей используется один защитный механизм. После его отключения производительность выросла примерно на 10%.
Защитные механизмы без изменений
L1TF/Foreshadow
Инверсия PTE включена постоянно. l1tf=flush — параметр по умолчанию, но он не релевантен, поскольку вложенная виртуализация не производится. Его отключение (l1tf=off) не оказало никакого влияния на результаты, поэтому значение по умолчанию осталось без изменений.
iTLB multihit
iTLB multihit актуален только для KVM. Он также не релевантен, поскольку AWS не поддерживает запуск KVM на инстансе EC2.
Speculative Store Bypass
Похоже, что в ядре нет защиты от этой уязвимости; вместо этого проблема решается обновлением микрокода Intel. По утверждениям AWS, их базовая инфраструктура не подвержена этой проблеме, кроме того, была опубликована рекомендация, касающаяся этой уязвимости. spec_store_bypass по-прежнему значится в ядре как уязвимость, — возможно, ОС просто не имеет возможности проверить микрокод.
SRBDS
Процессоры, используемые семейством инстансов c5, не подвержены этой уязвимости.
Результат
Отключение средств защиты повышает производительность примерно на 28%. Пропускная способность возрастает с 347 тыс. до 446 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 570.37us 49.60us 0.88ms 398.00us 66.72%
Req/Sec 28.05k 546.57 29.52k 26.97k 62.63%
Latency Distribution
50.00% 562.00us
90.00% 642.00us
99.00% 693.00us
99.99% 773.00us
4466617 requests in 10.00s, 621.92MB read
Requests/sec: 446658.48
Transfer/sec: 62.19MBАнализ Flame-графика
Прирост производительности был значительным, однако изменения в Flame-графике минимальны, поскольку эти защитные механизмы практически незаметны для профилирования. Тем не менее, сравнение результатов для __entry_trampoline_start и __indirect_thunk_start на предыдущем и текущем графике показывает, что их вклад либо полностью исчез, либо сильно сократился.
3. Аудит/блокировка системных вызовов
Overhead (излишее потребление ресурсов), связанный с аудитом/блокировкой системных вызовов по умолчанию в Linux/Docker, незаметен для большинства применений;, но ситуация меняется, когда необходимо делать миллионы системных вызовов в секунду. Выполнив поиск по audit|seccomp в предыдущем Flame-графике, вы поймете, о чем речь.
Отключение аудита системных вызовов
Подсистема аудита ядра Linux предоставляет механизм для сбора и регистрации событий, связанных с безопасностью, таких как доступ к конфиденциальным файлам или системные вызовы. Это может помочь в поиске причин неожиданного поведения программы или сборе данных для последующего анализа в случае взлома. В Amazon Linux 2 подсистема аудита включена по умолчанию, но не настроена на регистрацию системных вызовов.
Хотя ведение журнала системных вызовов отключено, подсистема аудита все равно «ест» немного ресурсов при каждом системном вызове. Хорошая новость в том, что это относительно легко поправить: auditctl -a never,task. Кастомный конфиг делает именно это. Надо сказать, затея так себе, если подсистема аудита действительно занимается регистрацией системных вызовов, но я подозреваю, что в большинстве случаев это не так. Issue в Bugzilla намекает на то, что Fedora поступает аналогично.
Отключение блокировки системных вызовов
По умолчанию Docker следит за лимитами процессов, запущенных в контейнере, с помощью пространств имен, контрольных групп и ограниченного набора возможностей Linux. Кроме того, фильтр seccomp ограничивает список системных вызовов, доступных приложению.
Большинство контейнерных приложений без проблем работают с этими ограничениями, при этом контроль системных вызовов создает небольшой overhead. Одна из возможных альтернатив — запустить контейнер с параметром --privileged. Это сработает, но у контейнера окажется больше привилегий, чем необходимо. Вместо этого можно использовать параметр --security-opt, отключая только фильтр seccomp. Таким образом, команда для запуска в Docker будет выглядеть так:
docker run -d --rm --network host --security-opt seccomp=unconfined --init libreactorРезультат
В совокупности прирост производительности составил примерно 11%. Пропускная способность увеличилась с 446 тыс. до 495 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 514.02us 39.05us 1.65ms 134.00us 67.34%
Req/Sec 31.09k 433.78 32.27k 30.01k 65.97%
Latency Distribution
50.00% 513.00us
90.00% 565.00us
99.00% 604.00us
99.99% 696.00us
4950091 requests in 10.00s, 689.23MB read
Requests/sec: 495005.93
Transfer/sec: 68.92MBАнализ Flame-графика
Эти меры полностью устраняют соответствующий overhead. После их применения syscall_trace_enter и syscall_slow_exit_work исчезают с Flame-графика.
Еще одно примечание: в документации Docker говорится, что в AppArmor также есть профиль по умолчанию, однако он, похоже, отключен в Amazon Linux 2. Дело в том, что при использовании параметра --security-opt apparmor=unconfined заметных изменений в производительности (или Flame-графике) не наблюдалось.
4. Отключение iptables/netfilter
iptables/netfilter* — основной компонент, используемый традиционными брандмауэрами Linux для управления доступом к сети. Это чрезвычайно мощный и гибкий сетевой инструмент, на который полагается куча других программ, например, при преобразовании сетевых адресов (NAT). Учитывая экстремальную нагрузку теста, overhead, связанный с работой iptables, значителен, поэтому iptables становятся нашей следующей целью. На предыдущем Flame-графике overhead от iptables проявляется как на стороне отправки, так и на стороне приема в виде функции nf_hook_slow ядра; быстрый поиск по Flame-графику показывает, что на нее приходится почти 18% фреймов.
* netfilter — имя модуля ядра, который фактически выполняет всю работу. iptables — user-space-программа для изменения правил netfilter, при этом их совместный «дуэт» обычно и называют iptables.
Отключение iptables не так спорно с точки зрения безопасности, как могло бы показаться раньше. С появлением облачных вычислений задача по фильтрации пакетов сместилась с iptables на облачные примитивы (вроде AWS Security Groups). Тем не менее, во многих случаях iptables по-прежнему применяются для NAT, особенно в окружениях с большим числом Docker-контейнеров. Обратите внимание: просто отключить iptables недостаточно, необходимо также обновить/заменить все приложения, которые от него зависят.
В рамках этого теста поддержка iptables отключается в ядре и демоне Docker. Это реально, поскольку единственный контейнер напрямую подключается к хост-сети и нет необходимости в преобразовании сетевых адресов. Главное помнить, что после отключения поддержки iptables в Docker параметр --network host необходимо включать в любую команду, которая взаимодействует с сетью (в том числе в docker build).
Я предпочел отключить модуль ядра при загрузке вместо того, чтобы занести его в черный список. Теперь включить его так же просто, как добавить новое правило в iptables. Это сильно упрощает задачу, когда нужно быстро добавить динамическое правило, чтобы заблокировать недавно обнаруженную уязвимость. Увы, попутно возрастает риск случайного включения сторонним скриптом или программой. Более надежный путь — переключиться на nftables (наследника iptables) с лучшей производительностью и расширяемостью. Ограниченное тестирование с nftables показало, что загрузка этого модуля не влияет негативно на производительность, если таблица правил пуста, тогда как включение iptables существенно влияет на производительность даже без каких-либо правил.
Недостатком nftables является то, что поддержка со стороны дистрибутивов Linux появилась относительно недавно, а поддержка со стороны сторонних инструментов находится на стадии разработки. Docker — прекрасный пример этого. Что касается дистрибутивов, Debian 10, Fedora 32 и RHEL 8 перешли на nftables в качестве бэкенда по умолчанию. Слой iptables-nft используется как (преимущественно) совместимая замена iptables в user space. Разработчики Ubuntu пытались перейти на nftables в 20.04 и 20.10, но, похоже, оба раза сталкивались с проблемами совместимости. Amazon Linux 2 по-прежнему по умолчанию использует iptables. Если ваш дистрибутив поддерживает nftables, поздравляю — можно оставить модуль ядра в покое и просто внести изменения в конфиг Docker. Надеюсь, однажды в Docker появится встроенная поддержка nftables с минимальным набором правил, необходимых, чтобы сбалансировать производительность и функциональность.
Результат
Отключение iptables повысило производительность примерно на 22%. Пропускная способность возросла с 495 тыс. до 603 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 420.68us 43.25us 791.00us 224.00us 63.70%
Req/Sec 37.88k 687.33 39.54k 36.35k 62.94%
Latency Distribution
50.00% 419.00us
90.00% 479.00us
99.00% 517.00us
99.99% 575.00us
6031161 requests in 10.00s, 839.76MB read
Requests/sec: 603112.18
Transfer/sec: 83.98MBАнализ Flame-графика
Отключение iptables полностью устраняет соответствующий overhead. nf_hook_slow отсутствует на Flame-графике.

5. Идеальная локальность
Linux — крутое многоцелевое ядро, которое хорошо работает в самых разных сценариях. По умолчанию оно изо всех сил старается распределять ресурсы максимально равномерно, автоматически разбрасывая нагрузку по множеству сетевых очередей, процессов и процессоров. Такой подход отлично работает в большинстве случаев, но если нужно перейти с хорошей производительности на экстремальную, приходится жестко контролировать весь процесс.
Один из методов, возникших с появлением серверов со множеством очередей/процессоров, заключается в создании обособленных процессов (похожих на шарды баз данных), в каждом из которых сетевая очередь «прикрепляется» к CPU. В результате каждая пара работает максимально независимо от других. При этом операционная система и приложение должны быть настроены так, чтобы гарантировать, что после поступления сетевого пакета в любую очередь вся дальнейшая его обработка будет проводиться одной и той же парой vCPU/очередь как для входящих, так и для исходящих данных. Подобная привязка пакетов/данных повышает эффективность за счет актуальности кэша CPU, сокращения необходимости в переключении контекста/режимов, минимизации межпроцессорного взаимодействия и устранения конфликтов блокировок.
Привязка к процессору
Первый шаг к достижению идеальной локальности — создание отдельного серверного процесса libreactor для каждого из доступных vCPU в инстансе и привязка к этому vCPU. В нашем случае за это отвечает fork_workers (). На самом деле закрепление CPU применяется постоянно, а особое внимание, уделенное ему в текущем разделе, связано с его важностью в деле создания пары vCPU/очередь.
Receive Side Scaling (RSS)
Следующим шагом является организация фиксированных пар между сетевыми очередями и vCPU для входящих данных (исходящие обрабатываются отдельно). Receive Side Scaling — механизм с аппаратной поддержкой по равномерному распределению сетевых пакетов по нескольким очередям приема. Драйвер AWS ENA поддерживает RSS, и тот включен по умолчанию. Хеш-функция (Toeplitz) преобразует фиксированный хеш-ключ (автоматически сгенерированный при запуске) и параметры src/dst/ip/port соединения в некое хешированное значение; далее 7 наименее значимых битов этого хеша объединяются с RSS indirection table, определяя, в какую приемную очередь будет записан пакет. Такой подход гарантирует, что входящие данные от определенного соединения всегда помещаются в одну и ту же очередь. На c5n.xlarge RSS indirection table по умолчанию распределяет соединения/данные по четырем доступным приемным очередям (что и требуется), поэтому оставляем ее без изменений.
После записи пакета в область ОЗУ, зарезервированную для очереди приема, операционная система должна получить уведомление (аппаратное прерывание) о наличии данных, ожидающих обработки. Каждая сетевая очередь получает свой IRQ — по сути, выделенный канал для аппаратных прерываний. Чтобы определить, какой CPU будет обрабатывать прерывание, каждый IRQ сопоставляется с CPU с помощью /proc/irq/$IRQ/smp_affinity_list. По умолчанию сервис irqbalance обновляет значения в списке smp_affinity_list для динамического распределения нагрузки. Чтобы сохранить привязку очередей к процессорам, необходимо отключить irqbalance и вручную прописать значения в списке smp_affinity_list так, чтобы queue 0 соответствовала CPU 0, queue 1 соответствовала CPU 1, и т. д.
systemctl stop irqbalance.service
export IRQS=($(grep eth0 /proc/interrupts | awk '{print $1}' | tr -d :))
for i in ${!IRQS[@]}; do echo $i > /proc/irq/${IRQS[i]}/smp_affinity_list; done;Аппаратные прерывания и программные прерывания (softirq) автоматически обрабатываются на одном и том же процессоре, поэтому привязка сохраняется и для softirq. Это важно, поскольку аппаратные обработчики прерываний крайне минималистичны, а вся реальная работа по процессингу входящего пакета выполняется softirq-обработчиком. После завершения работы softirq данные готовы для передачи в приложение через сокет.
SO_ATTACH_REUSEPORT_CBPF
Реализация libreactor использует параметр сокета SO_REUSEPORT, позволяющий нескольким серверным процессам ожидать соединений на одном и том же порту. Это отличный вариант для распределения соединений по нескольким процессам. По умолчанию используется простая хеш-функция. Она также использует параметры src/dst/ip/port, но никак не связана с функцией, которая используется для RSS. К сожалению, случайность этого распределения нарушает привязку. Входящий пакет может быть направлен на CPU 2 для softirq-обработки, а затем передан процессу приложения, работающему на CPU 0. К счастью, начиная с версии 4.6 ядра появилась возможность более контролируемым образом управлять этими соединениями. Параметр сокета SO_ATTACH_REUSEPORT CBPF позволяе
